Microsoft Spark Utilities の概要
Microsoft Spark Utilities (MSSparkUtils) は、一般的なタスクをより簡単に実行できるようにする組み込みパッケージです。 MSSparkUtils を使用すると、ファイル システムを操作し、環境変数を取得し、ノートブックをまとめてチェーン化し、シークレットを操作できます。 MSSparkUtils は、PySpark (Python)、Scala、.NET Spark (C#)、R (Preview) の各ノートブックと Synapse パイプラインで使用できます。
前提条件
Azure Data Lake Storage Gen2 へのアクセスを構成する
Synapse ノートブックでは、Microsoft Entra パススルーを使用して、ADLS Gen2 アカウントにアクセスします。 ADLS Gen2 アカウント (またはフォルダー) にアクセスするには、Storage Blob データ共同作成者である必要があります。
Synapse パイプラインでは、ワークスペースの管理サービス ID (MSI) を使用してストレージ アカウントにアクセスします。 パイプライン アクティビティで MSSparkUtils を使用するには、ADLS Gen2 アカウント (またはフォルダー) にアクセスするために、ワークスペース ID が Storage Blob データ共同作成者である必要があります。
Microsoft Entra ID とワークスペースの MSI が ADLS Gen2 アカウントにアクセスできることを確認するには、次の手順に従います。
Azure portal と、アクセスしたいストレージ アカウントを開きます。 アクセスしたい特定のコンテナーに移動できます。
左側のパネルから [アクセス制御 (IAM)] を選択します。
[追加]>[ロールの割り当ての追加] を選択して、[ロールの割り当ての追加] ページを開きます。
次のロールを割り当てます。 詳細な手順については、「Azure portal を使用して Azure ロールを割り当てる」を参照してください。
設定 値 Role ストレージ BLOB データ共同作成者 アクセスの割り当て先 USER と MANAGEDIDENTITY メンバー Microsoft Entra アカウントとワークスペース ID Note
マネージド ID の名前は、ワークスペース名でもあります。

[保存] を選択します。
Synapse Spark を使用して ADLS Gen2 のデータにアクセスするには、次の URL を使用します。
abfss://<container_name>@<storage_account_name>.dfs.core.windows.net/<path>
Azure Blob Storage へのアクセスを構成する
Synapse は、Shared Access Signature (SAS) を使って Azure Blob Storage にアクセスします。 コードの SAS キーが公開されないようにするには、Synapse ワークスペースで、アクセスしたい Azure Blob Storage アカウントにリンクされたサービスを新しく作成することをお勧めします。
Azure Blob Storage アカウントにリンクされたサービスを新しく追加するには、次の手順に従います。
- Azure Synapse Studio を開く
- 左側のパネルで [管理] を選択し、 [外部接続] の下にある [リンクされたサービス] を選択します。
- 右側にある [新しいリンクされたサービス] パネルで Azure Blob Storage を検索します。
- [続行] をクリックします。
- リンクされたサービス名にアクセスして構成するには、Azure Blob Storage アカウントを選択します。 [認証方法] には、 [アカウント キー] を使用することをお勧めします。
- [テスト接続] を選択して設定が正しいことを検証します。
- 最初に [作成] を選択し、 [すべて公開] をクリックして、変更を保存します。
Synapse Spark を使用して Azure Blob Storage のデータにアクセスするには、次の URL を使用します。
wasb[s]://<container_name>@<storage_account_name>.blob.core.windows.net/<path>
コード例はこちらです。
from pyspark.sql import SparkSession
# Azure storage access info
blob_account_name = 'Your account name' # replace with your blob name
blob_container_name = 'Your container name' # replace with your container name
blob_relative_path = 'Your path' # replace with your relative folder path
linked_service_name = 'Your linked service name' # replace with your linked service name
blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
wasb_path = 'wasbs://%s@%s.blob.core.windows.net/%s' % (blob_container_name, blob_account_name, blob_relative_path)
spark.conf.set('fs.azure.sas.%s.%s.blob.core.windows.net' % (blob_container_name, blob_account_name), blob_sas_token)
print('Remote blob path: ' + wasb_path)
val blob_account_name = "" // replace with your blob name
val blob_container_name = "" //replace with your container name
val blob_relative_path = "/" //replace with your relative folder path
val linked_service_name = "" //replace with your linked service name
val blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
val wasbs_path = f"wasbs://$blob_container_name@$blob_account_name.blob.core.windows.net/$blob_relative_path"
spark.conf.set(f"fs.azure.sas.$blob_container_name.$blob_account_name.blob.core.windows.net",blob_sas_token)
var blob_account_name = ""; // replace with your blob name
var blob_container_name = ""; // replace with your container name
var blob_relative_path = ""; // replace with your relative folder path
var linked_service_name = ""; // replace with your linked service name
var blob_sas_token = Credentials.GetConnectionStringOrCreds(linked_service_name);
spark.Conf().Set($"fs.azure.sas.{blob_container_name}.{blob_account_name}.blob.core.windows.net", blob_sas_token);
var wasbs_path = $"wasbs://{blob_container_name}@{blob_account_name}.blob.core.windows.net/{blob_relative_path}";
Console.WriteLine(wasbs_path);
# Azure storage access info
blob_account_name <- 'Your account name' # replace with your blob name
blob_container_name <- 'Your container name' # replace with your container name
blob_relative_path <- 'Your path' # replace with your relative folder path
linked_service_name <- 'Your linked service name' # replace with your linked service name
blob_sas_token <- mssparkutils.credentials.getConnectionStringOrCreds(linked_service_name)
# Allow SPARK to access from Blob remotely
sparkR.session()
wasb_path <- sprintf('wasbs://%s@%s.blob.core.windows.net/%s',blob_container_name, blob_account_name, blob_relative_path)
sparkR.session(sprintf('fs.azure.sas.%s.%s.blob.core.windows.net',blob_container_name, blob_account_name), blob_sas_token)
print( paste('Remote blob path: ',wasb_path))
Azure Key Vault へのアクセスを構成する
Synapse で資格情報を管理するために、リンクされたサービスとして Azure Key Vault を追加することができます。 Synapse のリンクされたサービスとして Azure Key Vault を追加するには、次の手順に従います。
左側のパネルで [管理] を選択し、 [外部接続] の下にある [リンクされたサービス] を選択します。
右側にある [新しいリンクされたサービス] パネルで Azure Key Vault を検索します。
リンクされたサービス名にアクセスして構成するには、Azure Key Vault アカウントを選択します。
[テスト接続] を選択して設定が正しいことを検証します。
最初に [作成] を選択し、 [すべて公開] をクリックして、変更を保存します。
Synapse ノートブックでは、Microsoft Entra パススルーを使用して、Azure Key Vault にアクセスします。 Synapse パイプラインでは、ワークスペース ID (MSI) を使用して Azure Key Vault にアクセスします。 コードがノートブックと Synapse パイプラインの両方で動作することを確認するには、Microsoft Entra アカウントとワークスペース ID の両方に対してシークレット アクセス許可を付与することをお勧めします。
ワークスペース ID にシークレット アクセス権を付与するには、次の手順に従います。
- Azure portal と、アクセスしたい Azure Key Vault を開きます。
- 左側のパネルで [アクセス ポリシー] を選択します。
- [アクセス ポリシーの追加] を選択します。
- 構成テンプレートとして [キー、シークレット、および証明書の管理] を選択します。
- プリンシパルの選択で Microsoft Entra アカウントとワークスペース ID (ワークスペース名と同じ) を選択するか、既に割り当てられていることを確認します。
- [選択] および [追加] を選択します。
- [保存] ボタンを選択して変更をコミットします。
ファイルシステム ユーティリティ
mssparkutils.fs では、Azure Data Lake Storage Gen2 (ADLS Gen2) や Azure Blob Storage など、さまざまなファイルシステムを操作するためのユーティリティが提供されています。 Azure Data Lake Storage Gen2 および Azure Blob Storage へのアクセスを適切に構成するようにしてください。
次のコマンドを実行して、使用可能なメソッドの概要を取得します。
from notebookutils import mssparkutils
mssparkutils.fs.help()
mssparkutils.fs.help()
using Microsoft.Spark.Extensions.Azure.Synapse.Analytics.Notebook.MSSparkUtils;
FS.Help()
library(notebookutils)
mssparkutils.fs.help()
結果は次のようになります。
mssparkutils.fs provides utilities for working with various FileSystems.
Below is overview about the available methods:
cp(from: String, to: String, recurse: Boolean = false): Boolean -> Copies a file or directory, possibly across FileSystems
mv(src: String, dest: String, create_path: Boolean = False, overwrite: Boolean = False): Boolean -> Moves a file or directory, possibly across FileSystems
ls(dir: String): Array -> Lists the contents of a directory
mkdirs(dir: String): Boolean -> Creates the given directory if it does not exist, also creating any necessary parent directories
put(file: String, contents: String, overwrite: Boolean = false): Boolean -> Writes the given String out to a file, encoded in UTF-8
head(file: String, maxBytes: int = 1024 * 100): String -> Returns up to the first 'maxBytes' bytes of the given file as a String encoded in UTF-8
append(file: String, content: String, createFileIfNotExists: Boolean): Boolean -> Append the content to a file
rm(dir: String, recurse: Boolean = false): Boolean -> Removes a file or directory
Use mssparkutils.fs.help("methodName") for more info about a method.
ファイルの一覧表示
ディレクトリのコンテンツを表示します。
mssparkutils.fs.ls('Your directory path')
mssparkutils.fs.ls("Your directory path")
FS.Ls("Your directory path")
mssparkutils.fs.ls("Your directory path")
ファイルのプロパティを表示します
ファイル名、ファイル パス、ファイル サイズ、ファイルの変更時刻、ディレクトリなのかファイルなのかなど、ファイルのプロパティを返します。
files = mssparkutils.fs.ls('Your directory path')
for file in files:
print(file.name, file.isDir, file.isFile, file.path, file.size, file.modifyTime)
val files = mssparkutils.fs.ls("/")
files.foreach{
file => println(file.name,file.isDir,file.isFile,file.size,file.modifyTime)
}
var Files = FS.Ls("/");
foreach(var File in Files) {
Console.WriteLine(File.Name+" "+File.IsDir+" "+File.IsFile+" "+File.Size);
}
files <- mssparkutils.fs.ls("/")
for (file in files) {
writeLines(paste(file$name, file$isDir, file$isFile, file$size, file$modifyTime))
}
新しいディレクトリの作成
指定されたディレクトリが存在しない場合は作成し、必要な親ディレクトリを作成します。
mssparkutils.fs.mkdirs('new directory name')
mssparkutils.fs.mkdirs("new directory name")
FS.Mkdirs("new directory name")
mssparkutils.fs.mkdirs("new directory name")
ファイルのコピー
ファイルまたはディレクトリをコピーします。 ファイル システム間でのコピーをサポートします。
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)# Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
FS.Cp("source file or directory", "destination file or directory", true) // Set the third parameter as True to copy all files and directories recursively
mssparkutils.fs.cp('source file or directory', 'destination file or directory', True)
パフォーマンスの高いコピー ファイル
このメソッドでは、ファイル (特に大量のデータ) を迅速にコピーまたは移動する方法を提供します。
mssparkutils.fs.fastcp('source file or directory', 'destination file or directory', True) # Set the third parameter as True to copy all files and directories recursively
Note
このメソッドは、 Azure Synapse Runtime for Apache Spark 3.3 および Azure Synapse Runtime for Apache Spark 3.4 でのみサポートされます。
ファイル コンテンツのプレビュー
指定したファイルの最初の 'maxBytes' バイトまでを、UTF-8 でエンコードされた文字列として返します。
mssparkutils.fs.head('file path', maxBytes to read)
mssparkutils.fs.head("file path", maxBytes to read)
FS.Head("file path", maxBytes to read)
mssparkutils.fs.head('file path', maxBytes to read)
ファイルの移動
ファイルまたはディレクトリを移動します。 ファイル システム間での移動をサポートします。
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
mssparkutils.fs.mv("source file or directory", "destination directory", true) // Set the last parameter as True to firstly create the parent directory if it does not exist
FS.Mv("source file or directory", "destination directory", true)
mssparkutils.fs.mv('source file or directory', 'destination directory', True) # Set the last parameter as True to firstly create the parent directory if it does not exist
ファイルの書き込み
指定した文字列を UTF-8 でエンコードしてファイルに書き込みます。
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
FS.Put("file path", "content to write", true) // Set the last parameter as True to overwrite the file if it existed already
mssparkutils.fs.put("file path", "content to write", True) # Set the last parameter as True to overwrite the file if it existed already
ファイルへのコンテンツの追加
指定した文字列を UTF-8 でエンコードしてファイルに追加します。
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path","content to append",true) // Set the last parameter as True to create the file if it does not exist
FS.Append("file path", "content to append", true) // Set the last parameter as True to create the file if it does not exist
mssparkutils.fs.append("file path", "content to append", True) # Set the last parameter as True to create the file if it does not exist
Note
mssparkutils.fs.append()とmssparkutils.fs.put()は、原子性の保証がないため、同じファイルへの同時書き込みはサポートされていません。forループでmssparkutils.fs.appendAPI を使用して同じファイルに書き込む場合は、定期的な書き込みの間に約 0.5s~ 1s のsleepステートメントを追加することをお勧めします。 これは、mssparkutils.fs.appendAPI の内部flush操作が非同期であるため、短い遅延がデータの整合性を確保するのに役立ちます。
ファイルまたはディレクトリの削除
ファイルまたはディレクトリを削除します。
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
FS.Rm("file path", true) // Set the last parameter as True to remove all files and directories recursively
mssparkutils.fs.rm('file path', True) # Set the last parameter as True to remove all files and directories recursively
Notebook のユーティリティ
サポートされていません。
MSSparkUtils Notebook ユーティリティを使用して、ノートブックを実行したり、値を持つノートブックを終了したりできます。 次のコマンドを実行して、使用可能なメソッドの概要を取得します。
mssparkutils.notebook.help()
結果の取得:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
Note
Notebook ユーティリティは、Apache Spark ジョブ定義 (SJD) には適用されません。
Notebookの参照
ノートブックを参照し、その終了値を返します。 関数呼び出しの入れ子は、対話形式またはパイプラインで、ノートブックで実行できます。 参照されているノートブックは、ノートブックがこの機能を呼び出す Spark プールで実行されます。
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
次に例を示します。
mssparkutils.notebook.run("folder/Sample1", 90, {"input": 20 })
実行が完了すると、セルの出力に「ノートブックの実行の表示: "ノートブック名"」というスナップショット リンクが表示されます。このリンクをクリックすると、この特定の実行のスナップショットを表示できます。

複数のノートブック参照を並列で実行する
mssparkutils.notebook.runMultiple() メソッドを使用すると、複数のノートブックを並列で、または定義済みのトポロジ構造で実行できます。 この API は、Spark セッション内でのマルチスレッド実装メカニズムを使用しています。つまり、コンピューティング リソースは参照Notebookの実行によって共有されます。
mssparkutils.notebook.runMultiple() を使用すると、以下のことができます。
各Notebookが完了するのを待たずに、複数のNotebookを同時に実行します。
単純な JSON 形式を使用して、Notebookの依存関係と実行順序を指定します。
Spark コンピューティング リソースの使用を最適化し、Synapse プロジェクトのコストを削減します。
出力内の各Notebook実行レコードのスナップショットを表示し、Notebook タスクを容易にデバッグ/監視します。
各エグゼクティブ アクティビティの終了値を取得し、ダウンストリーム タスクで使用します。
mssparkutils.notebook.help("runMultiple") を実行して、例と詳細な使用方法を見つけることもできます。
このメソッドを使用して一連のNotebookを並列で実行する簡単な例を次に示します。
mssparkutils.notebook.runMultiple(["NotebookSimple", "NotebookSimple2"])
ルート Notebookからの実行結果は次のとおりです。

次に、mssparkutils.notebook.runMultiple()を使用してトポロジ構造を持つ複数のNotebookを実行する例を示します。 コード エクスペリエンスを使用してノートブックを簡単にオーケストレーションするには、このメソッドを使用します。
# run multiple notebooks with parameters
DAG = {
"activities": [
{
"name": "NotebookSimple", # activity name, must be unique
"path": "NotebookSimple", # notebook path
"timeoutPerCellInSeconds": 90, # max timeout for each cell, default to 90 seconds
"args": {"p1": "changed value", "p2": 100}, # notebook parameters
},
{
"name": "NotebookSimple2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 2", "p2": 200}
},
{
"name": "NotebookSimple2.2",
"path": "NotebookSimple2",
"timeoutPerCellInSeconds": 120,
"args": {"p1": "changed value 3", "p2": 300},
"retry": 1,
"retryIntervalInSeconds": 10,
"dependencies": ["NotebookSimple"] # list of activity names that this activity depends on
}
]
}
mssparkutils.notebook.runMultiple(DAG)
Note
- このメソッドは、 Azure Synapse Runtime for Apache Spark 3.3 および Azure Synapse Runtime for Apache Spark 3.4 でのみサポートされます。
- 複数のノートブック実行での並列処理の次数は、Spark セッションの使用可能なコンピューティング リソースの合計に制限されます。
ノートブックを終了する
値を指定してノートブックを終了します。 関数呼び出しの入れ子は、対話形式またはパイプラインで、ノートブックで実行できます。
exit() 関数をノートブックから対話形式で呼び出すと、Azure Synapse によって例外がスローされ、サブシーケンス セルの実行がスキップされて、Spark セッションが維持されます。
Synapse パイプラインで
exit()関数を呼び出す ノートブックを調整すると、Azure Synapse は終了値を返し、パイプラインの実行を完了して、Spark セッションを停止します。参照されているノートブックで
exit()関数を呼び出すと、Azure Synapse は参照されているノートブックでさらに実行を停止し、そのrun()関数を呼び出すノートブックで次のセルを続けて実行します。 たとえば、Notebook1 には 3 つのセルがあり、 2 番目のセルでexit()関数を呼び出します。 Notebook2 は 5 つのセルを持ち 、3 番目のセルにrun(notebook1)を呼び出します。 Notebook2 を実行すると、exit()関数がヒットしたときに 2 番目のセルで Notebook1 が停止します。 Notebook2 は、4 番目のセルと 5 番目のセルを引き続き実行します。
mssparkutils.notebook.exit("value string")
次に例を示します。
Sample1 ノートブックは次の 2 つのセルを持つ folder/ 下を検索します。
- セル 1 は、既定値が 10 に設定された 入力 パラメーターを定義します。
- セル2は、終了値として 入力 を使用してノートブック を終了します。
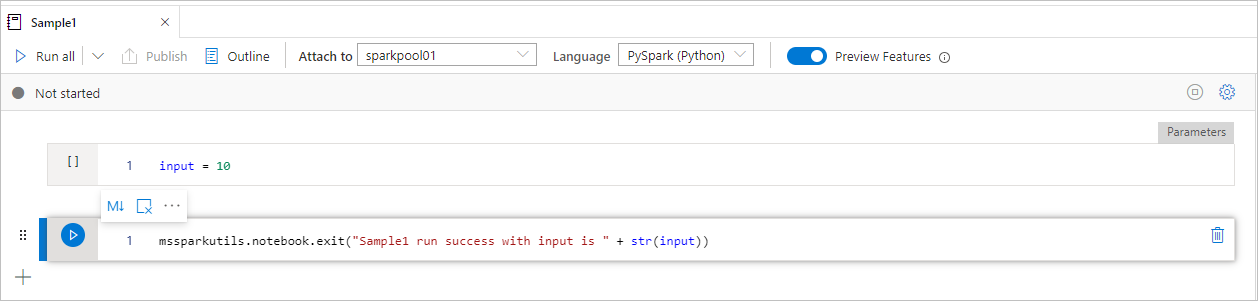
既定値を使用して、別のノートブックで Sample1 を実行できます。
exitVal = mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
結果は次のようになります。
Sample1 run success with input is 10
別のノートブックで Sample1 を実行して、入力値を 20 に設定できます。
exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print (exitVal)
結果は次のようになります。
Sample1 run success with input is 20
MSSparkUtils Notebook ユーティリティを使用して、ノートブックを実行したり、値を持つノートブックを終了したりできます。 次のコマンドを実行して、使用可能なメソッドの概要を取得します。
mssparkutils.notebook.help()
結果の取得:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
ノートブックの参照
ノートブックを参照し、その終了値を返します。 関数呼び出しの入れ子は、対話形式またはパイプラインで、ノートブックで実行できます。 参照されているノートブックは、ノートブックがこの機能を呼び出す Spark プールで実行されます。
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
次に例を示します。
mssparkutils.notebook.run("folder/Sample1", 90, Map("input" -> 20))
実行が完了すると、セルの出力に「ノートブックの実行の表示: "ノートブック名"」というスナップショット リンクが表示されます。このリンクをクリックすると、この特定の実行のスナップショットを表示できます。
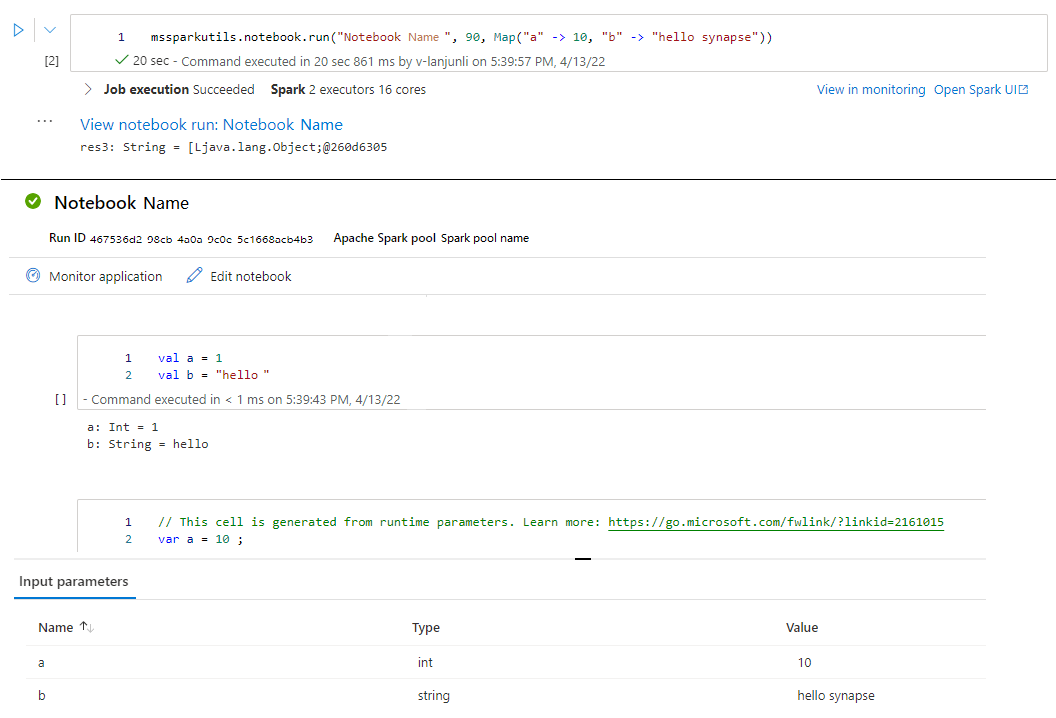
ノートブックを終了する
値を指定してノートブックを終了します。 関数呼び出しの入れ子は、対話形式またはパイプラインで、ノートブックで実行できます。
exit()関数ノートブックを対話形式で呼び出すと、Azure Synapse は例外をスローし、サブシーケンス セルの実行をスキップして、Spark セッションを維持します。Synapse パイプラインで
exit()関数を呼び出す ノートブックを調整すると、Azure Synapse は終了値を返し、パイプラインの実行を完了して、Spark セッションを停止します。参照されているノートブックで
exit()関数を呼び出すと、Azure Synapse は参照されているノートブックでさらに実行を停止し、そのrun()関数を呼び出すノートブックで次のセルを続けて実行します。 たとえば、Notebook1 には 3 つのセルがあり、 2 番目のセルでexit()関数を呼び出します。 Notebook2 は 5 つのセルを持ち 、3 番目のセルにrun(notebook1)を呼び出します。 Notebook2 を実行すると、exit()関数がヒットしたときに 2 番目のセルで Notebook1 が停止します。 Notebook2 は、4 番目のセルと 5 番目のセルを引き続き実行します。
mssparkutils.notebook.exit("value string")
次に例を示します。
Sample1 ノートブックは mssparkutils/folder/ 下にあり、以下の 2 つのセルを持ちます。
- セル 1 は、既定値が 10 に設定された 入力 パラメーターを定義します。
- セル2は、終了値として 入力 を使用してノートブック を終了します。
既定値を使用して、別のノートブックで Sample1 を実行できます。
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1")
print(exitVal)
結果は次のようになります。
exitVal: String = Sample1 run success with input is 10
Sample1 run success with input is 10
別のノートブックで Sample1 を実行して、入力値を 20 に設定できます。
val exitVal = mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, {"input": 20 })
print(exitVal)
結果は次のようになります。
exitVal: String = Sample1 run success with input is 20
Sample1 run success with input is 20
MSSparkUtils Notebook ユーティリティを使用して、ノートブックを実行したり、値を持つノートブックを終了したりできます。 次のコマンドを実行して、使用可能なメソッドの概要を取得します。
mssparkutils.notebook.help()
結果の取得:
The notebook module.
exit(value: String): void -> This method lets you exit a notebook with a value.
run(path: String, timeoutSeconds: int, arguments: Map): String -> This method runs a notebook and returns its exit value.
ノートブックの参照
ノートブックを参照し、その終了値を返します。 関数呼び出しの入れ子は、対話形式またはパイプラインで、ノートブックで実行できます。 参照されているノートブックは、ノートブックがこの機能を呼び出す Spark プールで実行されます。
mssparkutils.notebook.run("notebook path", <timeoutSeconds>, <parameterMap>)
次に例を示します。
mssparkutils.notebook.run("folder/Sample1", 90, list("input": 20))
実行が完了すると、セルの出力に「ノートブックの実行の表示: "ノートブック名"」というスナップショット リンクが表示されます。このリンクをクリックすると、この特定の実行のスナップショットを表示できます。
ノートブックを終了する
値を指定してノートブックを終了します。 関数呼び出しの入れ子は、対話形式またはパイプラインで、ノートブックで実行できます。
exit()関数ノートブックを対話形式で呼び出すと、Azure Synapse は例外をスローし、サブシーケンス セルの実行をスキップして、Spark セッションを維持します。Synapse パイプラインで
exit()関数を呼び出す ノートブックを調整すると、Azure Synapse は終了値を返し、パイプラインの実行を完了して、Spark セッションを停止します。参照されているノートブックで
exit()関数を呼び出すと、Azure Synapse は参照されているノートブックでさらに実行を停止し、そのrun()関数を呼び出すノートブックで次のセルを続けて実行します。 たとえば、Notebook1 には 3 つのセルがあり、 2 番目のセルでexit()関数を呼び出します。 Notebook2 は 5 つのセルを持ち 、3 番目のセルにrun(notebook1)を呼び出します。 Notebook2 を実行すると、exit()関数がヒットしたときに 2 番目のセルで Notebook1 が停止します。 Notebook2 は、4 番目のセルと 5 番目のセルを引き続き実行します。
mssparkutils.notebook.exit("value string")
次に例を示します。
Sample1 ノートブックは次の 2 つのセルを持つ folder/ 下を検索します。
- セル 1 は、既定値が 10 に設定された 入力 パラメーターを定義します。
- セル2は、終了値として 入力 を使用してノートブック を終了します。
既定値を使用して、別のノートブックで Sample1 を実行できます。
exitVal <- mssparkutils.notebook.run("folder/Sample1")
print (exitVal)
結果は次のようになります。
Sample1 run success with input is 10
別のノートブックで Sample1 を実行して、入力値を 20 に設定できます。
exitVal <- mssparkutils.notebook.run("mssparkutils/folder/Sample1", 90, list("input": 20))
print (exitVal)
結果は次のようになります。
Sample1 run success with input is 20
資格情報ユーティリティ
MSSparkUtils 資格情報ユーティリティを使用して、リンクされたサービスのアクセス トークンを取得し、Azure Key Vault でシークレットを管理することができます。
次のコマンドを実行して、使用可能なメソッドの概要を取得します。
mssparkutils.credentials.help()
mssparkutils.credentials.help()
Not supported.
mssparkutils.credentials.help()
結果を取得します。
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
注意
現在、C# では getSecretWithLS(linkedService, secret) はサポートされていません。
getToken(audience, name): returns AAD token for a given audience, name (optional)
isValidToken(token): returns true if token hasn't expired
getConnectionStringOrCreds(linkedService): returns connection string or credentials for linked service
getFullConnectionString(linkedService): returns full connection string with credentials
getPropertiesAll(linkedService): returns all the properties of a linked servicegetSecret(akvName, secret, linkedService): returns AKV secret for a given AKV linked service, akvName, secret key
getSecret(akvName, secret): returns AKV secret for a given akvName, secret key
getSecretWithLS(linkedService, secret): returns AKV secret for a given linked service, secret key
putSecret(akvName, secretName, secretValue, linkedService): puts AKV secret for a given akvName, secretName
putSecret(akvName, secretName, secretValue): puts AKV secret for a given akvName, secretName
putSecretWithLS(linkedService, secretName, secretValue): puts AKV secret for a given linked service, secretName
トークンを取得する
指定された対象ユーザー、名前 (省略可能) の Microsoft Entra トークンを返します。 次の表に、使用可能なすべての対象ユーザーの種類を示します。
| 対象ユーザーの種類 | API 呼び出しで使用される文字列リテラル |
|---|---|
| Azure Storage | Storage |
| Azure Key Vault | Vault |
| Azure の管理 | AzureManagement |
| Azure SQL Data Warehouse (専用およびサーバーレス) | DW |
| Azure Synapse | Synapse |
| Azure Data Lake Store | DataLakeStore |
| Azure Data Factory | ADF |
| Azure Data Explorer | AzureDataExplorer |
| Azure Database for MySQL | AzureOSSDB |
| Azure Database for MariaDB | AzureOSSDB |
| Azure Database for PostgreSQL | AzureOSSDB |
mssparkutils.credentials.getToken('audience Key')
mssparkutils.credentials.getToken("audience Key")
Credentials.GetToken("audience Key")
mssparkutils.credentials.getToken('audience Key')
トークンの検証
トークンの有効期限が切れていない場合は true を返します。
mssparkutils.credentials.isValidToken('your token')
mssparkutils.credentials.isValidToken("your token")
Credentials.IsValidToken("your token")
mssparkutils.credentials.isValidToken('your token')
リンクされたサービスの接続文字列または資格情報の取得
リンクされたサービスの接続文字列または資格情報を返します。
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
mssparkutils.credentials.getConnectionStringOrCreds("linked service name")
Credentials.GetConnectionStringOrCreds("linked service name")
mssparkutils.credentials.getConnectionStringOrCreds('linked service name')
ワークスペース ID を使用したシークレットの取得
ワークスペース ID を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを返します。 Azure Key Vault へのアクセスが適切に構成されていることを確認してください。
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
mssparkutils.credentials.getSecret("azure key vault name","secret name","linked service name")
Credentials.GetSecret("azure key vault name","secret name","linked service name")
mssparkutils.credentials.getSecret('azure key vault name','secret name','linked service name')
ユーザー資格情報を使用したシークレットの取得
ユーザー資格情報を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを返します。
mssparkutils.credentials.getSecret('azure key vault name','secret name')
mssparkutils.credentials.getSecret("azure key vault name","secret name")
Credentials.GetSecret("azure key vault name","secret name")
mssparkutils.credentials.getSecret('azure key vault name','secret name')
ワークスペース ID を使用したシークレットの作成
ワークスペース ID を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを作成します。 Azure Key Vault へのアクセスが適切に構成されていることを確認してください。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
ワークスペース ID を使用したシークレットの作成
ワークスペース ID を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを作成します。 Azure Key Vault へのアクセスが適切に構成されていることを確認してください。
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value","linked service name")
ワークスペース ID を使用したシークレットの作成
ワークスペース ID を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを作成します。 Azure Key Vault へのアクセスが適切に構成されていることを確認してください。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value','linked service name')
ユーザー資格情報を使用したシークレットの作成
ユーザー資格情報を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを作成します。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
ユーザー資格情報を使用したシークレットの作成
ユーザー資格情報を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを作成します。
mssparkutils.credentials.putSecret('azure key vault name','secret name','secret value')
ユーザー資格情報を使用したシークレットの作成
ユーザー資格情報を使用して、指定した Azure Key Vault 名、シークレット名、およびリンクされたサービス名の Azure Key Vault シークレットを作成します。
mssparkutils.credentials.putSecret("azure key vault name","secret name","secret value")
環境ユーティリティ
次のコマンドを実行して、使用可能なメソッドの概要を取得します。
mssparkutils.env.help()
mssparkutils.env.help()
mssparkutils.env.help()
Env.Help()
結果を取得します。
getUserName(): returns user name
getUserId(): returns unique user id
getJobId(): returns job id
getWorkspaceName(): returns workspace name
getPoolName(): returns Spark pool name
getClusterId(): returns cluster id
ユーザー名の取得
現在のユーザー名を返します。
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
mssparkutils.env.getUserName()
Env.GetUserName()
ユーザー ID の取得
現在のユーザー ID を返します。
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
mssparkutils.env.getUserId()
Env.GetUserId()
ジョブ ID の取得
ジョブ ID を返します。
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
mssparkutils.env.getJobId()
Env.GetJobId()
ワークスペース名の取得
ワークスペース名を返します。
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
mssparkutils.env.getWorkspaceName()
Env.GetWorkspaceName()
プール名の取得
Spark プール名を返します。
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
mssparkutils.env.getPoolName()
Env.GetPoolName()
クラスター ID の取得
現在のクラスター ID を返します。
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
mssparkutils.env.getClusterId()
Env.GetClusterId()
ランタイム コンテキスト
mssparkutils ランタイム ユーティリティでは、3 つのランタイム プロパティを公開しています。mssparkutils ランタイム コンテキストを使用して、下に示すプロパティを取得できます。
- Notebookname - 現在のノートブックの名前では常に、対話モードとパイプライン モードの両方の値を返します。
- Pipelinejobid - パイプライン実行 ID では、パイプライン モードで値を返し、対話モードで空の文字列を返します。
- Activityrunid - ノートブック アクティビティの実行 ID では、パイプライン モードで値を返し、対話モードで空の文字列を返します。
現在、ランタイム コンテキストでは Python と Scala の両方をサポートしています。
mssparkutils.runtime.context
ctx <- mssparkutils.runtime.context()
for (key in ls(ctx)) {
writeLines(paste(key, ctx[[key]], sep = "\t"))
}
%%spark
mssparkutils.runtime.context
セッションの管理
対話型セッションの停止
停止ボタンを手動でクリックする代わりに、コードで API を呼び出して対話型セッションを停止する方が便利な場合があります。 このような場合のために、コードを介した対話型セッションの停止をサポートする API mssparkutils.session.stop() が提供されています。Scala と Python で使用できます。
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop()
mssparkutils.session.stop() API は、バックグラウンドで現在の対話型セッションを非同期的に停止し、Spark セッションを停止し、セッションによって占有されているリソースを解放して、同じプール内の他のセッションで使用できるようにします。
Note
Scala の sys.exit や Python のsys.exit() などの言語組み込み API をコードで呼び出すことはお勧めしません。このような API はインタープリター プロセスを強制終了するだけで、Spark セッションは有効なまま残り、リソースは解放されないためです。
パッケージの依存関係
ノートブックまたはジョブをローカルで開発し、コンパイル/IDE ヒントに関連するパッケージを参照する必要がある場合は、次のパッケージを使用できます。