v1 を使用して Azure Kubernetes Service クラスターにモデルをデプロイする
重要
この記事では、Azure Machine Learning CLI (v1) と Azure Machine Learning SDK for Python (v1) を使用してモデルをデプロイする方法について説明します。 v2 に推奨される方法については、「オンライン エンドポイントを使用して機械学習モデルをデプロイしてスコア付けする」を参照してください。
Azure Machine Learning を使って Azure Kubernetes Service (AKS) 上の Web サービスとしてモデルをデプロイする方法について説明します。 AKS は大規模な運用デプロイに適しています。 次の機能のいずれか 1 つでも必要な場合は、AKS を使います。
- 高速の応答時間
- デプロイされたサービスの自動スケール
- Logging
- モデル データ収集
- 認証
- TLS 終了
- GPU や Field Programmable Gate Array (FPGA) などのハードウェア アクセラレータ オプション
AKS にデプロイするときは、"ワークスペースに接続されている" AKS クラスターにデプロイします。 AKS クラスターのワークスペースへの接続に関する詳細については、「Azure Kubernetes Service クラスターを作成してアタッチする」を参照してください。
重要
Web サービスにデプロイする前にローカルでデバッグすることをお勧めします。 詳しくは、「ローカルでのモデル デプロイを使用したトラブルシューティング」をご覧ください。
Note
Azure Machine Learning のエンドポイント (v2) では、デプロイが改善され、シンプルになります。 エンドポイントは、リアルタイム シナリオとバッチ推論の両方をサポートします。 エンドポイントは、複数のコンピューティングの種類にわたってモデル デプロイを起動および管理するための統一インターフェイスを提供します。 「Azure Machine Learning エンドポイントとは」を参照してください。
前提条件
Azure Machine Learning ワークスペース。 詳細については、Azure Machine Learning ワークスペースの作成に関するページをご覧ください。
ワークスペースに登録されている機械学習モデル。 登録されたモデルがない場合は、「機械学習モデルを Azure にデプロイする」をご覧ください。
Machine Learning サービス向けの Azure CLI 拡張機能 (v1)、Azure Machine Learning Python SDK、または Azure Machine Learning Visual Studio Code 拡張機能。
重要
この記事の Azure CLI コマンドの一部では、Azure Machine Learning 用に
azure-cli-ml、つまり v1 の拡張機能を使用しています。 v1 拡張機能のサポートは、2025 年 9 月 30 日に終了します。 その日付まで、v1 拡張機能をインストールして使用できます。2025 年 9 月 30 日より前に、
ml(v2) 拡張機能に移行することをお勧めします。 v2 拡張機能の詳細については、Azure ML CLI 拡張機能と Python SDK v2 に関するページを参照してください。この記事の Python コード スニペットは、次の変数が設定されていることを前提としています。
ws- 使用しているワークスペースに設定されている。model- 登録済みのモデルに設定されている。inference_config- モデルの推論構成に設定されている。
これらの変数の設定について詳しくは、「Azure Machine Learning service を使用してモデルをデプロイする」を参照してください。
この記事の CLI のスニペットでは、inferenceconfig.json ドキュメントが既に作成されていると想定されています。 このドキュメントの作成について詳しくは、「機械学習モデルを Azure にデプロイする」をご覧ください。
ワークスペースに接続されている AKS クラスター。 詳細については、「Azure Kubernetes Service クラスターを作成してアタッチする」を参照してください。
- GPU ノードまたは FPGA ノード (または特定の製品) にモデルをデプロイしたい場合は、特定の製品でクラスターを作成する必要があります。 既存のクラスターにセカンダリ ノード プールを作成し、そのセカンダリ ノード プールにモデルをデプロイすることはサポートされていません。
デプロイ プロセスを理解する
"デプロイ" という用語は、Kubernetes と Azure Machine Learning の両方で使われます。 これら 2 つのコンテキストでは、"デプロイ"の意味が異なります。 Kubernetes では、デプロイは具体的なエンティティであり、宣言型の YAML ファイルで指定されます。 Kubernetes のデプロイには、定義されたライフサイクルと、Pods や ReplicaSets などの他の Kubernetes エンティティへの具体的な関係があります。 Kubernetes については、「What is Kubernetes?」 (Kubernetes とは) にあるドキュメントとビデオを参照してください。
Azure Machine Learning でのデプロイは、"プロジェクト リソースを使用できるようにすること、およびクリーンアップすること" というより一般的な意味で使われます。 Azure Machine Learning でデプロイ部分が考慮される手順は、次のとおりです。
- プロジェクト フォルダー内のファイルの解凍。 .amlignore または .gitignore で指定されたファイルは無視されます
- コンピューティング クラスターのスケールアップ (Kubernetes 関連)
- Dockerfile のビルドまたは計算ノードへのダウンロード (Kubernetes 関連)
- システムにより、次のハッシュが計算されます。
- 基本イメージ
- カスタム Docker の手順 (「カスタム Docker ベース イメージを使用してモデルをデプロイする」を参照してください)
- Conda 定義 YAML (Azure Machine Learning でのソフトウェア環境の作成と使用に関するページを参照してください)
- システムでは、ワークスペース Azure Container Registry (ACR) の検索で、このハッシュがキーとして使用されます
- 見つからない場合、グローバル ACR で一致するものが検索されます
- 見つからない場合、システムはキャッシュされてワークスペース ACR にプッシュされる新しいイメージをビルドします
- システムにより、次のハッシュが計算されます。
- 計算ノード上の一時記憶域への圧縮されたプロジェクト ファイルのダウンロード
- プロジェクト ファイルの解凍
python <entry script> <arguments>を実行する計算ノード- ./outputs に書き込まれたログ、モデル ファイル、その他のファイルの、ワークスペースに関連付けられているストレージ アカウントへの保存
- 一時的なストレージの削除など、コンピューティングのスケールダウン (Kubernetes 関連)
Azure Machine Learning ルーター
デプロイされたサービスへ受信推論要求をルーティングするフロントエンド コンポーネント (azureml-fe) は、必要に応じて自動的にスケーリングされます。 azureml-fe のスケーリングは、AKS クラスターの目的とサイズ (ノードの数) に基づいています。 クラスターの目的とノードは、AKS クラスターを作成またはアタッチするときに構成されます。 クラスターごとに 1 つの azureml-fe サービスがあり、複数のポッドで実行されている可能性があります。
重要
dev-testとして構成されているクラスターを使うと、セルフスケーラーは "無効" になります。 FastProd/DenseProd クラスターの場合でも、セルフスケーラーは利用統計情報で必要と示されている場合にのみ有効になります。- Azure Machine Learning では、システム コンテナーを含むコンテナーからログが自動的にアップロードまたは格納されません。 包括的なデバッグを行うには、AKS クラスター に対して Container Insights を有効にすることをお勧めします。 これにより、必要に応じて、コンテナー ログを保存、管理、および AML チームと共有できるようになります。 これがないと、AML では azureml-fe に関連する問題のサポートが保証されません。
- 最大要求ペイロードは 100 MB です。
azureml-fe は、より多くのコアを使用するためのスケールアップ (垂直方向)、およびより多くのポッドを使用するためのスケールアウト (水平方向) の両方を行います。 スケールアップするかどうかを決定するときは、受信推論要求のルーティングにかかる時間が使用されます。 この時間がしきい値を超えると、スケールアップが発生します。 受信要求をルーティングする時間がしきい値を超え続けると、スケールアウトが発生します。
スケールダウンとスケールインを行うときは、CPU 使用率が使用されます。 CPU 使用率のしきい値に達した場合、フロントエンドは最初にスケールダウンされます。 CPU 使用率がスケールインのしきい値にまで低下した場合は、スケールイン操作が行われます。 スケールアップとスケールアウトは、使用できるクラスター リソースが十分にある場合にのみ発生します。
スケールアップまたはスケールダウンが行われると、azureml-fe ポッドが再起動されて CPU とメモリの変更が適用されます。 再起動は推論の要求には影響しません。
AKS 推論クラスターの接続要件を理解する
Azure Machine Learning が AKS クラスターを作成またはアタッチすると、次の 2 つのネットワーク モデルのいずれかで AKS クラスターがデプロイされます。
- kubenet ネットワーク: AKS クラスターがデプロイされると、通常、ネットワーク リソースが作成されて構成されます。
- Azure Container Networking Interface (CNI) ネットワーク: AKS クラスターは、既存の仮想ネットワーク リソースと構成に接続されます。
Kubenet ネットワークでは、ネットワークが作成され、Azure Machine Learning service 用に適切に構成されます。 CNI ネットワークでは、接続要件を理解し、AKS 推論のための DNS 解決と送信接続を確認する必要があります。 たとえば、ファイアウォールを使ってネットワーク トラフィックをブロックしている場合があります。
次の図は、AKS 推論の接続要件を示しています。 黒い矢印は実際の通信を表し、青い矢印はドメイン名を表します。 これらのホストのエントリをファイアウォールまたはカスタム DNS サーバーに追加することが必要になる場合があります。
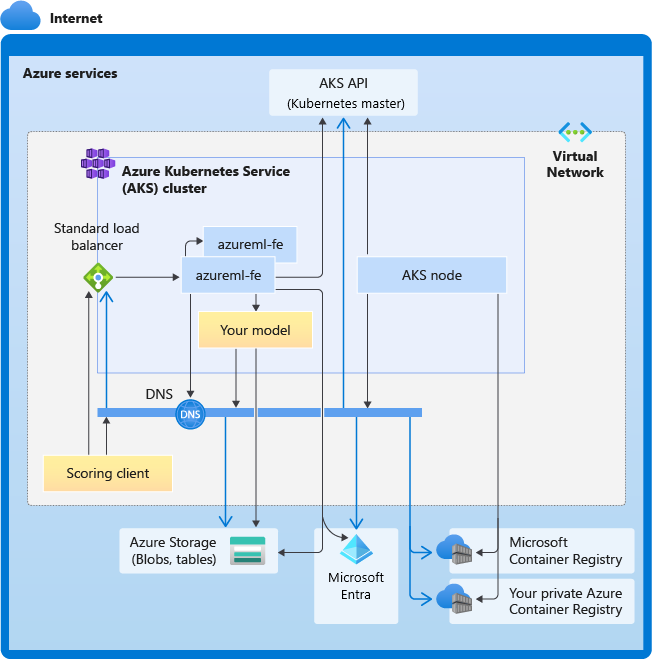
AKS の接続の一般的な要件については、「Azure Kubernetes Service (AKS) で Azure Firewall を使用してネットワーク トラフィックを制限する」をご覧ください。
ファイアウォールの向こう側にある Azure Machine Learning サービスにアクセスする方法については、「ネットワークの着信トラフィックおよび送信トラフィックを構成する」を参照してください。
全体的な DNS 解決の要件
既存の仮想ネットワーク内の DNS 解決は、ユーザーが管理します。 たとえば、ファイアウォールやカスタム DNS サーバーなどです。 次のホストに到達できる必要があります。
| ホスト名 | 使用者 |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
AKS API サーバー |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Azure Container Registry (ACR) |
<account>.table.core.windows.net |
Azure Storage アカウント (テーブル ストレージ) |
<account>.blob.core.windows.net |
Azure Storage アカウント (BLOB ストレージ) |
api.azureml.ms |
Microsoft Entra 認証 |
ingest-vienna<region>.kusto.windows.net |
利用統計情報をアップロードするための Kusto エンドポイント |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
エンドポイントのドメイン名 (Azure Machine Learning で自動生成した場合)。 カスタム ドメイン名を使用した場合は、このエントリは必要ありません。 |
時系列での接続要件
AKS の作成またはアタッチのプロセスでは、Azure Machine Learning ルーター (azureml-fe) が AKS クラスターにデプロイされます。 Azure Machine Learning ルーターをデプロイするために、AKS ノードで次の処理が可能である必要があります。
- AKS API サーバーの DNS を解決する
- Azure Machine Learning ルーターの docker イメージをダウンロードするために、MCR の DNS を解決する
- 送信接続が必要な MCR からイメージをダウンロードする
azureml-fe はデプロイされるとすぐに開始しようとしますが、そのためにはユーザーが次のことを行う必要があります。
- AKS API サーバーの DNS を解決する
- AKS API サーバーにそれ自体の他のインスタンスを検出するためにクエリを実行する (マルチポッド サービス)
- それ自体の他のインスタンスに接続する
azureml-fe が開始されると、正常に機能するために次の接続が必要になります。
- Azure Storage に接続して動的構成をダウンロードする
- デプロイされたサービスが Microsoft Entra 認証を使ってる場合は、Microsoft Entra 認証サーバー api.azureml.ms の DNS を解決して、それと通信します。
- デプロイされたモデルを検出するために AKS API サーバーにクエリを実行する
- デプロイされたモデル POD と通信する
モデルのデプロイ時に、モデルのデプロイが成功するには、AKS ノードで次のことができる必要があります。
- お客様の ACR の DNS を解決する
- お客様の ACR からイメージをダウンロードする
- モデルが格納されている Azure BLOB の DNS を解決する
- Azure BLOB からモデルをダウンロードする
モデルがデプロイされてサービスが開始すると、azureml-fe は AKS API を使ってそれを自動的に検出し、要求をそれにルーティングできるようになります。 モデル POD と通信できる必要があります。
Note
デプロイされたモデルで何らかの接続が必要な場合 (外部データベースや他の REST サービスでのクエリの実行や、BLOB のダウンロードなど)、これらのサービスに対する DNS 解決と送信通信の両方が有効になっている必要があります。
AKS にデプロイする
AKS にモデルをデプロイするには、必要なコンピューティング リソースが記述されているデプロイ構成を作成します。 たとえば、コアの数やメモリなどです。 また、モデルと Web サービスのホストに必要な環境を記述した 推論構成 も必要です。 推論構成の作成の詳細については、「Azure Machine Learning service を使用してモデルをデプロイする」を参照してください。
注意
デプロイされるモデルの数は、デプロイごとに 1,000 モデル (コンテナーごと) に制限されます。
適用対象:  Python SDK azureml v1
Python SDK azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
この例で使われているクラス、メソッド、パラメーターの詳細については、次のリファレンス ドキュメントをご覧ください。
自動スケール
適用対象: Python SDK azureml v1
Azure Machine Learning モデル デプロイの自動スケールを処理するコンポーネントは、azureml-fe というスマート要求ルーターです。 すべての推論要求がそれを通過するため、そこにはデプロイされたモデルを自動的にスケーリングするために必要なデータがあります。
重要
モデル デプロイでは、Kubernetes のポッドの水平オートスケーラー (HPA) を有効にしないでください。 そうすると、2 つの自動スケーリング コンポーネントが互いに競合するようになります。 azureml-fe は、Azure Machine Learning によってデプロイされたモデルを自動スケールするように設計されています。この設計では、HPA が CPU 使用率やカスタム メトリック構成などの汎用メトリックから、モデルの使用率を推測または概算する必要があります。
azureml-fe によって、AKS クラスターのノードの数はスケーリングされません。これは、予期しないコストの増加につながる可能性があるからです。 その代わりに、物理クラスターの境界内でモデルのレプリカの数をスケーリングします。 クラスター内のノードの数をスケーリングする必要がある場合は、手動でクラスターをスケーリングするか、AKS クラスター オートスケーラーを構成することができます。
自動スケールは、AKS Web サービスに autoscale_target_utilization、autoscale_min_replicas、および autoscale_max_replicas を設定することで制御できます。 自動スケールを有効にする方法を次の例に示します。
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
スケールアップまたはスケールダウンの決定は、現在のコンテナー レプリカの使用率に基づきます。 ビジー状態 (要求を処理中) のレプリカの数を現在のレプリカの総数で除算した数が、現在の使用率です。 この数が autoscale_target_utilization を超えると、さらにレプリカが作成されます。 これが下回ると、レプリカが減少します。 既定では、ターゲット使用率は 70% です。
レプリカの追加は、集中的かつ迅速に決定されます (約 1 秒)。 レプリカの削除は慎重に決定されます (約 1 分)。
必要なレプリカの数は、次のコードを使用して計算できます。
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
autoscale_target_utilization、autoscale_max_replicas、autoscale_min_replicas の設定に関する詳細については、AksWebservice モジュール リファレンスを参照してください。
Web サービス認証
Azure Kubernetes Service にデプロイする場合、キーベース の認証は既定で有効になります。 トークン ベース の認証を有効にすることもできます。 トークン ベースの認証では、クライアントが Microsoft Entra アカウントを使用して認証トークンを要求する必要があります。これは、展開されたサービスへの要求を行うために使用されます。
認証を 無効 にするには、デプロイ構成の作成時に auth_enabled=False パラメーターを設定します。 次の例では、SDK を使用して認証を無効にします。
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
クライアント アプリケーションからの認証の詳細については、「Web サービスとしてデプロイされた Azure Machine Learning モデルを使用する」を参照してください。
キーによる認証
キー認証が有効になっている場合は、get_keys メソッドを使用して、プライマリおよびセカンダリ認証キーを取得できます。
primary, secondary = service.get_keys()
print(primary)
重要
キーを再生成する必要がある場合は、service.regen_key を使用します。
トークンによる認証
トークン認証を有効にするには、デプロイの作成時や更新時に token_auth_enabled=True パラメーターを設定します。 次の例では、SDK を使用してトークン認証を有効にします。
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
トークン認証が有効になっている場合は、get_token メソッドを使用して、JWT トークンとそのトークンの有効期限を取得できます。
token, refresh_by = service.get_token()
print(token)
重要
トークンの refresh_by 時刻が過ぎたら、新しいトークンを要求する必要があります。
AKS クラスターと同じリージョンに Azure Machine Learning ワークスペースを作成することを強くお勧めします。 トークンを使って認証を行うため、Web サービスは、Azure Machine Learning ワークスペースが作成されているリージョンに対して呼び出しを行います。 ワークスペースのリージョンが利用できない場合、クラスターがワークスペースとは異なるリージョンにあったとしても、Web サービスのトークンをフェッチできません。 その場合、ワークスペースのリージョンが再び利用できるようになるまで、事実上、トークン ベースの認証を利用できなくなります。 さらに、クラスターのリージョンとワークスペースのリージョンの間の距離が長くなるほど、トークンのフェッチにかかる時間も長くなります。
トークンを取得するには、Azure Machine Learning SDK または az ml service get-access-token コマンドを使用する必要があります。
脆弱性のスキャン
Microsoft Defender for Cloud では、統合されたセキュリティ管理と高度な脅威に対する保護がハイブリッド クラウド ワークロードに提供されます。 リソースのスキャンを Microsoft Defender for Cloud に許可し、その推奨事項に従う必要があります。 詳しくは、Microsoft Defender for Containers でのコンテナーのセキュリティに関する記事をご覧ください。
関連するコンテンツ
- Kubernetes 認可に Azure ロールベースのアクセス制御を使用する
- 仮想ネットワークを使用して Azure Machine Learning 推論環境をセキュリティで保護する
- カスタム コンテナーを使用してモデルをオンライン エンドポイントにデプロイする
- リモートでのモデル デプロイのトラブルシューティング
- デプロイされた Web サービスを更新する
- TLS を使用して Azure Machine Learning による Web サービスをセキュリティで保護する
- Web サービスとしてデプロイされた Azure Machine Learning モデルを使用する
- ML Web サービス エンドポイントからのデータを監視および収集する
- 実稼働環境のモデルからデータを収集する