Azure Log Analytics を使用して Apache Spark アプリケーションを監視する
このチュートリアルでは、Log Analytics に組み込まれている Synapse Studio コネクタを有効にする方法について説明します。 その後、Apache Spark アプリケーションのメトリックとログを収集し、Log Analytics ワークスペースに送信できます。 最後に、Azure Monitor ブックを利用してメトリックとログを視覚化できます。
ワークスペース情報を構成する
次の手順に従って、Synapse Studio で必要な情報を構成します。
手順 1: Log Analytics ワークスペースを作成する
次のいずれかのリソースを参照して、ワークスペースを作成します。
- Azure portal でワークスペースを作成します。
- Azure CLI を使用してワークスペースを作成します。
- PowerShell を使用して Azure Monitor でワークスペースを作成して構成します。
手順 2: Apache Spark 構成ファイルを準備する
次のいずれかのオプションを使用して、ファイルを準備します。
オプション 1: Log Analytics ワークスペースの ID とキーを使用して構成する
次の Apache Spark 構成をコピーして spark_loganalytics_conf.txt として保存し、パラメーターを入力します。
<LOG_ANALYTICS_WORKSPACE_ID>: Log Analytics ワークスペース の ID。<LOG_ANALYTICS_WORKSPACE_KEY>: Log Analytics のキー。 これを見つけるには、Azure portal で [Azure Log Analytics ワークスペース]>[エージェント]>[プライマリ キー] に移動します。
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.secret <LOG_ANALYTICS_WORKSPACE_KEY>
オプション 2: Azure Key Vault を使用して構成する
Note
Apache Spark アプリケーションを送信するユーザーにシークレットの読み取りアクセス許可を付与する必要があります。 詳細については、「Azure のロールベースのアクセス制御を使用して Key Vault のキー、証明書、シークレットへのアクセス権を付与する」を参照してください。 Synapse パイプラインでこの機能を有効にする場合は、オプション 3 を使用する必要があります。 これは、ワークスペースのマネージド ID を使用して Azure Key Vault からシークレットを取得するために必要です。
ワークスペース キーを格納するよう Azure Key Vault を構成するには、次の手順に従います。
Azure portal でキー コンテナーを作成し、そこに移動します。
キー コンテナーの設定ページで、 [シークレット] を選択します。
[Generate/Import](生成/インポート) を選択します。
[シークレットの作成] 画面で、次の値を選択します。
- 名前: シークレットの名前を入力します。 既定値として、「
SparkLogAnalyticsSecret」と入力します。 - 値: シークレットの
<LOG_ANALYTICS_WORKSPACE_KEY>を入力します。 - 他の値は既定値のままにしておきます。 [作成] を選択します。
- 名前: シークレットの名前を入力します。 既定値として、「
次の Apache Spark 構成をコピーして spark_loganalytics_conf.txt として保存し、パラメーターを入力します。
<LOG_ANALYTICS_WORKSPACE_ID>: Log Analytics ワークスペース ID。<AZURE_KEY_VAULT_NAME>: 構成したキー コンテナーの名前。<AZURE_KEY_VAULT_SECRET_KEY_NAME>(省略可能): ワークスペース キーのキー コンテナー内のシークレット名。 既定値は、SparkLogAnalyticsSecretです。
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
Note
ワークスペース ID を Key Vault に格納することもできます。 上記の手順を参照し、ワークスペース ID をシークレット名 SparkLogAnalyticsWorkspaceId を使用して格納してください。 または、構成 spark.synapse.logAnalytics.keyVault.key.workspaceId を使用して、Key Vault でワークスペース ID のシークレット名を指定することもできます。
方法 3. リンク サービスを使用した構成
注意
このオプションでは、ワークスペースのマネージド ID にシークレットの読み取りアクセス許可を付与する必要があります。 詳細については、「Azure のロールベースのアクセス制御を使用して Key Vault のキー、証明書、シークレットへのアクセス権を付与する」を参照してください。
Synapse Studio で Key Vault のリンク サービスを構成してワークスペース キーを格納するには、次の手順に従います。
前のセクション「オプション 2」に記載されているすべての手順を実行します。
Synapse Studio で Key Vault のリンク サービスを作成します。
a. [Synapse Studio]>[管理]>[リンク サービス] に移動し、 [新規] を選択します。
b. 検索ボックスで Azure Key Vault を検索します。
c. リンク サービスの名前を入力します。
d. キー コンテナーを選択し、 [作成] を選択します。
Apache Spark 構成に
spark.synapse.logAnalytics.keyVault.linkedServiceName項目を追加します。
spark.synapse.logAnalytics.enabled true
spark.synapse.logAnalytics.workspaceId <LOG_ANALYTICS_WORKSPACE_ID>
spark.synapse.logAnalytics.keyVault.name <AZURE_KEY_VAULT_NAME>
spark.synapse.logAnalytics.keyVault.key.secret <AZURE_KEY_VAULT_SECRET_KEY_NAME>
spark.synapse.logAnalytics.keyVault.linkedServiceName <LINKED_SERVICE_NAME>
Apache Spark の構成一覧については、「使用可能な Apache Spark 構成」を参照してください
手順 3: Apache Spark 構成を Apache Spark プールにアップロードする
注意
この手順は、手順 4 に置き換えられます。
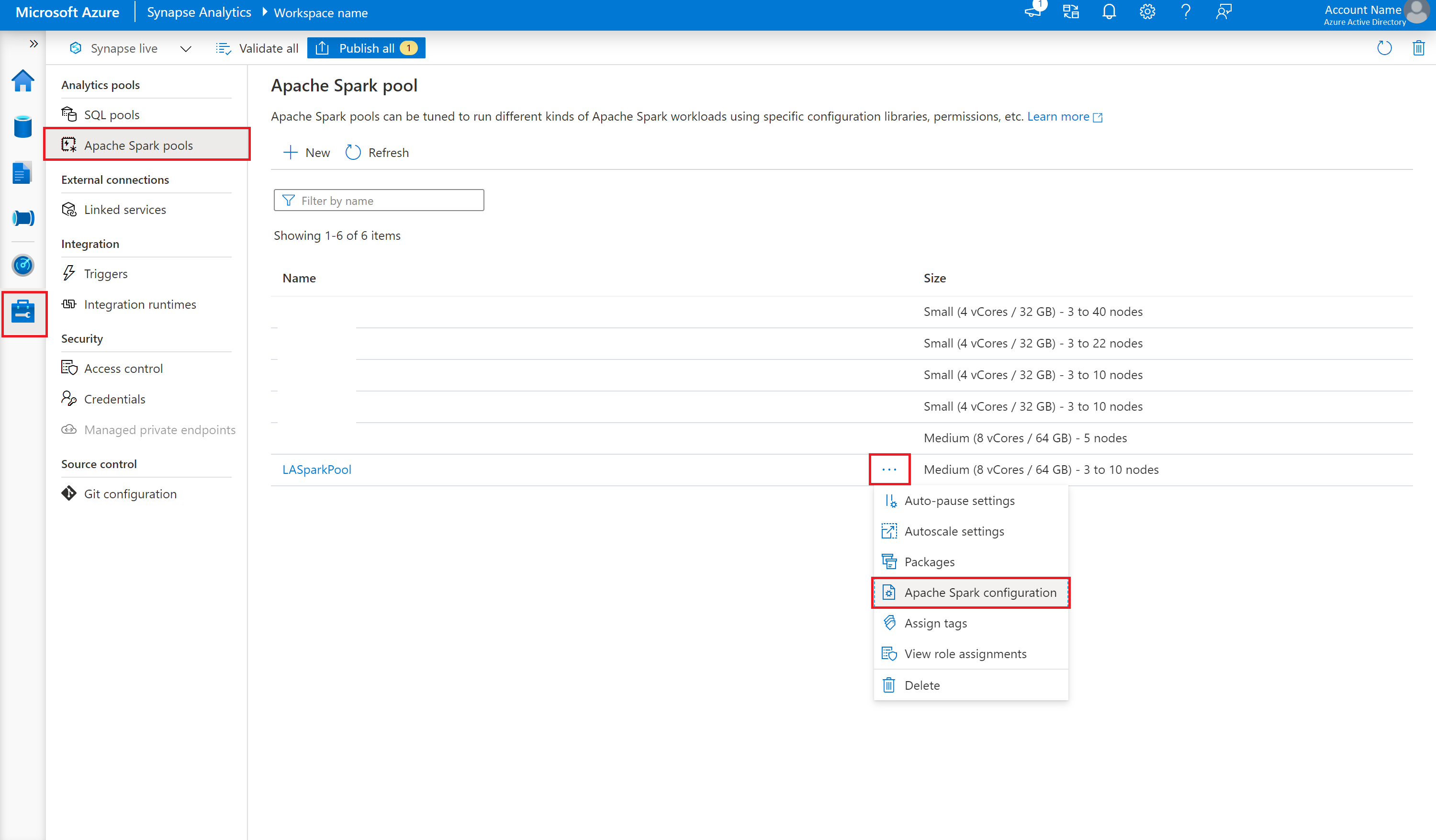
構成ファイルは、Azure Synapse Analytics Apache Spark プールにアップロードできます。 Synapse Studio で次のようにします。
[管理]>[Apache Spark プール] を選択します
Apache Spark プールの横にある [...] ボタンを選択します。
[Apache Spark 構成] を選択します。
[アップロード] を選択し、spark_loganalytics_conf.txt ファイルを選択します。
[アップロード] を選択し、 [適用] を選択します。
Note
Apache Spark プールに送信されたすべての Apache Spark アプリケーションでは、この構成設定を使用して、指定したワークスペースに Apache Spark アプリケーションのメトリックとログがプッシュされます。
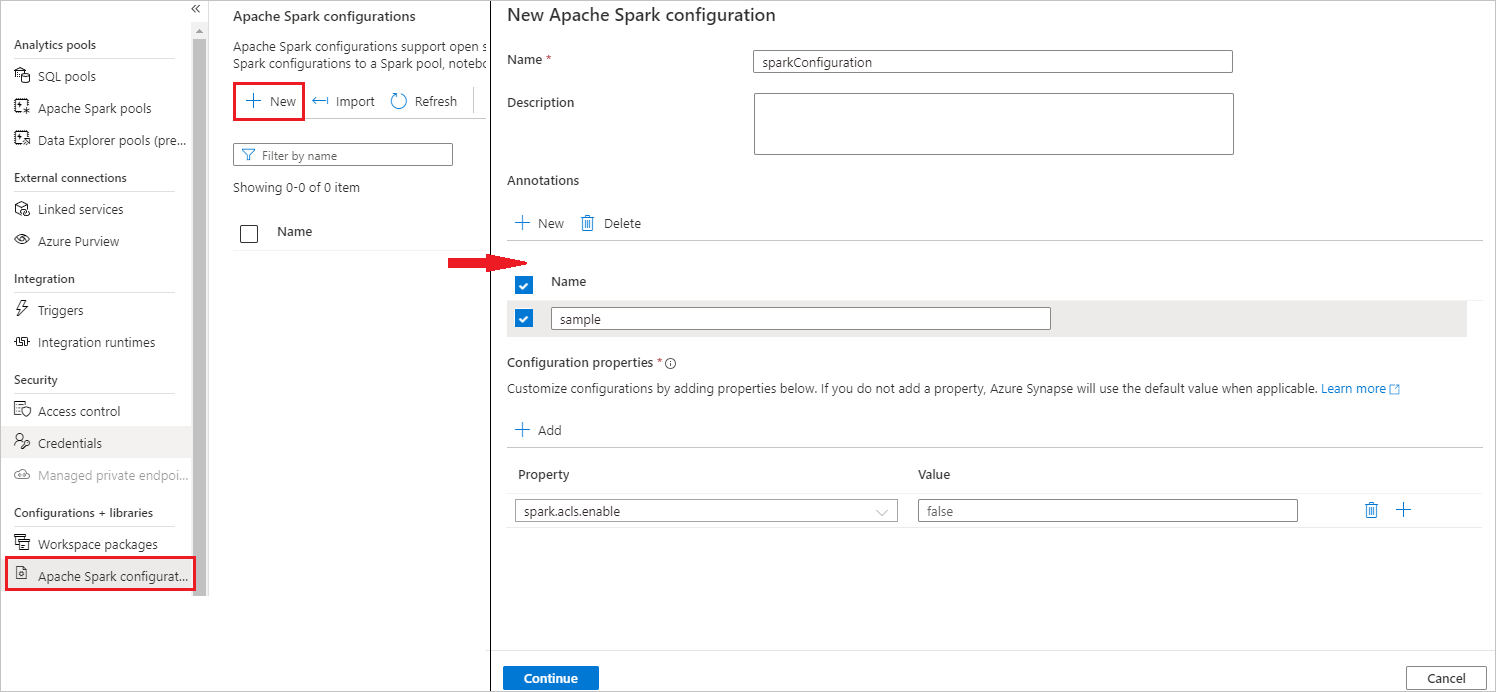
手順 4: Apache Spark 構成の作成
ワークスペースに Apache Spark 構成を作成し、Notebook または Apache Spark ジョブ定義を作成するときに、Apache Spark プールで使用する Apache Spark 構成を選択できます。 選択すると、構成の詳細が表示されます。
[管理]>[Apache Spark 構成] を選択します。
[新規] ボタンをクリックして新しい Apache Spark 構成を作成するか、[ローカル .json ファイルをワークスペースにインポートする] をクリックします。
[新規] ボタンをクリックすると、[新しい Apache Spark 構成] ページが開きます。
[名前] には、任意の有効な名前を入力できます。
[説明] には、説明を入力できます。
[注釈] には、[新規] ボタンをクリックして注釈を追加したり、[削除] ボタンを選択しクリックして既存の注釈を削除することもできます。
[構成プロパティ] で、[追加] ボタンをクリックしてプロパティを追加し、構成をカスタマイズします。 プロパティを追加しない場合、Azure Synapse では必要に応じて既定値を使用します。
Apache Spark アプリケーションを送信してログとメトリックを表示する
その方法は次のとおりです。
前の手順で構成した Apache Spark プールに Apache Spark アプリケーションを送信します。 次のいずれかの方法を使用して、これを行うことができます。
- Synapse Studio でノートブックを実行する。
- Synapse Studio で、Apache Spark ジョブ定義を使用して Apache Spark バッチ ジョブを送信します。
- Apache Spark アクティビティを含むパイプラインを実行する。
指定した Log Analytics ワークスペースに移動し、Apache Spark アプリケーションの実行が開始されたときにアプリケーションのメトリックとログを表示します。
カスタム アプリケーション ログを書き込む
Apache Log4j ライブラリを使用して、カスタム ログを書き込むことができます。
Scala の例:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
PySpark の例:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
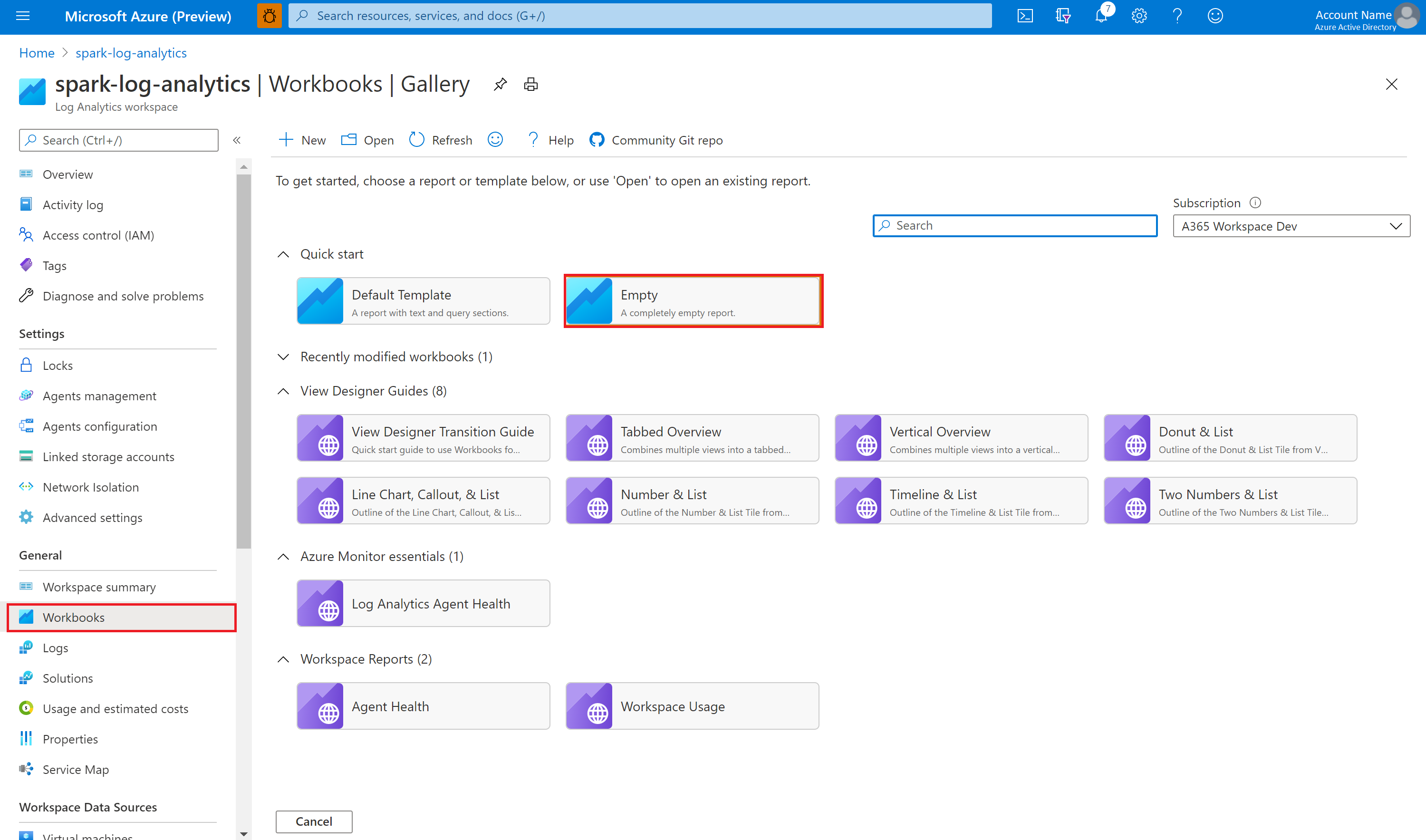
サンプルのブックを使用してメトリックとログを視覚化する
ブックをダウンロードします。
ブック ファイルを開き、内容をコピーします。
Azure portal で、 [Log Analytics ワークスペース]>[ブック] の順に選択します。
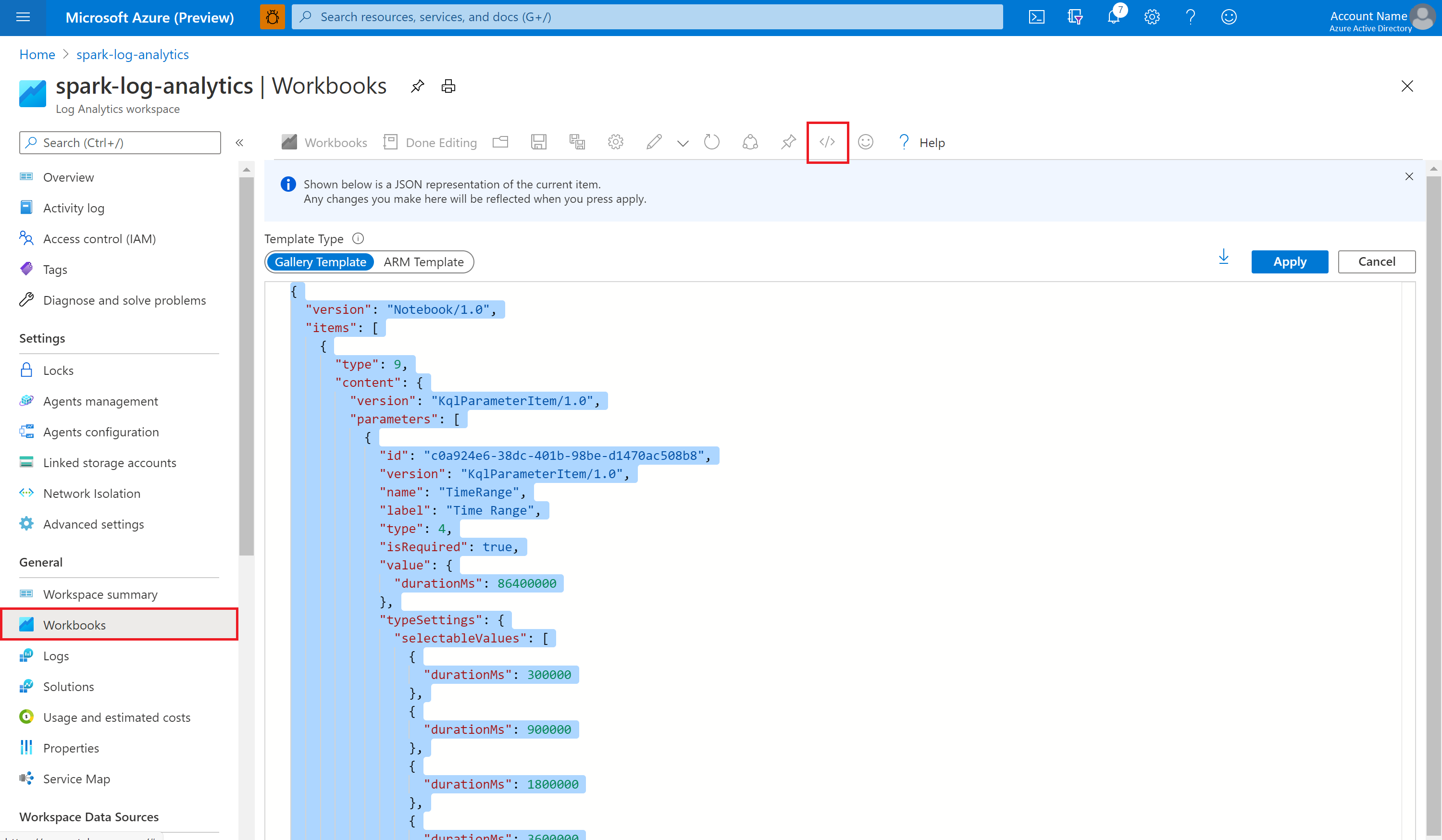
空のブックを開きます。 </> アイコンを選択して、[詳細エディター] モードを使用します。
存在する JSON コードの上に貼り付けます。
[適用] を選択し、次に [編集が完了しました] を選択します。
その後、構成済みの Apache Spark プールに Apache Spark アプリケーションを送信します。 アプリケーションが実行状態になったら、ブックのドロップダウン リストで、実行中のアプリケーションを選択します。
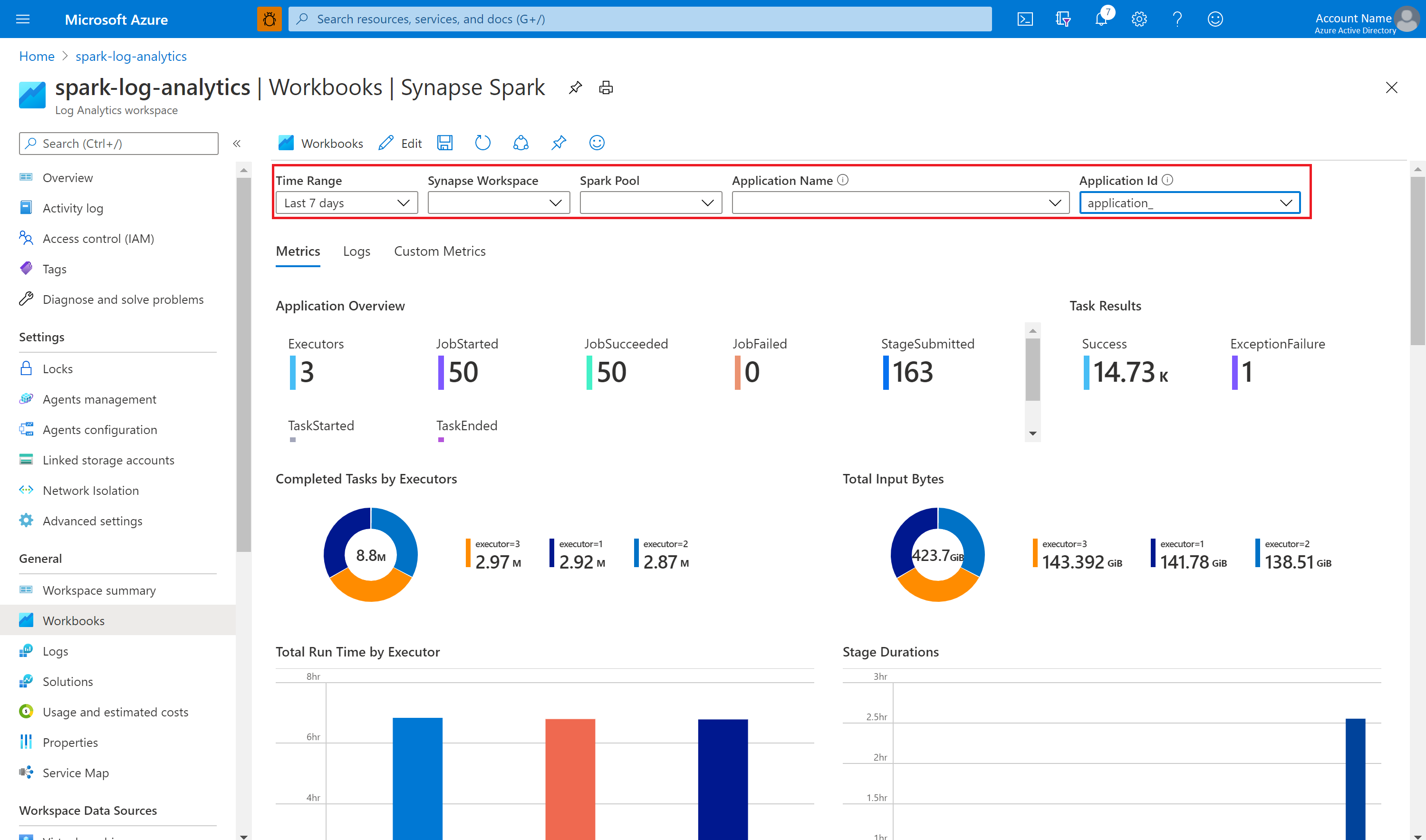
ブックはカスタマイズできます。 たとえば、Kusto クエリを使用してアラートを構成できます。
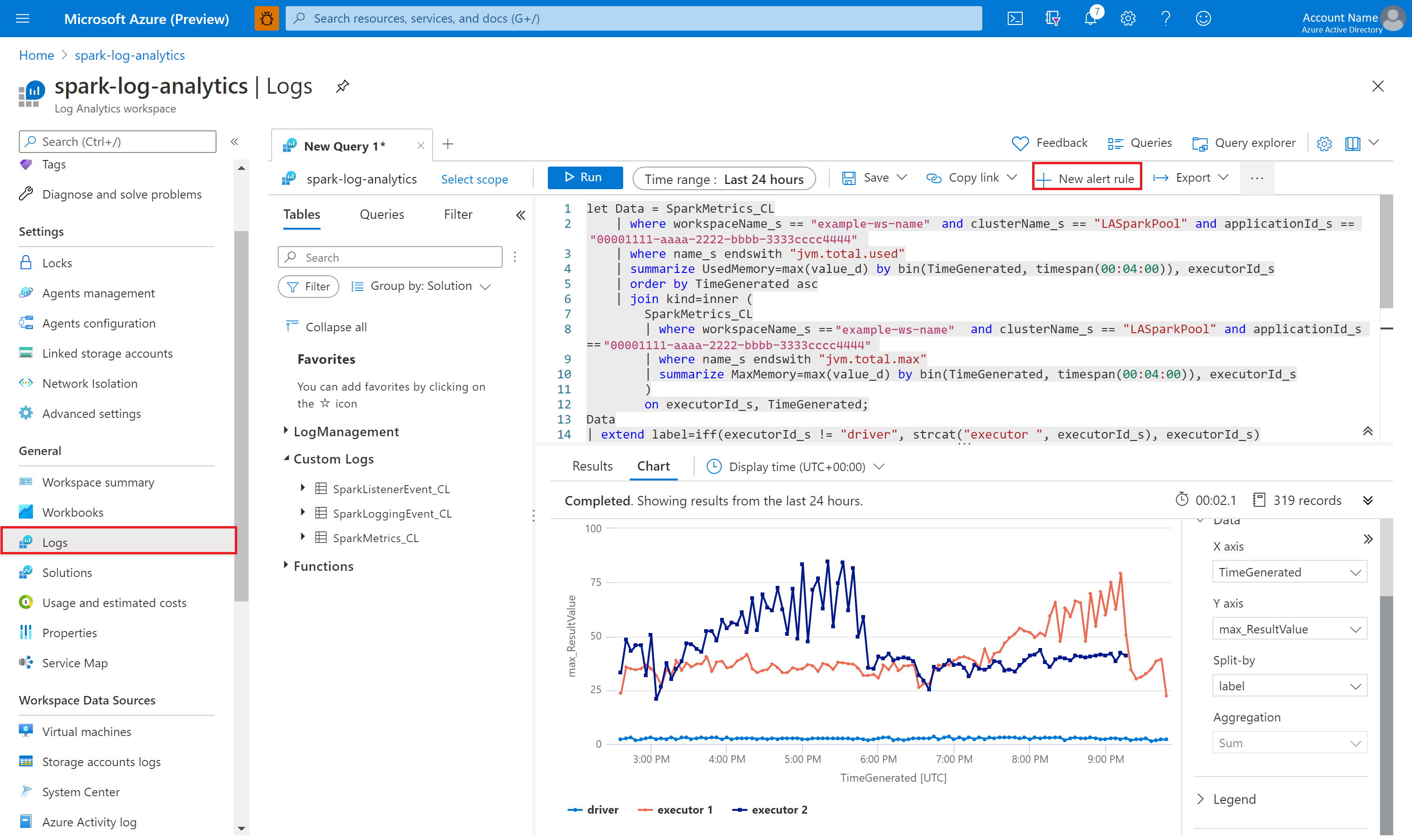
Kusto を使用してデータのクエリを実行する
Apache Spark イベントに対するクエリ実行の例を次に示します。
SparkListenerEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Apache Spark アプリケーションのドライバーと Executor ログに対するクエリの実行例を次に示します。
SparkLoggingEvent_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| order by TimeGenerated desc
| limit 100
Apache Spark メトリックに対するクエリ実行例を次に示します。
SparkMetrics_CL
| where workspaceName_s == "{SynapseWorkspace}" and clusterName_s == "{SparkPool}" and livyId_s == "{LivyId}"
| where name_s endswith "jvm.total.used"
| summarize max(value_d) by bin(TimeGenerated, 30s), executorId_s
| order by TimeGenerated asc
アラートの作成および管理
ユーザーは、設定された頻度でクエリを実行してメトリックとログを評価し、その結果に基づいてアラートを発行することができます。 詳細については、「Azure Monitor を使用してログ アラートを作成、表示、管理する」を参照してください。
データ流出の防止が有効になっている Synapse ワークスペース
データ流出の防止が有効になっている Synapse ワークスペースが作成された後。
この機能を有効にする場合は、ワークスペースの承認された Microsoft Entra テナント内の Azure Monitor Private Link スコープ (A M P L S) に対して、マネージド プライベート エンドポイント接続要求を作成する必要があります。
下の手順に従って、Azure Monitor Private Link スコープ (A M P L S) に対するマネージド プライベート エンドポイント接続を作成できます。
- 既存の A M P L S がない場合は、Azure Monitor Private Link 接続の設定に関する記事に従って作成します。
- Azure portal で A M P L S に移動し、[Azure Monitor リソース] ページで、[追加] をクリックして Azure Log Analytics ワークスペースに接続を追加します。
- [Synapse Studio] > [管理] > [マネージド プライベート エンドポイント] に移動して、[新規] ボタンをクリックし、[Azure Monitor Private Link スコープ]、[続行] の順に選択します。
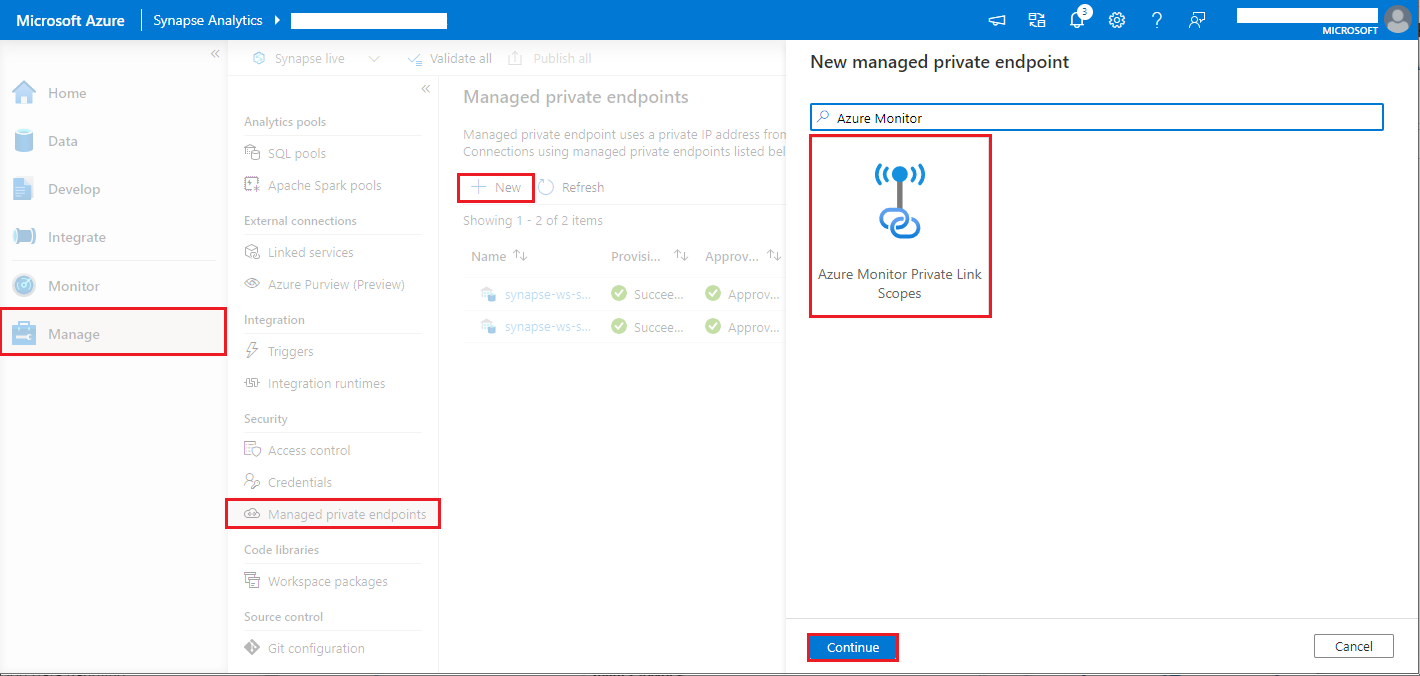
- 作成した Azure Monitor プライベート リンク スコープを選択し、 [作成] ボタンをクリックします。
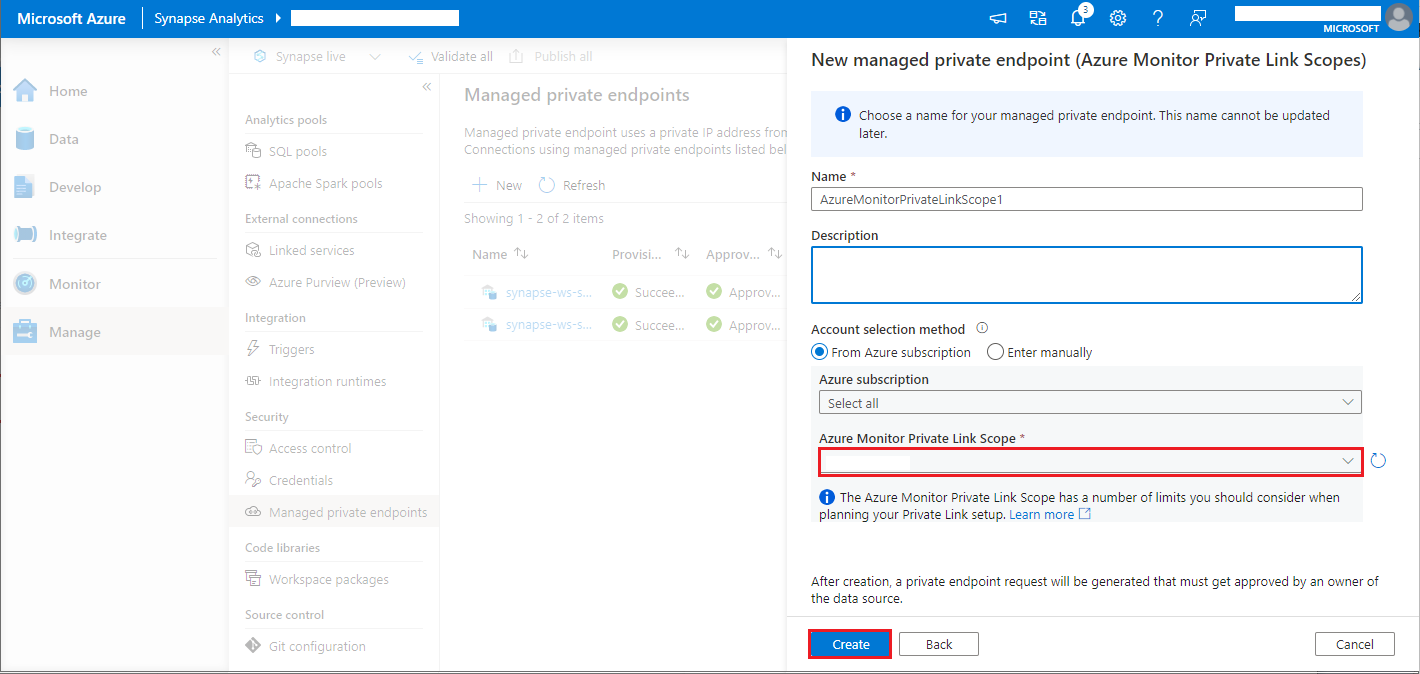
- プライベート エンドポイントのプロビジョニングが完了するまで数分待ちます。
- Azure portal で再び A M P L S に移動し、[プライベート エンドポイント接続] ページで、先ほどプロビジョニングした接続を選択し [承認] します。
注意
- A M P L S オブジェクトには、Private Link の構成を計画するときに考慮に入れる必要のある制限がいくつかあります。 これらの制限の詳細については、A M P L S の制限に関する記事を参照してください。
- マネージド プライベート エンドポイントを作成するための適切なアクセス許可があるか確認します。