スコアリング プロファイルを追加して検索スコアを上げる
スコアリング プロファイルを使用すると、条件に基づいて一致するドキュメントのランク付けをブーストすることができます。 この記事では、指定したパラメーターに基づいて検索スコアをブーストさせるスコアリング プロファイルを指定して割り当てる方法について説明します。
スコアリング プロファイルは、キーワード検索、ベクトル検索、ハイブリッド検索に使用できます。 ただし、スコアリング プロファイルはベクトル以外のフィールドにのみ適用されるため、スコアリング プロファイルで使用できるテキスト フィールドまたは数値フィールドがインデックスに含まれていることを確認してください。 ベクトルおよびハイブリッド検索のスコアリング プロファイル サポートは、2024-05-01-preview および 2024-07-01 REST API と、これらのリリースを対象とする Azure SDK パッケージで使用できます。
スコアリング プロファイルに関する重要なポイント
スコアリング プロファイル パラメーターは、次のいずれかです。
特定の文字列フィールドで一致が見つかった、重み付けフィールド。 たとえば、"summary" フィールドで見つかった一致について、"content" フィールドで見つかった同じ一致よりも関連性を高くしたい場合があります。
日付、範囲、地理座標などの数値データ用の関数。 任意の文字列コレクションを提供するフィールドで動作するタグ関数もあります。 tags フィールドで一致が見つかったかどうかに基づいてスコアをブーストする場合は、重み付けフィールドよりもこのアプローチを選択できます。
複数のプロファイルを作成し、クエリ ロジックを変更して、使用するプロファイルを選択できます。
インデックスには最大 100 個のスコアリング プロファイルを含めることができます (サービスの制限に関する記事を参照) が、クエリには一度に 1 つのプロファイルのみ指定できます。
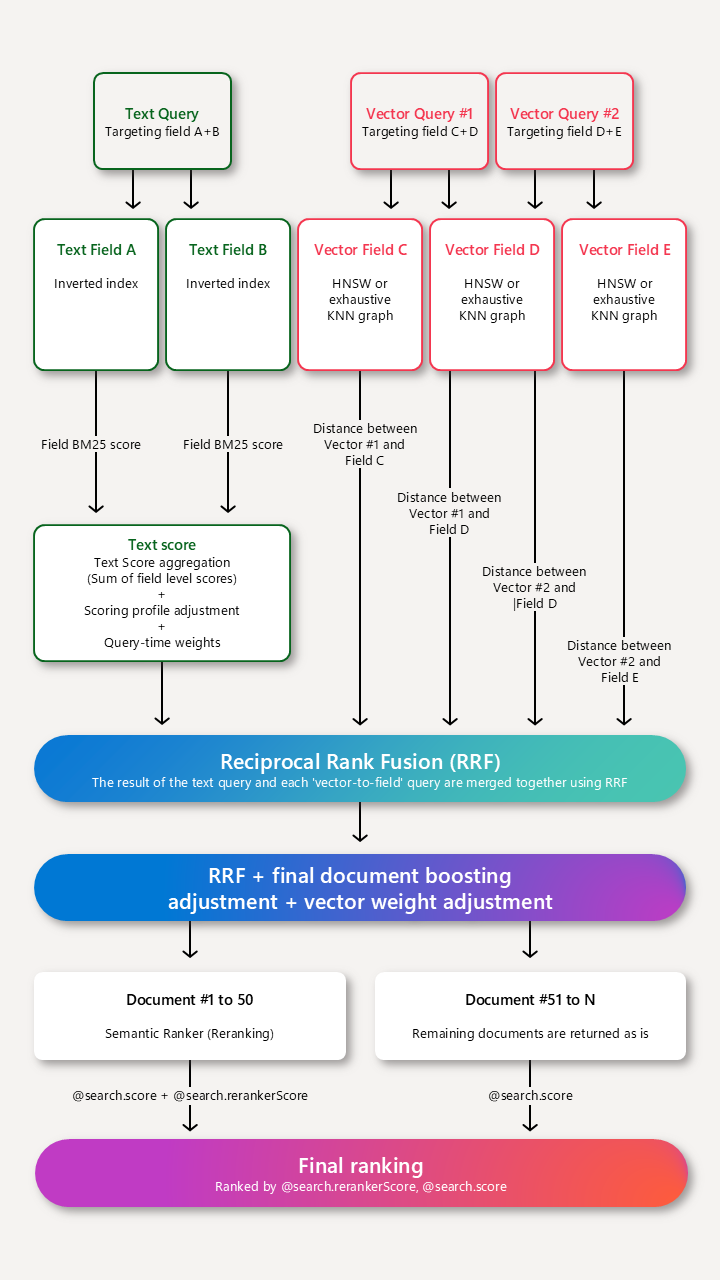
スコアリング プロファイルでセマンティック ランカーを使用できます。 複数のランク付け機能または関連性機能が機能している場合、セマンティック ランク付けは最後の手順です。 検索スコアリングのしくみには図が用意されています。
Note
関連性の概念について詳しく理解するには、 背景については、Azure AI 検索での関連性とスコアリングに関するページを参照してください。 また、BM25 ランク付けされた結果のスコアリング プロファイルについては、この YouTube の動画セグメントもご覧ください。
スコアリング プロファイルの定義
スコアリング プロファイルは、インデックス スキーマで定義されている名前付きオブジェクトです。 スコアリング プロファイルは、重み付けフィールド、関数、パラメーターで構成されます。
次の定義は、"geo" という名前の単純なプロファイルを示しています。 この例では、hotelName フィールド内の検索語句を含む結果をブーストします。 また、distance 関数を使用して、現在の場所から 10 キロメートル以内にある結果を優先します。 他のユーザーが語句 "inn" の検索を実行し、"inn" がたまたまホテル名の一部であった場合、現在位置の半径 10 Km 以内にあって "inn" を含むホテルが記載されているドキュメントが検索結果で上位に表示されます。
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
このスコアリング プロファイルを使用するには、クエリを作成して、要求に scoringProfile パラメーターを指定します。 REST API を使用している場合、クエリは GET および POST 要求を使用して指定されます。 次の例では、"currentLocation" には単一のダッシュ (-) の区切り記号があります。 その後に経度と緯度の座標が続き、経度は負の値です。
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
POST を使用する場合の構文の違いに注意してください。 POST では、"scoringParameters" は複数形であり、配列です。
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
このクエリは、語句 "inn" を検索し、現在の場所を渡します。 このクエリには、scoringParameter などの他のパラメーターが含まれていることがわかります。 "scoringParameter" などのクエリ パラメーターについては、「ドキュメントの検索 (REST API)」を参照してください。
その他のシナリオについては、「ベクトルおよびハイブリッド検索の拡張例」と「キーワード検索の拡張例」を参照してください。
Azure AI 検索での検索スコアリングのしくみ
スコアリング プロファイルは、プロファイルの条件を満たす一致のスコアをブーストすることで、既定のスコアリング アルゴリズムを補完します。 スコアリング関数は次に適用されます。
- テキスト (キーワード) 検索
- 純粋なベクトル クエリ
- テキストおよびベクトル サブクエリを並列で実行するハイブリッド クエリ
スタンドアロン テキスト クエリの場合、スコアリング プロファイルは BM25 ランク検索で最大 1,000 件の一致を識別し、上位 50 件が結果として返されます。
純粋なベクトルの場合、クエリはベクトル専用ですが、k 一致するドキュメントに、人間が判別できるコンテンツがある非ベクトル フィールドが含まれている場合は、スコアリング プロファイルを適用できます。 スコアリング プロファイルは、プロファイル内の条件に一致するドキュメントをブーストして、結果セットを修正します。
ハイブリッド クエリのテキスト クエリの場合、スコアリング プロファイルは BM25 ランク検索で最大 1,000 件の一致を識別します。 ただし、これらの 1,000 件の結果が特定されると、その元の BM25 の順序に復元され、ベクターの結果と共に再スコア付けされ、最終的な逆数ランク付け関数 (RRF) の順序になります。ここで、スコアリング プロファイル (図では "最終ドキュメントブースト調整" として識別されます) がマージされた結果に適用され、ベクターの重み付けとセマンティック ランク付けが最後の手順として適用されます。
スコアリング プロファイルを検索インデックスに追加する
まず、インデックス定義から始めます。 既存のインデックスでスコアリング プロファイルを追加および更新できます。インデックスを再構築する必要はありません。 リビジョンを投稿するには、インデックスの作成または更新要求を使用します。
この記事に記載されているテンプレートに貼り付けます。
名前付け規則に準拠した名前を指定します。
ブースト条件を指定します。 1 つのプロファイルには、テキスト重み付けフィールド、関数、またはその両方を含めることができます。
特定のプロファイルの有効性を証明または誤りを証明するために役立つデータ セットを使用して、反復的な作業を行う必要があります。
次のスクリーンショットに示すように、スコアリング プロファイルは Azure portal で定義できます。また、REST API や Azure SDK (Azure SDK for .NET の ScoringProfile クラスなど) を使用してプログラムから定義することもできます。
![[スコアリング プロファイルの追加] ページ](media/scoring-profiles/portal-add-scoring-profile.png#lightbox)
テキスト重み付けフィールドを使用する
フィールド コンテキストが重要で、クエリに searchable 文字列フィールドが含まれる場合は、テキスト重み付けフィールドを使用します。 たとえば、クエリに "airport" という語句が含まれる場合は、Description フィールドの "airport" の重みを HotelName よりも大きく設定できます。
重み付けフィールドは、searchable フィールドと乗数として使用される正の数で構成される名前と値のペアです。 HotelName の元のフィールド スコアが 3 の場合、そのフィールドのブーストされたスコアは 6 になり、親ドキュメント自体の全体のスコアが高くなります。
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Functions の使用
数値データに対する計算である距離や鮮度の場合のように、単純かつ相対的な重みが不足している場合、または適用されない場合は、関数を使用します。 スコアリング プロファイルごとに複数の関数を指定できます。 Azure AI Search で使用される EDM データ型の詳細については、「 サポートされているデータ型」を参照してください。
| 関数 | 説明 | ユース ケース |
|---|---|---|
| distance | 近接または地理的位置によりブーストします。 この関数は、 Edm.GeographyPoint フィールドでのみ使用できます。 |
"近くを検索" シナリオに使用します。 |
| freshness | datetime フィールド (Edm.DateTimeOffset) の値によってブーストします。
boostingDuration を設定して、ブーストが行われる期間を表す値を指定します。 |
新しいまたは以前の日付でブーストする場合に使用します。 カレンダー イベントなどの項目を将来の日付で順位付けして、現在に近い項目が遠い将来の項目よりも上位に順位付けされるようにします。 範囲の一方の端は現在時刻に固定されます。 過去の時間範囲をブーストするには、正の boostingDuration を使用します。 将来の時刻の範囲をブーストするには、負の値の boostingDuration を使用します。 |
| magnitude | 数値フィールドの値の範囲に基づいて順位付けを変更します。 値は整数または浮動小数点数にする必要があります。 1 ~ 4 の星評価を対象とする場合、これは 1 になります。 50% を超える利益を対象とする場合、これは 50 になります。 この関数は、Edm.Double フィールドと Edm.Int フィールドでのみ使用できます。 magnitude 関数では、逆のパターンが必要な場合 (たとえば、価格がより高い項目より価格がより低い項目をブーストする場合) に、高範囲から低範囲に反転することができます。 たとえば、価格の範囲が 100 ~ 1 ドルである場合、boostingRangeStart を 100 に、boostingRangeEnd を 1 に設定して、より低い価格の項目をブーストします。 |
利益率、評価、クリックスルー数、ダウンロード数、最高価格、最低価格、またはダウンロード数でブーストする場合に使用します。 2 つの項目が該当する場合は、評価の高い方の項目が最初に表示されます。 |
| タグ | 検索ドキュメントとクエリ文字列の両方に共通するタグでブーストします。 タグは tagsParameter で指定されます。 この関数は、Edm.String および Collection(Edm.String) 型の検索フィールドでのみ使用できます。 |
タグ フィールドがある場合に使用します。 リスト内の特定のタグ自体がコンマ区切りのリストである場合は、フィールドに対してテキスト ノーマライザーを使用して、クエリ時にコンマを取り除くことができます (コンマ文字をスペースにマップします)。 この方法では、すべての語句がコンマ区切りの 1 つの長い文字列になるようにリストを "フラット化" します。 |
関数の使用に関する規則
- 関数は、
filterableとして属性付けされたフィールドにのみ適用できます。 - 関数型 ("freshness"、"magnitude"、"distance"、"tag") は小文字にする必要があります。
- 関数に null または空の値を含めることはできません。
- 関数には、関数定義ごとに 1 つのフィールドのみを含めることができます。 同じプロファイルで magnitude を 2 回使用するには、フィールドごとに 1 つずつ、2 つの magnitude 定義を指定します。
Template
このセクションでは、スコアリング プロファイルの構文とテンプレートを示します。 プロパティの説明については、REST API リファレンスを参照してください。
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
補間の設定
補間により、スコアリングに使用する傾きの形状が設定されます。 スコアリングは高から低なので、傾きは常に減少ですが、補間により下向きの傾きの曲線が決まります。 次の補間を使用できます。
| 補間 | 説明 |
|---|---|
linear |
最大値と最小値の範囲内にある項目の場合、ブーストは一定量ずつ減少して適用されます。 線形はスコアリング プロファイルの既定の補間です。 |
constant |
開始と終了の範囲内にある項目については、一定のブーストが順位の結果に適用されます。 |
quadratic |
ブーストが一定の割合で減少する線状補間と比較して、二次の場合、最初は遅いペースで減少しますが、終了範囲に近づくにつれて減少するペースが速くなります。 tag スコアリング関数では、この補間オプションは使用できません。 |
logarithmic |
ブーストが一定の割合で減少する線状補間と比較して、対数の場合、最初は速いペースで減少しますが、終了範囲に近づくにつれて減少するペースが遅くなります。 tag スコアリング関数では、この補間オプションは使用できません。 |

freshness 関数の boostingDuration を設定する
boostingDuration は freshness 関数の属性です。 これを使用して特定のドキュメントに対して有効期限を設定します。この期限が過ぎるとブースティングは停止します。 たとえば、10 日のプロモーション期間中に製品ラインまたはブランドをブーストするには、該当するドキュメントに対して 10 日の期間を "P10D" で指定します。
boostingDuration は、XSD "dayTimeDuration" 値 (ISO 8601 期間値の制限されたサブセット) としてフォーマットする必要があります。 このパターンは、"P[nD][T[nH][nM][nS]]" です。
次の表に、いくつかの例を示します。
| 長さ | boostingDuration |
|---|---|
| 1 日 | "P1D" |
| 2 日と 12 時間 | "P2DT12H" |
| 約 15 分 | "PT15M" |
| 30 日 と 5 時間 10 分 6.334 秒 | "P30DT5H10M6.334S" |
他の例については、「 XML スキーマ: データ型 (W3.org web サイト)」を参照してください。
ベクトルおよびハイブリッド検索の拡張例
ベクトルおよび生成 AI シナリオでのスコアリング プロファイルとドキュメント ブーストの使用のデモについては、このブログ記事とノートブックを参照してください。
キーワード検索の拡張例
次の例では、2 つのスコアリング プロファイル (boostGenre、newAndHighlyRated) を使用するインデックス スキーマを示します。 いずれかのプロファイルをクエリ パラメーターとして指定したクエリを、このインデックスに対して実行すると、該当するプロファイルを使用して結果セットのスコアリングが行われます。
boostGenre プロファイルでは、重み付けされたテキスト フィールドを使用して、albumTitle、genre、artistName の各フィールドで検出された一致をブーストします。 これらのフィールドはそれぞれ 1.5、5、および 2 でブーストされます。 なぜ genre は他のものよりも大幅に高くブーストされるのでしょうか? ある程度同じようなデータに対して検索を実行する場合 (musicstoreindex での "genre" の場合のように)、相対的な重みをより分散することが必要になる可能性があります。 たとえば、musicstoreindex では、"ロック" はジャンルとして表示されると共に、言葉で表現されるジャンルの説明の中にも表示されます。 ジャンルがジャンルの説明を上回るようにする場合は、genre フィールドの相対的な重みをより高くする必要があります。
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}