チュートリアル: Azure Machine Learning スタジオでコードなし AutoML を使用して分類モデルをトレーニングする
このチュートリアルでは、Azure Machine Learning スタジオで Azure Machine Learning を使って、コードなし自動機械学習 (AutoML) により分類モデルをトレーニングする方法について説明します。 この分類モデルでは、金融機関で顧客が定期預金を申し込むかどうかを予測します。
自動 ML を使うと、時間がかかるタスクを自動化することができます。 自動機械学習では、アルゴリズムとハイパーパラメーターのさまざまな組み合わせをすばやく反復し、選択された成功のメトリックに基づいて最適なモデルを効率的に発見します。
このチュートリアルではコードを記述しません。 スタジオのインターフェイスを使ってトレーニングを実行します。 次のタスクを実行する方法について説明します。
- Azure Machine Learning ワークスペースの作成
- 自動機械学習の実験を実行する
- モデルの詳細を調べる
- 推奨モデルをデプロイする
前提条件
Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、無料アカウントを作成してください。
bankmarketing_train.csv データ ファイルをダウンロードします。 [y] 列では、このチュートリアルの予測対象列として後で識別される定期預金に顧客が申し込んだかどうかが示されます。
Note
この Bank Marketing データセットは、クリエイティブ コモンズ (CCO:パブリック ドメイン) ライセンスにより利用できます。 データベースの個々のコンテンツに含まれる権限は、データベース コンテンツ ライセンスによりライセンス供与され、Kaggle で入手できます。 このデータセットのオリジナルは、UCI Machine Learning データベースから入手できます。
[Moro その他、2014 年] S. Moro、P. Cortez、Rita。 銀行のテレマーケティングの成功を予測するためのデータドリブン アプローチ。 意思決定支援システム、Elsevier、62:22-31、2014 年 6 月。
ワークスペースの作成
Azure Machine Learning ワークスペースは、機械学習モデルを実験、トレーニング、およびデプロイするために使用する、クラウドでの基本的なリソースです。 ワークスペースは、Azure サブスクリプションとリソース グループを、サービス内の簡単に使用できるオブジェクトに結び付けます。
以下の手順を実行してワークスペースを作成し、チュートリアルを続行してください。
Azure Machine Learning Studio にサインインします。
[ワークスペースの作成] を選択します。
新しいワークスペースを構成するには、次の情報を指定します。
フィールド 説明 ワークスペース名 ワークスペースを識別する一意の名前を入力します。 名前は、リソース グループ全体で一意である必要があります。 覚えやすく、他のユーザーが作成したワークスペースと区別しやすい名前を使用します。 ワークスペース名では、大文字と小文字は区別されません。 サブスクリプション 使用する Azure サブスクリプションを選択します。 リソース グループ サブスクリプションの既存のリソース グループを使用するか、任意の名前を入力して新しいリソース グループを作成します。 リソース グループは、Azure ソリューションの関連するリソースを保持します。 既存のリソース グループを使用するには、共同作成者または所有者のロールが必要です。 詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。 リージョン ユーザーとデータ リソースに最も近い Azure リージョンを選択し、ワークスペースを作成します。 [作成] を選択して、ワークスペースを作成します。
Azure リソースについて詳しくは、「ワークスペースを作成する」を参照してください。
Azure でワークスペースを作成するその他の方法については、「ポータルまたは Python SDK (v2) を使用して Azure Machine Learning ワークスペースを管理する」を参照してください。
自動機械学習のジョブを作成する
https://ml.azure.com で Azure Machine Learning スタジオを使って、以下の実験の設定と実行の手順を完了します。 Machine Learning スタジオは、あらゆるスキル レベルのデータ サイエンス実務者がデータ サイエンス シナリオを実行するための機械学習ツールが含まれている、統合 Web インターフェイスです。 スタジオは Internet Explorer ブラウザーではサポートされません。
お使いのサブスクリプションと、作成したワークスペースを選択します。
ナビゲーション ウィンドウで、[作成]>[自動 ML] を選択します。
このチュートリアルは初めて自動 ML を使う実験なので、空のリストとドキュメントへのリンクが表示されます。
![新しい自動 ML ジョブを作成できる [自動 ML] ページを示すスクリーンショット。](media/tutorial-first-experiment-automated-ml/get-started.png?view=azureml-api-2)
[新規の自動機械学習ジョブ] を選びます。
[トレーニング方法] で、[自動的にトレーニングする] を選択し、[ジョブの構成を開始する] を選択します。
[基本設定] で、[新規作成] を選択し、[実験名] に「my-1st-automl-experiment」と入力します。
[次へ] を選択して、データセットを読み込みます。
![新しい自動 ML ジョブを作成できる [自動 ML] ページを示すスクリーンショット。](media/tutorial-first-experiment-automated-ml/get-started.png?view=azureml-api-2#lightbox)
データセットを作成してデータ資産として読み込む
実験を構成する前に、データ ファイルを Azure Machine Learning データ資産の形式でワークスペースにアップロードします。 このチュートリアルの場合、データ資産とは自動 ML ジョブのデータセットだと考えることができます。 そう考えると、データを実験に適した形式にすることができます。
[タスクの種類とデータ] の [タスクの種類を選択] で、[分類] を選択します。
[データの選択] で、[作成] を選択します。
[データの種類] フォームで、データ資産に名前を付け、必要に応じて説明を入力します。
[種類] で [表形式] を選択します。 現在、自動 ML のインターフェイスでは TabularDataset のみがサポートされています。
[次へ] を選択します。
[データ ソース] フォームで、[ローカル ファイルから] を選択します。 [次へ] を選択します。
[宛先ストレージの種類] で、ワークスペースの作成時に自動的に設定された既定のデータストア、workspaceblobstore を選択します。 データ ファイルをこの場所にアップロードして、ワークスペースで利用できるようにします。
[次へ] を選択します。
[ファイルまたはフォルダーの選択] で、[ファイルまたはフォルダーのアップロード]>[ファイルのアップロード] を選択します。
ローカル コンピューター上の bankmarketing_train.csv ファイルを選択します。 このファイルは、前提条件としてダウンロードしました。
[次へ] を選択します。
アップロードが完了すると、ファイルの種類に基づいて [データ プレビュー] 領域が設定されます。
[設定] フォームで、データの値を確認します。 [次へ] を選択します。
フィールド 説明 チュートリアルの値 ファイル形式 ファイルに格納されているデータのレイアウトと種類を定義します。 区切り記号 区切り記号 プレーン テキストまたは他のデータ ストリーム内の個別の独立した領域の間の境界を指定するための 1 つ以上の文字。 コンマ エンコード データセットの読み取りに使用する、ビットと文字のスキーマ テーブルを識別します。 UTF-8 列見出し データセットの見出しがある場合、それがどのように処理されるかを示します。 すべてのファイルのヘッダーを同じものにする 行のスキップ データセット内でスキップされる行がある場合、その行数を示します。 なし [スキーマ] フォームを使用すると、この実験用にデータをさらに構成できます。 この例では、day_of_week のトグル スイッチを選択して、これを含めないようにします。 [次へ] を選択します。
![[スキーマ] フォームを示すスクリーンショット。ここではデータから列を除外できます。](media/tutorial-first-experiment-automated-ml/configure-schema-tab.png?view=azureml-api-2)
[確認] フォームで設定した情報を確認し、[作成] を選択します。
次に、一覧からデータセットを選択します。
データ資産を選択し、プレビュー タブを確認して、データをレビューします。day_of_week が含まれていないことを確認し、[閉じる] を選択します。
[次へ] を選択して、タスクの設定に進みます。
ジョブを構成する
データを読み込んで構成したら、実験を設定できます。 このセットアップには、ご使用のコンピューティング環境のサイズの選択や予測する列の指定など、実験の設計タスクが含まれます。
[タスクの設定] フォームで次のように設定します。
ターゲット列として [y (String)] を選択します。この列を予測する必要があります。 この列には、クライアントが定期預金を申し込むかどうかが示されます。
[View additional configuration settings](追加の構成設定を表示) を選択し、次のようにフィールドを設定します。 これらは、トレーニング ジョブをより細かく制御するための設定です。 設定しない場合、実験の選択とデータに基づいて既定値が適用されます。
追加の構成 説明 チュートリアルの値 主要メトリック 機械学習アルゴリズムの測定に使う評価メトリック。 AUCWeighted 最適なモデルの説明 自動 ML で作成された最適なモデルの説明を自動的に表示します。 有効にする ブロックされたモデル トレーニング ジョブから除外するアルゴリズム なし [保存] を選択します。
[検証とテスト] で:
- [検証の種類] として [k 分割交差検証] を選択します。
- [交差検証の数] で [2] を選択します。
[次へ] を選択します。
コンピューティングの種類として [コンピューティング クラスター] を選択します。
コンピューティング先とは、トレーニング スクリプトを実行したりサービスのデプロイをホストしたりするために使用されるローカルまたはクラウド ベースのリソース環境です。 この実験では、クラウドベースのサーバーレス コンピューティング (プレビュー) を試すか、独自のクラウドベースのコンピューティングを作成できます。
Note
サーバーレス コンピューティングを使用するには、プレビュー機能を有効にし、[サーバーレス] を選択して、この手順をスキップします。
独自のコンピューティング先を作成するには、[コンピューティングの種類の選択] で [コンピューティング クラスター] を選択し、コンピューティング先を構成します。
[仮想マシン] フォームに必要事項を入力してコンピューティングを設定します。 新規を選択します。
フィールド 説明 チュートリアルの値 場所 マシンを実行する場所となるリージョン 米国西部 2 仮想マシンの階層 実験の優先度を選択します。 専用 仮想マシンのタイプ コンピューティング用の仮想マシンの種類を選択します。 CPU (中央処理装置) 仮想マシンのサイズ コンピューティングの仮想マシン サイズを選択します。 指定したデータと実験の種類に基づいて、推奨サイズの一覧が提供されます。 Standard_DS12_V2 [次へ] を選択して、[詳細設定] フォームに進みます。
![[詳細設定] ページを示すスクリーンショット。ここでコンピューティング クラスターの値を入力します。](media/tutorial-first-experiment-automated-ml/compute-settings.png?view=azureml-api-2)
フィールド 説明 チュートリアルの値 コンピューティング名 コンピューティング コンテキストを識別する一意名。 automl-compute 最小/最大ノード データをプロファイリングするには、1 つ以上のノードを指定する必要があります。 最小ノード: 1
最大ノード: 6スケール ダウンする前のアイドル時間 (秒) クラスターが自動的に最小ノード数にスケールダウンされるまでのアイドル時間。 120 (既定値) 詳細設定 実験用の仮想ネットワークを構成および承認するための設定。 なし [作成] を選択します
コンピューティングの作成には数分かかる場合があります。
作成後、一覧から新しいコンピューティング先を選択します。 [次へ] を選択します。
[トレーニング ジョブの送信] を選択して実験を実行します。 実験の準備が開始すると、[概要] 画面が開き、[状態] が上部に表示されます。 この状態は、実験の進行に応じて更新されます。 スタジオには、実験の状態を表す通知も表示されます。
![[詳細設定] ページを示すスクリーンショット。ここでコンピューティング クラスターの値を入力します。](media/tutorial-first-experiment-automated-ml/compute-settings.png?view=azureml-api-2#lightbox)
重要
実験の実行の準備に、10 から 15 分かかります。 実行の開始後、各イテレーションのためにさらに 2、3 分かかります。
運用環境では、しばらく席を離れるかもしれません。 ただし、このチュートリアルでは、他のイテレーションが実行中でも、アルゴリズムのテストが終わりしだい [モデル] タブでその調査を開始できます。
モデルを調査する
[モデル + 子ジョブ] タブに移動し、テストされたアルゴリズム (モデル) を確認します。 既定では、ジョブは各モデルを完了時のメトリック スコア順に並べ替えます。 このチュートリアルでは、選択した AUCWeighted メトリックに基づいてスコアが最も高いモデルが、リストの一番上に表示されます。
すべての実験モデルが終了するのを待っている間に、完了したモデルの [アルゴリズム名] を選択して、そのパフォーマンスの詳細を調査します。 [概要] と [メトリック] タブを選択して、ジョブに関する情報を確認します。
次のアニメーションでは、選択したモデルのプロパティ、メトリック、パフォーマンス グラフを表示しています。

モデルの説明を確認する
モデルが完成するまで待つ間、モデルの説明を参照し、どのデータの特徴 (未加工または設計済み) が特定のモデルの予測に影響したかを確認することもできます。
こうしたモデルの説明は、必要に応じて生成できます。 [説明 (プレビュー)] タブの一部であるモデルの説明ダッシュボードでは、これらの説明がまとめられています。
モデルの説明を生成するには:
ページの上部にあるナビゲーション リンクでジョブ名を選択し、[モデル] 画面に戻ります。
[モデル + 子ジョブ] タブを選択します。
このチュートリアルでは、最初の MaxAbsScaler、LightGBM モデルを選択します。
[モデルを説明する] を選択します。 右側には [Explain model](モデルの説明) ペインが表示されます。
コンピューティングの種類を選択し、インスタンスまたはクラスターを選択します。これは前に作成した automl-compute です。 このコンピューティングにより、モデルの説明を生成する子ジョブが開始されます。
[作成] を選択します 緑色の成功メッセージが表示されます。
Note
説明可能性のジョブが完了するまでに約 2 分から 5 分かかります。
[説明 (プレビュー)] を選択します。 説明可能性の実行が完了すると、このタブに表示されます。
左側で、ペインを展開します。 [特徴量] で、未加工と表示された行を選択します。
[特徴量の重要度集約] タブを選択します。このグラフは、選択したモデルの予測に影響を与えたデータの特徴を示しています。
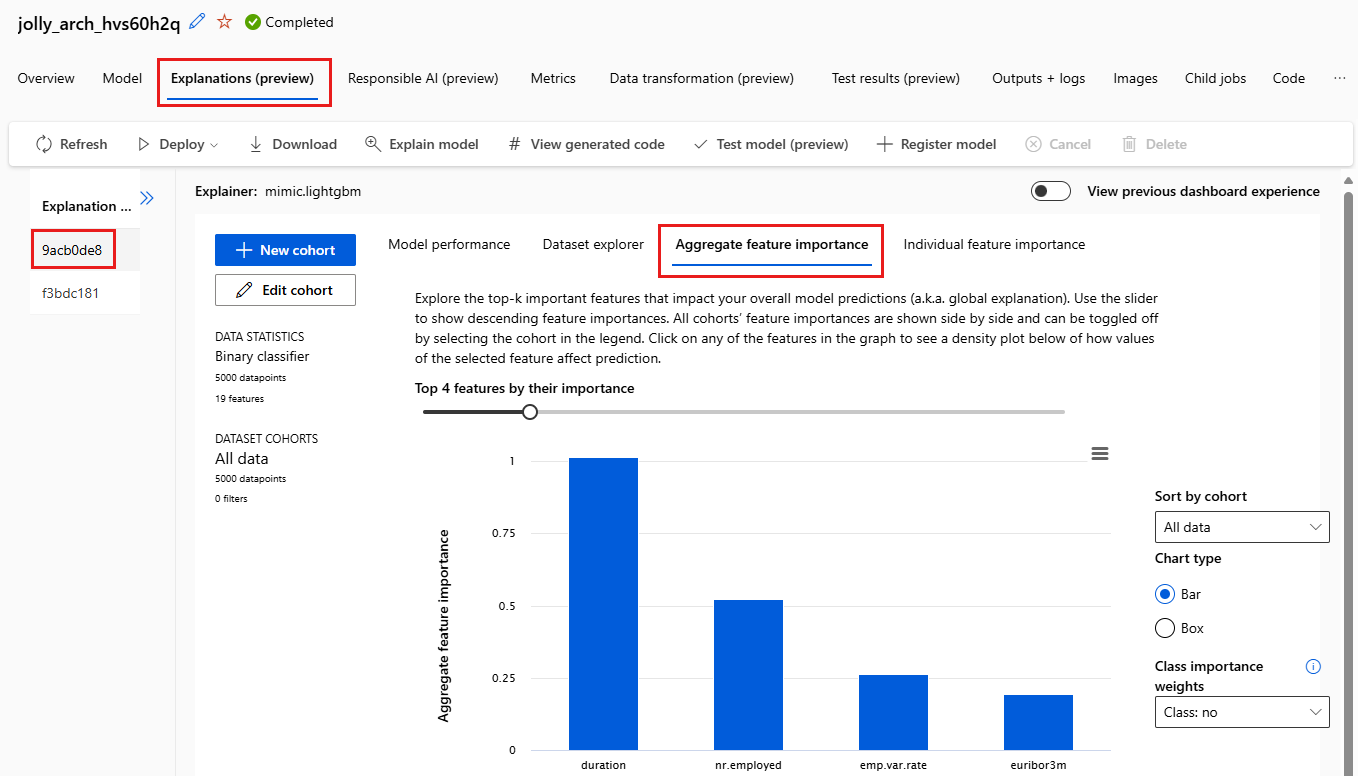
この例では、"期間" がこのモデルの予測に最も影響を与えているように見えます。

最適なモデルをデプロイする
自動機械学習インターフェイスを使用すると、最適なモデルを Web サービスとしてデプロイすることができます。 "デプロイ" とは、新しいデータを予測したり、改善の余地がある領域を特定したりできるようにモデルを統合することです。 この実験における Web サービスへのデプロイは、定期預金の潜在顧客を特定するためのスケーラブルな反復 Web ソリューションを金融機関が持つことを意味します。
実験の実行が完了したかどうかを確認します。 そうするには、画面の上部にあるジョブ名を選択して、親ジョブのページに戻ります。 画面の左上に完了状態が表示されます。
実験の実行が完了すると、[詳細] ページに [最適なモデルの概要] セクションが設定されます。 この実験のコンテキストでは、AUCWeighted メトリックに基づいて VotingEnsemble が最適なモデルと見なされます。
このモデルをデプロイします。 デプロイの完了には 20 分程度かかります。 デプロイ プロセスには、モデルを登録したり、リソースを生成したり、Web サービス用にそれらを構成したりすることを含む、いくつかの手順が伴います。
[VotingEnsemble] を選択して、モデル固有のページを開きます。
[デプロイ]>[Web サービス] の順に選択します。
[Deploy a model](モデルのデプロイ) ペインに次のように入力します。
フィールド 値 名前 my-automl-deploy 説明 初めての自動機械学習実験のデプロイ コンピューティングの種類 Azure コンテナー インスタンスを選択します 認証を有効にする 無効。 カスタム デプロイ アセットを使用する 無効。 既定のドライバー ファイル (スコアリング スクリプト) と環境ファイルが自動的に生成されます。 この例では、[詳細] メニューで指定されている既定値を使用します。
[デプロイ] を選択します。
[ジョブ] 画面の上部に緑色の成功メッセージが表示されます。 [モデルの概要] ペインの [デプロイの状態] に、ステータス メッセージが表示されます。 [最新の情報に更新] を定期的にクリックして、デプロイの状態を確認します。
予測を生成するための運用 Web サービスが作成されました。
新しい Web サービスの使い方、Azure Machine Learning サポートに組み込まれている Power BI を使った予測のテスト方法について詳しくは、「関連コンテンツ」に進みます。
リソースをクリーンアップする
デプロイ ファイルはデータ ファイルと実験ファイルよりも大きいため、格納コストは高くなります。 ワークスペースと実験ファイルを残したい場合は、デプロイ ファイルだけを削除して、アカウントのコストを最小限に抑えます。 いずれのファイルも使う予定がない場合は、リソース グループ全体を削除します。
デプロイ インスタンスの削除
https://ml.azure.com/. で Azure Machine Learning からデプロイ インスタンスのみを削除します
Azure Machine Learning に移動します。 ワークスペースに移動し、[資産] ペインで [エンドポイント] を選択します。
削除するデプロイを選択し、 [削除] を選択します。
[続行] を選択します。
リソース グループを削除します
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
リソース グループ名を入力します。 次に、 [削除] を選択します。
関連するコンテンツ
この自動機械学習チュートリアルでは、Azure Machine Learning の自動 ML インターフェイスを使用して分類モデルの作成とデプロイを行いました。 さらなる情報と次の手順については、次のリソースを参照してください。
- 自動機械学習についてさらに理解を深める。
- 分類メトリックとグラフについては、記事「自動機械学習実験の結果を評価」を参照してください。
- 詳細については、NLP の AutoML を設定する方法を参照してください。
他のタイプのモデルについても、自動機械学習を試してみましょう。
- コードなしの予測の例については、「チュートリアル: Azure Machine Learning スタジオでコードなし自動機械学習を使用して需要を予測する」を参照してください。
- 物体検出モデルの Code First の例については、「チュートリアル: AutoML と Python を使用して物体検出モデルをトレーニングする」を参照してください。