Service Fabric の正常性モニタリングの概要
Azure Service Fabric に導入している正常性モデルは、機能が豊富で、柔軟性と拡張可能性を備えた正常性評価とレポートを提供します。 このモデルを使用すると、クラスターの状態とその内部で実行されているサービスの状態をほぼリアルタイムで監視することができます。 正常性の情報を容易に取得でき、潜在的な問題を事前に解決できるため、問題が連鎖的に発生して大規模なサービス停止を引き起こす事態を防げます。 一般的なモデルでは、サービスがローカルのビューに基づくレポートを送信し、その情報が集計されて、クラスター レベル全体のビューが提供されます。
Service Fabric のコンポーネントは、この豊富な機能を持つ正常性モデルを使用して、現在の状態を報告します。 アプリケーションからの正常性レポートにも同じメカニズムを使用できます。 カスタム条件をキャプチャする高品質の正常性レポートに投資すれば、実行中のアプリケーションの問題をより簡単に検出し、修正できます。
Service Fabric 正常性モデルとその使用方法を説明しているトレーニング ビデオについては、このページを確認してください。
Note
正常性サブシステムは、そもそも監視付きアップグレードの必要性から生まれました。 Service Fabric では、アプリケーションとクラスターのアップグレードを監視し、完全な可用性、ダウンタイムの防止、ユーザー操作の最小化を実現できます。 このような目標を達成するには、構成したアップグレード ポリシーに基づいて、アップグレードで正常性をチェックします。 所定のしきい値を守っている正常性の場合にのみ、アップグレードを進めることができます。 それ以外の場合、アップグレードは自動的にロールバックするか、一時停止して管理者に問題を解決する機会を提供します。 アプリケーションのアップグレードの詳細については、 この記事を参照してください。
正常性ストア
クラスターのエンティティに関する正常性関連の情報は、容易に取得して評価できるように、正常性ストアに保持されています。 これは、Service Fabric の永続的ステートフル サービスとして、高可用性とスケーラビリティを確保するために実装されています。 正常性ストアは、 fabric:/System アプリケーションの一部であり、クラスターが稼動し始めると、使用可能になります。
正常性エンティティと階層
正常性エンティティは異なるエンティティ間の相互作用と依存関係をキャプチャする論理階層に整理されます。 Service Fabric コンポーネントから受信したレポートに基づいて、正常性エンティティと階層が正常性ストアによって自動的に構築されます。
正常性エンティティは、Service Fabric エンティティを反映します。 (たとえば、正常性アプリケーション エンティティはクラスターにデプロイされているアプリケーション インスタンスと一致し、正常性ノード エンティティは Service Fabric クラスター ノードと一致します。)正常性の階層は、システム エンティティの相互作用をキャプチャしており、高度な正常性評価の基盤になります。 主要な Service Fabric の概念については、「 Service Fabric の技術概要」を参照してください。 アプリケーションに関する詳細については、「 Service Fabric アプリケーション モデル」を参照してください。
正常性エンティティと階層により、クラスターとアプリケーションのレポート作成、デバッグ、および監視が効果的に行えます。 正常性モデルにより、クラスター内にある数多くの変動要素の正常性を正確かつ 詳細に 表すことができます。
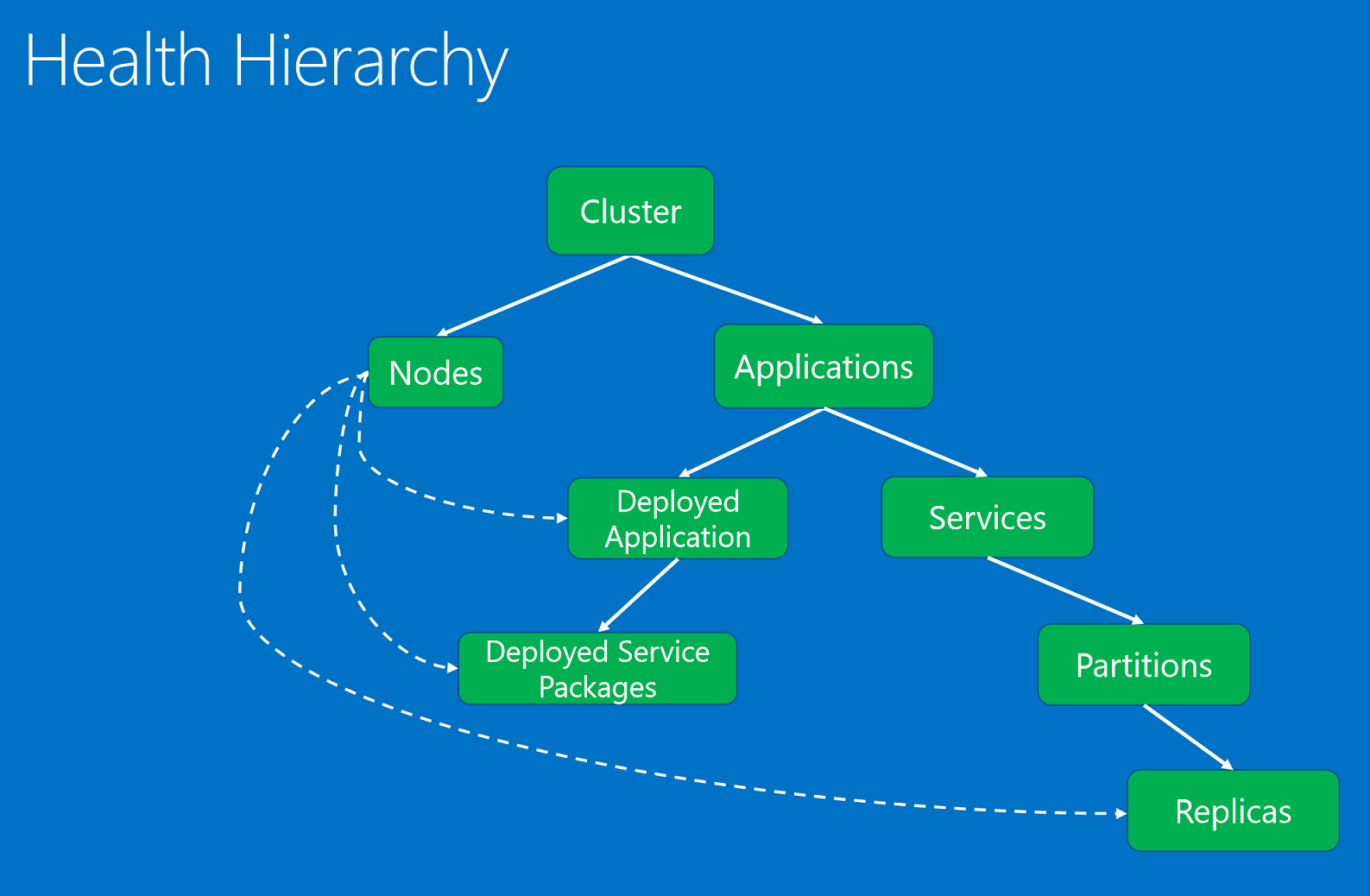 親子関係に基づく階層に分類された正常性エンティティ。
親子関係に基づく階層に分類された正常性エンティティ。
正常性エンティティは、次のとおりです。
- クラスター。 Service Fabric クラスターの正常性を表します。 クラスターの正常性レポートには、クラスター全体に影響を与える条件が記述されます。 これらの条件は、クラスター内の複数のエンティティまたはクラスター自体に影響を与えます。 このレポートでは、条件に基づいて、1 つまたは複数の正常ではない子まで問題を絞り込むことはできません。 たとえば、ネットワーク パーティション分割または通信の問題による、クラスターのスプリット ブレインなどがあります。
- Node。 Service Fabric ノードの正常性を表します。 ノードの正常性レポートには、ノードの機能に影響を与える条件が記述されます。 通常、これらの条件はノード上で実行中のデプロイされたエンティティすべてに影響します。 たとえば、ノードのディスク領域 (または、メモリや接続など、他のコンピューター全体のプロパティ) が不足している場合や、ノードが停止している場合などです。 ノードのエンティティは、ノード名 (文字列) で識別されます。
- アプリケーション。 クラスターで実行されているアプリケーション インスタンスの正常性を表します。 アプリケーションの正常性レポートには、アプリケーションの全体的な正常性に影響を与える条件が記述されます。 これらの条件は、個々の子 (サービスまたはデプロイされたアプリケーション) に絞ることはできません。 たとえば、アプリケーション内の異なるサービス間のエンド ツー エンド対話などです。 アプリケーション エンティティは、アプリケーション名 (URI) で識別されます。
- サービス。 クラスターで実行中のサービスの正常性を表します。 サービスの正常性レポートには、サービスの全体的な正常性に影響を与える条件が記述されます。 このレポートでは、正常ではないパーティションやレプリカまで問題を絞り込むことはできません。 たとえば、すべてのパーティションに問題を引き起こしているサービス構成 (ポートまたは外部ファイルの共有など) などです。 サービス エンティティは、サービス名 (URI) で識別されます。
- パーティション。 サービス パーティションの正常性を表します。 パーティションの正常性レポートには、レプリカ セット全体に影響を与える条件が記述されます。 たとえば、レプリカの数がターゲット数を下回る場合や、パーティションがクォーラム損失の状態にある場合などです。 パーティション エンティティは、パーティション ID (GUID) で識別されます。
- レプリカ。 ステートフル サービス レプリカ、またはステートレス サービス インスタンスの正常性を表します。 レプリカは、ウォッチドッグおよびシステム コンポーネントがアプリケーションに関するレポートを行うことができる最小単位です。 たとえば、ステートフル サービスの場合は、オプションをセカンダリや低速なレプリケーションにレプリケートできないプライマリ レプリカなどがあります。 また、ステートレス インスタンスでは、リソースが不足しているか、接続の問題が発生した場合にレポートを行うことができます。 レプリカ エンティティは、パーティション ID (GUID) およびレプリカまたはインスタンスの ID (Long 型) によって識別されます。
- DeployedApplication。 ノードで実行されているアプリケーションの正常性を表します。 デプロイされたアプリケーションの正常性レポートには、ノード上のアプリケーションに固有で、同じノードにデプロイされているサービス パッケージには絞ることができない条件が記述されます。 たとえば、アプリケーション パッケージをそのノードにダウンロードすることができない場合のエラーや、アプリケーションのセキュリティ プリンシパルをノードに設定する場合の問題などです。 デプロイされたアプリケーションは、アプリケーション名 (URI) とノード名 (文字列) で識別されます。
- DeployedServicePackage。 クラスター内のノードで実行されているサービス パッケージの正常性を表します。 これには、特定のサービス パッケージに固有で、同じアプリケーションの同じノードにある他のサービス パッケージには影響を与えない条件が記述されます。 たとえば、起動できないサービス パッケージのコード パッケージや、読み取ることができない構成パッケージなどです。 デプロイされたサービス パッケージは、アプリケーション名 (URI)、ノード名 (文字列)、サービス マニフェスト名 (文字列)、およびサービス パッケージ アクティブ化 ID (文字列) で識別されます。
正常性モデルの粒度により、問題の検出と修正が容易になります。 たとえば、サービスが応答していない場合、アプリケーション インスタンスが異常であるとレポートすることができます。 ただし、このレベルのレポートは理想的とは言えません。問題がアプリケーション内のすべてのサービスに影響するわけではない可能性があるからです。 レポートは異常なサービスに適用される必要があります。あるいは、特定の子パーティションを指定できるだけの情報がある場合は、そのパーティションに適用される必要があります。 このデータは自動的に階層を通過して表面化し、異常なパーティションはサービスとアプリケーションのレベルで視覚化されます。 この集計は、問題の根本原因をより迅速に特定して解決するのに役立ちます。
正常性の階層は親子関係で構成されています。 クラスターはノードとアプリケーションで構成されています。 アプリケーションにはサービスとデプロイされたアプリケーションがあります。 デプロイされたアプリケーションにはデプロイされたサービス パッケージがあります。 サービスはパーティションを含んでおり、各パーティションは 1 つまたは複数のレプリカを含んでいます。 ノードとデプロイされたエンティティの間には特別な関係があります。 ノード対して権限を持つシステム コンポーネント (Failover Manager サービス) によってノードの異常が報告された場合、デプロイされたアプリケーション、サービス パッケージ、そのノード上にデプロイされるレプリカに影響が及びます。
正常性の階層は、最新の正常性レポートに基づくシステムの最新の状態を表します。この情報は、ほぼリアルタイムの情報です。 内部および外部のウォッチドッグは、アプリケーション固有のロジックまたはカスタム監視付き条件に基づいて、同じエンティティに関して報告する場合があります。 ユーザー レポートはシステム レポートと共存します。
大規模なクラウド サービスの設計時に、正常性のレポート方法と対応方法に投資する計画を立ててください。 このような事前の投資によって、サービスのデバッグ、監視、運用が簡単になります。
正常性状態
Service Fabric は 3 つの正常性状態 (OK、警告、エラー) を使用してエンティティが正常な状態であるかどうかどうかを記述します。 正常性ストアに送信されるすべてのレポートには、これらの状態のいずれかを指定する必要があります。 正常性の評価結果は、これらの状態のいずれかです。
考えられる 正常性状態 は次のとおりです。
- OK。 エンティティは正常です。 そのエンティティ、およびその子 (該当する場合) に関して報告されている既知の問題はありません。
- 警告。 エンティティにいくつかの問題がありますが、まだ正常に機能することができます。 たとえば、遅延はありますが、まだ機能の問題は発生していない場合などです。 場合によっては、外部が介入することなく警告条件が解消することがあります。 正常性レポートを見ると、このような場合を認識し、状況を把握できます。 その他の場合、ユーザーが介入しないと、警告状態からより深刻な問題に悪化する可能性があります。
- エラー。 エンティティは異常です。 エンティティが正しく機能していないため、その状態を修正するアクションを取る必要があります。
- 不明。 エンティティは正常性ストアに存在しません。 この結果は、複数のコンポーネントからの結果をマージする分散クエリから取得できます。 たとえば、ノード リスト取得クエリは FailoverManager、ClusterManager、および HealthManager に行き、アプリケーション リスト取得クエリは ClusterManager と HealthManager に行きます。 これらのクエリは、複数のシステム コンポーネントからの結果をマージします。 別のシステム コンポーネントから正常性ストアに存在しないエンティティが返されると、マージされた結果の正常性状態は不明になります。 エンティティがストアに存在しない理由は、正常性レポートがまだ処理されていないか、削除後にエンティティがクリーンアップされたためです。
正常性ポリシー
正常性ストアは、正常性ポリシーを適用し、エンティティが正常かどうかをそのエンティティのレポートとその子に基づいて判断します。
Note
正常性ポリシーは、クラスター マニフェスト (クラスターおよびノードの正常性評価用) またはアプリケーション マニフェスト (アプリケーション評価およびその任意の子用) で指定できます。 正常性評価要求では、その評価にのみ使用される、カスタムの正常性評価ポリシーを渡すこともできます。
既定では、Service Fabric は親子階層関係に厳密なルール (すべて正常でなければならない) を適用します。 子の 1 つに 1 つの異常なイベントがある限り、親は異常と見なされます。
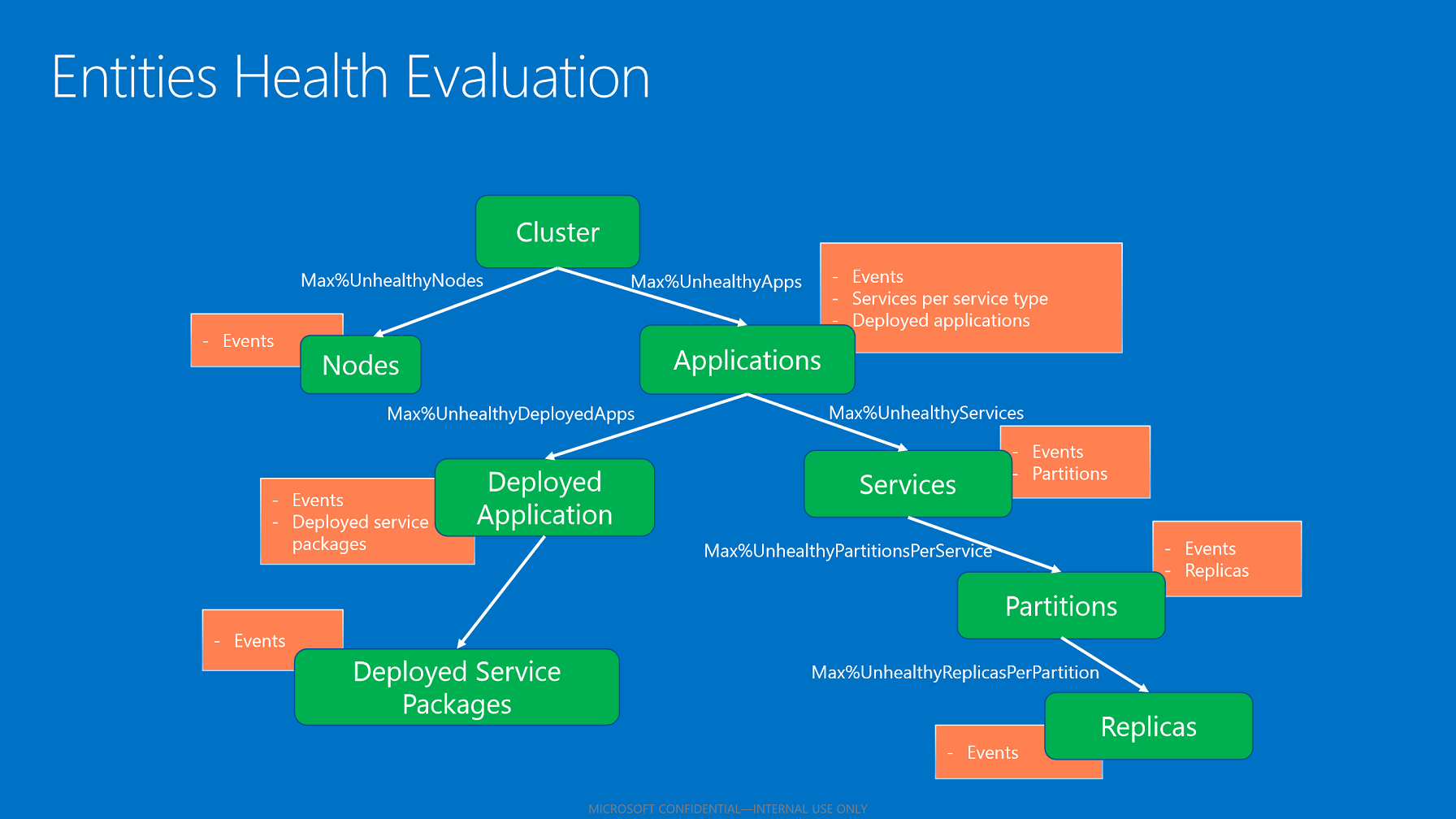
クラスターの正常性ポリシー
クラスターの正常性ポリシー は、クラスターの正常性状態とノードの正常性状態を評価するために使用されます。 このポリシーは、クラスター マニフェストで定義できます。 存在しない場合は、既定のポリシー (許容エラー数: 0) が使用されます。
クラスターの正常性ポリシーには以下のものが含まれます。
ConsiderWarningAsError。 警告の正常性レポートを正常性の評価中にエラーとして処理するかどうかを指定します。 既定値は false です。
MaxPercentUnhealthyApplications。 異常な可能性のあるアプリケーションの最大許容パーセンテージを指定します。この値を超えるとクラスターはエラーの状態と見なされます。
MaxPercentUnhealthyNodes。 異常な可能性のあるノードの最大許容パーセンテージを指定します。この値を超えるとクラスターはエラーの状態と見なされます。 大規模なクラスターでは、ダウンしているか修復を必要とするノードがいくつか必ず存在するため、それが許容されるようにこのパーセンテージを構成する必要があります。
ApplicationTypeHealthPolicyMap。 アプリケーションの種類の正常性ポリシー マップをクラスターの正常性評価時に使用して、特別なアプリケーションの種類を記述できます。 既定では、すべてのアプリケーションはプールに入れられ、MaxPercentUnhealthyApplications を使用して評価されます。 一部の種類のアプリケーションは、異なる方法で扱う必要がある場合にグローバル プールから除外することができます。 代わりに、マップでアプリケーションの種類名に関連付けられているパーセンテージに照らして評価されます。 たとえば、クラスターには、異なる種類の数千ものアプリケーションがあり、特別なアプリケーションの種類の制御アプリケーション インスタンスの数はわずかです。 制御アプリケーションがエラー状態になることはありません。 グローバルな MaxPercentUnhealthyApplications を 20% に指定していくつかのエラーを許容することはできますが、アプリケーションの種類が "ControlApplicationType" の場合は、MaxPercentUnhealthyApplications を 0 に設定します。 このようにすると、多くのアプリケーションのうちのいくつかが異常でも、グローバルな異常のパーセンテージを下回っている場合、クラスターは警告と評価されます。 警告の正常性状態はクラスターのアップグレードや、エラーの正常性状態によりトリガーされる他の監視には影響しません。 しかし、エラーになっている制御アプリケーションが 1 つでもある場合、クラスターが異常になり、アップグレードの構成に応じて、ロールバックがトリガーされたり、クラスター アップグレードが一時停止されたりします。 マップで定義されているアプリケーションの種類の場合は、すべてのアプリケーション インスタンスがアプリケーションのグローバル プールから除外されます。 これらは、マップの特定の MaxPercentUnhealthyApplications を使用して、該当するアプリケーションの種類のアプリケーションの総数に基づいて評価されます。 残りのアプリケーションはすべてグローバル プールで保持され、MaxPercentUnhealthyApplications を使用して評価されます。
次の例は、クラスター マニフェストからの抜粋です。 アプリケーションの種類マップでエントリを定義するには、パラメーター名の先頭に "ApplicationTypeMaxPercentUnhealthyApplications-" というプレフィックスを付け、パラメーター名の後にアプリケーションの種類名を続けます。
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>[https://login.microsoftonline.com/consumers/](
NodeTypeHealthPolicyMap) ノードの種類の正常性ポリシー マップをクラスターの正常性評価時に使用して、特別なノードの種類を記述できます。 ノードの種類は、マップでノードの種類名に関連付けられているパーセンテージに照らして評価されます。 この値を設定しても、MaxPercentUnhealthyNodesに使用されるノードのグローバル プールには影響しません。 たとえば、クラスターにはさまざまな種類の数百のノードがありますが、重要な作業をホストするのは少数のノードの種類です。 この種類のノードはダウンさせてはなりません。 すべてのノードについて、一部の失敗を許容するようグローバルMaxPercentUnhealthyNodesを 20% に設定できますが、ノードの種類SpecialNodeTypeについてはMaxPercentUnhealthyNodesを 0 に設定してください。 このようにすると、多くのノードのうちのいくつかが異常でも、グローバルな異常のパーセンテージを下回っている場合、クラスターは警告と評価されます。 正常性状態が警告であっても、クラスターのアップグレードや、正常性状態がエラーとなった場合にトリガーされる他の監視には影響しません。 ただし、SpecialNodeTypeノードのうち 1 つでも正常性状態がエラーとなった場合はクラスター異常となり、アップグレードの構成に応じて、ロールバックがトリガーされるか、クラスターのアップグレードが一時停止されます。 逆にグローバルMaxPercentUnhealthyNodesを 0 に設定した場合、SpecialNodeTypeの異常ノードを最大 100% に設定したとしても、グローバルな制限の方が厳しいため、SpecialNodeTypeの種類のノードが 1 つでもエラー状態になればクラスターはエラー状態となります。次の例は、クラスター マニフェストからの抜粋です。 ノードの種類のマップにエントリを定義するには、"NodeTypeMaxPercentUnhealthyNodes-" というプレフィックスを使い、ノード タイプ名を続けてください。
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
アプリケーションの正常性ポリシー
アプリケーションの正常性ポリシー は、アプリケーションとその子に関して、イベントの評価方法および子の状態の集計方法を記述します。 これは、アプリケーション パッケージにある、アプリケーション マニフェストの ApplicationManifest.xmlファイルで定義できます。 ポリシーが指定されていない場合、正常性状態が警告またはエラーの正常性レポートか子が見つかれば、Service Fabric はエンティティを異常と見なします。 構成可能なポリシーは、次のとおりです。
- ConsiderWarningAsError。 警告の正常性レポートを正常性の評価中にエラーとして処理するかどうかを指定します。 既定値は false です。
- MaxPercentUnhealthyDeployedApplications。 異常な可能性のあるデプロイされたアプリケーションの最大許容パーセンテージを指定します。この値を超えるとアプリケーションはエラーの状態と見なされます。 このパーセンテージは、デプロイされた異常なアプリケーションの数を、クラスター内でそのアプリケーションが現在デプロイされているノードの数で除算して計算されます。 切り上げ計算が実行され、少数のノードに対する 1 つのエラーは許容されます。 既定のパーセンテージは 0 です。
- DefaultServiceTypeHealthPolicy。 アプリケーション内のすべてのサービスの種類の既定の正常性ポリシーに代わる、既定のサービスの種類の正常性ポリシーを指定します。
- ServiceTypeHealthPolicyMap。 サービスの種類ごとのサービス正常性ポリシーのマップを指定します。 指定された各サービスの種類について、既定のサービスの種類の正常性ポリシーは、これらのポリシーに置き換えられます。 たとえば、アプリケーションにステートレスなゲートウェイ サービスの種類とステートフルなエンジン サービスの種類がある場合は、異なる方法で評価されるように正常性ポリシーを構成できます。 サービスの種類ごとにポリシーを指定すると、サービスの正常性をより細かく制御できます。
サービスの種類の正常性ポリシー
サービスの種類の正常性ポリシー は、サービスとサービスの子を評価および集計する方法を指定します。 このポリシーには以下のものが含まれます。
- MaxPercentUnhealthyPartitionsPerService。 異常なパーティションの最大許容パーセンテージを指定します。この値を超えるとサービスは異常と見なされます。 既定のパーセンテージは 0 です。
- MaxPercentUnhealthyReplicasPerPartition。 異常なレプリカの最大許容パーセンテージを指定します。この値を超えるとパーティションは異常と見なされます。 既定のパーセンテージは 0 です。
- MaxPercentUnhealthyServices。 異常なサービスの最大許容パーセンテージを指定します。この値を超えるとアプリケーションは異常と見なされます。 既定のパーセンテージは 0 です。
次の例は、アプリケーション マニフェストからの抜粋です。
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
正常性評価
ユーザーおよび自動化されたサービスは、いつでも任意のエンティティの正常性を評価できます。 エンティティの正常性を評価するため、正常性ストアは、エンティティに関するすべての正常性レポートを集計し、そのすべての子 (該当する場合) を評価します。 正常性の集計アルゴリズムでは、正常性レポートの評価方法と、子の正常性状態の集計方法 (該当する場合) を指定する正常性ポリシーを使用します。
正常性レポートの集計
1 つのエンティティに、さまざまなプロパティのさまざまなレポーター (システム コンポーネントやウォッチドッグ) から送信される複数の正常性レポートが含まれる場合があります。 集計には、関連付けられている正常性ポリシー、特にアプリケーションまたはクラスターの正常性ポリシーの ConsiderWarningAsError メンバーを使用します。 ConsiderWarningAsError は、警告の評価方法を指定します。
集計された正常性状態は、 エンティティの 最悪 の正常性レポートによってトリガーされます。 1 つでもエラーの正常性レポートがある場合は、集計された正常性状態はエラーになります。
1 つまたは複数のエラーの正常性レポートを持つ正常性エンティティは、エラーとして評価されます。 期限切れの正常性レポートも、正常性状態に関係なく、同様です。
エラーのレポートがなく、1 つまたは複数の警告がある場合、集計された正常性状態は警告またはエラーのいずれかであり、これは ConsiderWarningAsError ポリシーのフラグによって決まります。
警告のレポートがあり、ConsiderWarningAsError が false (既定値) に設定されている場合の正常性レポートの集計。
子の正常性の集計
エンティティの集計された正常性状態は、子の正常性状態を反映します (該当する場合)。 子の正常性状態を集計するためのアルゴリズムには、エンティティの種類に基づいて適用可能な正常性ポリシーが使用されます。
正常性ポリシーに基づく子の集計。
すべての子を評価した後、正常性ストアは異常な子の構成最大パーセンテージに基づいて、その正常性状態を集計します。 このパーセンテージは、エンティティと子の種類に基づくポリシーから取得されます。
- すべての子が OK の状態である場合は、子の集計正常性状態は OK です。
- OK と警告の両方の状態の子がある場合は、子の集計正常性状態は警告です。
- エラーの状態の子が、異常な子の最大許容パーセンテージを超える場合、親の集計正常性状態はエラーです。
- エラーの状態の子が、異常な子の最大許容パーセンテージ内である場合は、親の集計正常性状態は警告です。
正常性の報告
システム コンポーネント、Service Fabric アプリケーション、内部/外部のウォッチドッグは、Service Fabric エンティティに対してレポートすることができます。 レポーターは、監視対象エンティティの正常性を、監視条件に基づいて ローカルに 判定します。 これらは、グローバル状態や集計データを確認する必要がありません。 望ましいのは、送信すべき情報を推定するために多くのことを確認しなければならない複雑な構造体ではなく、単純なレポーターを持つことです。
正常性データを正常性ストアに送信するには、レポーターは影響を受けるエンティティを特定し、正常性レポートを作成する必要があります。 レポートを送信するには、FabricClient.HealthClient.ReportHealth API、Partition または CodePackageActivationContext オブジェクトで公開されている正常性レポート API、PowerShell コマンドレット、または REST を使用します。
正常性レポート
クラスターの各エンティティに関する 正常性レポート には、次の情報が含まれています。
SourceId。 正常性イベントのレポーターを一意に識別する文字列。
エンティティ識別子。 レポートを適用するエンティティを識別します。 この値は エンティティ型に応じて異なります:
- クラスター。 [なし] :
- ノード。 ノード名 (文字列)。
- アプリケーション をクリックします。 アプリケーション名 (URI)。 クラスターにデプロイされているアプリケーション インスタンスの名前を表します。
- サービス。 サービス名 (URI)。 クラスターにデプロイされているサービス インスタンスの名前を表します。
- パーティション。 パーティション ID (GUID)。 パーティションの一意の識別子を表します。
- レプリカ。 ステートフル サービス レプリカ ID またはステートレス サービス インスタンス ID (INT64)。
- DeployedApplication。 アプリケーション名 (URI) およびノード名 (文字列)。
- DeployedServicePackage。 アプリケーション名 (URI)、ノード名 (文字列)、およびサービス マニフェスト名 (文字列)。
プロパティ。 これは 文字列 (固定値列挙型ではない) で、レポーターはこれによってエンティティの特定のプロパティの正常性イベントを分類できます。 たとえば、レポーター A は Node01 の "ストレージ" プロパティの正常性をレポートし、レポーター B は Node01 の "接続" プロパティの正常性をレポートできます。 正常性ストアでは、これらのレポートは Node01 エンティティの別個の正常性イベントとして扱われます。
説明。 これは文字列で、レポーターはこれによって正常性イベントに関する詳細情報を提供できます。 SourceId、Property、および HealthState は、レポートを完全に記述する必要があります。 説明には、レポートに関する人間が判読できる情報が追加されます。 このテキストによって、管理者とユーザーは正常性レポートを理解しやすくなります。
HealthState。 列挙型 で、レポートの正常性状態を説明します。 有効な値は、"OK"、"警告"、および "エラー" です。
TimeToLive。 TimeSpan 型で、正常性レポートの有効期間を示します。 RemoveWhenExpiredと組み合わせて、期限切れイベントの評価方法を正常性ストアに通知します。 既定値は infinite で、レポートは永久に有効です。
RemoveWhenExpired。 ブール値。 true に設定されている場合、期限切れの正常性レポートは自動的に正常性ストアから削除され、エンティティの正常性評価には影響しません。 レポートが指定された期間のみ有効で、レポーターがレポートを明示的に消去する必要がない場合に使用されます。また、正常性ストアからレポートを削除する場合 (たとえば、ウォッチドッグが変更され、以前のソースとプロパティを使用したレポート送信を停止した場合) にも使用されます。 短い TimeToLive と RemoveWhenExpired を一緒に使用してレポートを送信し、正常性ストアから以前の任意の状態をクリアできます。 この値が false に設定されている場合、期限切れのレポートは正常性評価でエラーとして扱われます。 値を false にすると、このプロパティに関するソースからの定期的なレポートが必要であることが正常性ストアに通知されます。 通知されない場合は、ウォッチドッグに何らかの問題があります。 ウォッチドッグの正常性は、このイベントをエラーと見なすことによりキャプチャされます。
SequenceNumber。 正の整数値です。レポートの順序を表すものであり、増え続ける必要があります。 正常性ストアにより、ネットワークの遅延やその他の問題のために受信が遅れた古いレポートを検出するのに使用されます。 レポートのシーケンス番号が、同じエンティティ、ソース、およびプロパティに適用されている最新のシーケンス番号以下である場合、レポートは拒否されます。 指定されていない場合、シーケンス番号は自動的に生成されます。 状態遷移をレポートする場合にのみ、シーケンス番号を入力する必要があります。 この場合、ソースは送信したレポートを記憶し、フェールオーバー時の復旧用にその情報を保持する必要があります。
すべての正常性レポートに、SourceId、エンティティ識別子、プロパティおよび HealthState という 4 つの情報が必要です。 SourceId 文字列では、先頭に "System. " というプレフィックスを使用することはできません。これはシステム レポート用に予約されています。 同じエンティティの場合、同じソースとプロパティに対するレポートは 1 つだけ存在します。 同じソースとプロパティに対する複数のレポートは、正常性クライアント側 (バッチ処理される場合) または正常性ストア側で、互いにオーバーライドします。 置換はシーケンス番号に基づいて行われます。新しいレポート (シーケンス番号が大きい方) が古いレポートを置換します。
正常性イベント
内部的には、正常性ストアは 正常性イベントを保持しており、これにはレポートからのすべての情報と追加のメタデータが含まれています。 メタデータには、レポートが正常性クライアントに送信された時刻やレポートがサーバー側で変更された時刻が含まれています。 正常性イベントは、 正常性クエリによって返されます。
追加のメタデータは、次のとおりです。
- SourceUtcTimestamp。 レポートが正常性クライアントに送信された時刻 (世界協定時刻)。
- LastModifiedUtcTimestamp。 レポートがサーバー側で最後に変更された時刻 (世界協定時刻)。
- IsExpired。 正常性ストアでクエリが実行された時点でレポートが期限切れになるかどうかを示すフラグ。 イベントを期限切れにできるのは、RemoveWhenExpired が false の場合のみです。 それ以外の場合、イベントはクエリによって返されずに、ストアから削除されます。
- LastOkTransitionAt、LastWarningTransitionAt、LastErrorTransitionAt。 OK/警告/エラーの最終遷移時刻。 これらのフィールドは、イベントの正常性状態の遷移に関する履歴を提供します。
この状態遷移フィールドは、よりスマートなアラートや正常性イベントの "履歴" 情報に使用できます。 次のようなシナリオが可能です。
- プロパティが X 分間以上警告/エラー状態の場合はアラートを出す。 一定の時間にわたって条件を確認することで、一時的な状態に対するアラートが回避される。 たとえば、正常性状態の警告が 5 分より長く続いた場合にアラートを出すには、HealthState == Warning、Now - LastWarningTransitionTime > 5 minutes とします。
- 最後の X 分間に変更された条件のみに基づいてアラートを出す。 指定した時刻より前に既にエラーの状態にあったレポートについては、既に通知されているため、無視できます。
- プロパティが警告とエラーの状態を行き来している場合、異常とする (つまり、OK ではない) 時間を決定します。 たとえば、プロパティが正常でない状態が 5 分より長く続いたときにアラートを出すには HealthState != Ok、Now - LastOkTransitionTime > 5 minutes とします。
例:アプリケーションの正常性をレポートおよび評価する
次の例では、PowerShell を使用して、fabric:/WordCount というアプリケーションの正常性レポートを MyWatchdog というソースから送信します。 正常性レポートには、エラーの正常性状態の正常性プロパティ "availability" に関する情報が、無限に設定された TimeToLive と共に含まれています。 次に、アプリケーションの正常性がクエリされ、集計された正常性状態のエラーおよびレポートされた正常性イベントが正常性イベントの一覧で返されます。
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
正常性モデルの使用法
正常性モデルを使用することにより、監視と正常性判断がクラスター内のさまざまなモニター間に分散されるため、クラウド サービス、および基になる Service Fabric プラットフォームの拡張が可能になります。 他のシステムでは、クラスター レベルで集中管理されている単一のサービスで、サービスによって生成される " 潜在的に " 有用な情報すべてを解析しています。 この方法はスケーラビリティの妨げになっています。 また、問題や潜在的な問題の根本原因を可能な限り正確に識別するのに役立つ特定の情報を収集するのは困難です。
正常性モデルは、監視と診断、クラスターとアプリケーションの正常性の評価、および監視付きアップグレードに多用されます。 他のサービスは、正常性データを使用して自動修復を実行し、クラスターの正常性履歴を構築し、特定の条件でアラートを出します。