Azure Stream Analytics と Azure Machine Learning の統合
機械学習モデルをユーザー定義関数 (UDF) として Azure Stream Analytics ジョブに実装し、ストリーミング入力データに対してリアルタイムのスコアリングと予測を行うことができます。 Azure Machine Learning では、TensorFlow、scikit-learn、PyTorch などの一般的なオープンソース ツールを使用して、モデルの準備、トレーニング、およびデプロイを行うことができます。
前提条件
機械学習モデルを関数として Stream Analytics ジョブに追加する前に、次の手順を完了します。
Azure Machine Learning を使用して、モデルを Web サービスとしてデプロイします。
Machine Learning エンドポイントには、Stream Analytics によって入力と出力のスキーマが理解されやすいようにする、関連付けられた swagger が指定されている必要があります。 このサンプルの Swagger 定義を、それが正しく設定されていることを確認するための参照として使用できます。
Web サービスが JSON シリアル化データを受け入れて返すことを確認します。
高スケールの運用デプロイ向けの Azure Kubernetes Service にモデルをデプロイします。 Web サービスがジョブからの要求数を処理できない場合、Stream Analytics ジョブのパフォーマンスが低下し、待機時間に影響します。 Azure Container Instances にデプロイされたモデルは、Azure portal を使用する場合にのみサポートされます。
機械学習モデルをジョブに追加する
Azure portal または Visual Studio Code から直接、Azure Machine Learning 関数を Stream Analytics ジョブに追加できます。
Azure portal
Azure portal で Stream Analytics ジョブに移動し、 [ジョブ トポロジ] で [関数] を選択します。 次に、 [+ 追加] ドロップダウン メニューから [Azure Machine Learning Service] を選択します。
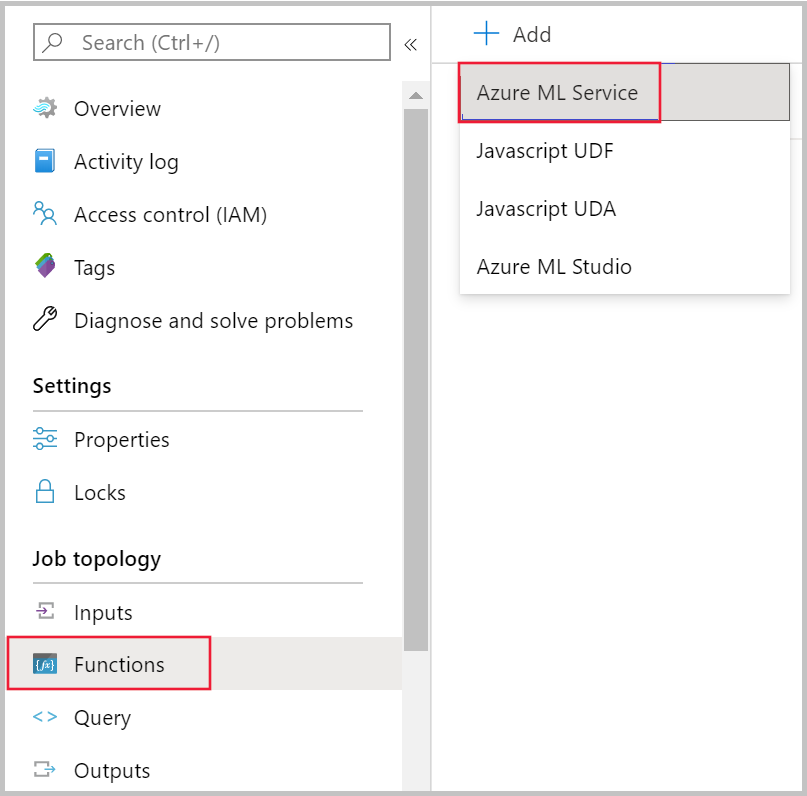
[Azure Machine Learning Service function](Azure Machine Learning Service 関数) フォームに次のプロパティ値を入力します。
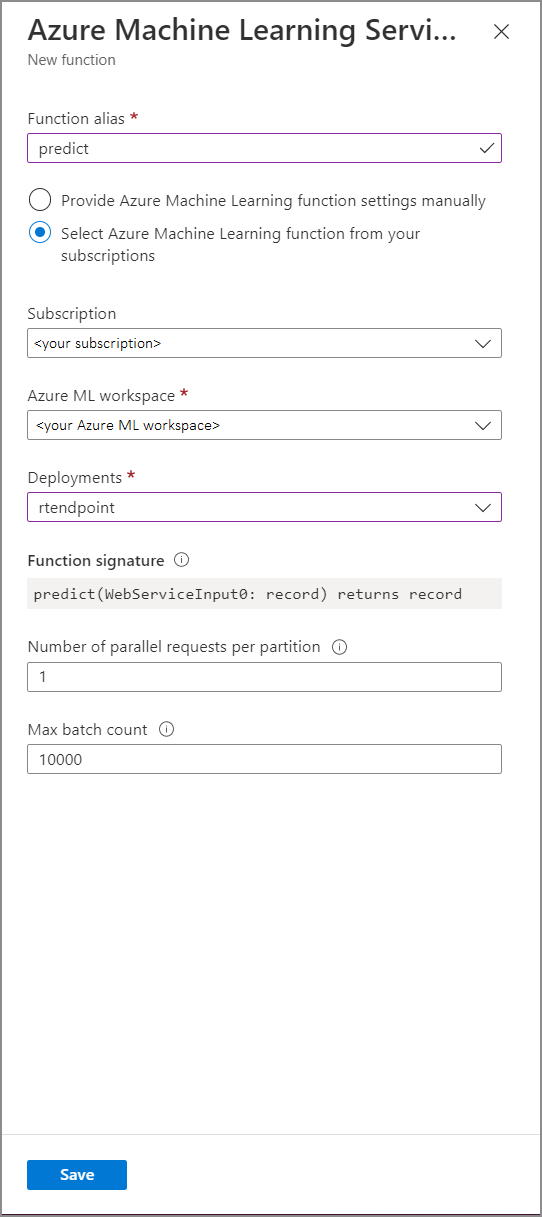
次の表は、Stream Analytics の Azure Machine Learning Service 関数の各プロパティの説明です。
| プロパティ | 説明 |
|---|---|
| 関数のエイリアス | クエリ内で関数を呼び出すための名前を入力します。 |
| サブスクリプション | Azure サブスクリプション。 |
| Azure Machine Learning ワークスペース | モデルを Web サービスとしてデプロイするために使用した Azure Machine Learning ワークスペース。 |
| エンドポイント | モデルをホストしている Web サービス。 |
| 関数シグネチャ | API のスキーマ仕様から推測される Web サービスのシグネチャ。 シグネチャの読み込みに失敗した場合は、スキーマを自動生成するためにスコアリング スクリプトでサンプルの入力と出力を提供したことを確認してください。 |
| パーティションごとの並列要求の数 | これは、高スケールのスループットを最適化するための高度な構成です。 この数は、ジョブの各パーティションから Web サービスに送信される同時要求を表します。 ストリーミング ユニット (SU) が 6 つ以下のジョブには、1 つのパーティションがあります。 SU が 12 個のジョブには 2 つのパーティションがあり、SU が 18 個であれば 3 つのパーティションがあり、以下同様です。 たとえば、ジョブに 2 つのパーティションがあり、このパラメーターを 4 に設定した場合、ジョブから Web サービスへの同時要求数は 8 になります。 |
| 最大バッチ カウント | これは、高スケールのスループットを最適化するための高度な構成です。 この数は、Web サービスに送信される 1 つの要求にバッチ化されるイベントの最大数を表します。 |
クエリからの Machine Learning エンドポイントの呼び出し
Stream Analytics クエリが Azure Machine Learning UDF を呼び出すと、Web サービスへの JSON シリアル化要求がジョブによって作成されます。 要求は、Stream Analytics によってエンドポイントの swagger から推論されるモデル固有のスキーマに基づいています。
警告
Azure portal のクエリ エディターでテストしている場合、ジョブは実行されていないため、Machine Learning エンドポイントは呼び出されません。 ポータルからエンドポイント呼び出しをテストするには、Stream Analytics ジョブが実行されている必要があります。
次の Stream Analytics クエリは、Azure Machine Learning UDF を呼び出す方法の例です。
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
ML UDF に送信された入力データが想定されているスキーマと一致しない場合、エンドポイントは、エラー コード 400 を含む応答を返します。これにより、Stream Analytics ジョブは失敗した状態になります。 ジョブに対してリソース ログを有効にすることをお勧めします。これにより、このような問題のデバッグとトラブルシューティングを簡単に行うことができます。 そのため、次を行うことを強くお勧めします。
- ML UDF への入力が null でないことを確認する
- ML UDF への入力であるすべてのフィールドの型を検証して、エンドポイントで想定されるものと一致することを確認する
Note
ML UDF は、条件式 (つまり CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END) を使用して呼び出された場合でも、特定のクエリ ステップの各行に対して評価されます。 必要に応じて、WITH 句を使用して分岐するパスを作成し、UNION を使用してパスを再度結合する前に、必要な場合にのみ ML UDF を呼び出します。
複数の入力パラメーターを UDF に渡す
Machine Learning モデルへの入力の最も一般的な例は、numpy 配列と DataFrame です。 JavaScript UDF を使用して配列を作成し、WITH 句を使用して JSON シリアル化 DataFrame を作成することができます。
入力配列の作成
N 個の入力を受け取って配列を作成する JavaScript UDF を作成できます。この配列は、Azure Machine Learning UDF への入力として使用できます。
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
JavaScript UDF をジョブに追加した後、次のクエリを使用して Azure Machine Learning UDF を呼び出すことができます。
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
次の JSON は要求の例です。
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Pandas または PySpark DataFrame の作成
次に示すように、WITH 句を使用して JSON シリアル化 DataFrame を作成できます。この DataFrame を、入力として Azure Machine Learning UDF に渡すことができます。
次のクエリでは、必要なフィールドを選択することによって DataFrame を作成し、その DataFrame を Azure Machine Learning UDF への入力として使用します。
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
次の JSON は、前のクエリからの要求の例です。
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Azure Machine Learning UDF のパフォーマンスの最適化
モデルを Azure Kubernetes Service にデプロイするときに、モデルをプロファイルしてリソース使用率を調べることができます。 要求率、応答時間、および失敗率を理解するために、デプロイに対して App Insights を有効にすることもできます。
イベントのスループットが高いシナリオがある場合、短いエンドツーエンド待機時間で最適なパフォーマンスを達成するために、Stream Analytics で次のパラメーターを変更することが必要な場合があります。
- 最大バッチ数。
- パーティションごとの並列要求の数。
適切なバッチ サイズの決定
Web サービスをデプロイした後、バッチ サイズを変えながらサンプル要求を送信します。バッチ サイズは 50 から始めて、100 単位で増やしていきます。 たとえば、200、500、1000、2000 のようにします。 特定のバッチ サイズを超えると、応答の待機時間が長くなることがわかります。 そこを超えると応答の待機時間が長くなるポイントを、ジョブの最大バッチ カウントにするのが適切です。
パーティションあたりの並列要求数の決定
最適なスケーリングでは、Stream Analytics ジョブが複数の並列要求を Web サービスに送信して応答を取得できるまで数ミリ秒以内です。 Web サービスの応答の待機時間は、Stream Analytics ジョブの待機時間とパフォーマンスに直接影響する可能性があります。 ジョブから Web サービスへの呼び出しに時間がかかる場合、ウォーターマークの遅延が増加する可能性が高く、バックログされる入力イベントの数も増加する可能性があります。
適切な数のノードとレプリカが Azure Kubernetes Service (AKS) クラスターにプロビジョニングされていることを確認することで、低遅延を実現することができます。 Web サービスの可用性が高く、正常な応答を返すことが重要です。 サービス使用不可応答 (503) などの再試行可能なエラーをジョブが受信した場合、エクスポネンシャル バックオフを使用して自動的に再試行が行われます。 これらのいずれかのエラーを、エンドポイントからの応答としてジョブが受信した場合、そのジョブは失敗した状態になります。
- 正しくない要求 (400)
- Conflict (409)
- Not Found (404)
- 承認されていません (401)
制限事項
Azure ML Managed Endpoint サービスを使用している場合、Stream Analytics では現在、パブリック ネットワーク アクセスが有効になっているエンドポイントにのみアクセスできます。 詳細については、Azure ML プライベート エンドポイントに関するページでお読みください。