Azure Synapse Analytics の Apache Spark とは
Apache Spark は、ビッグ データ分析アプリケーションのパフォーマンスを向上させるメモリ内処理をサポートする並列処理フレームワークです。 Azure Synapse Analytics の Apache Spark は、Apache Spark を Microsoft がクラウドに実装したものです。 Azure Synapse では、サーバーレス Apache Spark プールを Azure に簡単に作成して構成することができます。 Azure Synapse の Spark プールは、Azure Storage および Azure Data Lake Generation 2 ストレージと互換性があります。 そのため、Spark プールを使用して、Azure に格納されているデータを処理することができます。
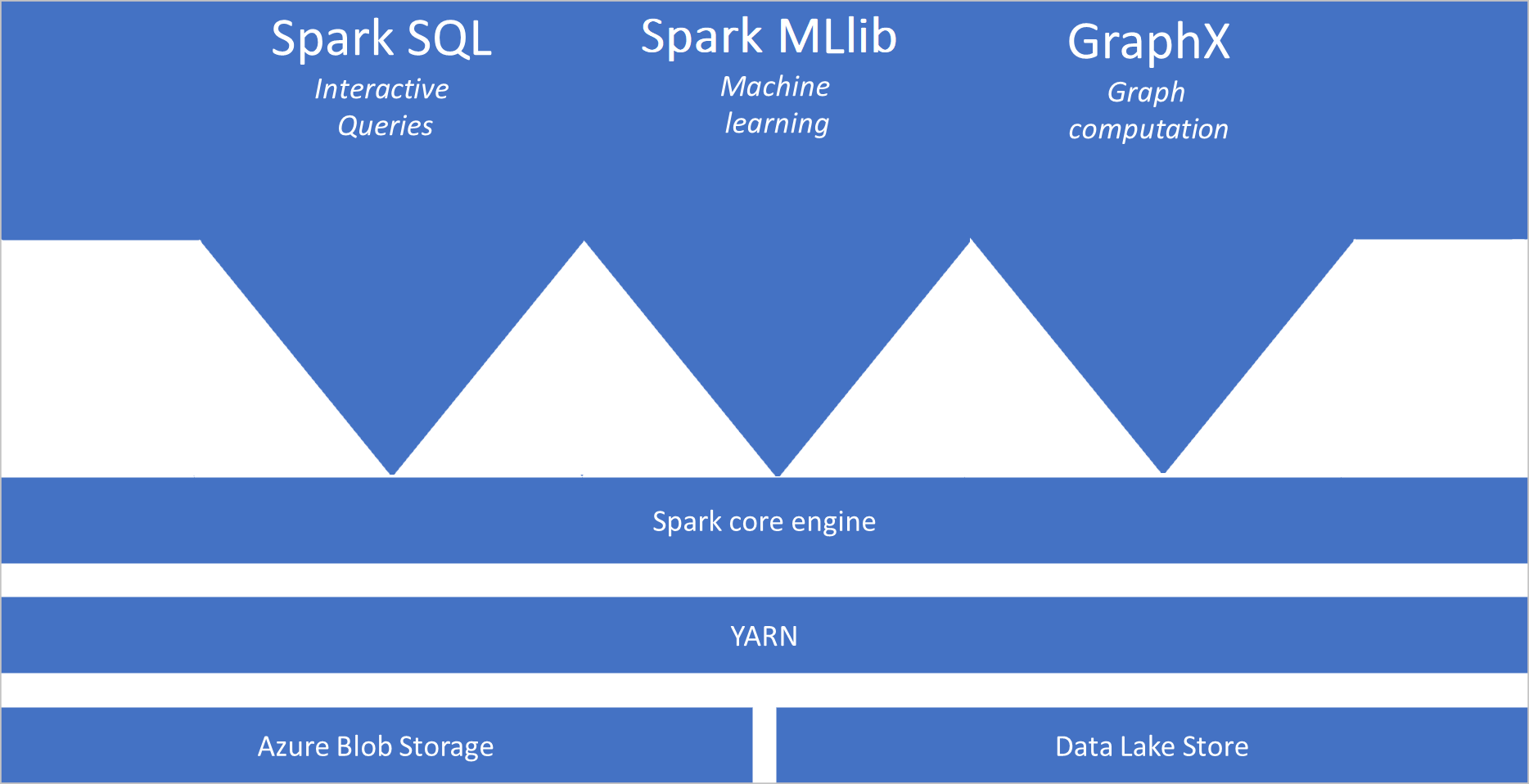
Apache Spark とは
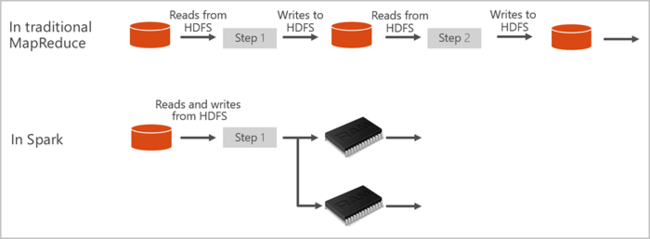
Apache Spark には、クラスターの計算処理をインメモリで行うための基本的な要素が備わっています。 Spark ジョブは、データをメモリに読み込んでキャッシュし、それを繰り返しクエリできます。 メモリ内計算は、ディスクベースのアプリケーションよりも高速です。 また Spark は、さまざまなプログラミング言語との親和性が高く、分散データ セットをローカル コレクションのように扱うことができます。 計算内容をすべて map 処理と reduce 処理に分ける必要がありません。 詳細については、「Apache Spark for Synapse」の動画を参照してください。
Azure Synapse の Spark プールでは、フル マネージドの Spark サービスを利用できます。 以下の一覧は、Azure Synapse Analytics で Spark プールを作成する利点をまとめたものです。
| 特徴量 | 説明 |
|---|---|
| スピードと効率 | Spark インスタンスの起動時間は、60 ノード未満の場合で約 2 分、それより多いの場合には約 5 分となります。 インスタンスの既定のシャットダウン時間は、ノートブック接続によって維持される場合を除き、最後のジョブ実行から 5 分後です。 |
| 作成のしやすさ | Azure Synapse には、Azure portal、Azure PowerShell、Synapse Analytics .NET SDK のいずれかを使用して新しい Spark プールを数分で作成できます。 Azure Synapse Analytics の Spark プールの概要に関するページを参照してください。 |
| 使いやすさ | Synapse Analytics には、nteract から派生したカスタム ノートブックが含まれています。 対話型のデータ処理と視覚化にこれらの Notebook を使用できます。 |
| REST API | Azure Synapse Analytics の Spark には、ジョブの送信と監視をリモートで実行する REST API ベースの Spark ジョブ サーバーである Apache Livy が含まれています。 |
| Azure Data Lake Storage Generation 2 のサポート | Azure Synapse の Spark プールでは、Azure Data Lake Storage Gen2 と BLOB ストレージを使用できます。 Data Lake Store の詳細については、「Azure Data Lake Storage の概要」を参照してください |
| サード パーティ製 IDE との統合 | Azure Synapse には、アプリケーションを作成して Spark プールに送信するうえで役立つ JetBrains の IntelliJ IDEA 用 IDE プラグインが用意されています。 |
| 読み込み済みの Anaconda ライブラリ | Azure Synapse の Spark プールには、プレインストールされた Anaconda ライブラリが付属しています。 Anaconda は、機械学習、データ分析、視覚化などのテクノロジための 200 個近いライブラリを提供します。 |
| スケーラビリティ | Azure Synapse プールの Apache Spark で自動スケールを有効にすると、必要に応じてノードを追加したり削除したりすることによって、プールをスケーリングすることができます。 また、すべてのデータは Azure Storage または Data Lake Storage に格納されるため、Spark プールはデータの損失なしでシャットダウンできます。 |
Azure Synapse の Spark プールには、プールで既定で利用できる次のコンポーネントが含まれています。
- Spark Core。 Spark Core、Spark SQL、GraphX、MLlib が含まれます。
- Anaconda
- Apache Livy
- nteract ノートブック
Spark プールのアーキテクチャ
Spark アプリケーションは、"ドライバー プログラム" と呼ばれる、メイン プログラムの SparkContext オブジェクトによって調整される、独立したプロセスのセットとしてプールで実行されます。
SparkContext は、アプリケーション間でリソースを割り当てるクラスター マネージャーに接続できます。 クラスター マネージャーは Apache Hadoop YARN です。 接続されると、Spark はプール内のノードで Executor を取得します。Executor は、アプリケーションの計算を実行し、データを格納するプロセスです。 次に、SparkContext に渡される JAR または Python ファイルで定義されたアプリケーション コードを Executor に送信します。 最後に、SparkContext はタスクを Executor に送信して実行させます。
SparkContext は、ユーザーの main 関数を実行し、ノードでさまざまな並列処理を実行します。 その後、SparkContext は各操作の結果を収集します。 ノードによるデータの読み取りと書き込みは、ファイル システムとの間で行われます。 また、ノードは、変換後のデータを Resilient Distributed Dataset (RDD) としてメモリ内にキャッシュします。
SparkContext は Spark プールに接続し、アプリケーションを有向非巡回グラフ (DAG) に変換する処理を担います。 グラフは、ノードの Executor プロセス内で実行される個々のタスクで構成されます。 アプリケーションはそれぞれ独自の Executor プロセスを取得します。これらは、アプリケーションが終了するまで稼働し続けながら、複数のスレッドでタスクを実行します。
Azure Synapse Analytics での Apache Spark のユース ケース
Azure Synapse Analytics の Spark プールでは、以下に挙げる主なシナリオを実現できます。
- Data Engineering とデータ準備
Apache Spark には、大量データの準備と処理をサポートする多くの言語機能が含まれているため、データの価値を高め、それを Azure Synapse Analytics 内の他のサービスから利用することができます。 これは、複数の言語 (C#、Scala、PySpark、Spark SQL) と、処理および接続を目的に提供されているライブラリによって実現されています。
- Machine Learning
Apache Spark には、Spark を基に作成された機械学習ライブラリである MLlib が付属し、Azure Synapse Analytics の Spark プールから使用できます。 Azure Synapse Analytics の Spark プールには、Anaconda も含まれています。これは、機械学習を始めとするデータ サイエンス用のさまざまなパッケージを含む Python ディストリビューションです。 ノートブックの組み込みサポートを併用すれば、機械学習アプリケーションを作成するための環境が得られます。
- データのストリーミング
Synapse Spark が Spark Structured Streaming をサポートするのは、利用者がサポートされているバージョンの Azure Synapse Spark ランタイム リリースを実行している場合に限ります。 すべてのジョブは 7 日間稼働できます。 これはバッチ ジョブとストリーミング ジョブの両方に適用され、通常、お客様は Azure Functions を使用して再起動プロセスを自動化します。
関連するコンテンツ
Azure Synapse Analytics の Apache Spark の詳細については、次の記事を参照してください。
- クイック スタート: Azure Synapse の Spark プールを作成する
- クイック スタート: Apache Spark ノートブックを作成する
- チュートリアル:Apache Spark を使用した機械学習
Note
Apache Spark の公式ドキュメントの一部では、Spark コンソールの使用を前提としていますが、これは Azure Synapse Spark では利用できません。 代わりに、ノートブックまたは IntelliJ のエクスペリエンスを使用してください。