キーワード検索での関連性 (BM25 スコアリング)
この記事では、フルテキスト検索で検索スコアを計算するために使用される BM25 関連性スコアリングのアルゴリズムについて説明します。 BM25 関連性は、フルテキスト検索に限定されます。 フィルター クエリ、オートコンプリート、提案されたクエリ、ワイルドカード検索、あいまい検索の各クエリは、関連性についてスコアリングもランク付けもされません。
フルテキスト検索で使用されるスコアリング アルゴリズム
Azure AI Search には、フルテキスト検索用の次のスコアリング アルゴリズムが用意されています:
| アルゴリズム | 使用法 | Range |
|---|---|---|
BM25Similarity |
2020 年 7 月以降に作成されたすべての検索サービスでアルゴリズムを修正しました。 このアルゴリズムは構成可能ですが、古いアルゴリズム (クラシック) に切り替えることはできません。 | 無制限。 |
ClassicSimilarity |
2020 年 7 月以前の古い検索サービスの既定値。 以前の検索サービスでは、BM25 にオプトインし、インデックスごとに BM25 アルゴリズムを選択できます。 | 0 < 1.00 |
BM25 とクラシックはいずれも TF-IDF タイプの取得関数です。この関数では、単語の出現頻度 (TF) と逆文書頻度 (IDF) が変数として使用され、ドキュメントとクエリの組みごとに関連スコアが計算されます。ドキュメントとクエリの組みはその後、ランク付けの結果に使用されます。 概念的にはクラシックと似ていますが、BM25 は確率論的情報取得に根ざしており、ユーザーの調査で測定した場合のように、より直感的な一致が生成されます。
BM25 には高度なカスタマイズ オプションがあります。たとえば、ユーザーは、一致した用語の出現頻度で関連性スコアが変動するしくみを決定できます。
BM25 ランク付けのしくみ
関連性のスコアリングとは、検索スコア (@search.score) を計算することです。これは、現在のクエリのコンテキストにおける項目の関連性のインジケーターとして機能します。 範囲は無制限です。 ただし、スコアが高いほど、項目の関連性が高くなります。
検索スコアは、文字列入力とクエリ自体の統計プロパティに基づいて計算されます。 Azure AI Search では、検索語句に一致するドキュメント ( searchModeに応じて一部または全部) が検索され、検索語句の多くのインスタンスを含むドキュメントが優先されます。 データ インデックス全体での語句の出現頻度は低いがドキュメント内ではよく使用されている場合、検索スコアはより高くなります。 関連性を計算するこのアプローチの基礎となる手法は、TF-IDF (単語の出現頻度 - 逆文書頻度) と呼ばれています。
検索スコアは、結果セット全体で繰り返すことができます。 同じ検索スコアを持つ項目が複数ヒットした場合、同じスコアを持つ項目の順序付けは定義されていないので安定しません。 クエリを再度実行すると、特に、複数のレプリカで無料のサービスまたは課金対象サービスを使用している場合は、項目の位置が変わる場合があります。 同一スコアの項目が 2 つ存在する場合、どちらが最初に表示されるかは特定できません。
繰り返しスコアの間の関係を解除するには、$orderby 句を追加することで、まずスコアで並べ替えを行い、次に別の並べ替え可能なフィールド ($orderby=search.score() desc,Rating desc など) で並べ替えを行うことができます。
スコアリングには、インデックスで searchable としてマークされているフィールド、またはクエリで searchFields としてマークされているフィールドのみが使用されます。
retrievable としてマークされたフィールド、またはクエリの select で指定されたフィールドのみが、検索スコアと共に検索結果に返されます。
Note
@search.score = 1 は、スコア付けまたは順位付けが行われていない結果セットを示します。 スコアは、すべての結果にわたって均一です。 スコア付けされていない結果が発生するのは、クエリ フォームがファジー検索、ワイルドカード、または正規表現のクエリである場合、または空の検索である場合 (search=* がフィルターとペアで指定され、一致を返す主な手段がフィルターである場合があります) です。
次のビデオ セグメントでは、Azure AI Search で使用される一般提供の優先度付けアルゴリズムの説明に早送りしています。 詳しい背景情報については、ビデオ全編をご覧ください。
テキスト結果のスコア
結果がランク付けされるたびに、@search.score プロパティには結果の順序付けに使用される値が含まれます。
次の表は、スコアリング プロパティ、アルゴリズム、および範囲を示しています。
| 検索メソッド | パラメーター | スコアリング アルゴリズム | Range |
|---|---|---|---|
| フルテキスト検索 | @search.score |
BM25 アルゴリズム。インデックスで指定されたパラメーターを使用します。 | 無制限。 |
スコア バリエーション
検索スコアは、一般的な意味での関連性を示すものであり、同じ結果セット内の他のドキュメントと比べた場合の一致の強さが反映されています。 ただし、スコアは、あるクエリと次のものとの間で必ずしも一貫しているとは限らないため、クエリを操作していると、検索ドキュメントの順序付け方法における小さな不一致に気付くことがあります。 これが発生する理由については、次のいくつかの説明があります。
| 原因 | 説明 |
|---|---|
| 同一のスコア | 複数のドキュメントのスコアが同じである場合、それらはいずれも最初に表示される可能性があります。 |
| データの不安定性 | ドキュメントを追加、変更、または削除すると、インデックス コンテンツは変動します。 インデックスの更新が徐々に処理されるに従って用語頻度は変化し、一致するドキュメントの検索スコアに影響を与えます。 |
| 複数のレプリカ | 複数のレプリカを使用するサービスの場合、クエリは、各レプリカに対して並列に発行されます。 検索スコアを計算するために使用されるインデックス統計はレプリカごとに計算され、クエリ応答の中で結果がマージされ、順序付けられます。 レプリカのほとんどは互いのミラーですが、状態の小さな違いのために統計は異なる場合があります。 たとえば、あるレプリカで、他のレプリカからマージされた、その統計に寄与しているドキュメントが削除されることがあります。 通常、レプリカごとの統計の違いは、小さなインデックスの方がより顕著です。 この条件について詳しくは、以下のセクションで説明します。 |
クエリ結果に対するシャーディング効果
"シャード" とは、インデックスのチャンクです。 Azure AI Search では、インデックスをさらに "シャード" に分割し、(シャードを新しい検索単位に移動することによって) パーティションを追加するプロセスを高速化しています。 検索サービスでは、シャード管理は実装の詳細であり、構成できませんが、インデックスがシャード化されているとわかっていれば、順位付けやオートコンプリートの動作で不定期に発生する異常を容易に把握できます。
異常のランク付け: 検索スコアは最初にシャード レベルで計算され、続いて単位の結果セットに集計されます。 シャード コンテンツの特性に応じて、あるシャードからの一致が別のシャードの一致よりも高い順位になる場合があります。 検索結果の順位付けが直観に反しているように感じられる場合は、シャーディングの影響が原因である可能性が最も高いです (特にインデックスが小さい場合)。 インデックス全体でグローバルにスコアを計算するように選択すれば、これらの順位付けの異常を回避できますが、その場合、パフォーマンスが低下します。
オートコンプリートの異常: オートコンプリート クエリでは、部分的に入力された語句の最初のいくつかの文字で照合が行われますが、スペルの少しの間違いを許容するあいまいパラメーターが使用されます。 オートコンプリートの場合、あいまい一致は現在のシャード内の用語に限定されます。 たとえば、シャードに "Microsoft" が含まれており、"micro" という部分的な語句が入力された場合、検索エンジンはそのシャード内の "Microsoft" と一致しますが、インデックスの残りの部分を保持した他のシャードでは一致しません。
次の図は、レプリカ、パーティション、シャード、および検索単位間の関係を示しています。 ここでは、2 つのレプリカと 2 つのパーティションを持つサービスで、どのように 1 つのインデックスが 4 つの検索単位にわたっているかを例で示しています。 4 つの検索単位それぞれには、インデックスのシャードの半分だけが格納されます。 左側の列の検索単位は、シャードの前半を格納して最初のパーティションを構成し、右側の列の検索単位は、シャードの後半を格納して 2 番目のパーティションを構成しています。 レプリカが 2 つあるため、各インデックス シャードのコピーは 2 つあります。 上部の行の検索単位は、1 つのコピーを格納して最初のレプリカを構成し、下部の行の検索単位は、別のコピーを格納して 2 番目のレプリカを構成しています。
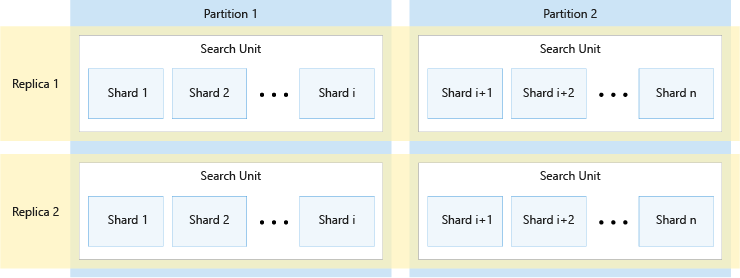
上の図は 1 つの例にすぎません。 パーティションとレプリカはさまざまに組み合わせることができ、最大で合計 36 の検索単位が可能です。
Note
レプリカとパーティションの数は、均等に 12 分割されます (具体的には、1、2、3、4、6、12)。 Azure AI Search では各インデックスを 12 のシャードに事前に分割して、それぞれがすべてのパーティションに均等に分散されるようにします。 たとえば、サービスに 3 つのパーティションがあり、インデックスを作成する場合、各パーティションにはインデックスの 4 つのシャードを含めます。 Azure AI Search でインデックスがどのようにシャードされるかは実装の詳細であり、今後のリリースで変更される場合があります。 今日 12 個であっても、今後も必ず 12 個になるとは限りません。
スコアリング統計とスティッキー セッション
スケーラビリティのために、Azure AI Search はシャーディング プロセスを通じて各インデックスを水平方向に配布します。つまり、インデックスの 部分は物理的に個別です。
既定では、ドキュメントのスコアは、"シャード内" のデータの統計プロパティに基づいて計算されます。 このアプローチは、一般に、データの大規模なコーパスでは問題にならず、すべてのシャードの情報に基づいてスコアを計算する必要がある場合よりもパフォーマンスが向上します。 ただし、このパフォーマンスの最適化を使用すると、2 つの非常に類似したドキュメント (またはまったく同一のドキュメント) は、それぞれが異なるシャードになる場合、関連性スコアが異なる可能性があります。
すべてのシャードの統計プロパティに基づいてスコアを計算する場合、これを行うには、scoringStatistics=global をクエリ パラメーターとして追加します (またはクエリ要求の本文パラメーターとして "scoringStatistics": "global" を追加します)。
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"scoringStatistics": "global"
}
scoringStatistics を使用すると、同じレプリカのすべてのシャードで同じ結果が得られるようになります。 ただし、レプリカはインデックスの最新の変更で常に更新されるため、それぞれ若干異なる場合があります。 一部のシナリオでは、ユーザーが "クエリ セッション" 中により一貫した結果を得られるようにすることが求められる場合があります。 このようなシナリオでは、クエリの一部として sessionId を指定できます。
sessionId は、一意のユーザー セッションを参照するために作成する一意の文字列です。
POST https://[service name].search.windows.net/indexes/hotels/docs/search?api-version=2024-07-01
{
"search": "<query string>",
"sessionId": "<string>"
}
同じ sessionId が使用されていれば、同じレプリカをターゲットにするためにベストエフォートの試行が行われるので、ユーザーに表示される結果の一貫性が向上します。
Note
同じ sessionId 値を繰り返し再利用すると、レプリカ間での要求の負荷分散が妨げられ、検索サービスのパフォーマンスに悪影響を与える可能性があります。 sessionId として使用される値は、'_' 文字で始めることはできません。
関連性のチューニング
Azure AI 検索では、キーワード検索とハイブリッド クエリのテキスト部分に対して、BM25 アルゴリズム パラメーターを構成し、次のメカニズムを使用して検索の関連性を調整し、検索スコアを向上させることができます。
| アプローチ | 実装 | 説明 |
|---|---|---|
| BM25 アルゴリズムの構成 | Search index | ドキュメントの長さと用語の頻度が関連性スコアに与える影響を構成します。 |
| スコアリング プロファイル | Search index | コンテンツ特性に基づいて一致の検索スコアを向上させる基準が指定されます。 たとえば、収益の見込みに基づいて一致をブーストしたり、より新しいアイテムをプロモートしたり、場合によっては在庫期間が長すぎるアイテムをブーストしたりできます。 スコアリング プロファイルは、インデックス定義の一部であり、重み付けされたフィールド、関数、およびパラメーターで構成されます。 スコアリング プロファイルの変更によって既存のインデックスを更新できます。インデックスの再構築は必要ありません。 |
| セマンティック ランク付け | クエリ要求 | 検索結果に機械読解を適用し、意味的に関連性の高い結果を上位に昇格させます。 |
| featuresMode パラメーター | クエリ要求 | このパラメーターは、多くの場合、BM25 スコアのアンパックに使用されますが、カスタム スコアリング ソリューションを提供するコードで使用されることもあります。 |
featuresMode パラメーター (プレビュー)
ドキュメントの検索要求では、フィールド レベルでの BM25 関連性スコアの詳細を提供する featuresMode パラメーターがサポートされます。
@searchScore はドキュメント全体に対して計算されますが (このクエリのコンテキストにおけるこのドキュメントの関連度)、featuresMode を使用すると、@search.features 構造体で表現された、個々のフィールドに関する情報が明らかになります。 この構造体には、クエリで使用されるすべてのフィールド (クエリ内の searchFields を介した特定のフィールド、またはインデックス内で検索可能として属性が付けられているすべてのフィールド) が含まれます。
フィールドごとに、@search.features では次の値が取得されます。
- フィールド内で見つかった一意のトークン数
- 類似性スコア。つまり、クエリ用語に対するフィールド内容の類似度のメジャー
- 用語の頻度。つまり、フィールド内でクエリ用語が見つかった回数
"Description" および "title" フィールドを対象とするクエリの場合、@search.features を含む応答は次のようになります。
"value": [
{
"@search.score": 5.1958685,
"@search.features": {
"description": {
"uniqueTokenMatches": 1.0,
"similarityScore": 0.29541412,
"termFrequency" : 2
},
"title": {
"uniqueTokenMatches": 3.0,
"similarityScore": 1.75451557,
"termFrequency" : 6
}
}
}
]
カスタムのスコアリング ソリューションでこれらのデータ ポイントを使用したり、この情報を使用して検索の関連性の問題をデバッグしたりできます。
featuresMode パラメーターは REST API のドキュメントには記載されていませんが、BM25 ランクによるテキスト検索 (キーワード) 検索に対するプレビュー REST API 呼び出しで使用できます。
フルテキスト クエリ応答のランク付けされた結果の数
既定では、改ページを使用していない場合、検索エンジンはフルテキスト検索では上位 50 位のランクの一致を返します。
top パラメーターを使用して、返されるアイテム数を減らしたり増やしたりできます (1 回の応答で 1,000 個まで)。
skip と next を使用して結果をページングすることができます。 ページングは、各論理ページの結果数を決定し、コンテンツ ナビゲーションをサポートします。 詳細については、「検索結果の形状設定」を参照してください。
フルテキスト クエリがハイブリッド クエリの一部である場合は、maxTextRecallSize を設定することで、クエリのテキスト側からの結果の数を増減することができます。
フルテキスト検索には、最大 1,000 件の一致という制限が適用されます (「API 応答の制限」を参照)。 1,000 件の一致が見つかると、検索エンジンはそれ以上の検索を行いません。