自動機械学習実験の結果を評価
この記事では、自動機械学習 (自動 ML) の実験でトレーニングされたモデルを評価し、比較する方法について説明します。 自動 ML 実験の過程で、多くのジョブが作成され、各ジョブでモデルが作成されます。 自動 ML では、モデルごとに、モデルのパフォーマンスを測定するのに役立つ評価メトリックとグラフが生成されます。 さらに、責任ある AI ダッシュボードを生成して、既定で推奨される最適なモデルの全体的な評価とデバッグを行うことができます。 これには、モデルの説明、公平性とパフォーマンスのエクスプローラー、データ エクスプローラー、モデル エラー分析などの分析情報が含まれます。 責任ある AI ダッシュボードを生成する方法の詳細については、こちらを参照してください。
たとえば、自動 ML では、実験の種類に基づいて次のグラフが生成されます。
| 分類 | 回帰/予測 |
|---|---|
| 混同行列 | Residuals ヒストグラム |
| 受信者操作特性 (ROC) 曲線 | 予測と True |
| 適合率 - 再現率 (PR) 曲線 | 予測期間 |
| リフト曲線 | |
| 累積ゲイン曲線 | |
| 較正曲線 |
重要
この記事で "(プレビュー)" と付記されている項目は、現在、パブリック プレビュー段階です。 プレビュー バージョンはサービス レベル アグリーメントなしで提供されています。運用環境のワークロードに使用することはお勧めできません。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
- Azure Machine Learning 実験は、次のいずれかを使用して作成します。
ジョブの結果を表示する
自動 ML 実験の完了後、ジョブの履歴を次の方法で見つけることができます。
- ブラウザーと Azure Machine Learning スタジオ
- JobDetails Jupyter ウィジェットを使用する Jupyter ノートブック
次の手順とビデオでは、スタジオで実行履歴とモデル評価のメトリックとグラフを表示する方法について説明します。
- スタジオにサインインし、ワークスペースに移動します。
- 左側のメニューで、[ジョブ] を選択します。
- 使用する実験を実験の一覧から選択します。
- ページの下部にあるテーブルで、自動 ML ジョブを選びます。
- [モデル] タブで、評価するモデルの [アルゴリズム名] を選択します。
- [メトリック] タブで、左側のチェックボックスを使用してメトリックとグラフを表示します。
分類メトリック
自動 ML では、実験用に生成された分類モデルごとにパフォーマンス メトリックが計算されます。 これらのメトリックは、scikit-learn 実装に基づいています。
2 つのクラスの二項分類には多くの分類メトリックが定義されており、複数クラス分類用に 1 つのスコアを生成するには、クラスの平均値を求める必要があります。 Scikit-learn ではいくつかの平均化方法が提供され、そのうちの 3 つ、マクロ、マイクロ、および加重が、自動 ML で公開されます。
- マクロ -各クラスのメトリックを計算し、非加重平均を取得します。
- マイクロ - 真陽性、偽陰性、偽陽性の合計をカウントすることによって、メトリックをグローバルに計算します (クラスとは無関係)。
- 加重 - 各クラスのメトリックを計算し、クラスあたりのサンプル数に基づいて加重平均を取得します。
各平均化方法にはそれぞれのメリットがありますが、適切な方法を選択する際に共通する考慮事項の 1 つは、クラスの不均衡です。 クラスのサンプル数が異なる場合は、マイノリティ クラスがマジョリティ クラスと同等に重み付けされる、マクロ平均を使用する方が有益である可能性があります。 自動 ML でのバイナリ メトリックと多クラス メトリックの詳細について確認してください。
次の表は、実験用に生成された各分類モデルに対して自動 ML によって計算されるモデル パフォーマンス メトリックをまとめたものです。 詳細については、各メトリックの "計算" フィールドにリンクされている scikit-learn のドキュメントを参照してください。
注意
画像分類モデルのメトリックの詳細については、画像メトリックに関するセクションを参照してください。
| メトリック | 説明 | 計算 |
|---|---|---|
| AUC | AUC は受信者操作特性曲線の下の領域です。 目標: 1 に近いほど良い 範囲: [0, 1] サポートされているメトリック名の例 AUC_macro: クラスごとの AUC の算術平均です。AUC_micro、真陽性、偽陰性、偽陽性の合計をカウントすることによって計算されます。 AUC_weighted: 各クラスのスコアの算術平均で、各クラス内の true インスタンスの数によって重み付けされます。 AUC_binary: 1 つの特定のクラスを true クラスとして扱い、他のすべてのクラスを false クラスとして結合することによる、AUC の値。 |
計算 |
| accuracy | 精度は、true クラス ラベルと正確に一致する予測の割合です。 目標: 1 に近いほど良い 範囲: [0, 1] |
計算 |
| average_precision | 平均適合率は、各しきい値で達成した適合率の加重平均として適合率-再現率曲線をまとめたもので、前のしきい値より増加した再現率を重みとして使用します。 目標: 1 に近いほど良い 範囲: [0, 1] サポートされているメトリック名の例 average_precision_score_macro: 各クラスの平均適合率スコアの算術平均です。average_precision_score_micro、真陽性、偽陰性、偽陽性の合計をカウントすることによって計算されます。average_precision_score_weighted: 各クラスの平均適合率スコアの算術平均で、各クラス内の true インスタンスの数によって重み付けされます。 average_precision_score_binary: 1 つの特定のクラスを true クラスとして扱い、他のすべてのクラスを false クラスとして結合することによる、平均適合率の値。 |
計算 |
| balanced_accuracy | バランスの取れた精度は、各クラスの再現率の算術平均です。 目標: 1 に近いほど良い 範囲: [0, 1] |
計算 |
| f1_score | F1 スコアは、適合率と再現率の調和平均です。 偽陽性と偽陰性の両方を調整して測定します。 ただし、真陰性は考慮されません。 目標: 1 に近いほど良い 範囲: [0, 1] サポートされているメトリック名の例 f1_score_macro: 各クラスの F1 スコアの算術平均です。 f1_score_micro: 真陽性、偽陰性、偽陽性の合計をカウントすることによって計算されます。 f1_score_weighted: 各クラスの F1 スコアのクラスごとの頻度の加重平均です。 f1_score_binary: 1 つの特定のクラスを true クラスとして扱い、他のすべてのクラスを false クラスとして結合することによる、f1 の値。 |
計算 |
| log_loss | これは、(多項) ロジスティック回帰とその拡張機能 (ニューラル ネットワークなど) で使用される損失関数で、確率的分類法の予測を前提として、true ラベルの負の対数尤度として定義されます。 目標: 0 に近いほど良い 範囲: [0, inf) |
計算 |
| norm_macro_recall | 正規化されたマクロ再現率は、ランダムなパフォーマンスでのスコアが 0、最適なパフォーマンスでのスコアが 1 になるように、マクロ平均化および正規化された再現率です。 目標: 1 に近いほど良い 範囲: [0, 1] |
(recall_score_macro - R) / (1 - R) ここで、 R はランダム予測の recall_score_macro の予想される値です。R = 0.5: 二項分類の場合。 R = (1 / C): C クラス分類の問題の場合。 |
| matthews_correlation | Matthews 相関係数は、精度のバランスを取ります。これは、1 つのクラスに他より多くのサンプルが含まれている場合でも使用できます。 係数 1 は完全な予測、0 はランダムな予測、-1 は逆予測を示します。 目標: 1 に近いほど良い 範囲: [-1, 1] |
計算 |
| 精度 | 適合率は、負のサンプルが正としてラベル付けされないようにするモデルの機能です。 目標: 1 に近いほど良い 範囲: [0, 1] サポートされているメトリック名の例 precision_score_macro: 各クラスの適合率の算術平均です。 precision_score_micro: 真陽性と偽陽性の合計をカウントすることによって、グローバルに計算されます。 precision_score_weighted: 各クラスの適合率の算術平均で、各クラス内の true インスタンスの数によって重み付けされます。 precision_score_binary: 1 つの特定のクラスを true クラスとして扱い、他のすべてのクラスを false クラスとして結合することによる、適合率の値。 |
計算 |
| リコール | 再現率は、すべての正のサンプルを検出するモデルの機能です。 目標: 1 に近いほど良い 範囲: [0, 1] サポートされているメトリック名の例 recall_score_macro: 各クラスの再現率の算術平均です。 recall_score_micro: 真陽性、偽陰性、偽陽性の合計をカウントすることによって、グローバルに計算されます。recall_score_weighted: 各クラスの再現率の算術平均で、各クラス内の true インスタンスの数によって重み付けされます。 recall_score_binary: 1 つの特定のクラスを true クラスとして扱い、他のすべてのクラスを false クラスとして結合することによる、再現率の値。 |
計算 |
| weighted_accuracy | 加重精度は、各サンプルが同じクラスに属するサンプルの合計数によって重み付けされる精度です。 目標: 1 に近いほど良い 範囲: [0, 1] |
計算 |
バイナリと多クラスの分類メトリック
自動 ML では、データがバイナリかどうかが自動的に検出され、true クラスを指定することによってデータが多クラスの場合でも、ユーザーは二項分類メトリックをアクティブにすることができます。 データセットに 2 つ以上のクラスがある場合、多クラス分類メトリックが報告されます。 バイナリ分類メトリックは、データがバイナリの場合にのみ報告されます。
多クラス分類メトリックは多クラス分類を目的としていることに注意してください。 バイナリ データセットに適用した場合、これらのメトリックによってどのクラスも true クラスとして扱われません。 明らかに多クラス向けのメトリックには、micro、macro、または weighted がサフィックスとして付けられます。 例として、average_precision_score、f1_score、precision_score、recall_score、AUC などがあります。 たとえば、リコールを tp / (tp + fn) として計算する代わりに、多クラスの平均リコール (micro、macro、または weighted) は、二項分類データセットの両方のクラスの平均をとります。 これは、true クラスと false クラスのリコールを個別に計算してから、その 2 つの平均を取得することと同じです。
また、二項分類の自動検出がサポートされてはいますが、それでも、true クラスを常に手動で指定して、二項分類メトリックが正しいクラスに対して計算されるようにすることをお勧めします。
データセット自体が多クラスのときに、二項分類データセットのメトリックをアクティブにするために、ユーザーが行う必要があるのは、true クラスとして扱われるクラスの指定だけであり、これらのメトリックが計算されます。
混同行列
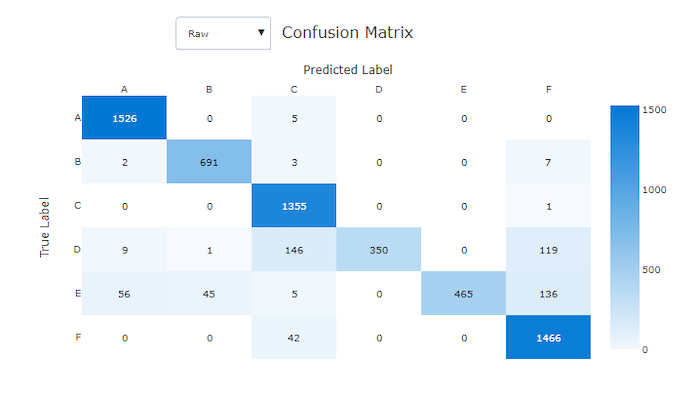
混同行列は、機械学習モデルが分類モデルの予測でどのように体系的なエラーをするかを視覚的に示します。 "混同" という言葉は、モデルの "混同" やサンプルの誤ったラベル付けに由来しています。 混同行列内の行 i と列 j にあるセルには、クラス C_i に属し、モデルによってクラス C_jに分類された、評価データセット内のサンプルの数が含まれています。
スタジオでは、セルが濃い方がサンプルが多いことを示しています。 ドロップダウンで正規化ビューを選択すると、各マトリックス行が正規化され、C_j クラスと予測される C_i クラスの割合が示されます。 既定の未処理ビューを使用するメリットは、実際のクラスの分布の不均衡によって、モデルがマイノリティ クラスのサンプルを誤って分類しているかどうかを確認できることです。これは、不均衡なデータセットでよくある問題です。
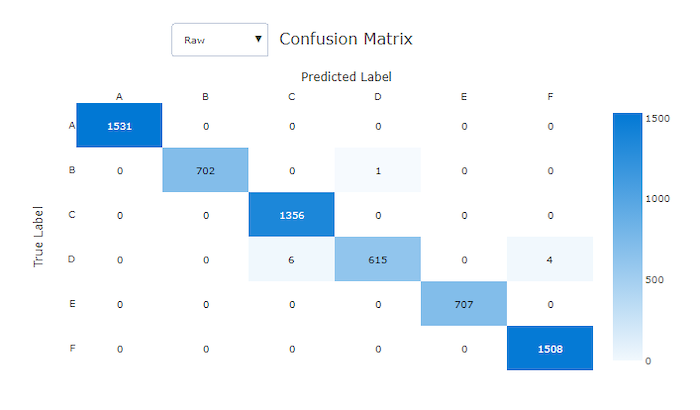
適切なモデルの混同行列では、ほとんどのサンプルが対角線に沿っています。
適切なモデルの混同行列
適切でないモデルの混同行列
ROC 曲線
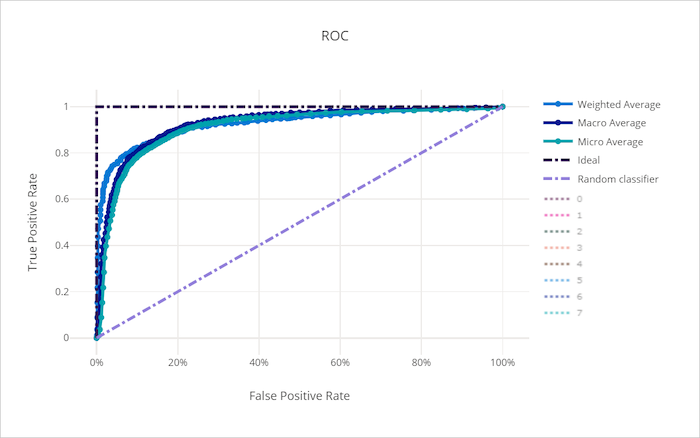
受信者操作特性 (ROC) 曲線は、決定しきい値の変化に応じて、真陽性率 (TPR) と偽陽性率 (FPR) との関係をプロットします。 マジョリティ クラスによってマイノリティ クラスからのコントリビューションが打ち消される可能性があるため、クラスの不均衡が大きいデータセットでモデルをトレーニングする場合、ROC 曲線はあまり有益ではありません。
曲線 (AUC) の下の領域は、適切に分類されたサンプルの割合と解釈できます。 より正確に言うと、AUC は、分類子がランダムに選択された正のサンプルをランダムに選択された負のサンプルよりも高くランク付けする確率です。 曲線の形状は、分類のしきい値または決定の境界に応じて、TPR と FPR の関係を直感できるようにします。
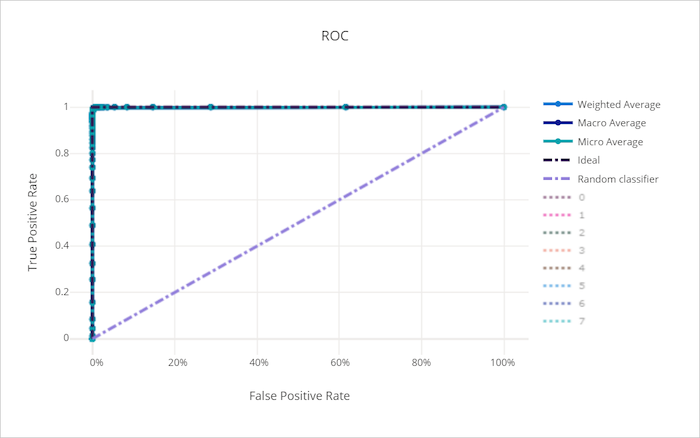
グラフの左上隅に近づく曲線は、最適なモデルである 100% の TPR と 0% の FPR に近づいています。 ランダム モデルでは、左下隅から右上に向かう y = x 線に沿って ROC 曲線が生成されます。 ランダム モデルより良くないのは、ROC 曲線が y = x 線より下がるものです。
ヒント
分類の実験では、自動 ML モデル用に生成された各折れ線グラフを使用して、クラスごとにモデルを評価したり、すべてのクラスに対して平均化したりできます。 グラフの右側にある凡例のクラス ラベルをクリックすると、これらのビューを切り替えることができます。
適切なモデルの ROC 曲線
適切でないモデルの ROC 曲線
適合率 - 再現率曲線
適合率 - 再現率曲線は、決定しきい値の変化に応じて、適合率と再現率の関係をプロットします。 再現率はすべての正のサンプルを検出するモデルの機能であり、適合率は負のサンプルを正としてラベル付けすることを回避するモデルの機能です。 いくつかのビジネス上の問題により、偽陰性の回避と偽陽性の回避のどちらが相対的に重要かに応じて、より高い再現性と適合率が求められる場合があります。
ヒント
分類の実験では、自動 ML モデル用に生成された各折れ線グラフを使用して、クラスごとにモデルを評価したり、すべてのクラスに対して平均化したりできます。 グラフの右側にある凡例のクラス ラベルをクリックすると、これらのビューを切り替えることができます。
適切なモデルの適合率 - 再現率曲線
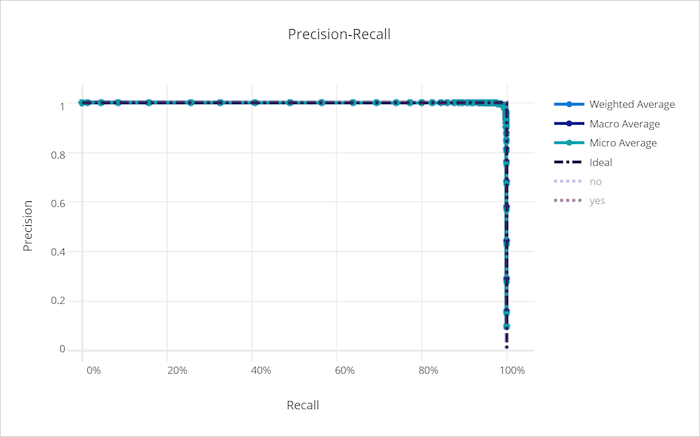
適切でないモデルの適合率 - 再現率曲線
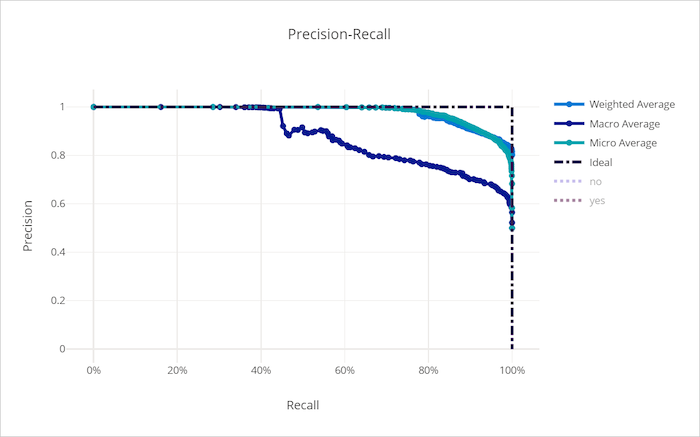
累積ゲイン曲線
累積ゲイン曲線は、検討しているサンプルの割合に応じて、適切に分類された正のサンプルの割合をプロットします。サンプルは、予測される確率の順序で検討します。
ゲインを計算するには、まず、モデルで予測される確率が最高のものから最小のものまで、すべてのサンプルを並べ替えます。 次に、最も信頼度の高い予測の x% を使用します。 この x% で検出された正のサンプルの数を正のサンプルの合計数で割ることで、ゲインを得ることができます。 累積ゲインは、正のクラスに属する可能性が最も高いデータの割合を考慮した場合に検出される、正のサンプルの割合です。
完全なモデルでは、すべての正のサンプルをすべての負のサンプルの上に優先度付けして、2 つの直線セグメントで構成される累積ゲイン曲線を示します。 1 つ目は (0, 0) から (x, 1) への傾き 1 / x の線で、x は正のクラスに属するサンプルの割合です (クラスの均衡が取れている場合は 1 / num_classes)。 2 つ目は (x, 1) から (1, 1) までの水平線です。 最初のセグメントでは、すべての正のサンプルが正しく分類され、累積ゲインは、考慮されたサンプルの最初の x% 内で 100% になります。
ベースライン ランダム モデルでは、y = x の後に累積ゲイン曲線があります。ここでは、検討されたサンプルの x% について、正のサンプルの合計の約 x% のみが検出されました。 バランスの取れたデータセットに完璧なモデルでは、マイクロ平均曲線と、累積ゲインが 100% になるまで傾きが num_classes のマクロ平均線があり、その後はデータの割合が 100 になるまで水平になります。
ヒント
分類の実験では、自動 ML モデル用に生成された各折れ線グラフを使用して、クラスごとにモデルを評価したり、すべてのクラスに対して平均化したりできます。 グラフの右側にある凡例のクラス ラベルをクリックすると、これらのビューを切り替えることができます。
適切なモデルの累積ゲイン曲線
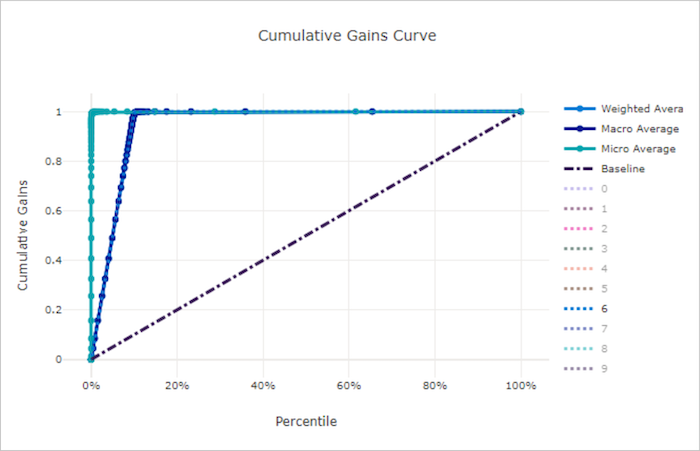
適切でないモデルの累積ゲイン曲線
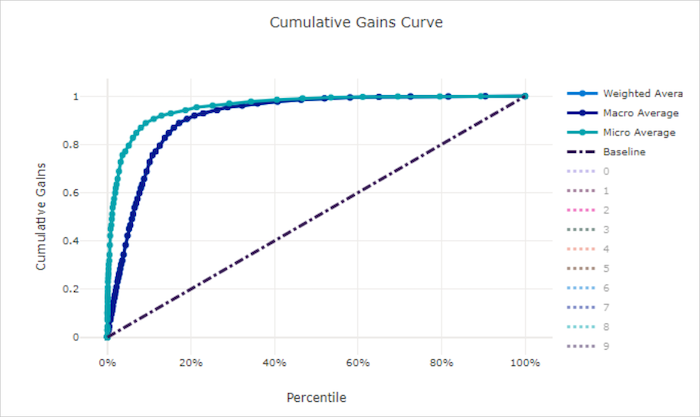
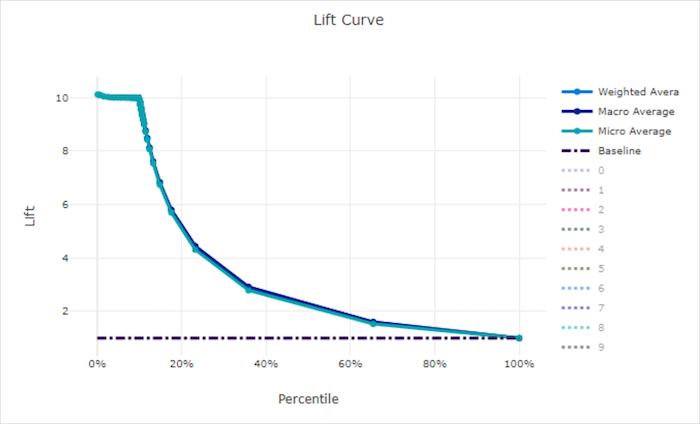
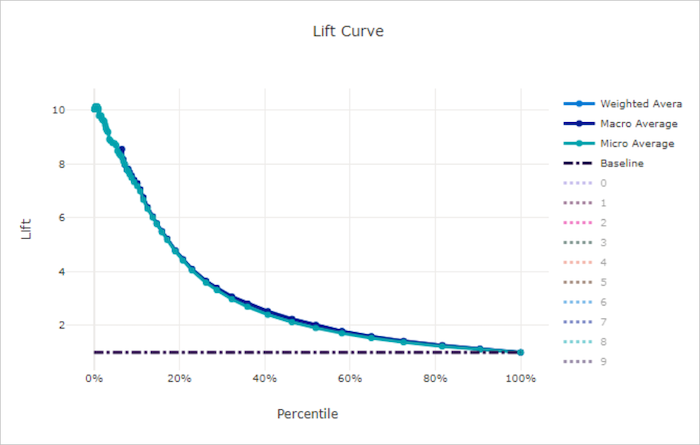
リフト曲線
リフト曲線には、ランダム モデルと比較して、モデルのパフォーマンスが何倍優れているかが示されます。 リフトは、ランダム モデルの累積ゲインに対する累積ゲインの比率として定義されます (常に 1 になる必要があります)。
この相対的なパフォーマンスでは、クラスの数を増やすと分類が困難になるという事実が考慮されます。 ランダム モデルでは、2 つのクラスを持つデータセットと比較して、10 個のクラスを持つデータセットからのサンプルの割合が、誤って予測されます。
ベースライン リフト曲線は、モデルのパフォーマンスとランダム モデルのパフォーマンスが一致する y = 1 の線です。 一般的に、適切なモデルのリフト曲線は、グラフ上でより高くなり、x 軸からより離れています。つまり、モデルの予測の信頼度が最も高い場合は、ランダムな推測よりもパフォーマンスが何倍も良くなります。
ヒント
分類の実験では、自動 ML モデル用に生成された各折れ線グラフを使用して、クラスごとにモデルを評価したり、すべてのクラスに対して平均化したりできます。 グラフの右側にある凡例のクラス ラベルをクリックすると、これらのビューを切り替えることができます。
適切なモデルのリフト曲線
適切でないモデルのリフト曲線
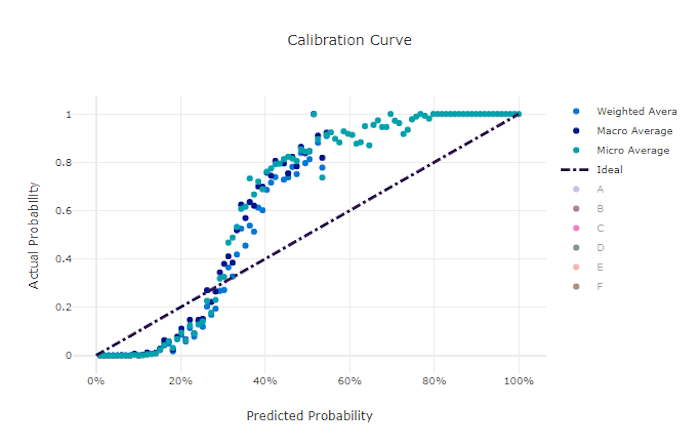
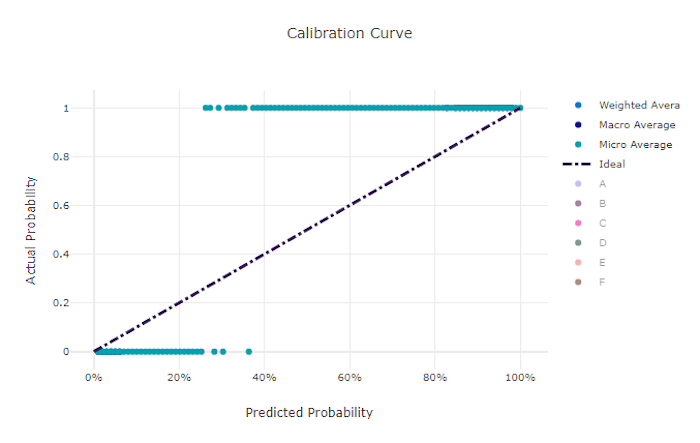
較正曲線
較正曲線は、各信頼レベルでの、正のサンプルの比率に対するモデルの予測の信頼度をプロットします。 適切に較正されたモデルでは、予測の 100% が正確に分類され、100% の信頼度が割り当てられます。また、予測の 50% に 50% の信頼度が、予測の 20% に 20% の信頼度が割り当てられます。 完全に較正されたモデルでは、y = x の線の後に較正曲線があり、サンプルが各クラスに属している確率が完全に予測されます。
過剰信頼モデルでは、0 と 1 に近い確率が過剰予測され、各サンプルのクラスが不確実であることはほぼありません。また、較正曲線は逆さの "S" のようになります。信頼されないモデルでは、予測したクラスに概して低い確率が割り当てられ、関連付けられている較正曲線は "S" のようになります。 較正曲線は、適切に分類するモデルの能力を表すのではなく、予測に信頼を適切に割り当てる能力を表します。 適切でないモデルでも、そのモデルが低い信頼度と高い不確実性を適切に割り当てる場合は、適切な較正曲線が得られます。
注意
較正曲線はサンプル数に依存しているため、小さな検証セットによって、解釈が難しいノイズのある結果が生成される可能性があります。 これは、必ずしも、モデルが適切に較正されていないことを意味するわけではありません。
適切なモデルの較正曲線
適切でないモデルの較正曲線
回帰/予測メトリック
自動 ML は、回帰実験であるか予測実験であるかに関係なく、生成される各モデルに対して同じパフォーマンス メトリックを計算します。 また、これらのメトリックは、異なる範囲のデータでトレーニングされたモデルを比較できるように正規化されます。 詳細については、「メトリックの正規化」を参照してください。
次の表は、回帰および予測実験用に生成される、モデル パフォーマンス メトリックをまとめたものです。 分類メトリックと同様に、これらのメトリックも scikit-learn 実装に基づいています。 適切な scikit-learn ドキュメントが、 "計算" フィールドに適宜リンクされています。
| メトリック | 説明 | 計算 |
|---|---|---|
| explained_variance | 説明分散では、モデルでターゲット変数のバリエーションを指定する範囲を測定します。 エラーの分散に対する元データの分散の減少の割合です。 誤差の平均が 0 の場合は、決定係数と等しくなります (次のチャートの r2_score を参照)。 目標: 1 に近いほど良い 範囲: (-inf, 1] |
計算 |
| mean_absolute_error | 平均絶対誤差は、ターゲットと予測の間における差異の絶対値について予期される値です。 目標: 0 に近いほど良い 範囲: [0, inf) タイプ: mean_absolute_error normalized_mean_absolute_error: データの範囲で除算した mean_absolute_error です。 |
計算 |
| mean_absolute_percentage_error | 平均絶対パーセント誤差 (MAPE) は、予測された値と実際の値との平均差を測定したものです。 目標: 0 に近いほど良い 範囲: [0, inf) |
|
| median_absolute_error | 中央絶対誤差は、ターゲットと予測の間におけるすべての絶対差の中央値です。 この損失は外れ値に対してロバストです。 目標: 0 に近いほど良い 範囲: [0, inf) タイプ: median_absolute_errornormalized_median_absolute_error: データの範囲で除算した median_absolute_error です。 |
計算 |
| r2_score | R2 (決定係数) では、観測されたデータの全分散と比較して平均二乗誤差 (MSE) の比例減少が測定されます。 目標: 1 に近いほど良い 範囲: [-1, 1] 注: R2 は、(-inf, 1] の範囲を持つことがよくあります。 MSE は観測された分散よりも大きい場合があるため、データとモデル予測によっては、R2 は任意の大きな負の値を持つ場合があります。 自動 ML クリップによって -1 の R2 スコアが報告された場合、R2 の値 -1 は、実際の R2 スコアが -1 未満であることを意味する可能性があります。 負の R2 スコアを解釈する場合は、他のメトリック値とデータのプロパティを考慮してください。 |
計算 |
| root_mean_squared_error | 平均平方二乗誤差 (RMSE) は、ターゲットと予測の間における予期される二乗誤差の平方根です。 不偏推定の場合、RMSE は標準偏差と等しくなります。 目標: 0 に近いほど良い 範囲: [0, inf) タイプ: root_mean_squared_error normalized_root_mean_squared_error: データの範囲で除算した root_mean_squared_error です。 |
計算 |
| root_mean_squared_log_error | 対数平均平方二乗誤差は、予期される対数二乗誤差の平方根です。 目標: 0 に近いほど良い 範囲: [0, inf) タイプ: root_mean_squared_log_error normalized_root_mean_squared_log_error: データの範囲で除算した root_mean_squared_log_error です。 |
計算 |
| spearman_correlation | スピアマンの相関は、2 つのデータセット間の関係の単調性に対するノンパラメトリック測定です。 ピアソンの相関とは異なり、スピアマンの相関は両方のデータセットが正規分布していることを想定しません。 他の相関係数と同様に、スピアマンは -1 と 1 の間で変化し、0 は相関関係がないことを示します。 相関係数が -1 または 1 の場合は、完全に単調な関係であることを示します。 スピアマンはランク順序の相関関係メトリックです。これは、予測値または実際の値を変更しても、予測値または実際の値のランク順序を変更しないと、スピアマンの結果が変更されないことを意味します。 目標: 1 に近いほど良い 範囲: [-1, 1] |
計算 |
メトリックの正規化
自動 ML は回帰および予測メトリックを正規化します。これにより、異なる範囲のデータでトレーニングされたモデルを比較できます。 より大きな範囲のデータでトレーニングされたモデルは、そのエラーが正規化されていない限り、より小さな範囲のデータでトレーニングされた同じモデルよりもエラーが高くなります。
エラー メトリックを標準化する標準的な方法はありませんが、自動 ML では、データの範囲によってエラーを除算する一般的な方法を採用しています: normalized_error = error / (y_max - y_min)
Note
データの範囲はモデルと一緒に保存されません。 予約テスト セットに対して同じモデルを使用して推論を行う場合、y_min と y_max はテスト データに応じて変化する可能性があります。また、トレーニング セットとテスト セットに対するモデルのパフォーマンスを比較するために正規化されたメトリックを直接使用できないことがあります。 トレーニング セットから y_min と y_max の値を渡すことで、比較を公平に行うことができます。
予測メトリック: 正規化と集計
予測モデル評価のメトリックの計算では、データに複数の時系列が含まれている場合、いくつかの点で特別な考慮が必要です。 複数の系列でメトリックを集計するには、2 つの自然な選択肢があります。
- 各系列からの評価メトリックに等しい重みが与えられているマクロ平均。
- 各予測に対する評価メトリックが等しい重みを持つ マイクロ平均。
これらのケースは、多クラス分類におけるマクロ平均化とマイクロ平均化に直接類似しています。
マクロ平均化とマイクロ平均化の区別は、モデル選択の主要なメトリックを選択する際に重要となる場合があります。 たとえば、一部のコンシューマー製品の需要を予測する小売シナリオを考えてみましょう。 製品の中には、他の製品と比べて販売量が多いものがあります。 マイクロ平均 RMSE をプライマリ メトリックとして選択した場合、量が多い項目が、モデリング エラーのほとんどを占め、メトリックを大きく左右する可能性があります。 モデル選択アルゴリズムでは、少量の項目よりも、大量の項目で精度の高いモデルが優先される場合があります。 これに対し、マクロ平均の正規化された RMSE では、少量の項目は、大量の項目とほぼ同じ重みになります。
次の表に、マクロ平均化とマイクロ平均化を使用する AutoML の予測メトリックを示します。
| マクロ平均 | マイクロ平均 |
|---|---|
normalized_mean_absolute_error、normalized_median_absolute_error、normalized_root_mean_squared_error, normalized_root_mean_squared_log_error |
mean_absolute_error, median_absolute_error, root_mean_squared_error, root_mean_squared_log_error, r2_score, explained_variance, spearman_correlation, mean_absolute_percentage_error |
マクロ平均メトリックでは、各系列が個別に正規化されることに注意してください。 その後、各系列の正規化されたメトリックが平均化され、最終的な結果が得られます。 マクロとマイクロの正しい選択はビジネス シナリオによって異なりますが、一般的には normalized_root_mean_squared_error を使用することをお勧めします。
残差
残差グラフは、回帰実験および予測実験のために生成される予測エラー (残差) のヒストグラムです。 残差はすべてのサンプルの y_predicted - y_true として計算され、モデルの偏りを示すヒストグラムとして表示されます。
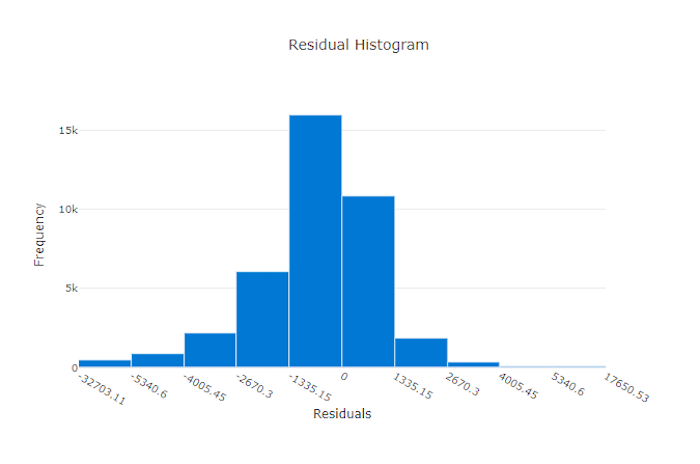
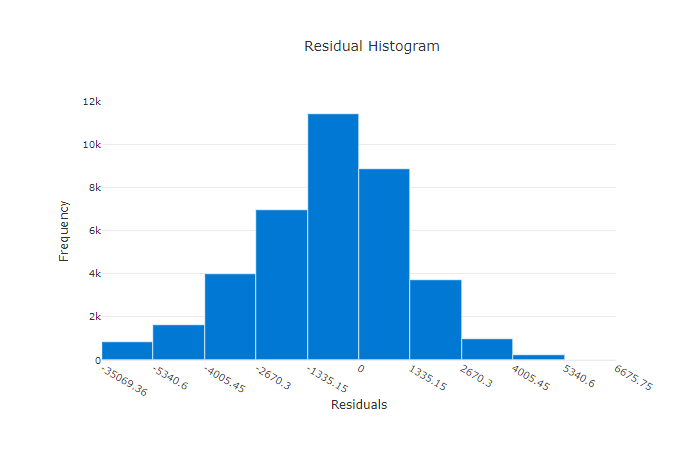
この例では、両方のモデルで、実際の値よりも低く予測するように若干偏っています。 実際のターゲットが傾斜分布しているデータセットの場合、これは珍しくありませんが、モデルのパフォーマンスが悪いことを示します。 適切なモデルでは、極端な場合はごくわずかな残差の、最高でゼロの残差分布です。 適切でないモデルでは、ほぼゼロの少数のサンプルの、拡散した残差分布です。
適切なモデルの残差グラフ
適切でないモデルの残差グラフ
予測と True
回帰および予測の実験の場合、予測と True のグラフは、ターゲットの特徴 (True の値/実際の値) とモデルの予測との関係をプロットします。 True の値は x 軸に沿ってビン分割され、各ビンの平均予測値はエラー バーでプロットされます。 これにより、モデルで特定の値を予測するように偏りがあるかどうかを確認できます。 線は平均の予測を表示し、網掛けされた領域はその平均に対する予測の分散を示します。
多くの場合、最も一般的な True 値では、分散が最も低い、最も正確な予測です。 True の値が少ない理想的な y = x 線からの傾向線の距離は、外れ値に対するモデルのパフォーマンスを測る正しい尺度です。 グラフの下部にあるヒストグラムを使用して、実際のデータ分布を判断できます。 分布がまばらなデータ サンプルを追加すると、未認識のデータに対するモデルのパフォーマンスが向上することがあります。
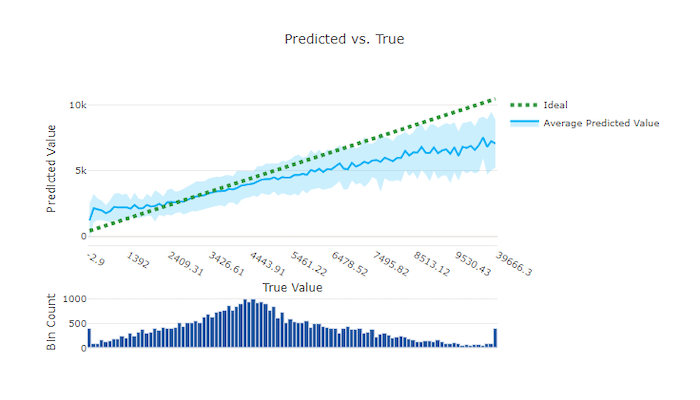
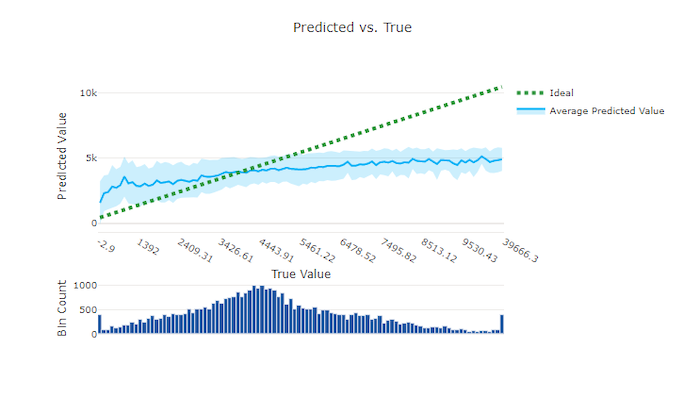
この例では、より優れたモデルで、予測と True の線が理想的な y = x の線に近くなっています。
適切なモデルの予測と True のグラフ
適切でないモデルの予測と True のグラフ
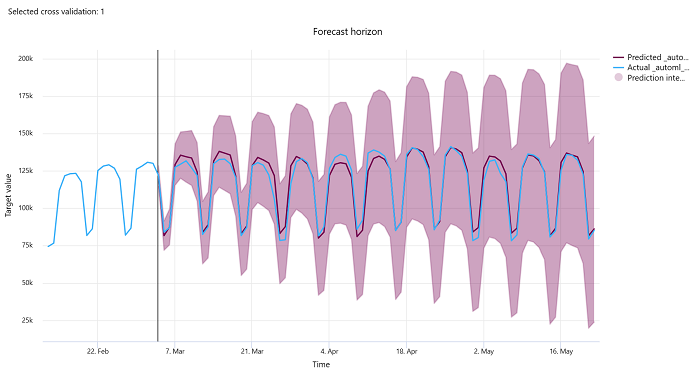
予測期間
予測実験の場合、予測期間グラフでは、モデルの予測値と、クロス検証フォールドあたりの時間経過に伴ってマップされた実際の値との関係がプロットされます (最大 5 個のフォールド)。 x 軸には、トレーニングの設定時に指定した頻度に基づいて時間がマップされます。 グラフの垂直線では、水平線とも呼ばれる予測水平点がマークされます。これは、予測の生成を開始する期間です。 予測水平線の左側には、過去の傾向をより適切に視覚化するための履歴トレーニング データを表示できます。 予測期間の右側には、さまざまなクロス検証フォールドと時系列識別子の実際の数値 (青い線) に対する予測 (紫色の線) を視覚化できます。 網かけの紫色の領域は、その平均に関する予測の信頼区間または分散を示します。
グラフの右上隅にある編集された (鉛筆) アイコンをクリックして、表示するクロス検証フォールドと時系列識別子の組み合わせを選択できます。 最初の 5 個のクロス検証フォールドと最大 20 個の異なる時系列識別子から選択して、さまざまな時系列のグラフを視覚化します。
重要
このグラフは、トレーニング データと検証データから生成されたモデルのトレーニング実行と、トレーニング データとテスト データに基づくテスト実行で使用できます。 予測の起点の前に最大 20 個のデータ ポイントと、その後に最大 80 個のデータ ポイントを使用できます。 DNN モデルの場合、トレーニング実行のこのグラフは、モデルが完全にトレーニングされた後の最後のエポックからのデータを示しています。 テスト実行のこのグラフは、トレーニングの実行中に検証データが明示的に指定された場合、水平線の前にギャップが発生する可能性があります。 これは、トレーニング データとテスト データがテスト実行で使用され、ギャップとなる検証データが省略されるためです。
イメージ モデルのメトリック (プレビュー)
モデルのパフォーマンスを評価するために、自動 ML には検証データセットの画像が使用されます。 トレーニングの進行状況を把握するために、モデルのパフォーマンスはエポックレベルで測定されます。 ニューラル ネットワーク内でデータセット全体が 1 回だけ送信と返信で渡されると、1 エポックが経過します。
画像分類メトリック
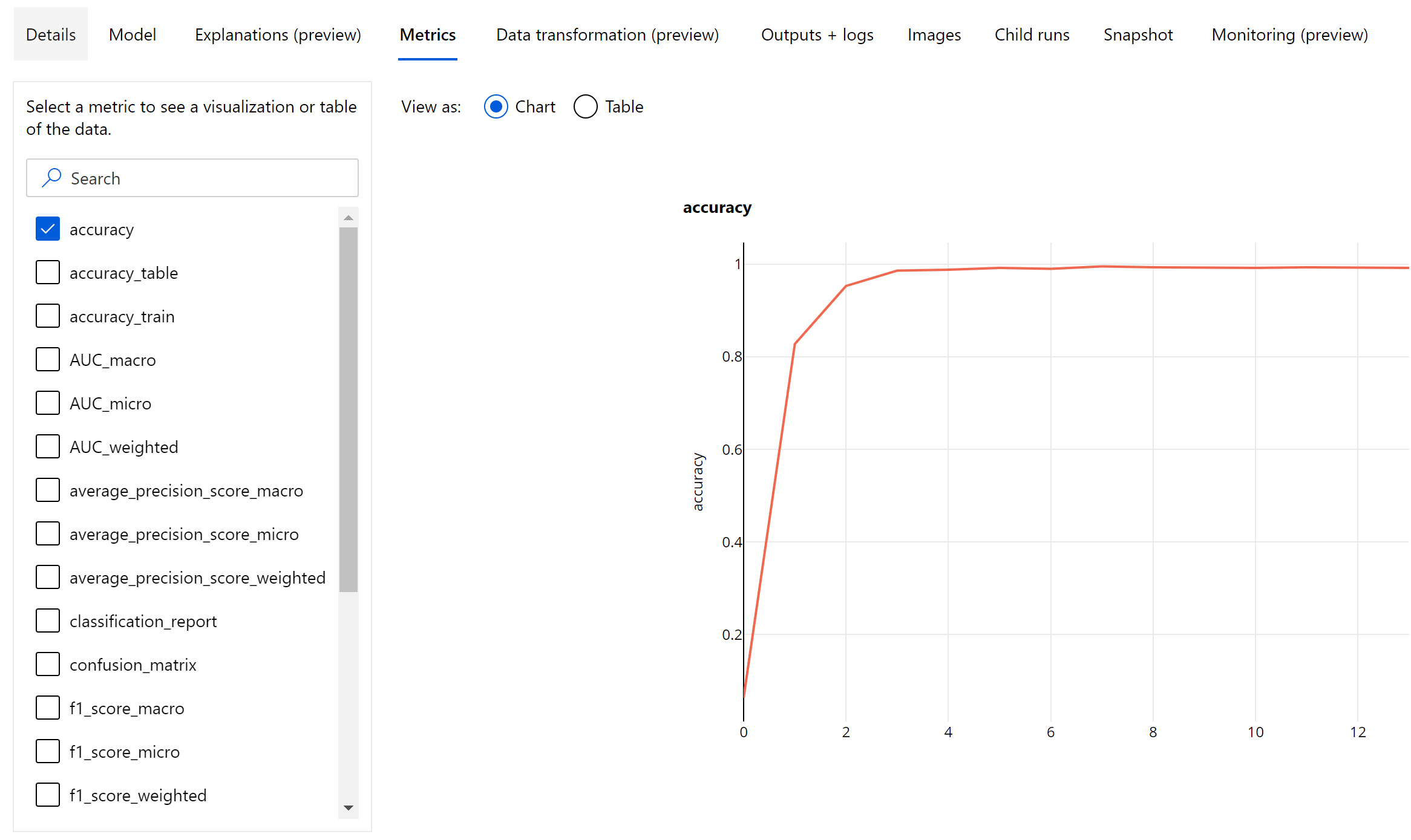
評価の主なメトリックは、バイナリおよびマルチクラス分類モデルの場合は正確性であり、マルチラベル分類モデルの場合は IoU (Intersection over Union) です。 画像分類モデルの分類メトリックは、「分類メトリック」セクションに定義されているものと同じです。 また、あるエポックに関連付けられた損失値はログに記録もされます。これは、トレーニングの進行状況を監視し、モデルが過剰適合か過少適合かを判断するのに役立ちます。
分類モデルのすべての予測は、予測が行われたときの信頼度のレベルを示す信頼度スコアと関連付けられています。 マルチラベル画像分類モデルは、既定では、0.5 のスコアしきい値を使用して評価されます。つまり、少なくともこのレベルの信頼性を持つ予測のみが、関連するクラスの陽性の予測と見なされます。 マルチクラス分類にはスコアしきい値が使用されませんが、代わりに、最大の信頼度スコアを持つクラスが予測と見なされます。
画像分類のためのエポックレベルのメトリック
表形式データセットの分類メトリックとは異なり、画像分類モデルの場合、以下に示すように、すべての分類メトリックはエポックレベルでログに記録されます。
画像分類の概要メトリック
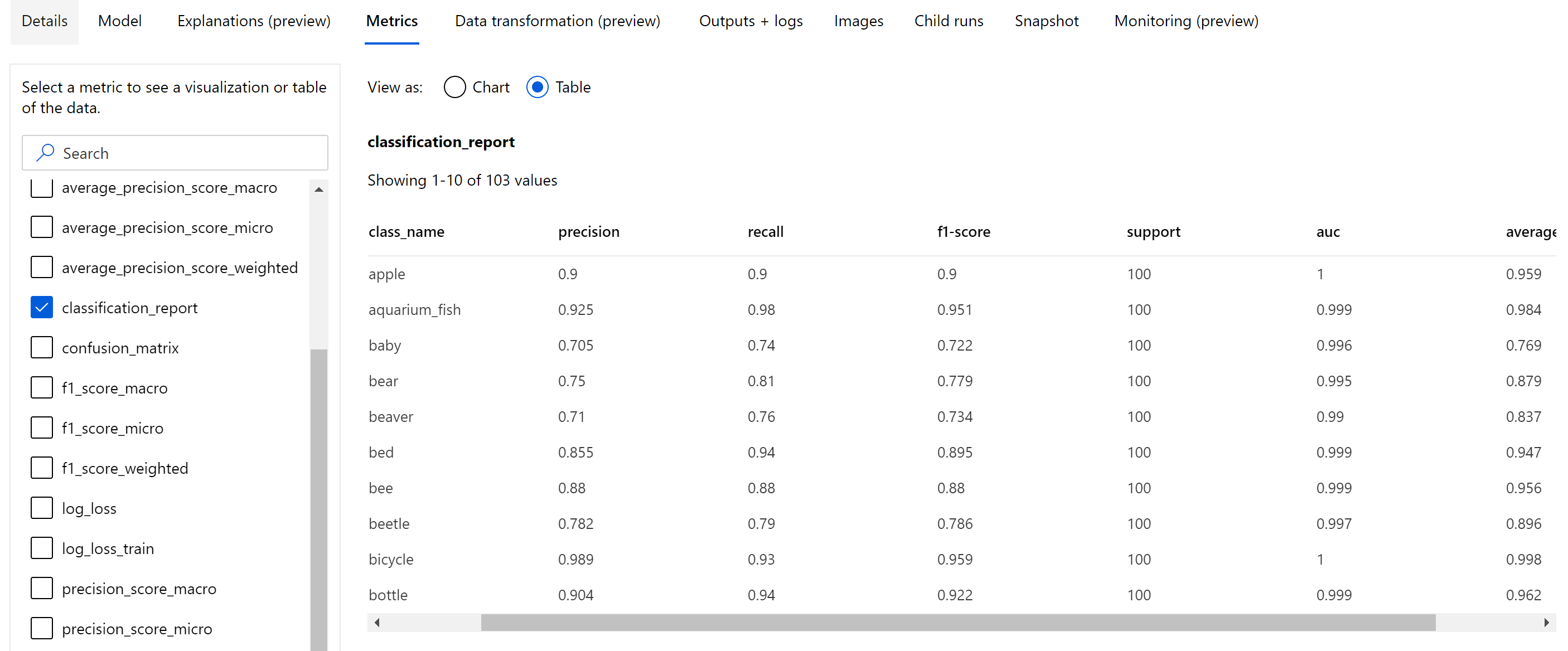
エポック レベルでログに記録されるスカラー メトリックとは別に、画像分類モデルの場合、混同行列、ROC 曲線、適合率 - 再現率曲線を含む分類グラフ、最高レベルの主要メトリック (正確性) スコアを取得した最善のエポックのモデルの分類レポートなどの概要メトリックもログに記録されます。
分類レポートには、適合率、リコール、f1 スコア、サポート、auc、平均適合率などのメトリックのクラスレベルの値を、以下に示すように、ミクロ、マクロ、加重といったさまざまなレベルの平均化と共に利用できます。 「分類メトリック」セクションのメトリック定義を参照してください。
オブジェクト検出とインスタンス セグメント化のメトリック
画像オブジェクト検出またはインスタンス セグメント化のモデルからのすべての予測は、信頼度スコアと関連付けられます。
信頼度スコアがスコアのしきい値より大きい予測は予測として出力され、メトリックの計算に使用されます。その既定値はモデルによって異なり、ハイパーパラメーターの調整に関するページ (box_score_threshold ハイパーパラメーター) から参照できます。
画像オブジェクト検出とインスタンス セグメント化モデルのメトリック コンピューティングは、IoU (Intersection over Union) というメトリックで定義される重複測定に基づいて行われます。これを計算するには、グランドトゥルースと予測の間の積集合を、グランドトゥルースと予測の和集合で除算します。 すべての予測から計算された IoU は、IoU しきい値と呼ばれる重複しきい値と比較されます。これでは、ユーザーが注釈を付けたグランドトゥルースとどれだけ予測が重なると、予測が陽性の予測と見なされるかが決定されます。 予測から計算された IoU が重複しきい値よりも小さい場合、その予測は関連するクラスの陽性の予測とは見なされません。
画像オブジェクト検出モデルとインスタンス セグメント化モデルを評価するための主要なメトリックは、平均適合率 (mAP) です。 mAP は、すべてのクラスの平均適合率 (AP) の平均値です。 自動化 ML オブジェクト検出モデルは、次の 2 つの一般的な方法を使用した mAP の計算をサポートしています。
パスカル VOC メトリック:
パスカル VOC mAP は、オブジェクト検出またはインスタンス セグメント化モデルで既定の mAP 計算方法です。 パスカル VOC スタイルの mAP 法により、適合率 - 再現率曲線のバージョンの下の面積が計算されます。 最初の p(rᵢ) は、再現率 i における適合率であり、すべての一意の再現率値に対して計算されます。 次に、p(rᵢ) は任意の再現率 r' >= rᵢ で取得された最大適合率に置き換えられます。 このバージョンの曲線の適合率値は、単調に減少しています。 パスカル VOC mAP メトリックは、既定では IoU しきい値 0.5 で評価されます。 この概念の詳細な説明については、このブログを参照してください。
COCO メトリック:
COCO 評価法の場合、10 個の IoU しきい値の平均値と共に、101 点補間法が AP の計算に使用されます。 AP@[.5:.95] は 0.5 から 0.95 までの IoU の平均 AP に対応し、ステップ サイズは 0.05 です。 自動 ML を使用すると、AP や AR (平均再現率) などの COCO 法で定義された 12 個のメトリックがさまざまなスケールでアプリケーション ログに記録されますが、メトリックのユーザー インターフェイスには、IoU しきい値が 0.5 の mAP のみが表示されます。
ヒント
ハイパーパラメーターの調整に関するセクションで説明されているように、validation_metric_typeハイパーパラメーターを 'coco' に設定すると、画像オブジェクト検出モデルの評価に coco メトリックを使用できます。
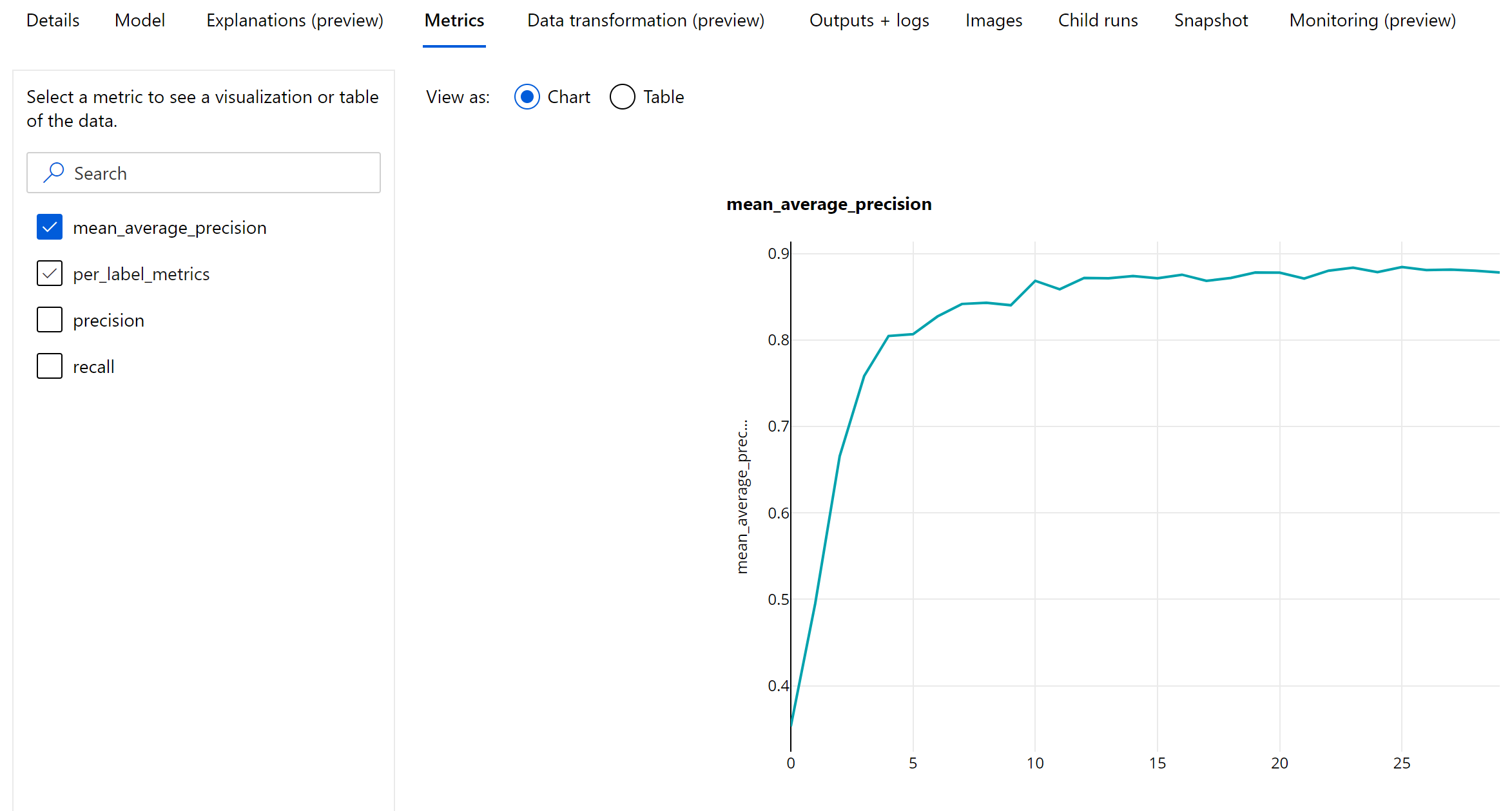
オブジェクト検出とインスタンス セグメント化のエポックレベル メトリック
mAP、適合率、再現率の値は、画像オブジェクト検出およびインスタンス セグメント化モデルのエポックレベルでログに記録されます。 また、mAP、適合率、再現率のメトリックは、'per_label_metrics' という名前でクラスレベルでもログに記録されます。 この 'per_label_metrics' は表形式で表示することをお勧めします。
注意
'coco' 法を使用している場合、適合率、再現率、ラベル単位のメトリックのエポックレベル メトリックは使用できません。
最も推奨される AutoML モデルのための責任ある AI ダッシュボード (プレビュー)
Azure Machine Learning の責任ある AI ダッシュボードには、責任ある AI を効果的かつ効率的に実際に実装するのに役立つ 1 つのインターフェイスが用意されています。 責任ある AI ダッシュボードは、表形式のデータを使用する場合のみサポートされ、分類モデルと回帰モデルでのみサポートされます。 これは、次に示す分野のいくつかの成熟した責任ある AI ツールを 1 つにまとめたものです。
- モデルのパフォーマンスと公平性の評価
- データの探索
- 機械学習の解釈可能性
- エラー分析
モデル評価メトリックとグラフはモデルの一般的な品質を測定するのに適していますが、責任ある AI を実践する場合、モデルの公平性の検査、その説明の表示 (モデルが予測に使用したデータセットの特徴とも呼ばれます)、エラーと潜在的なモデルの盲点の検査などの操作が不可欠です。 そのため、自動 ML は、モデルに関するさまざまな分析情報を観察するのに役立つ責任ある AI ダッシュボードを提供します。 Azure Machine Learning スタジオで 責任ある AI ダッシュボードを表示する方法をご覧ください。
UI または SDK を介してこのダッシュボードを生成する方法を確認してください。
モデルの説明と特徴の重要度
モデル評価メトリックおよびグラフは、モデルの一般的な質を測るのに適していますが、信頼できる AI を実現するには、モデルがその予測にデータセットのどの特徴を使用したかを調査することが重要です。 データセットの特徴の相対的なコントリビューションを測定してレポートする、モデルの説明ダッシュボードが自動 ML に備わっているのは、このためです。 Azure Machine Learning スタジオで説明ダッシュボードを表示する方法をご覧ください。
注意
解釈可能性、最適なモデルの説明は、次のアルゴリズムを最適なモデルまたはアンサンブルとして推奨する自動 ML の予測実験では使用できません。
- TCNForecaster
- AutoArima
- ExponentialSmoothing
- Prophet
- 平均
- Naive
- Seasonal Average
- Seasonal Naive
次のステップ
- 自動機械学習モデルの説明のサンプル ノートブックを試してください。
- 自動 ML 固有の質問については、askautomatedml@microsoft.com にお問い合わせください。