チュートリアル:Synapse Studio で Apache Spark ジョブ定義を作成する
このチュートリアルでは、Synapse Studio を使用して Apache Spark ジョブ定義を作成し、それらをサーバーレス Apache Spark プールに送信する方法を示します。
このチュートリアルに含まれるタスクは次のとおりです。
- PySpark (Python) 用の Apache Spark ジョブ定義を作成する
- Spark (Scala) 用の Apache Spark ジョブ定義を作成する
- .NET Spark (C# または F#) 用の Apache Spark ジョブ定義を作成する
- JSON ファイルをインポートしてジョブ定義を作成する
- Apache Spark ジョブ定義ファイルをローカルにエクスポートする
- Apache Spark ジョブ定義をバッチ ジョブとして送信する
- Apache Spark ジョブ定義をパイプラインに追加する
前提条件
このチュートリアルを開始する前に、次の要件を満たしてください。
- Azure Synapse Analytics ワークスペース。 手順については、Azure Synapse Analytics ワークスペースの作成に関するページを参照してください。
- サーバーレス Apache Spark プール。
- ADLS Gen2 ストレージ アカウント。 使用する ADLS Gen2 ファイル システムのストレージ BLOB データ共同作成者である必要があります。 そうでない場合は、手動でアクセス許可を追加する必要があります。
- ワークスペースの既定のストレージを使用したくない場合は、必要な ADLS Gen2 ストレージ アカウントを Synapse Studio でリンクしてください。
PySpark (Python) 用の Apache Spark ジョブ定義を作成する
このセクションでは、PySpark (Python) 用の Apache Spark ジョブ定義を作成します。
Synapse Studio を開きます。
Apache Spark ジョブ定義を作成するためのサンプル ファイルに移動して、python.zip のサンプル ファイルをダウンロードし、圧縮パッケージを解凍して、wordcount.py ファイルと shakespeare.txt ファイルを抽出します。
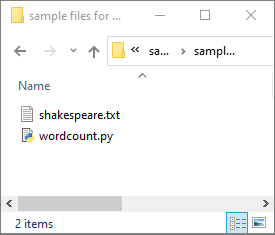
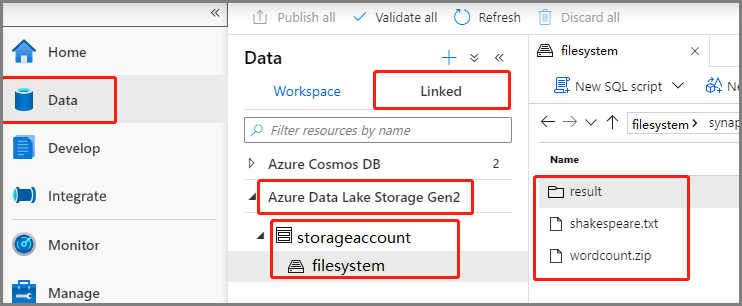
[データ]>[Linked](リンク済み)>[Azure Data Lake Storage Gen2] の順に選択し、wordcount.py と shakespeare.txt を ADLS Gen2 ファイル システムにアップロードします。
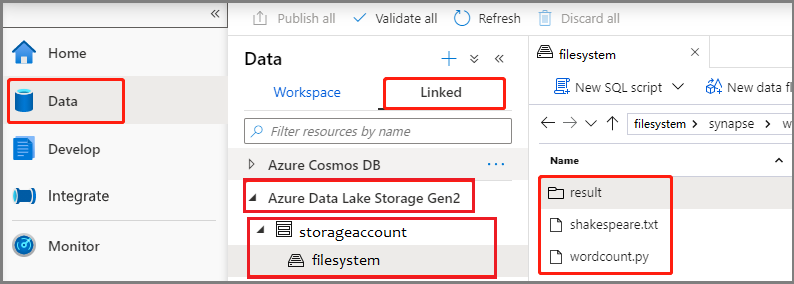
[開発] ハブを選択し、[+] アイコンを選択して [Spark job definition](Spark ジョブ定義) を選択し、新しい Spark ジョブ定義を作成します。
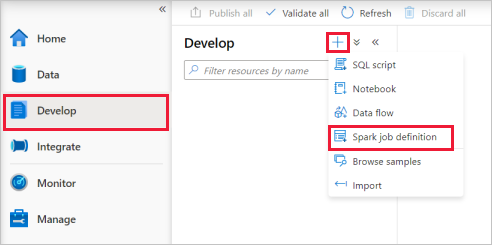
Apache Spark ジョブ定義のメイン ウィンドウの [言語] ドロップ ダウン リストから [PySpark (Python)] を選択します。
Apache Spark ジョブ定義の情報を入力します。
プロパティ 説明 Job definition name (ジョブ定義名) Apache Spark ジョブ定義の名前を入力します。 この名前は公開されるまでいつでも更新できます。
サンプル:job definition sampleMain definition file (メイン定義ファイル) ジョブに使用されるメイン ファイルです。 ストレージから PY ファイルを選択します。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。
サンプル:abfss://…/path/to/wordcount.pyコマンド ライン引数 ジョブに対する省略可能な引数。
サンプル:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意事項: サンプル ジョブ定義の 2 つの引数はスペースで区切ります。参照ファイル メイン定義ファイル内で参照に使用される追加ファイル。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。 Spark プール 選択した Apache Spark プールにジョブが送信されます。 Spark のバージョン Apache Spark プールが実行されている Apache Spark のバージョン。 エグゼキュータ ジョブ用の指定された Apache Spark プール内で提供される Executor の数。 Executor size (エグゼキュータのサイズ) ジョブ用の指定された Apache Spark プール内で提供される、Executor に使用するコアとメモリの数。 Driver size (ドライバー サイズ) ジョブ用の指定された Apache Spark プール内で提供される、ドライバーに使用するコアとメモリの数。 Apache Spark の構成 以下のプロパティを追加して構成をカスタマイズします。 プロパティを追加しない場合、Azure Synapse では必要に応じて既定値を使用します。 
[公開] を選択して、Apache Spark ジョブ定義を保存します。

Apache Spark (Scala) 用の Apache Spark ジョブ定義を作成する
このセクションでは、Apache Spark (Scala) 用の Apache Spark ジョブ定義を作成します。
Azure Synapse Studio を開きます。
Apache Spark ジョブ定義を作成するためのサンプル ファイルに移動して、scala.zip のサンプル ファイルをダウンロードし、圧縮パッケージを解凍して、wordcount.jar ファイルと shakespeare.txt ファイルを抽出します。
[データ]>[Linked](リンク済み)>[Azure Data Lake Storage Gen2] の順に選択し、wordcount.jar と shakespeare.txt を ADLS Gen2 ファイル システムにアップロードします。

[開発] ハブを選択し、[+] アイコンを選択して [Spark job definition](Spark ジョブ定義) を選択し、新しい Spark ジョブ定義を作成します。 (サンプル画像は、PySpark (Python) 用の Apache Spark ジョブ定義を作成する方法に関するセクションの手順 4. と同じです。)
Apache Spark ジョブ定義のメイン ウィンドウの [言語] ドロップ ダウン リストから [Spark (Scala)] を選択します。
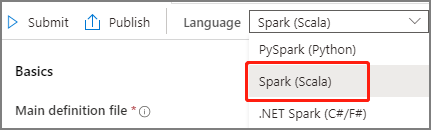
Apache Spark ジョブ定義の情報を入力します。 サンプル情報をコピーできます。
プロパティ 説明 Job definition name (ジョブ定義名) Apache Spark ジョブ定義の名前を入力します。 この名前は公開されるまでいつでも更新できます。
サンプル:scalaMain definition file (メイン定義ファイル) ジョブに使用されるメイン ファイルです。 ストレージから JAR ファイルを選択します。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。
サンプル:abfss://…/path/to/wordcount.jarメイン クラス名 完全修飾識別子またはメイン定義ファイル内のメイン クラス。
サンプル:WordCountコマンド ライン引数 ジョブに対する省略可能な引数。
サンプル:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意事項: サンプル ジョブ定義の 2 つの引数はスペースで区切ります。参照ファイル メイン定義ファイル内で参照に使用される追加ファイル。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。 Spark プール 選択した Apache Spark プールにジョブが送信されます。 Spark のバージョン Apache Spark プールが実行されている Apache Spark のバージョン。 エグゼキュータ ジョブ用の指定された Apache Spark プール内で提供される Executor の数。 Executor size (エグゼキュータのサイズ) ジョブ用の指定された Apache Spark プール内で提供される、Executor に使用するコアとメモリの数。 Driver size (ドライバー サイズ) ジョブ用の指定された Apache Spark プール内で提供される、ドライバーに使用するコアとメモリの数。 Apache Spark の構成 以下のプロパティを追加して構成をカスタマイズします。 プロパティを追加しない場合、Azure Synapse では必要に応じて既定値を使用します。 
[公開] を選択して、Apache Spark ジョブ定義を保存します。

.NET Spark (C# または F#) 用の Apache Spark ジョブ定義を作成する
このセクションでは、.NET Spark (C# または F#) 用の Apache Spark ジョブ定義を作成します。
Azure Synapse Studio を開きます。
Apache Spark ジョブ定義を作成するためのサンプル ファイルに移動して、dotnet.zip のサンプル ファイルをダウンロードし、圧縮パッケージを解凍して、wordcount.zip ファイルと shakespeare.txt ファイルを抽出します。
[データ]>[Linked](リンク済み)>[Azure Data Lake Storage Gen2] の順に選択し、wordcount.zip と shakespeare.txt を ADLS Gen2 ファイル システムにアップロードします。
[開発] ハブを選択し、[+] アイコンを選択して [Spark job definition](Spark ジョブ定義) を選択し、新しい Spark ジョブ定義を作成します。 (サンプル画像は、PySpark (Python) 用の Apache Spark ジョブ定義を作成する方法に関するセクションの手順 4. と同じです。)
Apache Spark ジョブ定義のメイン ウィンドウの [言語] ドロップ ダウン リストから [.NET Spark (C#/F#)] を選択します。
Apache Spark ジョブ定義の情報を入力します。 サンプル情報をコピーできます。
プロパティ 説明 Job definition name (ジョブ定義名) Apache Spark ジョブ定義の名前を入力します。 この名前は公開されるまでいつでも更新できます。
サンプル:dotnetMain definition file (メイン定義ファイル) ジョブに使用されるメイン ファイルです。 ストレージから .NET for Apache Spark アプリケーション (メインの実行可能ファイル、ユーザー定義関数を含む DLL、およびその他の必要なファイル) を含む ZIP ファイルを選択します。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。
サンプル:abfss://…/path/to/wordcount.zipMain executable file (メイン実行可能ファイル) メイン定義 ZIP ファイル内のメインの実行可能ファイル。
サンプル:WordCountコマンド ライン引数 ジョブに対する省略可能な引数。
サンプル:abfss://…/path/to/shakespeare.txtabfss://…/path/to/result
注意事項: サンプル ジョブ定義の 2 つの引数はスペースで区切ります。参照ファイル メイン定義 ZIP ファイル (依存 jar、追加のユーザー定義関数 DLL、およびその他の構成ファイル) に含まれていない .NET for Apache Spark アプリケーションを実行するために、ワーカー ノードによって必要とされる追加のファイル。 [ファイルのアップロード] を選択して、ファイルをストレージ アカウントにアップロードできます。 Spark プール 選択した Apache Spark プールにジョブが送信されます。 Spark のバージョン Apache Spark プールが実行されている Apache Spark のバージョン。 エグゼキュータ ジョブ用の指定された Apache Spark プール内で提供される Executor の数。 Executor size (エグゼキュータのサイズ) ジョブ用の指定された Apache Spark プール内で提供される、Executor に使用するコアとメモリの数。 Driver size (ドライバー サイズ) ジョブ用の指定された Apache Spark プール内で提供される、ドライバーに使用するコアとメモリの数。 Apache Spark の構成 以下のプロパティを追加して構成をカスタマイズします。 プロパティを追加しない場合、Azure Synapse では必要に応じて既定値を使用します。 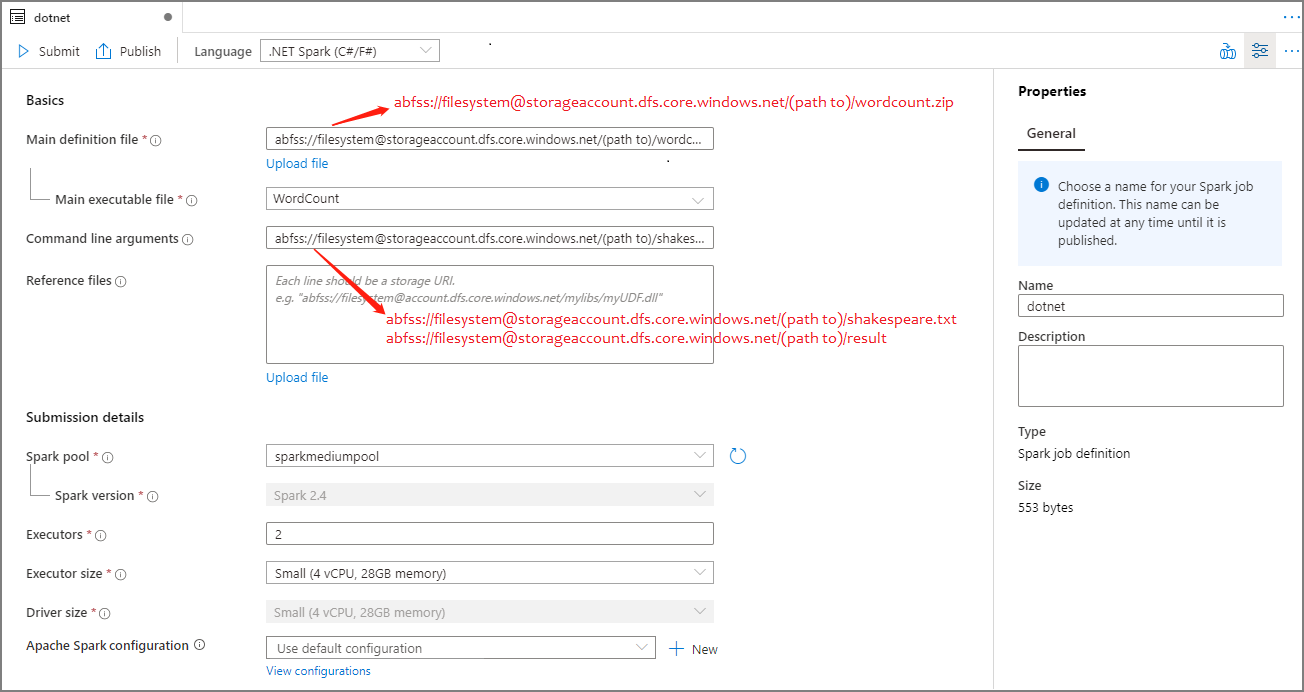
[公開] を選択して、Apache Spark ジョブ定義を保存します。

注意
Apache Spark 構成では、Apache Spark ジョブ定義の Apache Spark 構成で特に処理が行われなかった場合は、ジョブの実行時に既定の構成が使用されます。
JSON ファイルをインポートして Apache Spark ジョブ定義を作成する
Apache Spark ジョブ定義エクスプローラーのアクション (...) メニューから既存のローカル JSON ファイルを Azure Synapse ワークスペースにインポートして、新しい Apache Spark ジョブ定義を作成します。
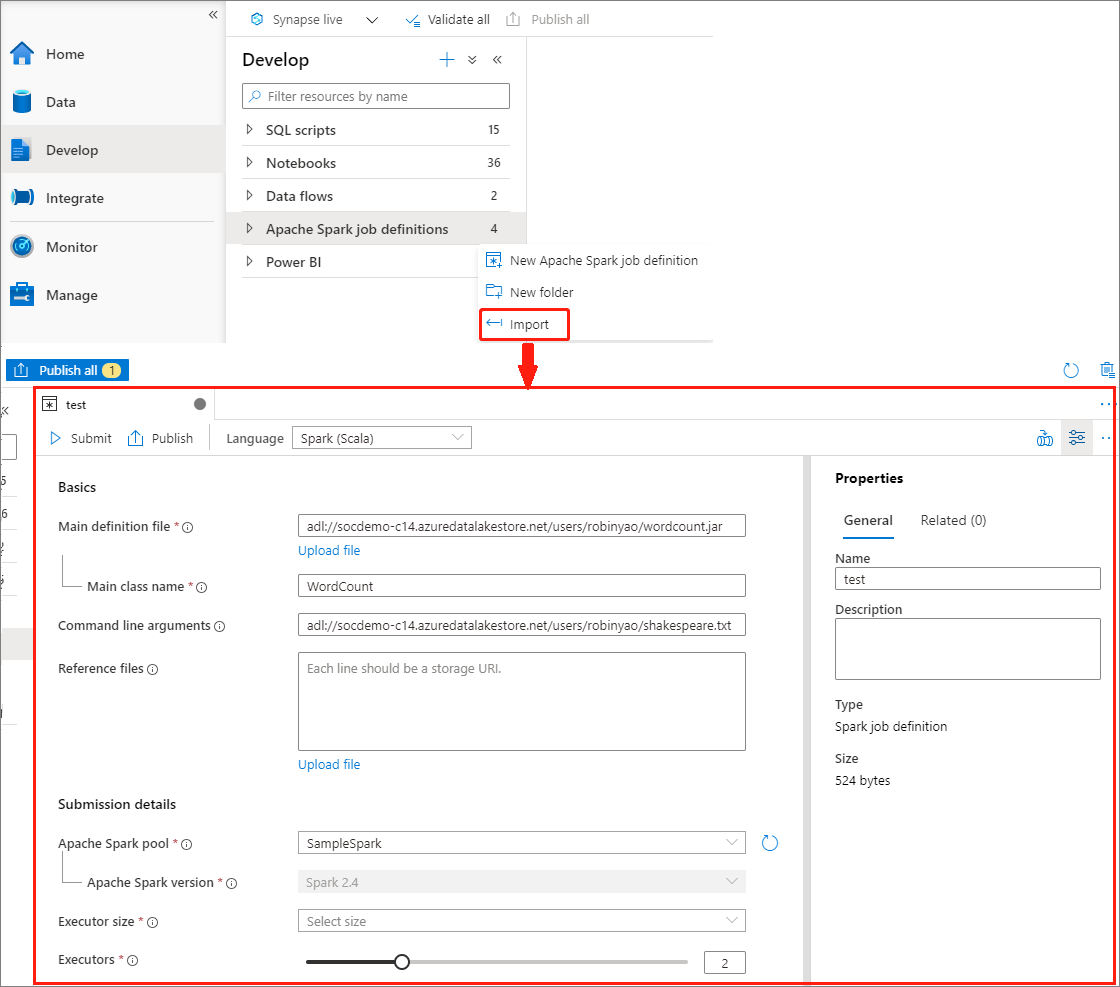
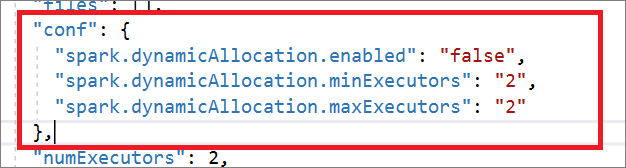
Spark ジョブ定義は、Livy API と完全に互換性があります。 その他の Livy プロパティのパラメーター (Livy の REST API に関するドキュメント (apache.org) を参照) は、ローカル JSON ファイルに追加できます。 また、次に示したように、Spark 構成に関連したパラメーターを構成プロパティに指定することもできます。 その後、JSON ファイルを再びインポートして、バッチ ジョブ用に新しい Apache Spark ジョブ定義を作成できます。 Spark 定義インポート用の JSON の例:
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
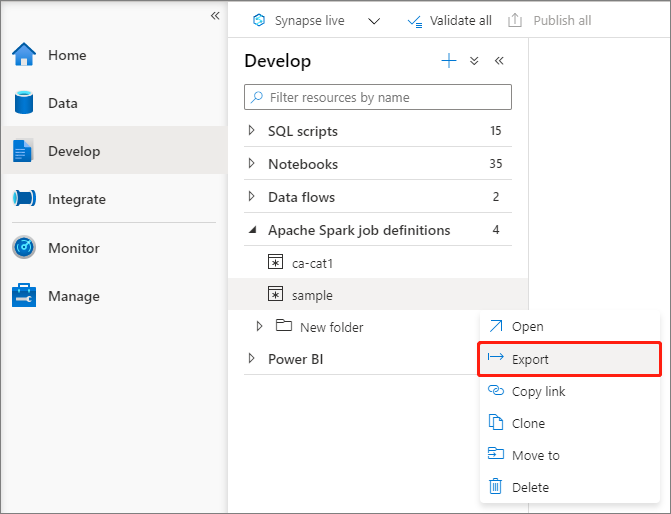
既存の Apache Spark ジョブ定義ファイルをエクスポートする
エクスプローラーのアクション (...) メニューから、既存の Apache Spark ジョブ定義ファイルをローカルにエクスポートすることができます。 必要に応じて、さらに JSON ファイルを更新して Livy のプロパティを追加した後、再びそれをインポートして、新しいジョブ定義を作成できます。
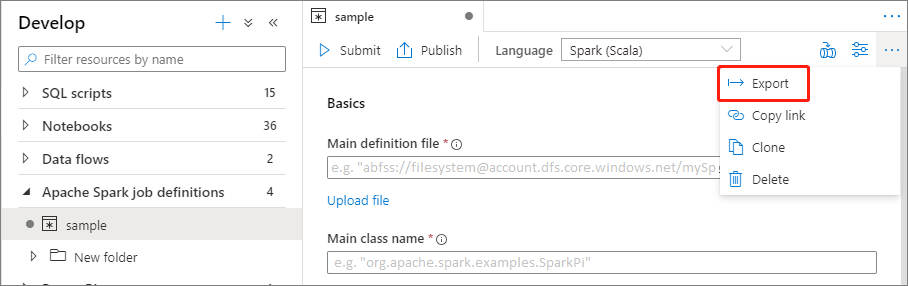
Apache Spark ジョブ定義をバッチ ジョブとして送信する
Apache Spark ジョブ定義を作成したら、それを Apache Spark プールに送信できます。 使用する ADLS Gen2 ファイルシステムのストレージ BLOB データ共同作成者であることを確認してください。 そうでない場合は、手動でアクセス許可を追加する必要があります。
シナリオ 1:Apache Spark ジョブ定義を送信する
Apache Spark ジョブ定義を選択してウィンドウを開きます。
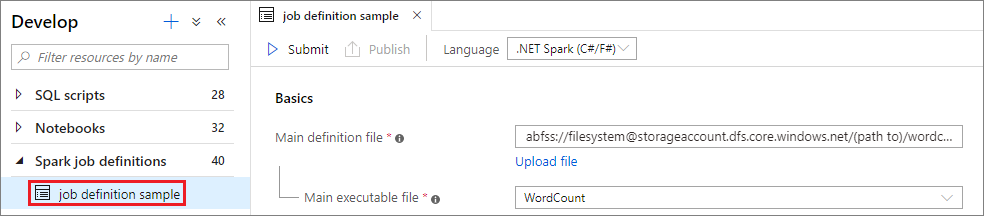
[送信] ボタンを選択し、選択した Apache Spark プールにプロジェクトを送信します。 [Spark monitoring URL](Spark 監視 URL) タブを選択して、Apache Spark アプリケーションの LogQuery を表示できます。
![[送信] ボタンを選択して、Spark ジョブ定義を送信します](media/apache-spark-job-definitions/submit-spark-definition.png)
![[Spark Submission]\(Spark 送信\) ダイアログ ボックス](media/apache-spark-job-definitions/submit-definition-result.png)
シナリオ 2: Apache Spark ジョブの実行の進行状況を表示する
[モニター] を選択して、 [Apache Spark アプリケーション] オプションを選択します。 送信した Apache Spark アプリケーションを見つけることができます。
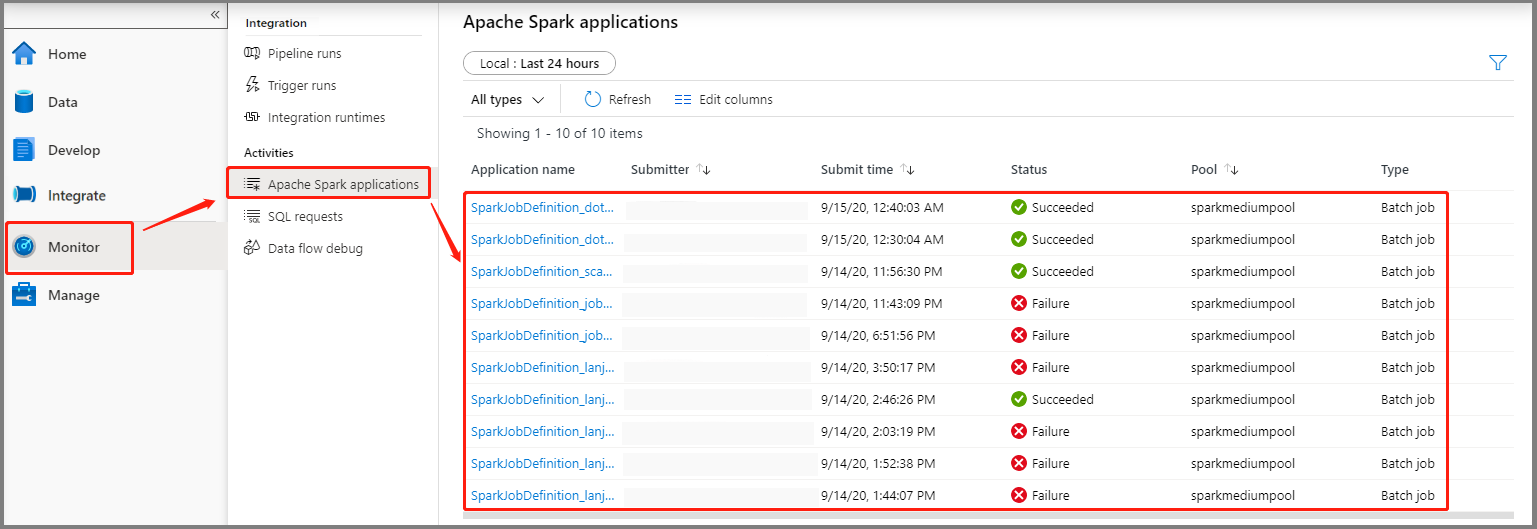
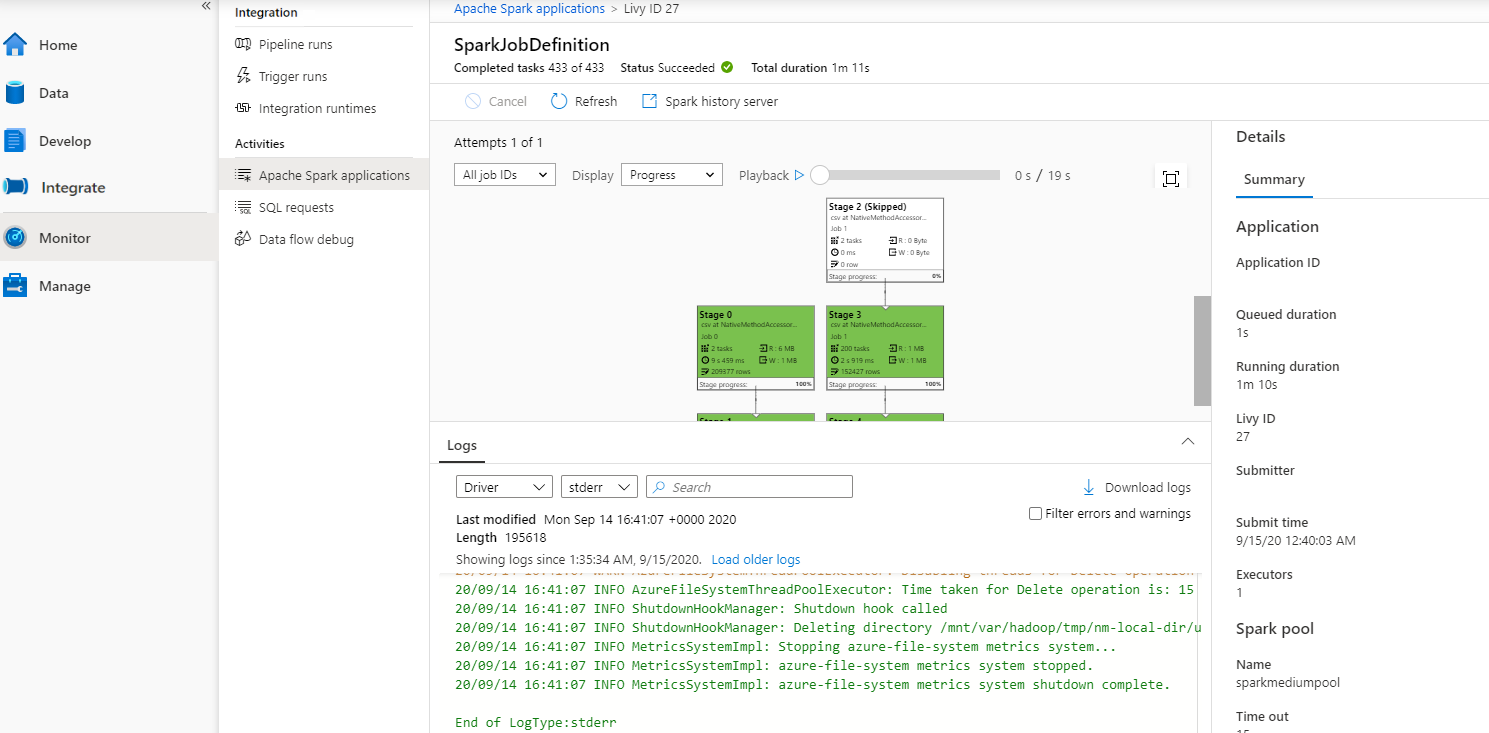
次に、その Apache Spark アプリケーションを選択すると、 [SparkJobDefinition] ジョブ ウィンドウが表示されます。 ここからジョブ実行の進行状況を表示できます。
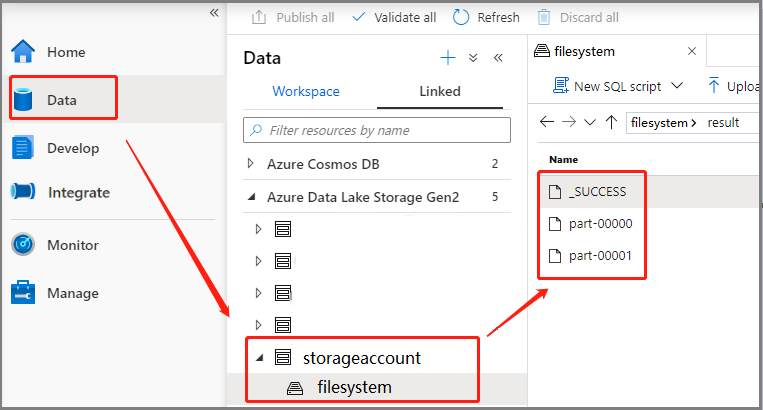
シナリオ 3: 出力ファイルを確認する
[データ]>[Linked](リンク済み)>[Azure Data Lake Storage Gen2] (hozhaobdbj) の順に選択し、先ほど作成した result フォルダーを開くと、結果フォルダーに移動して出力が生成されているかどうかを確認できます。
Apache Spark ジョブ定義をパイプラインに追加する
このセクションでは、Apache Spark ジョブ定義をパイプラインに追加します。
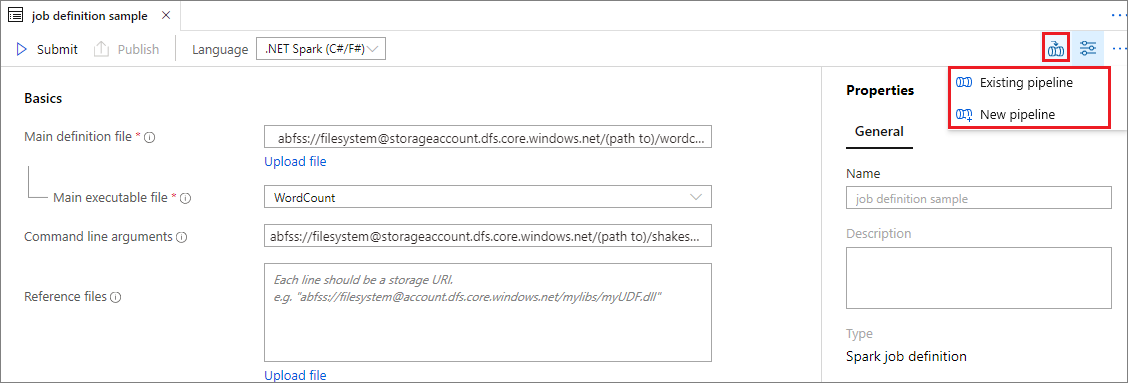
既存の Apache Spark ジョブ定義を開きます。
Apache Spark ジョブ定義の右上にあるアイコンを選択し、 [Existing pipeline](既存のパイプライン) または [新しいパイプライン] を選択します。 詳細については、パイプラインのページを参照してください。
次の手順
次に、Azure Synapse Studio を使用して Power BI データセットを作成し、Power BI データを管理できます。 詳細については、Power BI ワークスペースを Synapse ワークスペースにリンクするに関する記事を参照してください。