チュートリアル: BLOB インベントリ レポートを分析する
BLOB とコンテナーが運用環境でどのように格納され、整理され、使用されるかを理解することで、コストとパフォーマンスのトレードオフをより適切に最適化できます。
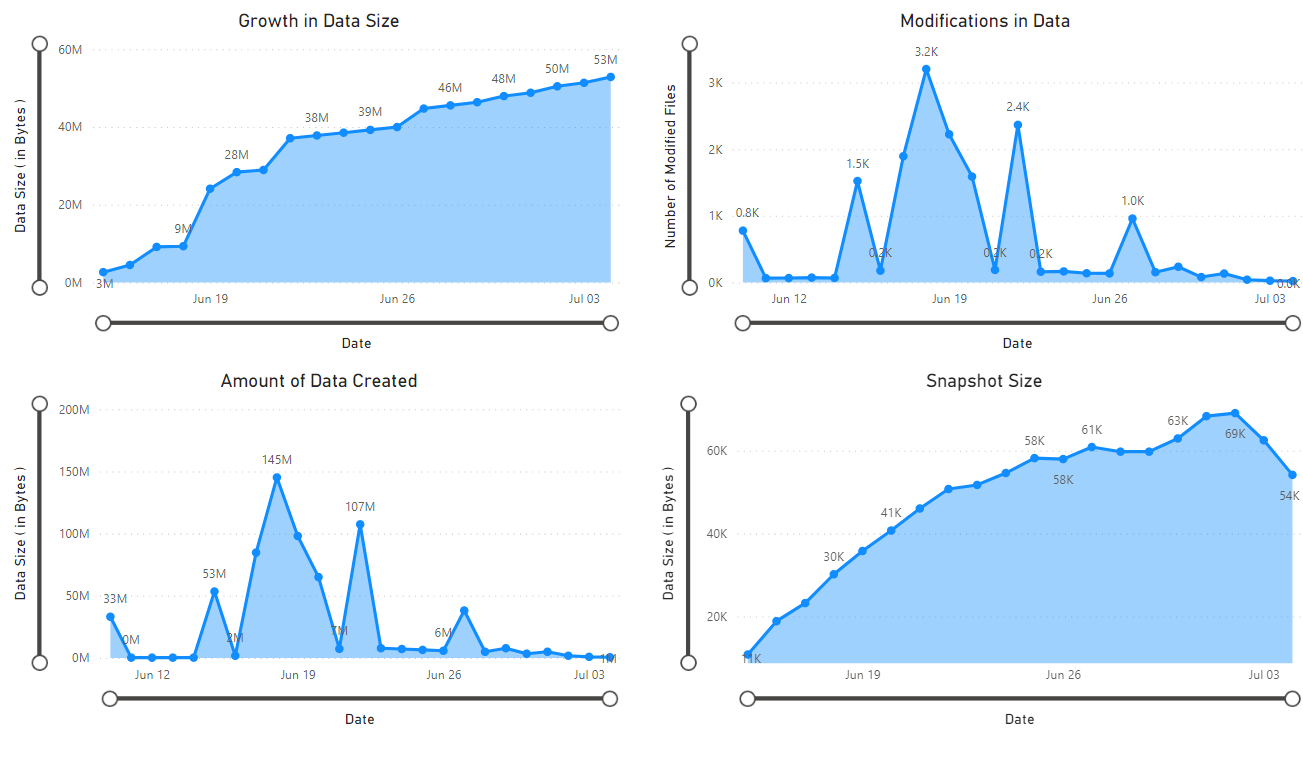
このチュートリアルでは、時間の経過に伴うデータの増加、時間の経過に伴うデータ追加、変更されたファイル数、BLOB スナップショットのサイズ、各階層のアクセス パターン、現在と時間の経過に伴うデータの分散方法などの統計情報を生成し、視覚化する方法について説明します (例: 複数の層、ファイルの種類、コンテナー、BLOB の種類にまたがるデータ)。
このチュートリアルでは、以下の内容を学習します。
- BLOB インベントリ レポートを生成する
- Synapse ワークスペースを設定する
- Synapse Studio を設定する
- Synapse Studio で分析データを生成する
- Power BI で結果を視覚化する
前提条件
Azure サブスクリプション - 無料のアカウントを作成する
Azure Storage アカウント - ストレージ アカウントを作成する
ユーザー ID にストレージ BLOB データ共同作成者ロールが割り当てられていることを確認します。
インベントリ レポートを生成する
ストレージ アカウントの BLOB インベントリ レポートを有効にします。 「Azure Storage BLOB のインベントリ レポートを有効にする」を参照してください。
インベントリ レポートを有効にしてから、最初のレポートを生成するには、最大で 24 時間待機することが必要な場合があります。
Synapse ワークスペースを設定する
Azure Synapse ワークスペースを作成します。 「Azure Synapse ワークスペースを作成する」を参照してください。
Note
ワークスペースを作成する一環として、階層型名前空間を持つストレージ アカウントを作成します。 Azure Synapse により、このアカウントに Spark テーブルとアプリケーション ログが格納されます。 Azure Synapse では、このアカウントを "プライマリ ストレージ アカウント" と呼びます。 混乱を避けるため、この記事では、インベントリ レポートを格納するアカウントを指す "インベントリ レポート アカウント" という用語を使います。
Synapse ワークスペースで、ユーザー ID に共同作成者ロールを割り当てます。 「Azure RBAC: ワークスペースの所有者ロール」を参照してください。
インベントリ レポート アカウントに移動し、ワークスペースのシステム マネージド ID にストレージ BLOB データ共同作成者ロールを割り当てて、Synapse ワークスペースにストレージ アカウントのインベントリ レポートにアクセスするアクセス許可を付与します。 「Azure portal を使用して Azure ロールを割り当てる」を参照してください。
プライマリ ストレージ アカウントに移動し、ユーザー ID に BLOB ストレージ共同作成者ロールを割り当てます。
Synapse Studio を設定する
Synapse Studio で Synapse ワークスペースを開きます。 「Synapse Studio を開く」を参照してください。
Synapse Studio で、自分の ID に Synapse 管理者のロールが割り当てられていることを確認します。 「Synapse RBAC: ワークスペースの Synapse 管理者ロール」を参照してください。
Apache Spark プールを作成する。 「サーバーレス Apache Spark プールを作成する」を参照してください。
サンプル ノートブックの設定と実行
このセクションでは、レポートで視覚化する統計データを生成します。 このチュートリアルを簡単にするために、このセクションではサンプルの構成ファイルとサンプルの PySpark ノートブックを使います。 このノートブックには、Azure Synapse Studio で実行するクエリのコレクションが含まれています。
サンプル構成ファイルの変更とアップロード
BlobInventoryStorageAccountConfiguration.json ファイルをダウンロードします。
そのファイルの次のプレースホルダーを更新します。
storageAccountNameをインベントリ レポート アカウントの名前に設定します。destinationContainerをインベントリ レポートを格納するコンテナーの名前に設定します。blobInventoryRuleNameを分析する結果を生成したインベントリ レポート規則の名前に設定します。accessKeyをインベントリ レポート アカウントのアカウント キーに設定します。
Synapse ワークスペースを作成したときに指定したプライマリ ストレージ アカウントのコンテナーにこのファイルをアップロードします。
サンプル PySpark ノートブックをインポートする
ReportAnalysis.ipynb サンプル ノートブックをダウンロードします。
Note
このファイルは必ず拡張子
.ipynbを付けて保存します。Synapse Studio で Synapse ワークスペースを開きます。 「Synapse Studio を開く」を参照してください。
Synapse Studio で、[開発] タブを選びます。
プラス記号 (+) を選んで項目を追加します。
[インポート] を選び、ダウンロードしたサンプル ファイルを参照してそのファイルを選び、[開く] を選びます。
[プロパティ] ダイアログ ボックスが表示されます。
[プロパティ] ダイアログ ボックスで [セッションの構成] リンクを選びます。
![[プロパティのインポート] ダイアログ ボックスのスクリーンショット。](media/storage-blob-inventory-report-analytics/import-properties-dialog-box.png)
[セッションの構成] ダイアログ ボックスが開きます。
[セッションの構成] ダイアログ ボックスの [アタッチ先] ドロップダウン リストで、この記事で先ほど作成した Spark プールを選びます。 次に [適用] ボタンを選びます。
Python ノートブックを変更する
Python ノートブックの最初のセルで、
storage_account変数の値をプライマリ ストレージ アカウントの名前に設定します。container_name変数の値を、そのアカウントで Synapse ワークスペースを作成したときに指定したコンテナーの名前に更新します。[発行] ボタンを選びます。
PySpark ノートブックを実行する
PySpark ノートブックで [すべて実行] を選びます。
Spark セッションの開始には数分かかります。また、インベントリ レポートの処理にはさらに数分かかります。 初回の実行は、処理するインベントリ レポートが多数ある場合に時間がかかることがあります。 以降の実行では、前回の実行以降に作成された新しいインベントリ レポートのみが処理されます。
Note
ノートブックが実行されている間にノートブックに変更を加えた場合は、必ず [発行] ボタンを使ってそのような変更を発行してください。
[データ] タブを選んで、ノートブックが正常に実行されたことを確認します。
[データ] ペインの [ワークスペース] タブに reportdata というデータベースが表示されます。 このデータベースが表示されない場合は、必要に応じて Web ページを更新します。
![reportdata データベースが表示されている [データ] ペインのスクリーンショット。](media/storage-blob-inventory-report-analytics/report-data-database.png)
このデータベースには一連のテーブルが含まれています。 各テーブルには、PySpark ノートブックからクエリを実して取得した情報が格納されています。
テーブルの内容を調べるには、reportdata データベースの Tables フォルダーを展開します。 次に、テーブルを右クリックし、[SQL スクリプトの選択] を選び、[上位 100 行を選択] を選びます。
必要に応じてクエリを変更し、[実行] を選んで結果を表示できます。
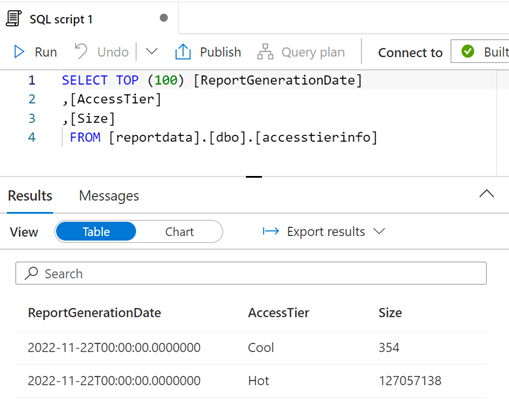
データの視覚化
ReportAnalysis.pbit サンプル レポート ファイルをダウンロードします。
Power BI Desktop を開きます。 インストール ガイダンスについては、「Power BI Desktop の取得」を参照してください。
Power BI で [ファイル]、[レポートを開く]、[レポートの参照] の順に選びます。
[開く] ダイアログ ボックスで、ファイルの種類を [Power BI テンプレート ファイル (*.pbit)] に変更します。
![[開く] ダイアログ ボックスに表示される Power BI テンプレート ファイルの種類のスクリーンショット。](media/storage-blob-inventory-report-analytics/file-type-setting.png)
ダウンロードした ReportAnalysis.pbit ファイルの場所を参照し、[開く] を選びます。
ダイアログ ボックスが表示され、Synapse ワークスペースの名前とデータベース名を指定するように求められます。
このダイアログ ボックスで、[synapse_workspace_name] フィールドをワークスペース名に設定し、[database_name] フィールドを
reportdataに設定します。 次に、[読み込む] ボタンを選びます。
ノートブックで取得したデータの視覚エフェクトが掲載されたレポートが表示されます。 次の図は、このレポートに表示されるチャートとグラフの種類を示したものです。
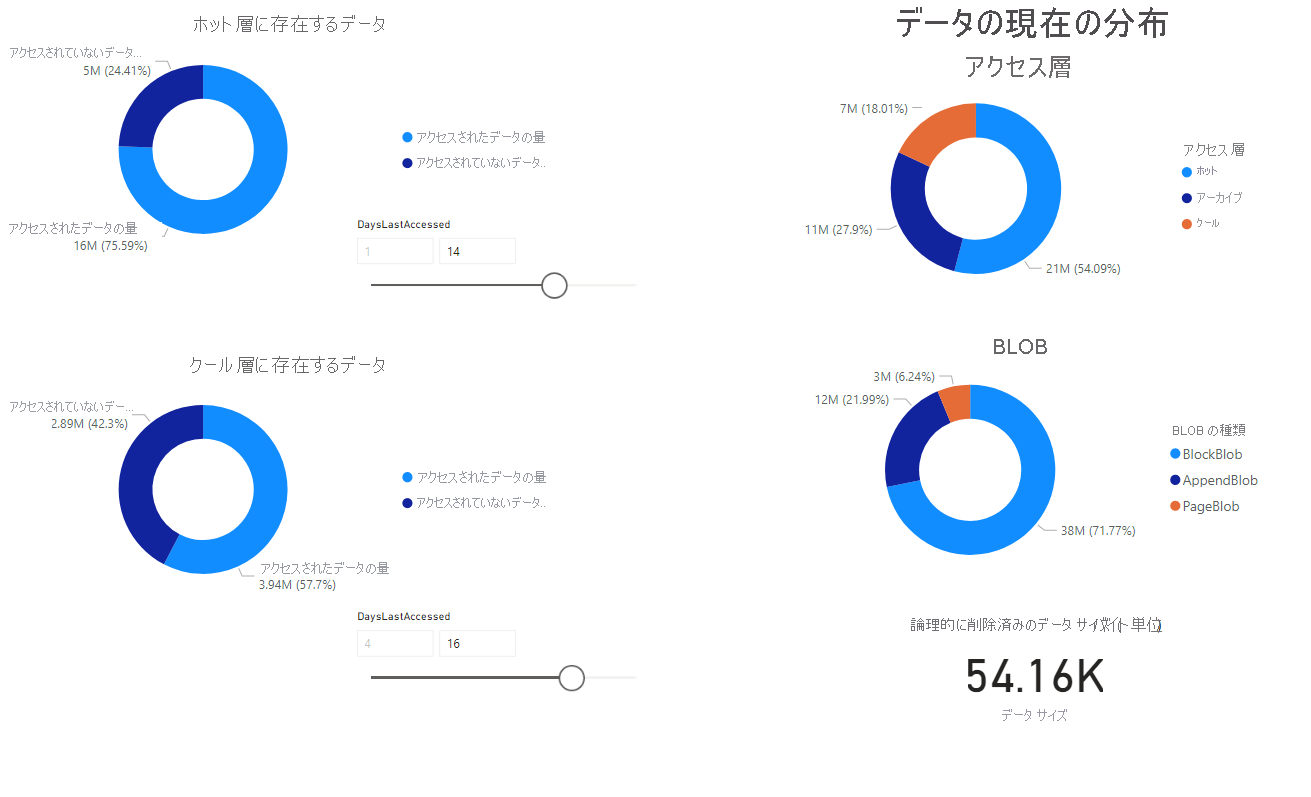
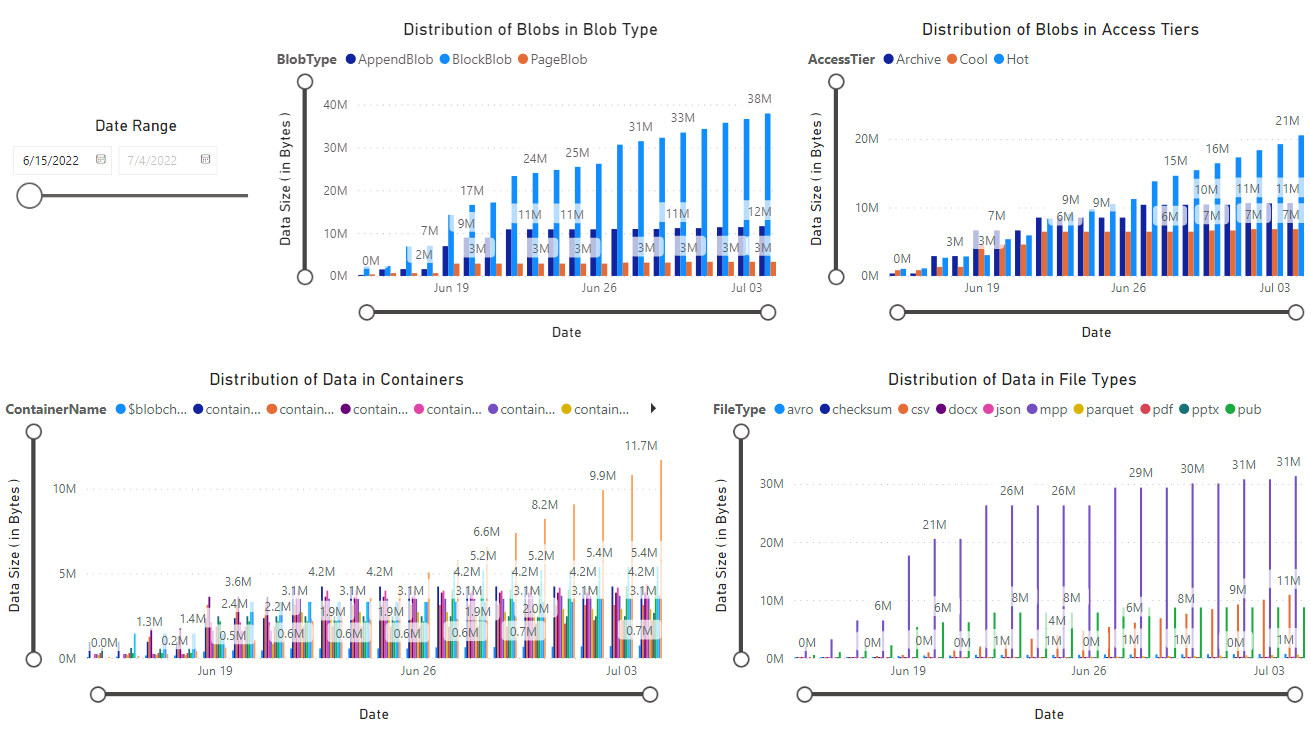
次のステップ
一定間隔でノートブックを実行し続けるように Azure Synapse パイプラインを設定します。 こうすることで、新しいインベントリ レポートを作成時に処理できます。 最初の実行後は、次の実行ごとに増分データが分析され、その分析結果を使ってテーブルが更新されます。 ガイダンスについては、「パイプラインと統合する」を参照してください。
ストレージ アカウントの個々のコンテナーを分析する方法を確認してください。 次の記事を参照してください。
BLOB とコンテナーの分析に基づいて、コストを最適化する方法を確認してください。 次の記事を参照してください。