Service Fabric に興味をお持ちでしょうか。
Azure Service Fabric は、拡張性と信頼性に優れたマイクロサービスのパッケージ化とデプロイ、管理を簡単に行うことができる分散システム プラットフォームです。 ただし、Service Fabric は対象領域が広く、習得する必要のあることが多くあります。 この記事では、主要な概念、プログラミング モデル、アプリケーション ライフ サイクル、テスト、クラスター、正常性の監視など、Service Fabric の概念について説明します。 Service Fabric の紹介やこれを使用したマイクロサービスの作成方法については、「概要」および「マイクロサービスとは何か」をご覧ください。 この記事には、包括的な内容の一覧が含まれていませんが、Service Fabric の各領域の概要とファースト ステップ ガイドの記事へのリンクを掲載しています。
主要な概念
「Service Fabric の用語」、「アプリケーション モデル」、および「サポートされるプログラミング モデル」では詳細な概念や説明が提供されていますが、ここでは基本的な概念について説明します。
- Service Fabric クラスター: このリンクのトレーニング ビデオで、Service Fabric アーキテクチャとその主要概念の概要と、Service Fabric の多くの機能をご覧ください。
- 実行時の概念: このリンクでトレーニング ビデオを確認して、Service Fabric の実行時の概念とベスト プラクティスを理解してください。
- 設計の種類の概念: このリンクでトレーニング ビデオを確認して、アプリケーション、パッケージ化、デプロイ、主な Service Fabric の用語、抽象化、概念について理解してください。
設計時: サービスの種類、サービス パッケージとマニフェスト、アプリケーションの種類、アプリケーションのパッケージとマニフェスト
サービスの種類は、サービスのコード パッケージとデータ パッケージ、構成パッケージに割り当てられる名前/バージョンです。 これは、ServiceManifest.xml ファイルで定義されています。 このサービスの種類は、実行時に読み込まれる実行可能コードおよびサービス構成設定と、サービスによって消費される静的データで構成されます。
サービス パッケージは、サービスの種類の ServiceManifest.xml ファイルが含まれるディスクのディレクトリで、そのサービスの種類のコード、静的データ、および構成パッケージを参照します。 たとえばサービス パッケージは、データベース サービスを構成するコードや静的データ、構成パッケージを参照します。
アプリケーションの種類は、一連のサービスの種類に割り当てられる名前/バージョンです。 これは、ApplicationManifest.xml ファイルで定義されています。
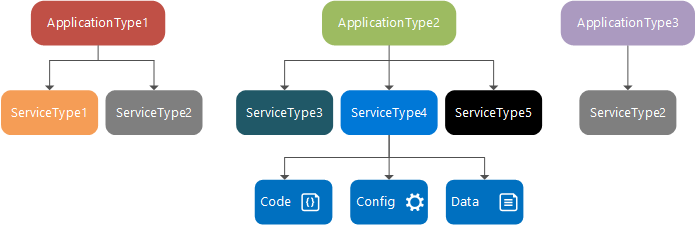
アプリケーション パッケージは、アプリケーションの種類の ApplicationManifest.xml ファイルが含まれているディスク ディレクトリであり、アプリケーションの種類を構成するサービスの種類ごとにサービス パッケージが参照されます。 たとえば電子メール アプリケーション タイプのアプリケーション パッケージであれば、Queue サービス パッケージやフロントエンド サービス パッケージ、データベース サービス パッケージへの参照が含まれることが考えられます。
アプリケーション パッケージ ディレクトリ内のファイルは、Service Fabric クラスターのイメージ ストアにコピーされます。 このアプリケーションの種類に基づいて名前付きアプリケーションを作成できます。作成したアプリケーションはクラスター内で実行します。 名前付きアプリケーションを作成した後、そのアプリケーションの種類のいずれかのサービスの種類から名前付きサービスを作成することができます。
実行時: クラスターとノード、名前付きアプリケーション、名前付きサービス、パーティション、およびレプリカ
Service Fabric クラスターは、ネットワークで接続された一連の仮想マシンまたは物理マシンで、マイクロサービスがデプロイおよび管理されます。 クラスターは多数のマシンにスケールできます。
クラスターに属しているコンピューターまたは VM をノードといいます。 それぞれのノードには、ノード名 (文字列) が割り当てられます。 ノードには、配置プロパティなどの特性があります。 それぞれのコンピューターまたは VM には、自動的に開始される Windows サービス (FabricHost.exe) が存在します。このサービスがコンピューターまたは VM の起動時に開始され、Fabric.exe と FabricGateway.exe の 2 つの実行可能ファイルを起動します。 ノードは、この 2 つの実行可能ファイルから成ります。 開発やテストのシナリオでは、Fabric.exe と FabricGateway.exe の複数のインスタンスを実行することによって、1 台のコンピューターまたは VM で複数のノードをホストできます。
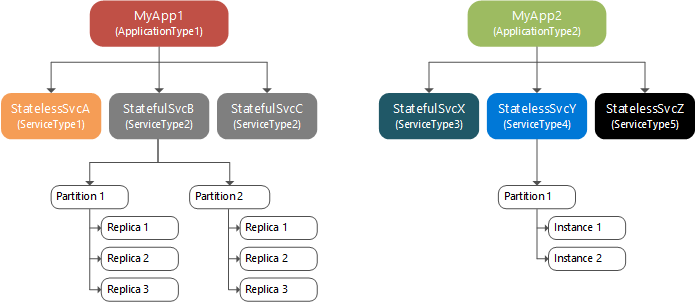
名前付きアプリケーションは、名前付きサービスのコレクションで、特定または複数の関数を実行します。 サービスは完全なスタンドアロンの機能を実行し (他のサービスから独立して開始、実行できる)、コード、構成、データで構成されます。 アプリケーション パッケージがイメージ ストアにコピーされた後、アプリケーション パッケージのアプリケーションの種類を (その名前/バージョンで) 指定することにより、そのアプリケーションのインスタンスをクラスター内に作成します。 アプリケーションの種類のインスタンスにはそれぞれ、URI 名が割り当てられます (例: fabric:/MyNamedApp)。 1 つのアプリケーションの種類から複数の名前付きアプリケーションをクラスター内で作成することが可能です。 異なるアプリケーションの種類から名前付きアプリケーションを作成することもできます。 個々の名前付きアプリケーションは別々に管理され、バージョニングされます。
名前付きアプリケーションを作成した後、そのいずれかのサービスの種類を (対応する名前/バージョンで) 指定することによって、特定のサービスの種類 (名前付きサービス) のインスタンスをクラスターに作成できます。 サービスの種類のインスタンスにはそれぞれ、対応する名前付きアプリケーションの URI に従属する URI 名が割り当てられます。 たとえば名前付きサービス "MyDatabase" を名前付きアプリケーション "MyNamedApp" 内に作成した場合、fabric:/MyNamedApp/MyDatabase のような URI が割り当てられます。 1 つの名前付きアプリケーションに複数の名前付きサービスを作成することができます。 名前付きサービスにはそれぞれ固有のパーティション構成とインスタンス/レプリカ数を割り当てることができます。
ステートレスとステートフルの 2 種類のサービスがあります。 ステートレス サービスは、サービス内に状態を保存しません。 ステートレス サービスでは、永続的なストレージが何もないか、Azure Storage、Azure SQL Database、Azure Cosmos DB などのように永続的な状態を外部ストレージ サービスに保存します。 ステートフル サービスはサービス内に状態を保存し、Reliable Collection あるいは Reliable Actors プログラミング モデルを使用して状態を管理します。
名前付きサービスを作成するときは、パーティション構成を指定します。 さまざまな状態を伴うサービスでは、データが複数のパーティションに分割されます。 各パーティションは、完全な状態のサービスの一部を担当し、クラスターのノード全体に分散されます。
次の図は、アプリケーションとサービス インスタンス、パーティション、レプリカ間のリレーションシップを示しています。
パーティション分割、スケーリング、および可用性
パーティション分割は Service Fabric に固有のものではありません。 よく知られているパーティション分割の形式として、データのパーティション分割またはシャーディングがあります。 さまざまな状態を伴うステートフル サービスでは、データが複数のパーティションに分割されます。 各パーティションは、完全な状態のサービスの一部を担当します。
各パーティションのレプリカがクラスターのノード間で分散され、名前付きのサービスの状態をスケールできます。 データ ニーズの拡大に応じて、パーティションが拡大し、Service Fabric はノード間でパーティションのバランスを再調整して、ハードウェア リソースを効率的に使用します。 新しいノードがクラスターに追加されると、Service Fabric は、増加したノード数全体で、パーティションのレプリカのバランスを再調整します。 アプリケーション全体のパフォーマンスが向上し、メモリへのアクセスの競合が減少します。 クラスター内のノードが効率的に使用されていない場合、クラスター内のノードの数を削減できます。 Service Fabric は、各ノードのハードウェアを効率的に利用できるように、減らされたノード数全体で、再度パーティション レプリカのバランスを再調整します。
パーティションには、ステートレスの名前付きサービスの場合はインスタンスが、ステートフルの名前付きサービスの場合はレプリカが格納されます。 通常、ステートレスの名前付きサービスは内部的な状態を持たないため、割り当てられるパーティションは 1 つだけですが、例外があります。 パーティションのインスタンスによってもたらされるのは可用性です。 つまり 1 つのインスタンスで障害が発生しても他のインスタンスは正常動作を保ち、Service Fabric によって新しいインスタンスが作成されます。 ステートフルの名前付きサービスでは、その状態がレプリカ内で管理されます。それぞれのパーティションが固有のレプリカ セットを持ちます。 読み取りおよび書き込み操作は、1 つのレプリカ (プライマリと呼ばれます) で実行されます。 書き込み操作からの状態の変更は、他の複数のレプリカ (アクティブ セカンダリと呼ばれます) にレプリケートされます。 万一レプリカに障害が発生した場合は、Service Fabric が既存のレプリカから新しいレプリカを構築します。
Service Fabric 用のステートレス マイクロサービスとステートフル マイクロサービス
Service Fabric では、マイクロサービスまたはコンテナーで構成されるアプリケーションを構築することができます。 ステートレス マイクロサービス (プロトコル ゲートウェイや Web プロキシなど) では、要求およびそのサービスからの応答以外では変更可能な状態が維持されません。 Azure Cloud Services worker ロールは、ステートレス サービスの一例です。 ステートフル マイクロサービス (ユーザー アカウント、データベース、デバイス、ショッピング カート、キューなど) では、要求およびその応答以外でも変更可能な認証状態が維持されます。 今日のインターネット規模のアプリケーションは、ステートレス マイクロサービスとステートフル マイクロサービスの組み合わせで構成されています。
Service Fabric との重要な違いは、組み込みプログラミング モデルまたはコンテナー化されたステートフル サービスで、ステートフル サービスの構築に大きな重点が置かれていることです。 アプリケーション シナリオでは、ステートフル サービスが使われるシナリオについて説明されています。
ステートレス マイクロサービスだけでなく、ステートフル マイクロサービスも必要である理由。 主に 2 つの理由があります。
- 同じコンピューター上でコードとデータを密接に保持することで、高スループット、低待機時間、エラー トレラントなオンライン トランザクション処理 (OLTP) サービスを構築できます。 例として、対話型のストアフロント、検索、モノのインターネット (IoT) システム、取引システム、クレジット カード処理、不正検出システム、個人記録管理などがあります。
- アプリケーションの設計を簡素化することができます。 完全にステートレスなマイクロサービスの可用性と待機時間の要件に対応するために、従来は追加のキューとキャッシュが必要でしたが、ステートフル マイクロサービスでは不要になります。 ステートフル サービスは高可用性と低待機時間が特徴であり、アプリケーション全体で管理すべき変動要素が少なくなります。
サポートされるプログラミング モデル
Service Fabric には、サービスの記述と管理に使用できる複数の方法が用意されています。 サービスでは Service Fabric API を使用して、プラットフォームの機能とアプリケーション フレームワークを最大限に活用できます。 サービスはまた、任意の言語で記述され、Service Fabric クラスターでホストされる任意のコンパイル済み実行可能プログラムにすることができます。 詳しくは、サポートされるプログラミング モデルに関する記事をご覧ください。
Containers
既定では、Service Fabric はサービスをプロセスとしてデプロイし、アクティブ化します。 また、Service Fabric ではコンテナー内のサービスもデプロイできます。 重要なこととして、プロセスとしてのサービスとコンテナー内のサービスを同じアプリケーション内で混在させることができます。 Service Fabric では、Linux コンテナーのデプロイと、Windows Server 2016 での Windows コンテナーのデプロイをサポートしています。 既存のアプリケーション、ステートレス サービス、またはステートフル サービスをコンテナーにデプロイできます。
Reliable Service
Reliable Services は軽量のフレームワークで、Service Fabric プラットフォームと統合した、プラットフォームの全機能を活用するサービスを作成できます。 Reliable Services は、Azure Cloud Services の Web サーバーや worker ロールなどの多くのサービス プラットフォームと同様にステートレスになる場合があり、状態は Azure DB や Azure Table Storage などの外部のソリューションに維持されます。 Reliable Services はステートフルになる場合もあり、状態は Reliable Collection を使用してサービスに直接維持されます。 状態はレプリケーションによって高可用になり、パーティションによって分散されます。いずれも Service Fabric で自動的に管理されます。
Reliable Actor
Reliable Actors フレームワークは Reliable Services 上に構築され、アクター設計パターンに基づいて、Virtual Actor パターンを実装するアプリケーション フレームワークです。 Reliable Actors フレームワークは、独立したコンピューティングのユニットと、アクターという単一スレッドの実行を含む状態を使用します。 Reliable Actors フレームワークには、アクターとプリセットされた状態の永続性とスケールアウト構成に対応する組み込みの通信が用意されています。
ASP.NET Core
Service Fabric は ASP.NET Core と統合することで、Web アプリケーションや API アプリケーションを構築するための優れたプログラミング モデルとして機能します。 ASP.NET Core は、Service Fabric で 2 とおりの方法で使用できます。
- ゲスト実行可能ファイルとしてホストする。 この方法は、主に、コードの変更なしで Service Fabric 上で既存の ASP.NET Core アプリケーションを実行するために使用します。
- リライアブル サービス内で実行する。 Service Fabric ランタイムとの統合がより密になり、ステートフルな ASP.NET Core サービスが可能になります。
ゲスト実行可能ファイル
ゲスト実行可能ファイルは、Service Fabric クラスターで他のサービスとともにホストされる既存の任意の実行可能ファイル (任意の言語で記述されたもの) です。 ゲスト実行可能ファイルは、Service Fabric API に直接統合されません。 ただし、カスタムの正常性と負荷のレポート、REST API を呼び出すことによるサービスの検出可能性など、プラットフォームに備わった機能からメリットを得られます。 また、完全なアプリケーションのライフサイクルのサポートも備えています。
アプリケーションのライフサイクル
その他のプラットフォームと同様に、通常、Service Fabric のアプリケーションは、デザイン、開発、テスト、デプロイ、アップグレード、保守、削除のフェーズを進みます。 Service Fabric は、開発からデプロイ、日常的な管理、保守、最終的な使用停止に至るまで、クラウド アプリケーションの完全なアプリケーション ライフサイクルに対して高度なサポートを提供します。 そのサービス モデルにより、アプリケーションのライフサイクルで個別に関与するさまざまな役割が有効になります。 「Service Fabric アプリケーションのライフサイクル」では、API の概要と、Service Fabric アプリケーション ライフサイクルのフェーズ全体でさまざまな役割がその API をどのように使用するかを示します。
アプリケーションのライフサイクル全体は、PowerShell コマンドレット、CLI コマンド、C# API、Java API、および REST API を使って管理できます。 Azure Pipelines や Jenkins などのツールを使用して、継続的インテグレーション/継続的なデプロイ パイプラインをセットアップすることもできます。
アプリケーションのライフサイクルを管理する方法を説明したトレーニングビデオについては、こちらのリンクをご覧ください。
アプリケーションとサービスをテストする
真のクラウド スケール サービスを作成するには、アプリケーションとサービスが現実の障害に耐えられるかを検証することが不可欠です。 Fault Analysis Service は、Service Fabric で構築されたサービスをテストするために設計されています。 Fault Analysis Service を使用すると、アプリケーションに対して意味のある障害を誘発させ、完全なテスト シナリオを実行することができます。 これらのエラーとシナリオでは、サービスがその有効期間中に経験する多数の状態と遷移を、完全に管理された安全で一貫性のある方法で実行して検証します。
アクションは、個別の障害を使用してテストするためのサービスを対象にします。 サービス開発者は、複雑なシナリオを記述するための構成要素としてアクションを使用できます。 シミュレートされる障害の例を次に示します。
- ノードを再起動して、コンピューターまたは VM がリブートされる状況をシミュレートします。
- ステートフル サービスのレプリカを移動して、負荷分散、フェールオーバー、またはアプリケーションのアップグレードをシミュレートします。
- ステートフル サービスでのクォーラムの損失を発生させ、新しいデータを受け入れるための十分な "バックアップ" または "セカンダリ" レプリカがないことが原因で書き込み操作を続行できない、という状況を作ります。
- ステートフル サービスでのデータ損失を発生させ、すべてのインメモリ状態が完全に消去された状況を作ります。
シナリオは、1 つまたは複数のアクションで構成される複雑な操作です。 Fault Analysis Service では、組み込みの完全なシナリオを 2 つ提供します。
- 混乱のシナリオ - 長時間にわたり、クラスター全体で、連続して交互に配置された (グレースフルと非グレースフルの両方) 障害がシミュレートされます。
- フェールオーバー シナリオ - 他のサービスに影響させずに、特定のサービス パーティションを対象にした、混乱のテスト シナリオの 1 つのバージョンです。
クラスター
Service Fabric クラスターは、ネットワークで接続された一連の仮想マシンまたは物理マシンで、マイクロサービスがデプロイおよび管理されます。 クラスターは多数のマシンにスケールできます。 クラスターに属しているコンピューターまたは VM をクラスター ノードといいます。 それぞれのノードには、ノード名 (文字列) が割り当てられます。 ノードには、配置プロパティなどの特性があります。 それぞれのコンピューターまたは VM には、自動的に開始されるサービス (FabricHost.exe) が存在します。このサービスがコンピューターまたは VM の起動時に開始され、Fabric.exe と FabricGateway.exe の 2 つの実行可能ファイルを起動します。 ノードは、この 2 つの実行可能ファイルから成ります。 テストのシナリオでは、Fabric.exe と FabricGateway.exe の複数のインスタンスを実行することによって、1 台のコンピューターまたは VM で複数のノードをホストできます。
Service Fabric クラスターは、Windows Server や Linux が動作している仮想マシン上や物理マシン上に作成できます。 オンプレミスか、Microsoft Azure 上か、任意のクラウド プロバイダー上かに関係なく、相互接続された一連の Windows Server コンピューターまたは Linux コンピューターがある任意の環境に、Service Fabric アプリケーションをデプロイして実行できます。
このリンクを参照して、サービス Service Fabric アーキテクチャ、そのコア概念、その他の多くのサービス ファブリック機能について説明するトレーニング ビデオを確認してください
Azure 上のクラスター
Azure で Service Fabric クラスターを実行すると、Azure の他の機能とサービスに統合されるため、クラスターの操作と管理が容易になり、信頼性が高まります。 クラスターは、Azure Resource Manager リソースであるため、Azure で他の任意のリソースのようにクラスターをモデル化できます。 Resource Manager では、クラスターで使用するすべてのリソースを 1 つの単位として簡単に管理することもできます。 Azure 上のクラスターは、Azure Diagnostics および Azure Monitor ログと統合されます。 クラスター ノードの種類は、仮想マシン スケール セットであるため、自動スケール機能が組み込まれています。
Azure Portal 経由で、テンプレートから、または Visual Studio から、Azure 上にクラスターを作成できます。
Linux 上の Service Fabric を使用すると、Windows 上と同じように、Linux で可用性とスケーラビリティの高いアプリケーションを構築、デプロイ、および管理できます。 Service Fabric フレームワーク (Reliable Services と Reliable Actors) は、Linux 上で、C# (.NET Core) に加え Java でも使用できるようになりました。 任意の言語またはフレームワークでゲスト実行可能サービスを構築することもできます。 調整 Docker コンテナーもサポートされています。 Docker コンテナーは、ゲスト実行可能ファイルまたはネイティブ Service Fabric サービスを実行できます。これらは、Service Fabric フレームワークを使用します。 詳細については、「Linux 上の Service Fabric」を参照してください。
Windows ではサポートされているものの Linux ではサポートされていない機能が一部存在します。 詳細については、「Linux での Service Fabric (プレビュー) と Windows での Service Fabric (一般公開) の違い」をご覧ください。
スタンドアロンのクラスター
Service Fabric には、オンプレミスまたは任意のクラウド プロバイダーにスタンドアロン Service Fabric クラスターを作成するインストール パッケージが用意されています。 スタンドアロン クラスターは、任意の場所でクラスターをホストする自由があります。 データがコンプライアンスや法的な制約を課せられる場合、またはデータをローカルに保持する場合は、独自のクラスターとアプリケーションをホストできます。 Service Fabric アプリケーションは、変更せずに複数のホスティング環境で実行できるため、アプリケーションの構築の知識を 1 つのホスティング環境から別の環境に持ち越すことができます。
初めての Service Fabric スタンドアロン クラスターの作成
Linux スタンドアロン クラスターはまだサポートされていません。
クラスターのセキュリティ
クラスターは、特に運用ワークロードが実行されている場合に、未承認ユーザーがクラスターに接続するのを防ぐためにセキュリティで保護する必要があります。 セキュリティで保護されていないクラスターを作成することはできますが、これを行うと、パブリック インターネットに管理エンドポイントを公開している場合に、匿名ユーザーがそのクラスターに接続できるようになります。 セキュリティ保護されていないクラスターに後からセキュリティを有効にすることはできません。クラスターのセキュリティは、クラスターの作成時に有効にします。
クラスターのセキュリティに関するシナリオは次のとおりです。
- ノード間のセキュリティ
- クライアントとノードの間のセキュリティ
- Service Fabric のロールベースのアクセス制御
詳細については、クラスターのセキュリティ保護に関するページを参照してください。
Scaling
新しいノードがクラスターに追加されると、Service Fabric は、増加したノード数全体で、パーティションのレプリカとインスタンスのバランスを再調整します。 アプリケーション全体のパフォーマンスが向上し、メモリへのアクセスの競合が減少します。 クラスター内のノードが効率的に使用されていない場合、クラスター内のノードの数を削減できます。 Service Fabric は、各ノードのハードウェアを効率的に利用できるように、減らされたノード数全体で、再度パーティションのレプリカとインスタンスのバランスを再調整します。 Azure 上のクラスターは、手動でまたはプログラムでスケールできます。 スタンドアロン クラスターは手動でスケールできます。
クラスターのアップグレード
定期的に、Service Fabric ランタイムの新しいバージョンがリリースされます。 常にサポートされるバージョンを実行しているように、クラスターで、ランタイム、またはファブリック、アップグレードを実行します。 ファブリックのアップグレードだけでなく、証明書やアプリケーション ポートなどのクラスター構成を更新することもできます。
Service Fabric クラスターはお客様が所有するリソースですが、一部は Microsoft によって管理されます。 Microsoft は、基になる OS の修正プログラムの適用や、クラスターでのファブリック アップグレードの実行を担当します。 クラスターは、新しいバージョンのファブリックがマイクロソフトからリリースされたときに自動アップグレードを適用するように設定できます。また、目的のサポートされているファブリック バージョンを選択するように設定することもできます。 ファブリックと構成のアップグレードは、Azure Portal から、またはリソース マネージャーから設定できます。 詳細については、「Azure Service Fabric クラスターのアップグレード」をご覧ください。
スタンドアロン クラスターは、ユーザーが完全に所有するリソースです。 基になる OS への修正プログラムの適用とファブリック アップグレードの開始はユーザーの責任です。 クラスターが https://www.microsoft.com/download に接続できる場合、新しい Service Fabric ランタイム パッケージを自動的にダウンロードして、プロビジョニングするようにクラスターを設定できます。 これにより、アップグレードを開始できます。 クラスターが https://www.microsoft.com/download にアクセスできない場合、インターネット接続されているコンピューターから新しいランタイム パッケージを手動でダウンロードしてアップグレードを開始できます。 詳細については、スタンドアロン Service Fabric クラスターのアップグレードに関するページをご覧ください。
正常性の監視
Service Fabric では、特定のエンティティ (クラスター ノードやサービス レプリカなど) で、問題のあるクラスターおよびアプリケーションの条件にフラグを設定することを目的とする 正常性モデル が導入されています。 正常性モデルは、正常性レポーター (システム コンポーネントとウォッチドッグ) を使用します。 その目標は、簡単かつ迅速な診断および修復です。 サービスの作成者は、正常性についてと正常性レポートの設計方法を事前に検討する必要があります。 正常性に影響する可能性があるすべての条件は、特にルートに近い問題にフラグを設定するために役立つ場合に、レポートする必要があります。 正常性の情報により、運用環境で、サービスが大規模に開始された後に、デバッグと調査にかかる時間と労力が削減されます。
Service Fabric レポーターは、識別された関心のある条件を監視します。 このレポーターは、そのローカル ビューに基づいて、これらの条件をレポートします。 正常性ストア は、すべてのレポーターによって送信された正常性データを集計して、エンティティがグローバルに正常な状態であるかどうかを判断します。 このモデルは、機能豊富、柔軟で、使いやすいように設計されています。 正常性レポートの品質によって、クラスターの正常性ビューがどの程度正確かが決定されます。 正常性の問題が誤って示される誤検知があると、正常性データを使用するアップグレードや他のサービスに悪影響が及びます。 このようなサービスの例として、修復サービスとアラート メカニズムがあります。 したがって、最適な方法で、関心のある条件をキャプチャするレポートを提供するには、ある程度の配慮が必要です。
レポートは、次のいずれかから作成できます。
- 監視対象の Service Fabric のサービス レプリカまたはインスタンス。
- Service Fabric のサービスとしてデプロイされる内部ウォッチドッグ (条件を監視して問題をレポートする Service Fabric ステートレス サービスなど)。 ウォッチドッグは、すべてのノードにデプロイするか、監視対象のサービスに関連付けることができます。
- Service Fabric のノードで実行されているが、Service Fabric のサービスとして実装されていない内部ウォッチドッグ。
- Service Fabric クラスター以外のリソースを調査する外部ウォッチドッグ (Gomez のような監視サービスなど)。
追加の設定なしで、Service Fabric コンポーネントは、クラスター内のすべてのエンティティの正常性をレポートします。 システム正常性レポートは、クラスターとアプリケーションの動作状況を視覚化し、正常性の問題を警告します。 システム正常性レポートは、アプリケーションとサービスを対象に、エンティティが実装されて正しく動作していることを Service Fabric ランタイムの観点から確認します。 レポートでは、サービスのビジネス ロジックの正常性監視や、応答しなくなったプロセスの検出は、提供されません。 サービスのロジックに固有の正常性情報を追加するには、サービスにカスタム正常性レポートを実装します。
Service Fabric には、正常性ストアに集計された正常性レポートを表示するために複数の方法が用意されています。
- Service Fabric Explorer またはその他の視覚化ツール。
- 正常性クエリ (PowerShell、CLI、C# FabricClient API および Java FabricClient API、または REST API を使用)。
- 正常性をプロパティの 1 つとして取得するエンティティの一覧を返す一般クエリ (PowerShell、CLI、API、または REST を使用)。
Service Fabric 正常性モデルとその使用方法を説明しているトレーニング ビデオについては、このページを確認してください。
監視と診断
監視と診断は、あらゆる環境でアプリケーションやサービスを開発、テスト、およびデプロイするために非常に重要です。 アプリケーションやサービスがローカル開発環境や運用環境で想定どおり機能するように監視と診断を計画し、実装する場合に、Service Fabric ソリューションは最も効果的に機能します。
監視と診断の主な目標は次のとおりです。
- ハードウェアとインフラストラクチャの問題の検出と診断
- ソフトウェアおよびアプリケーションの問題の検出と、サービス ダウンタイムの削減
- リソースの消費量の把握とドライブ操作の決定の支援
- アプリケーション、サービス、およびインフラストラクチャのパフォーマンスの最適化
- ビジネス上の洞察の創出と改善する領域の特定
監視と診断の全体的なワークフローは、次の 3 つの手順で構成されます。
- イベントの生成: これには、インフラストラクチャ (クラスター)、プラットフォーム、およびアプリケーション/サービス レベルでのイベント (ログ、トレース、カスタム イベント) が含まれます
- イベントの集計: 生成されたイベントを表示するには、生成されたイベントを収集して集計する必要があります
- 分析: イベントは、必要に応じて分析して表示できるように、視覚化して、特定の形式でアクセスできるようにする必要があります
この 3 つの領域すべてに対応する多数の製品があり、それぞれで異なるテクノロジを自由に選択できます。 詳しくは、「Azure Service Fabric での監視と診断」をご覧ください。
次のステップ
- Azure でのクラスターまたは Windows でのスタンドアロン クラスターを作成する方法を学びます。
- Reliable Services または Reliable Actors プログラミング モデルを使用してサービスを作成してみます。
- Cloud Services から移行する方法を学びます。
- サービスを監視および診断する方法を学びます。
- アプリとサービスをテストする方法を学びます。
- クラスター リソースを管理および調整する方法を学びます。
- Service Fabric サンプルを確認します。
- Service Fabric のサポート オプションについて学びます。
- チームのブログで記事やお知らせを読みます。