Azure Data Lake Storage で Common Data Model テーブルに接続する
注意
現在 Azure Active Directory は Microsoft Entra ID になりました。 詳細
Common Data Model テーブルの Dynamics 365 Customer Insights - Data アカウントを使用して、Azure Data Lake Storage にデータを取り込みます。 データ インジェストは、完全または増分にすることができます。
前提条件
Azure Data Lake Storage アカウントは、階層型名前空間が有効となっている必要があります。 データは、ルート フォルダーを定義し、テーブルごとにサブフォルダを持つ階層フォルダー形式で保存する必要があります。 サブ フォルダには、完全なデータ フォルダまたは増分データフォルダを含めることができます。
Microsoft Entra サービス プリンシパルで認証するには、テナントで構成されていることを確認してください。 詳細については、Microsoft Entra サービス プリンシパルで Azure Data Lake Storage アカウントに接続する を参照してください。
ファイアウォールで保護されたストレージに接続するには、Azure プライベート リンクを設定します。
現在、データレイクにプライベート リンク接続がある場合は、ネットワーク アクセス設定を問わず、Customer Insights - Data もプライベートリンクを使用して接続する必要があります。
接続してデータを取り込む Azure Data Lake Storage は、Dynamics 365 Customer Insights 環境と同じ Azure リージョンにある必要があり、サブスクリプションは同じテナントにある必要があります。 別の Azure リージョンにあるデータ レイクから Common Data Model フォルダーへの接続はサポートされていません。 環境の Azure リージョンを知るには、Customer Insights - Data. で 設定>システム>関連 に移動します。
オンライン サービスに保存されたデータは、データが処理または保存される場所とは別の場所に保存される場合があります。 オンラインサービスに保存されたデータをインポートまたは接続することにより、ユーザーはデータが転送されることに同意するものとします。 詳細については、Microsoft Trust Center を参照してください。
ストレージ アカウントにアクセスするには、Customer Insights - Data プリンシパルが次のいずれかの役割を果たしている必要があります。 詳細については、ストレージ アカウントにアクセスするためのアクセス許可をサービス プリンシパルに付与するを参照してください。
- ストレージ Blob データ閲覧者
- ストレージ Blob データ所有者
- ストレージ Blob データ共同作成者
Azure サブスクリプション オプションを使用して Azure ストレージに接続する場合、データ ソース接続を設定するユーザーには、少なくともストレージ アカウントに対するストレージ Blob データ共同作成者のアクセス許可が必要です。
Azure リソース オプションを使用して Azure ストレージに接続する場合、データ ソース接続を設定するユーザーには、少なくともストレージ アカウントに対するMicrosoft.Storage/storageAccounts/read アクションのアクセス許可が必要です。 このアクションを含む Azure 組み込みロール は、閲覧者 ロールです。 アクセスを必要なアクションのみに制限するには、このアクションのみを含む Azure カスタム ロールを作成します。
最適なパフォーマンスを得るには、パーティションのサイズは 1 GB 以下にする必要があり、フォルダー内のパーティション ファイルの数は 1000 以下にとどめる必要があります。
データレイク ストレージ内のデータは、データのストレージに関する共通データモデル標準に準拠し、データファイル (*.csv または*.parquet) のスキーマを表す Common Data Model マニフェストを備えている必要があります。 マニフェストには、テーブルの列やデータ型、データ ファイルの場所やファイル タイプなど、テーブルの詳細を記載する必要があります。 詳細については、Common Data Model のマニフェストを参照してください。 マニフェストが存在しない場合、Storage Blob Data Owner または Storage Blob Data Contributor のアクセス権を持つ Admin ユーザーは、データの取り込み時にスキーマを定義することができます。
注意
.parquet ファイルのいずれかのフィールドのデータ型が Int96 の場合、データが テーブル ページに表示されない場合があります。 Unix のタイムスタンプ形式 (1970 年 1 月 1 日深夜 (UTC) からの秒数で時間を表す) など、標準的なデータ型を使用することをお勧めします。
制限
- Customer Insights - Data は、精度が 16 を超える 10 進数タイプの列はサポートしません。
Azure Data Lake Storage への接続
データ接続名、データ パス (コンテナー内のフォルダーなど)、およびテーブル名には、文字で始まる名前を使用する必要があります。 名前に含めることができるのは、英字、数字、アンダースコア (_) のみです。 特殊文字はサポートされていません。
データ>データ ソースにアクセスします。
データ ソースの追加を選択します。
Azure Data Lake Common Data Model テーブル を選択します。

データソース名とオプションの説明を入力します。 この名前はダウンストリーム プロセスで参照されるため、データ ソースの作成後は変更できません。
ストレージの接続方法について、次のいずれかを選択します。 詳細については、Microsoft Entra サービス プリンシパルで Azure Data Lake Storage アカウントに接続する を参照してください。
- Azure リソース: リソース ID を入力します。
- Azure サブスクリプション:サブスクリプション を選択し、リソース グループと ストレージ アカウントを選択します。
注意
データ ソースを作成する際は、コンテナーに対して次のいずれかのロールが必要です。
- ストレージ BLOB データ閲覧者は、ストレージ アカウントから読み取りを行い、Customer Insights - Data にデータを取り込む上で十分です。
- ストレージ BLOB データの共同作成者や所有者は、Customer Insights - Data でマニフェスト ファイルを直接編集する場合に必要です。
ストレージ アカウントにロールがあると、そのすべてのコンテナーに同じロールが提供されます。
データをインポートするデータとスキーマ (model.json または manifest.json ファイル) を含むコンテナの名前を選択します。
注意
環境内にある別のデータ ソースに関連付けられている model.json または manifest.json ファイルは一覧に表示されません。 ただし、同じ model.json または manifest.json ファイルを複数の環境のデータ ソースに使用できます。
オプションとして、Azure Private Link を介してストレージ アカウントからデータを取り込む場合は、プライベート リンクを有効にするを選択します。 詳しくは、プライべ―ト リンクへアクセスしてください。
新しいスキーマを作成するには、新しいスキーマファイルを作成するに移動します。
既存のスキーマを使用するには、model.json または manifest.cdm.json ファイルを含むフォルダーに移動します。 ディレクトリ内を検索してファイルを見つけることができます。
json ファイルを選択し、次へ を選択します。 利用可能なすべてのテーブルの一覧が表示されます。
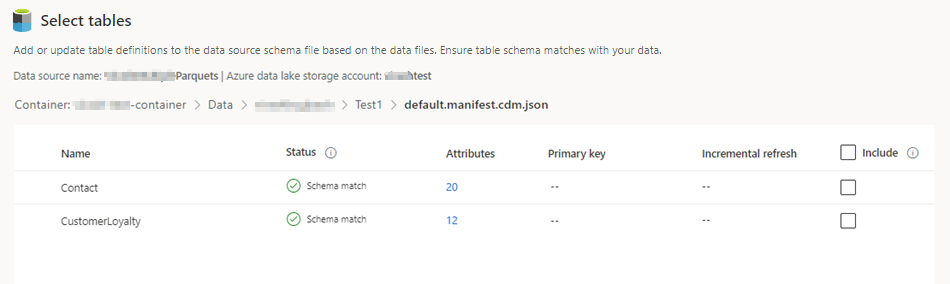
含めるテーブルを選択します。
ヒント
JSON 編集インターフェースでテーブルを編集するには、テーブルを選択し、スキーマ ファイルの編集を選択します。 変更を行い、保存を選択します。
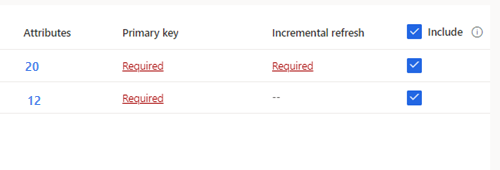
増分インジェストが必要なテーブルを選択した場合、増分更新の下に必須と表示されます。 これらの各テーブルについては、 Azure Data Lake データソースの増分更新を構成するを参照してください。
主キーが定義されていない選択されたテーブルの場合、主キーの下に必須が表示されます。 各テーブルについて:
- 必須を選択します。 テーブルの編集パネルが表示されます。
- 主キーを選択します。 主キーは、テーブルに固有の属性です。 属性を有効な主キーにするには、重複する値、欠落している値、または null 値を含めないようにする必要があります。 文字列、整数、および GUID データ型属性が主キーとしてサポートされています。
- 必要に応じて、パーティション パターンを変更します。
- 閉じる を選択し、パネルを保存して閉じます。
含まれる各テーブルの列の数を選択します。 属性の管理ページが表示されます。
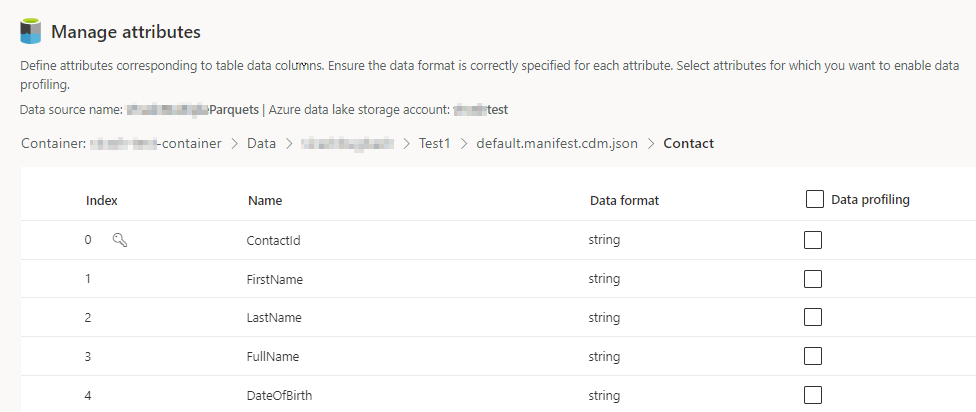
- 新しい列の作成、既存の列の編集、削除を行います。 名前、データ形式を変更したり、セマンティック タイプを追加したりできます。
- 解析やその他の機能を有効にするには、テーブル全体または特定の列の データ プロファイル を選択します。 既定では、データ プロファイルが有効になっているテーブルはありません。
- 完了を選択します。
保存 を選びます。 データソース ページが開き、新しいデータソースが更新された状態で表示されます。

データの読み込みには時間がかかる場合があります。 正常に最新の情報に更新したら、テーブル ページから取り込んだデータをレビューできます。
新しいスキーマ ファイルの作成
スキーマの作成を選択します。
ファイル名を入力し、保存を選択します。
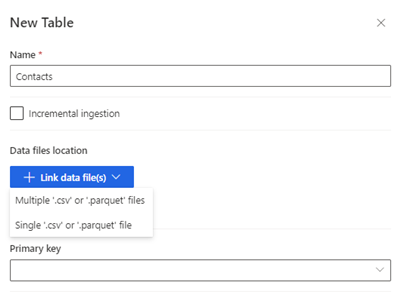
新しいテーブルを選択します。 新規テーブル パネルが表示されます。
テーブル名を入力し、データ ファイルの場所を選択します。
- 複数の .csv または .parquet ファイル: ルートフォルダーを参照し、パターンの種類を選択し、式を入力します。
- 単一の .csv または .parquet ファイル: .csv または .parquet ファイルを参照し、選択します。
保存 を選びます。
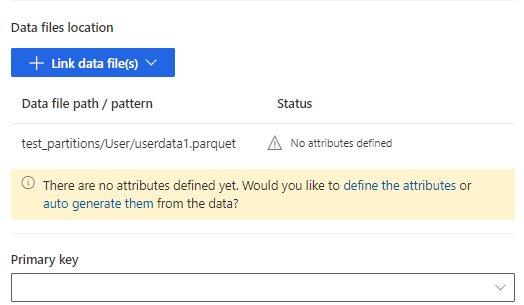
手動で属性を追加する場合は属性を定義するを選択し、自動生成する場合は自動生成を選択します。 属性を定義するには、名前を入力し、データ形式とオプションのセマンティック タイプを選択します。 自動生成された属性の場合:
属性が自動生成されたら、属性を確認するを選択します。 属性の管理ページが表示されます。
各属性のデータ形式が正しいことを確認してください。
解析やその他の機能を有効にするには、テーブル全体または特定の列のデータ プロファイリングを選択します。 既定では、データ プロファイルが有効になっているテーブルはありません。
完了を選択します。 テーブルの選択ページが表示されます。
該当する場合は、引き続きテーブルと列を追加します。
すべてのテーブルを追加したら、含めるを選択してデータ ソースの取り込みにテーブルを含めます。
増分インジェストが必要なテーブルを選択した場合、増分更新の下に必須と表示されます。 これらの各テーブルについては、 Azure Data Lake データソースの増分更新を構成するを参照してください。
主キーが定義されていない選択されたテーブルの場合、主キーの下に必須が表示されます。 各テーブルについて:
- 必須を選択します。 テーブルの編集パネルが表示されます。
- 主キーを選択します。 主キーは、テーブルに固有の属性です。 属性を有効な主キーにするには、重複する値、欠落している値、または null 値を含めないようにする必要があります。 文字列、整数、および GUID データ型属性が主キーとしてサポートされています。
- 必要に応じて、パーティション パターンを変更します。
- 閉じる を選択し、パネルを保存して閉じます。
保存 を選択します。 データソース ページが開き、新しいデータソースが更新された状態で表示されます。
データの読み込みには時間がかかる場合があります。 正常に最新の情報に更新したら、データ>テーブルページから取り込んだデータをレビューできます。
Azure Data Lake Storage データ ソースを編集する
オプションでストレージアカウントへの接続を更新することができます。 詳細については、Microsoft Entra サービス プリンシパルで Azure Data Lake Storage アカウントに接続する を参照してください。 ご利用のストレージ アカウントとは異なるコンテナーに接続をする場合や、アカウント名を変更する場合は、新しいデータ ソースの接続を作成してください。
データ>データ ソースにアクセスします。 更新するデータ ソースの横にある、編集を選択します。
次の情報のいずれかを変更します:
説明設定
次使用してストレージを接続するおよび接続情報。 接続の更新時に、コンテナー 情報を変更することはできません。
注意
次のいずれかの役割をストレージ アカウントまたはコンテナに割り当てる必要があります:
- ストレージ Blob データ閲覧者
- ストレージ Blob データ所有者
- ストレージ Blob データ共同作成者
Azure Private Link を介してストレージアカウントからデータを取り込む場合は、Private Link を有効 にします。 詳しくは、プライべ―ト リンクへアクセスしてください。
次へを選択します。
次のいずれかを変更します:
コンテナとは異なるテーブルのセットを持つ別の model.json または manifest.json ファイルに移動します。
取り込むテーブルを追加するには、新しいテーブルを選択します。
依存関係がない場合、すでに選択されているテーブルを削除するには、テーブルを選択し、削除を選択します。
重要
既存の model.json または manifest.json ファイルとテーブルのセットに依存関係がある場合、エラー メッセージが表示され、別の model.json または manifest.json ファイルを選択できません。 model.json または manifest.json ファイルを変更する前にこれらの依存関係を削除するか、依存関係の削除を回避するために使用する model.json または manifest.json ファイルを使用して新しいデータ ソースを作成します。
データ ファイルの場所または主キーを変更するには、編集を選択します。
増分取り込みデータを変更するには、次をを参照してください: Azure Data Lake データソースの増分更新を構成する。
テーブル名は、.json ファイルのテーブル名と一致するようにのみ変更してください。
注意
テーブル名は、取り込み後は常に、model.json または manifest.json ファイル内のテーブル名と同じにしてください。 Customer Insights - Data は、システムを更新するたびに、model.json または manifest.json を使用してすべてのテーブル名を検証します。 テーブル名が変更されると、Customer Insights - Data .json ファイル内で新しいテーブル名が見つからないため、エラーが発生します。 取り込まれたテーブル名が誤って変更された場合は、.json ファイル内の名前と一致するようにテーブル名を編集します。
列の追加や変更、データ プロファイリングを有効にするには、列を選択します。 そして 完了 を選択します。
保存を選択して変更を適用し、データ ソースページに戻ります。