チュートリアル: Azure Machine Learning Studio でコードなし自動機械学習を使用して需要を予測する
Azure Machine Learning スタジオで自動機械学習を使用し、1 行のコードも記述せずに時系列予測モデルを作成する方法について説明します。 このモデルは、自転車シェアリング サービスのレンタル需要を予測します。
このチュートリアルではコードを一切記述しません。スタジオのインターフェイスを使用してトレーニングを実行します。 次のタスクを実行する方法について説明します。
- データセットを作成して読み込む。
- 自動 ML 実験を構成して実行する。
- 予測設定を指定する。
- 実験結果を調べる。
- 最適なモデルをデプロイする。
他のタイプのモデルについても、自動機械学習を試してみましょう。
- ノーコードの分類モデルの例については、「チュートリアル: Azure Machine Learning の自動 ML で分類モデルを作成する」を参照してください。
- 物体検出モデルの Code First の例については、「チュートリアル: AutoML と Python を使用して物体検出モデルをトレーニングする」を参照してください。
前提条件
Azure Machine Learning ワークスペース。 「ワークスペース リソースの作成」 を参照してください。
bike-no.csv のデータ ファイルをダウンロードします
スタジオにサインインする
このチュートリアルでは、Azure Machine Learning Studio で自動 ML 実験の実行を作成します。Azure Machine Learning Studio は、あらゆるスキル レベルのデータ サイエンス実務者がデータ サイエンス シナリオを実行するための機械学習ツールを含む統合 Web インターフェイスです。 スタジオは Internet Explorer ブラウザーではサポートされません。
Azure Machine Learning Studio にサインインします。
お使いのサブスクリプションと、作成したワークスペースを選択します。
[Get started](作業を開始する) を選択します。
左側のウィンドウの [Author](作成者) セクションで [Automated ML](自動 ML) を選択します。
[+ 新規の自動機械学習ジョブ] を選びます。
データセットを作成して読み込む
実験を構成する前に、Azure Machine Learning データセットの形式でデータ ファイルをワークスペースにアップロードします。 そうすることで、データを実験に適した形式にすることができます。
[データセットの選択] フォームで、[+データセットの作成] ドロップダウンから [From local files](ローカル ファイルから) を選びます。
[基本情報] フォームでデータセットに名前を付け、必要に応じて説明を入力します。 現在、Azure Machine Learning スタジオの自動 ML でサポートされるデータセットは表形式のみであるため、データセットの種類は既定で表形式に設定されます。
左下の [次へ] を選択します
[データストアとファイルの選択] フォームで、ワークスペースの作成時に自動的に設定された既定のデータストア、workspaceblobstore (Azure Blob Storage) を選択します。 これは、データ ファイルをアップロードするストレージの場所です。
[アップロード] ドロップダウンから、[ファイルのアップロード] を選択します。
ローカル コンピューター上の bike-no.csv ファイルを選択します。 これは、前提条件としてダウンロードしたファイルです。
[次へ] を選択します
アップロードが完了すると、ファイルの種類に基づいて [Settings and preview](設定とプレビュー) フォームが事前設定されます。
[Settings and preview](設定とプレビュー) フォームが次のように設定されていることを確認し、 [次へ] を選択します。
フィールド 説明 チュートリアルの値 ファイル形式 ファイルに格納されているデータのレイアウトと種類を定義します。 区切り記号 区切り記号 プレーン テキストまたは他のデータ ストリーム内の個別の独立した領域の間の境界を指定するための 1 つ以上の文字。 コンマ エンコード データセットの読み取りに使用する、ビットと文字のスキーマ テーブルを識別します。 UTF-8 列見出し データセットの見出しがある場合、それがどのように処理されるかを示します。 最初のファイルのみにヘッダーがある 行のスキップ データセット内でスキップされる行がある場合、その行数を示します。 なし [スキーマ] フォームを使用すると、この実験用にデータをさらに構成できます。
この例では、casual と registered 列を無視するように選択します。 これらの列は cnt 列の内訳であるため、それらを含めません。
また、この例では、Properties と Type の既定値をそのまま使用します。
[次へ] を選択します。
[詳細の確認] フォームで、[基本情報] および [Settings and preview](設定とプレビュー) のフォームに入力された情報が一致していることを確認します。
[作成] を選択して、データセットの作成を完了します。
リストにデータセットが表示されたら、それを選択します。
[次へ] を選びます。
ジョブを構成する
データを読み込んで構成したら、リモート コンピューティング先を設定し、予測するデータの列を選択します。
- 次のように [ジョブの構成] フォームに入力します。
実験の名前として「
automl-bikeshare」と入力します。予測するターゲット列として、 [cnt] を選択します。 この列は、自転車シェアリング レンタルの合計数を示します。
コンピューティングの種類として [コンピューティング クラスター] を選択します。
[+新規] を選択して、ストレージおよびコンピューティング ターゲットを構成します。 自動 ML では、Azure Machine Learning コンピューティングのみがサポートされます。
[仮想マシンの選択] フォームに必要事項を入力してコンピューティングを設定します。
フィールド 説明 チュートリアルの値 仮想マシンの階層 実験の優先度を選択します。 専用 仮想マシンのタイプ コンピューティング用の仮想マシンの種類を選択します。 CPU (中央処理装置) 仮想マシンのサイズ コンピューティングの仮想マシン サイズを選択します。 指定したデータと実験の種類に基づいて、推奨サイズの一覧が提供されます。 Standard_DS12_V2 [次へ] を選択して、 [Configure settings](構成の設定) フォームに必要事項を入力します。
フィールド 説明 チュートリアルの値 コンピューティング名 コンピューティング コンテキストを識別する一意名。 bike-compute 最小/最大ノード データをプロファイリングするには、1 つ以上のノードを指定する必要があります。 最小ノード: 1
最大ノード: 6スケール ダウンする前のアイドル時間 (秒) クラスターが自動的に最小ノード数にスケールダウンされるまでのアイドル時間。 120 (既定値) 詳細設定 実験用の仮想ネットワークを構成および承認するための設定。 なし [作成] を選択して、コンピューティング先を取得します。
完了するまでに数分かかります。
作成後、ドロップダウン リストから新しいコンピューティング先を選択します。
[次へ] を選択します。
予測設定を選択する
機械学習のタスクの種類と構成設定を指定して、自動 ML 実験の設定を完了します。
[Task type and settings](タスクの種類と設定) フォームで、機械学習のタスクの種類として [時系列の予測] を選択します。
[時刻列] として [date] を選択し、 [時系列識別子] を空白のままにします。
[頻度] は、履歴データの収集頻度です。 [自動検出] を選択したままにします。
予測期間とは、予測対象となる将来の時間の長さです。 [自動検出] の選択を解除し、フィールドに「14」と入力します。
[View additional configuration settings](追加の構成設定を表示) を選択し、次のようにフィールドを設定します。 これらは、トレーニング ジョブをより細かく制御し、予測の設定を指定するための設定です。 設定しない場合、実験の選択とデータに基づいて既定値が適用されます。
追加の構成 説明 チュートリアルの値 主要メトリック 機械学習アルゴリズムを測定される評価メトリック。 正規化された平均平方二乗誤差 最適なモデルの説明 自動 ML で作成された最適なモデルの説明を自動的に表示します。 有効化 ブロックされたアルゴリズム トレーニング ジョブから除外するアルゴリズム 極端なランダム ツリー その他の予測設定 これらの設定は、モデルの精度を向上させるのに役立ちます。
[Forecast target lags]\(予測ターゲットのラグ\): ターゲット変数のラグをどの程度さかのぼって作成するかを指定します
ターゲットのローリング ウィンドウ: max、min、sum などの特徴が生成されるローリング ウィンドウのサイズを指定します。
予測ターゲットのラグ: なし
ターゲットのローリング ウィンドウ サイズ: なし終了条件 条件が満たされると、トレーニング ジョブが停止します。 トレーニング ジョブ時間 (時間単位): 3
Metric score threshold (メトリック スコアのしきい値): なしコンカレンシー イテレーションごとに実行される並列イテレーションの最大数 コンカレント イテレーションの最大数: 6 [保存] を選択します。
[次へ] を選択します。
[[省略可能] 検証とテスト] フォームで、
- [検証の種類] として [k 分割交差検証] を選択します。
- [クロス検証の数] として 5 を選択します。
実験を実行する
実験を実行するには、 [終了] を選択します。 [ジョブの詳細] 画面が開き、上部のジョブ番号の横に [ジョブの状態] が表示されます。 この状態は、実験の進行に応じて更新されます。 スタジオの右上隅にも、実験の状態を表す通知が表示されます。
重要
実験のジョブの準備には、10 から 15 分かかります。
実行の開始後、各イテレーションのためにさらに 2、3 分かかります。
実稼働環境では、このプロセスには時間がかかるため、しばらくお待ちください。 待機している間に、アルゴリズムのテストが終わり次第、 [モデル] タブで調査を開始することをお勧めします。
モデルを調査する
[モデル] タブに移動し、テストされたアルゴリズム (モデル) を確認します。 既定では、モデルは完了時のメトリック スコアで並べ替えられます。 このチュートリアルでは、選択した正規化された平均平方二乗誤差メトリックに基づいて最も高いスコアを獲得したモデルがリストの一番上に表示されます。
すべての実験モデルが終了するのを待っている間に、完了したモデルの [アルゴリズム名] を選択して、そのパフォーマンスの詳細を調査します。
次の例では、ジョブが作成したモデルのリストからモデルを選択します。 次に、[概要] と [メトリック] のタブを選択すると、選択したモデルのプロパティ、メトリック、およびパフォーマンス グラフが表示されます。
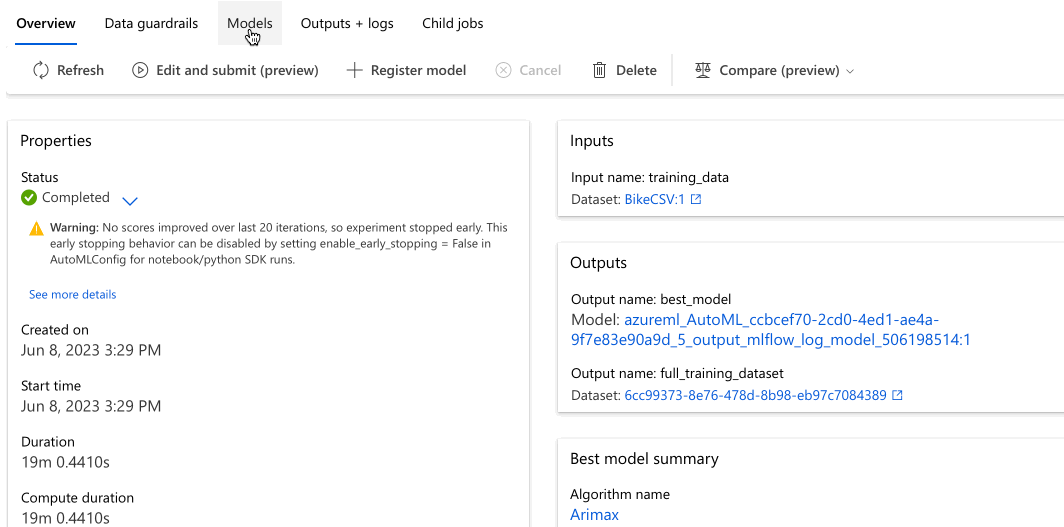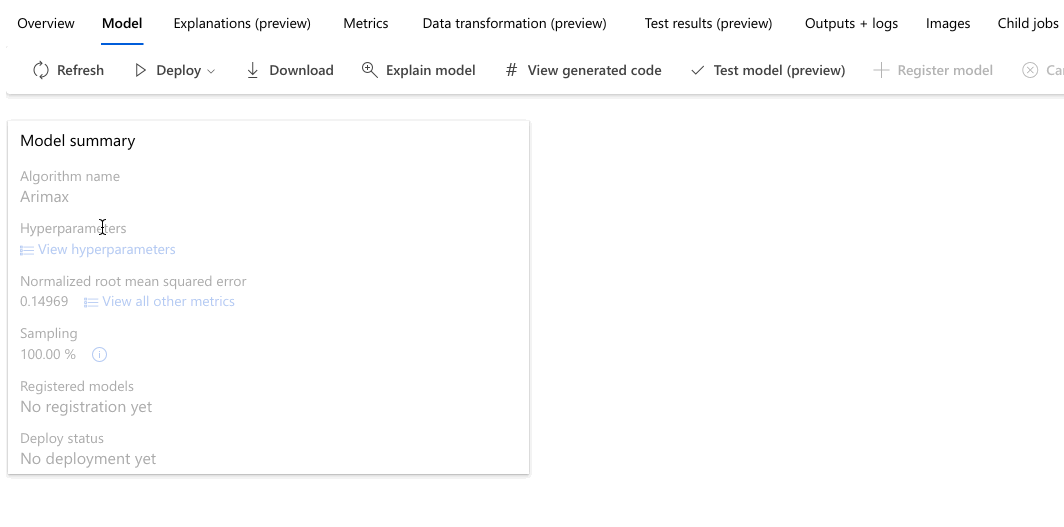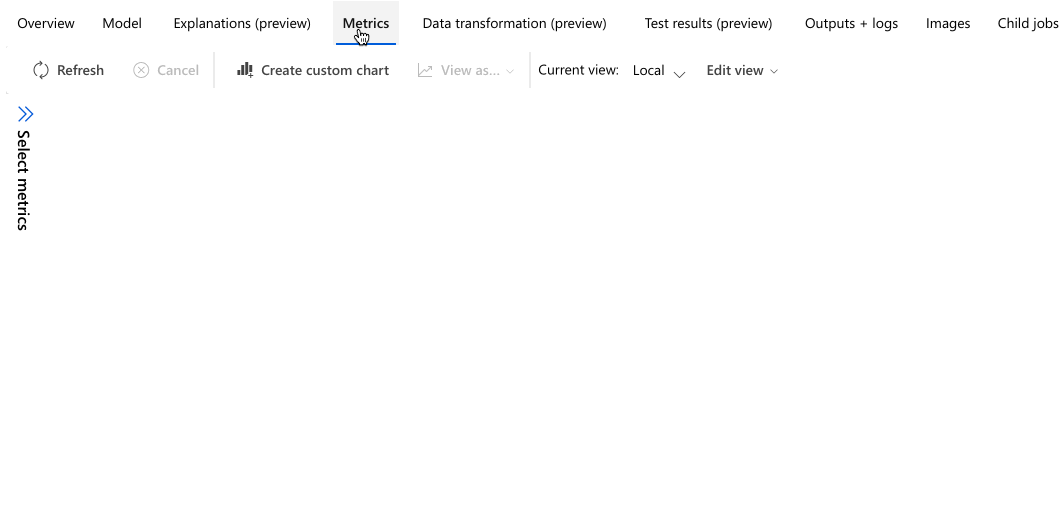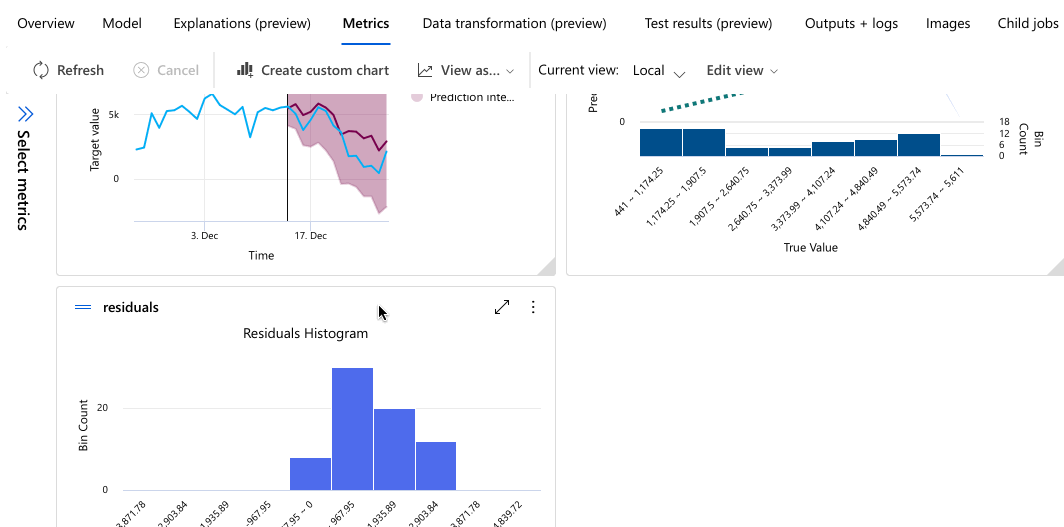
モデルをデプロイする
Azure Machine Learning Studio で自動機械学習を使用すると、わずかなステップで最良のモデルを Web サービスとしてデプロイすることができます。 デプロイとは、新しいデータを予測したり、潜在的な機会領域を特定したりできるようにモデルを統合することです。
この実験では、Web サービスへのデプロイは、自転車シェアリングのレンタル需要を予測するための反復的でスケーラブルな Web ソリューションを自転車シェアリング会社が持つことを意味します。
ジョブが完了したら、画面の上部にある [ジョブ 1] を選んで、親のジョブ ページに戻ります。
正規化された平均平方二乗誤差メトリックに基づいて、[Best model summary](最適なモデルの概要) セクションで、この実験のコンテキストで最適なモデルが選択されます。
このモデルをデプロイしますが、デプロイには完了まで約 20 分かかることにご留意ください。 デプロイ プロセスには、モデルを登録したり、リソースを生成したり、Web サービス用にそれらを構成したりすることを含む、いくつかの手順が伴います。
最適なモデル を選択して、モデル固有のページを開きます。
画面の左上の領域にある [デプロイ] ボタンを選択します。
[Deploy a model](モデルのデプロイ) ペインに次のように入力します。
フィールド 値 デプロイ名 bikeshare-deploy デプロイの説明 自転車シェアリング需要のデプロイ コンピューティングの種類 Azure のコンピューティング インスタンス (ACI) を選択します。 認証を有効にする 無効。 カスタム デプロイ アセットを使用する 無効。 無効化によって、既定のドライバー ファイル (スコアリング スクリプト) と環境ファイルが自動的に生成されます。 この例では、 [Advanced](詳細) メニューに指定されている既定値を使用します。
[デプロイ] を選択します。
デプロイが正常に開始されたことを示す緑色の成功メッセージが、[ジョブ] 画面の上部に表示されます。 デプロイの進行状況は、 [モデルの概要] ペインの [Deploy status](デプロイの状態) で確認できます。
デプロイに成功すると、予測を生成するための実稼働 Web サービスが作成されます。
新しい Web サービスの使い方、Azure Machine Learning サポートに組み込まれている Power BI を使用した予測のテスト方法の詳細については、次のステップに進みます。
リソースをクリーンアップする
デプロイ ファイルはデータ ファイルと実験ファイルよりも大きいため、格納コストは高くなります。 アカウントのコストを最小限に抑える場合、またはワークスペースと実験ファイルを保持する場合は、デプロイ ファイルだけを削除します。 それ以外の場合で、いずれのファイルも使用する予定がない場合は、リソース グループ全体を削除します。
デプロイ インスタンスの削除
他のチュートリアルや探索用にリソース グループとワークスペースを維持する場合は、Azure Machine Learning Studio からデプロイ インスタンスだけを削除します。
Azure Machine Learning Studio に移動します。 お使いのワークスペースに移動し、左側の [アセット] ウィンドウの下の [エンドポイント] を選択します。
削除するデプロイを選択し、 [削除] を選択します。
[続行] を選択します。
リソース グループを削除します
重要
作成したリソースは、Azure Machine Learning に関連したその他のチュートリアルおよびハウツー記事の前提条件として使用できます。
作成したどのリソースも今後使用する予定がない場合は、課金が発生しないように削除します。
Azure portal の検索ボックスに「リソース グループ」と入力し、それを結果から選択します。
一覧から、作成したリソース グループを選択します。
[概要] ページで、[リソース グループの削除] を選択します。
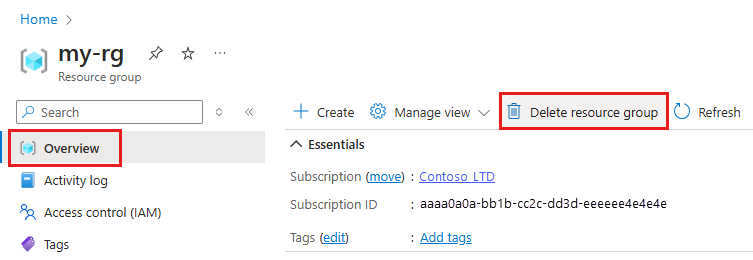
リソース グループ名を入力します。 次に、 [削除] を選択します。
次のステップ
このチュートリアルでは、Azure Machine Learning Studio で自動 ML を使用して、自転車シェアリングのレンタル需要を予測する時系列予測モデルを作成してデプロイしました。
- 自動機械学習についてさらに理解を深める。
- 分類メトリックとグラフの詳細については、「自動化機械学習の結果の概要」の記事を参照してください。
- 予測に関する FAQ の詳細を参照してください。
Note
この自転車シェアリング データセットは、このチュートリアル用に変更されています。 このデータセットは、Kaggle コンテストの一部として提供されており、もともとは Capital Bikeshare を通じて入手可能でした。 また、UCI Machine Learning データベースにもあります。
ソース:Fanaee-T, Hadi, and Gama, Joao、「Event labeling combining ensemble detectors and background knowledge」、Progress in Artificial Intelligence (2013): pp. 1-15、Springer Berlin Heidelberg。