Azure Synapse Analytics でのファイル マウント API とファイル マウント解除 API の概要
Azure Synapse Studio チームは、Microsoft Spark Utilities (mssparkutils) パッケージに 2 つの新しいマウントおよびマウント解除 API を構築しました。 これらの API を使って、すべての作業ノード (ドライバー ノードとワーカー ノード) にリモート ストレージ (Azure Blob Storage、Azure Data Lake Storage Gen2) をアタッチできます。 ストレージを配置した後は、ローカル ファイル API を使って、ローカル ファイル システムに格納されているかのようにデータにアクセスできます。 詳細については、「Microsoft Spark Utilities の概要」をご覧ください。
この記事では、ワークスペースでマウントおよびマウント解除 API を使う方法について説明します。 学習内容:
- Data Lake Storage Gen2 または Blob Storage をマウントする方法。
- ローカル ファイル システム API を使ってマウント ポイントの下にあるファイルにアクセスする方法。
-
mssparkutils fsAPI を使ってマウント ポイントの下にあるファイルにアクセスする方法。 - Spark 読み取り API を使ってマウント ポイントの下にあるファイルにアクセスする方法。
- マウント ポイントのマウントを解除する方法。
警告
Azure ファイル共有のマウントは、一時的に無効にされます。 次のセクションで説明するように、代わりに Data Lake Storage Gen2 または Azure Blob Storage のマウントを使用できます。
Azure Data Lake Storage Gen1 ストレージはサポートされていません。 マウント API を使う前に、Azure Data Lake Storage Gen1 から Gen2 への移行ガイダンスに関する記事に従って、Data Lake Storage Gen2 に移行できます。
ストレージをマウントする
このセクションでは、例として Data Lake Storage Gen2 をマウントする手順を示します。 Blob Storage のマウントも同様に機能します。
この例では、storegen2 という名前の 1 つの Data Lake Storage Gen2 アカウントがあるとします。 そのアカウントには mycontainer という名前のコンテナーが 1 つあり、それを Spark プールの /test にマウントします。
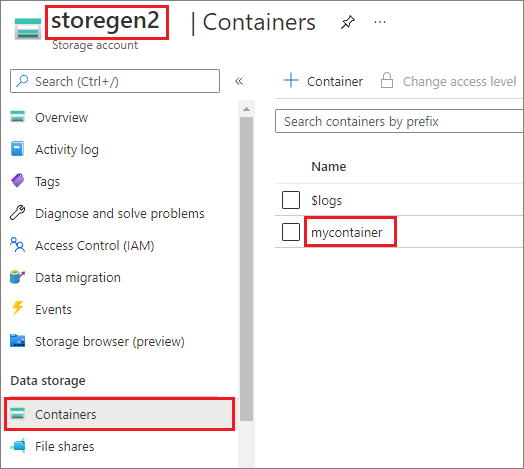
mycontainer という名前のコンテナーをマウントするには、mssparkutils で最初に、ユーザーがコンテナーにアクセスするためのアクセス許可を持っているかどうかを調べる必要があります。 現在、Azure Synapse Analytics でトリガー マウント操作に対してサポートされている認証方法は、linkedService、accountKey、sastoken の 3 つです。
リンク サービスを使ってマウントする (推奨)
リンク サービスによるトリガー マウントをお勧めします。 この方法を使うと、mssparkutils でシークレットや認証値自体が格納されないため、セキュリティ リークが避けられます。 代わりに、mssparkutils は常にリンク サービスから認証値をフェッチして、リモート ストレージに BLOB データを要求します。
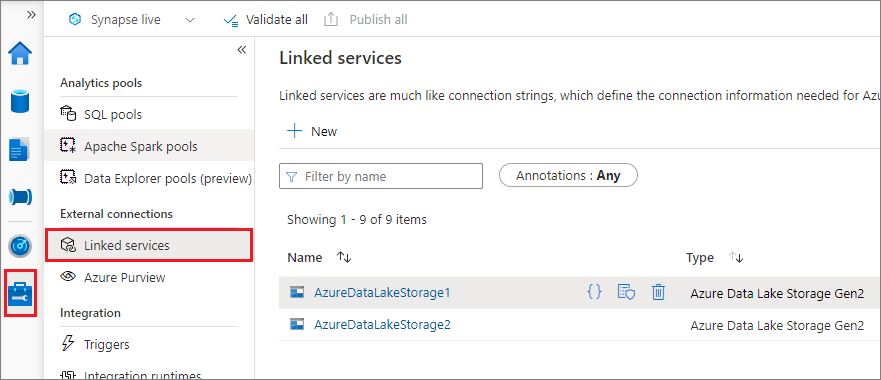
Data Lake Storage Gen2 または Blob Storage のリンク サービスを作成できます。 現在、Azure Synapse Analytics では、リンク サービスを作成するときに 2 つの認証方法がサポートされています。
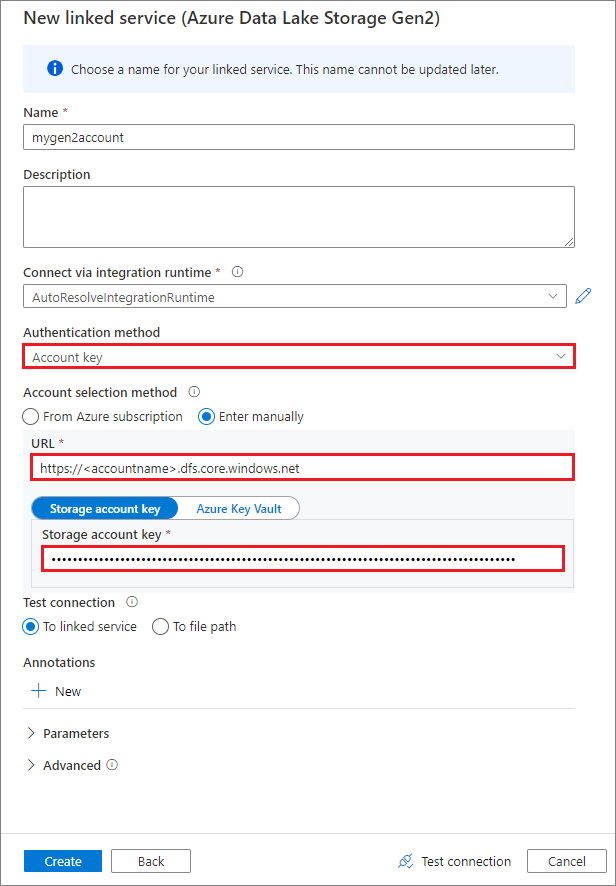
アカウント キーを使ってリンク サービスを作成する
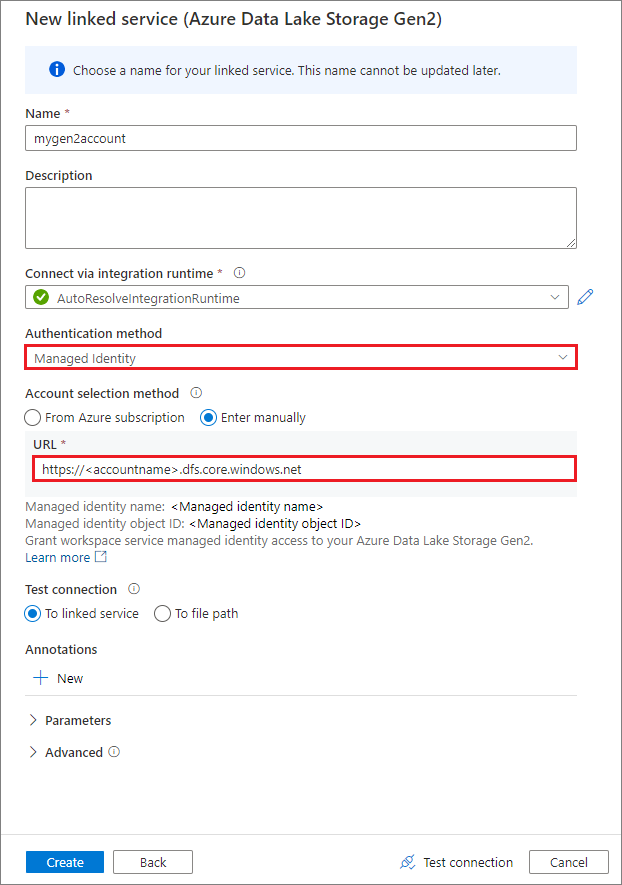
システム割り当てマネージド ID を使用してリンクされたサービスを作成する
重要
- 上記で作成した Azure Data Lake Storage Gen2 への Linked Service がマネージド プライベート エンドポイント (dfs URI を使用) を使用する場合、内部の fsspec/adlfs コードが BlobServiceClient インターフェイスを使用して接続できるように、Azure Blob Storage オプション (BLOB URI を使用) を使用した別のセカンダリ マネージド プライベート エンドポイントを作成する必要があります。
- セカンダリ マネージド プライベート エンドポイントが正しく構成されていない場合、ServiceRequestError: Cannot connect to host [storageaccountname].blob.core.windows.net:443 ssl:True [Name or service not known] のようなエラー メッセージが表示されます
注意
認証方法としてマネージド ID を使ってリンク サービスを作成する場合は、ワークスペースの MSI ファイルに、マウントされるコンテナーのストレージ BLOB データ共同作成者ロールがあることを確認します。
リンク サービスを正常に作成したら、次の Python コードを使って、コンテナーを Spark プールに簡単にマウントできます。
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
注意
mssparkutils を使用できない場合、それをインポートすることが必要な場合があります。
from notebookutils import mssparkutils
使用する認証方法に関係なく、ルート フォルダーをマウントすることはお勧めしません。
マウント パラメーター:
- fileCacheTimeout: BLOB は、ローカルの一時フォルダーに既定で 120 秒間キャッシュされます。 この間、blobfuse では、ファイルが最新であるかどうかの確認は行われません。 必要に応じて、パラメーターの指定により既定のタイムアウト時間を変更できます。 複数のクライアントから同時にファイルの変更操作が行われる場合は、ローカル ファイルとリモート ファイルとの間に不整合が発生するのを避けるために、キャッシュ時間を短縮するか 0 に設定し、常にサーバーから最新のファイルが取得されるようにすることをお勧めします。
- timeout: マウント操作のタイムアウトは、デフォルトで 120 秒です。 必要に応じて、パラメーターの指定により既定のタイムアウト時間を変更できます。 Executor が多すぎる場合や、マウントのタイムアウトが発生する場合は、値を大きくすることをお勧めします。
- scope: scope パラメーターは、マウントのスコープを指定する場合に使います。 既定値は "job" です。スコープが "job" に設定されている場合、マウントは現在のクラスターにのみ表示されます。 スコープが "workspace" に設定されている場合、マウントは現在のワークスペース内にあるすべてのノートブックに表示されます。また、マウント ポイントは、なければ自動的に作成されます。 マウント ポイントをマウント解除するには、同じパラメーターをマウント解除 API に追加します。 ワークスペース レベルのマウントは、リンク サービス認証でのみサポートされます。
これらのパラメーターの使用例を示します。
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Shared Access Signature トークンまたはアカウント キーを使ってマウントする
リンク サービスによるマウントだけでなく、mssparkutils では、アカウント キーまたは Shared Access Signature (SAS) トークンをパラメーターとして明示的に渡してターゲットをマウントすることがサポートされています。
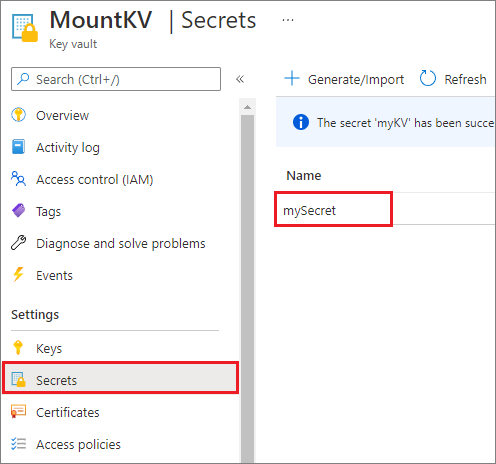
セキュリティ上の理由から、アカウント キーまたは SAS トークンを Azure Key Vault に格納することをお勧めします (次に示すスクリーンショットはその例です)。 その後、mssparkutil.credentials.getSecret API を使って取得できます。 詳細については、「Key Vault と Azure CLI を使用してストレージ アカウント キーを管理する (レガシ)」を参照してください。
コード例を次に示します。
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
注意
セキュリティ上の理由から、資格情報をコードに格納しないでください。
mssparkutils fs API を使ってマウント ポイントの下にあるファイルにアクセスする
マウント操作の主な目的は、ユーザーがローカル ファイル システムの API を使って、リモート ストレージ アカウントに格納されているデータにアクセスできるようすることです。 また、mssparkutils fs API を使用し、マウントされたパスをパラメーターで指定して、データにアクセスすることもできます。 ここで使用するパスの形式は少し異なります。
Data Lake Storage Gen2 コンテナー mycontainer をマウント API を使用して /test にマウントしたとします。 ローカル ファイル システム API を使用してデータにアクセスする場合:
- 3.3 以下の Spark バージョンの場合、パス形式は
/synfs/{jobId}/test/{filename}。 - 3.4 以上の Spark バージョンの場合、パス形式は
/synfs/notebook/{jobId}/test/{filename}。
正確なパスを取得するには、mssparkutils.fs.getMountPath() を使うことをお勧めします。
path = mssparkutils.fs.getMountPath("/test")
Note
workspaceスコープでストレージをマウントすると、マウント ポイントが /synfs/workspace フォルダーの下に作成されます。 正確なパスを取得するには、 mssparkutils.fs.getMountPath("/test", "workspace") を使用する必要があります。
mssparkutils fs API を使用してデータにアクセスする場合、パス形式は次のようになります: synfs:/notebook/{jobId}/test/{filename}。 この場合の synfs は、マウントされたパスの一部ではなく、スキーマとして使われていることがわかります。 もちろん、ローカル ファイル システム スキーマを使用してデータにアクセスすることもできます。 たとえば、file:/synfs/notebook/{jobId}/test/{filename} のようにします。
次の 3 つの例では、mssparkutils fs を使ってマウント ポイント パスでファイルにアクセスする方法を示します。
ディレクトリのリストを取得します。
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')ファイルの内容を読み取ります。
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')ディレクトリを作成します。
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Spark 読み取り API を使ってマウント ポイントの下にあるファイルにアクセスする
Spark 読み取り API を使って、データにアクセスするためのパラメーターを指定できます。 ここでのパス形式は、 mssparkutils fs API を使用する場合と同じです。
マウントされた Data Lake Storage Gen2 ストレージ アカウントからファイルを読み取る
次の例では、Data Lake Storage Gen2 ストレージ アカウントが既にマウントされているものとし、マウント パスを使ってファイルを読み取ります。
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Note
リンク サービスを使ってストレージをマウントする場合、データへのアクセスに synfs スキーマを使うには、必ず spark リンク サービス構成を明示的に設定する必要があります。 詳細については、リンク サービスの ADLS Gen2 ストレージに関するセクションを参照してください。
マウントされた Blob Storage アカウントからファイルを読み取る
Blob Storage アカウントをマウントした場合に、mssparkutils または Spark API を使ってそれにアクセスするには、マウント API を使ってコンテナーをマウントする前に、Spark の構成で SAS トークンを明示的に構成する必要があります。
トリガー マウントの後で
mssparkutilsまたは Spark API を使って Blob Storage アカウントにアクセスするには、次のコード例に示すように Spark の構成を更新します。 マウントの後でローカル ファイル API だけを使って Spark の構成にアクセスする場合は、このステップをバイパスできます。blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)リンク サービス
myblobstorageaccountを作成し、リンク サービスを使用して Blob Storage アカウントをマウントします。%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Blob Storage コンテナーをマウントした後、ローカル ファイル API でマウント パスを使ってファイルを読み取ります。
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Spark 読み取り API を使って、マウントされた Blob Storage コンテナーからデータを読み取ります。
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
マウント パスのマウントを解除する
マウント ポイント (この例では /test) をマウント解除するには、次のコードを使います。
mssparkutils.fs.unmount("/test")
既知の制限事項
マウント解除メカニズムは自動ではありません。 アプリケーションの実行が完了したときに、マウント ポイントをマウント解除してディスク領域を解放するには、コードでマウント解除 API を明示的に呼び出す必要があります。 そうしないと、マウント ポイントは、アプリケーションの実行が完了した後もノードに存在します。
Data Lake Storage Gen1 ストレージ アカウントのマウントは現在サポートされていません。