機械学習モデルを Azure にデプロイする
適用対象: Azure CLI ML 拡張機能 v1Python SDK azureml v1
Azure CLI ML 拡張機能 v1Python SDK azureml v1
機械学習またはディープ ラーニング モデルを Web サービスとして Azure クラウドにデプロイする方法について説明します。
注意
Azure Machine Learning のエンドポイント (v2) では、デプロイが改善され、シンプルになります。 エンドポイントは、リアルタイム シナリオとバッチ推論の両方をサポートします。 エンドポイントは、複数のコンピューティングの種類にわたってモデル デプロイを起動および管理するための統一インターフェイスを提供します。 「Azure Machine Learning エンドポイントとは」を参照してください。
モデルをデプロイするためのワークフロー
モデルをどこにデプロイするかに関係なく、ワークフローは同様です。
- モデルを登録します。
- エントリ スクリプトを用意します。
- 推論構成を準備します。
- モデルをローカルにデプロイして、すべてが正しく動作することを確認します。
- コンピューティング ターゲットを選択します。
- モデルをクラウドにデプロイします。
- 結果の Web サービスをテストします。
機械学習デプロイ ワークフローに関連する概念の詳細については、Azure Machine Learning でのモデルの管理、デプロイ、監視に関する記事を参照してください。
前提条件
適用対象:Azure CLI ml extension v1
重要
この記事の Azure CLI コマンドの一部では、Azure Machine Learning 用に azure-cli-ml、つまり v1 の拡張機能を使用しています。 v1 拡張機能のサポートは、2025 年 9 月 30 日に終了します。 その日付まで、v1 拡張機能をインストールして使用できます。
2025 年 9 月 30 日より前に、ml (v2) 拡張機能に移行することをお勧めします。 v2 拡張機能の詳細については、Azure Machine Learning CLI 拡張機能と Python SDK v2 に関する記事を参照してください。
- Azure Machine Learning ワークスペース。 詳細については、ワークスペース リソースの作成に関するページを参照してください。
- モデルです。 この記事の例では、事前トレーニング済みのモデルを使用します。
- コンピューティング インスタンスなどの、Docker を実行できるコンピューター。
ワークスペースに接続する
適用対象:Azure CLI ml extension v1
アクセスできるワークスペースを表示するには、次のコマンドを使用します。
az login
az account set -s <subscription>
az ml workspace list --resource-group=<resource-group>
モデルを登録する
展開する機械学習サービスには通常、次のものが必要です。
- デプロイする特定のモデルを表すリソース (例: Pytorch モデルのファイル)
- 特定の入力に対してモデルを実行するサービス上で実行されるコード。
Azure Machine Learnings では、サービスを 2 つの部分に分けて展開することにより、それまでと同じコードを維持しつつモデルを更新できます。 コードとは "別に" モデルをアップロードする仕組みを "モデルの登録" と定義しています。
モデルを登録すると、そのモデルは (ワークスペースの既定のストレージ アカウントの) クラウドにアップロードされ、Web サービスを実行しているコンピューターにマウントされます。
次の例では、モデルを登録する方法を示します。
重要
自分で作成したモデルまたは信頼できるソースから取得したモデルのみを使用する必要があります。 多数の一般的な形式でセキュリティの脆弱性が発見されているため、シリアル化されたモデルはコードとして扱う必要があります。 また、偏りのある出力や不正確な出力を提供するように、モデルが悪意のある目的で意図的にトレーニングされる場合もあります。
適用対象:Azure CLI ml extension v1
次のコマンドでは、モデルがダウンロードされ、Azure Machine Learning ワークスペースに登録されます。
wget https://aka.ms/bidaf-9-model -O model.onnx --show-progress
az ml model register -n bidaf_onnx \
-p ./model.onnx \
-g <resource-group> \
-w <workspace-name>
-p を、登録したいフォルダまたはファイルのパスに設定してください。
az ml model register の詳細については、リファレンス ドキュメントを参照してください。
Azure Machine Learning トレーニング ジョブからモデルを登録する
Azure Machine Learning トレーニング ジョブによって以前に作成したモデルを登録する必要がある場合は、実験、実行、およびモデルへのパスを指定できます。
az ml model register -n bidaf_onnx --asset-path outputs/model.onnx --experiment-name myexperiment --run-id myrunid --tag area=qna
--asset-path パラメーターは、クラウドでのモデルの場所を示します。 この例では、1 つのファイルへのパスが使用されます。 モデルの登録に複数のファイルを含めるには、--asset-path を、それらのファイルが含まれているフォルダーのパスに設定します。
az ml model register の詳細については、リファレンス ドキュメントを参照してください。
Note
ワークスペース UI ポータルを使用して、ローカル ファイルからモデルを登録することもできます。
現在、UI でローカル モデル ファイルをアップロードするには、次の 2 つのオプションがあります。
- v2 モデルを登録するローカル ファイルから。
- v1 モデルを登録する (フレームワークに基づく) ローカル ファイルから。
SDKv1/CLIv1 を使用して Web サービスとしてデプロイできるのは、(フレームワークに基づく) ローカル ファイルからの入口を介して登録されたモデル (v1 モデルと呼ばれる) のみであることに注意してください。
ダミー エントリ スクリプトを用意する
エントリ スクリプトは、デプロイされた Web サービスに送信されたデータを受け取り、それをモデルに渡します。 次に、クライアントに対するモデルの応答が返されます。 このスクリプトはこのモデルに固有のものです。 エントリ スクリプトでは、モデルが受け入れ、返すデータを認識する必要があります。
エントリ スクリプトでは、次の 2 つの処理を実行する必要があります。
- モデルの読み込み (
init()という関数を使用) - 入力データでのモデルの実行 (
run()という関数を使用)
最初のデプロイでは、受け取ったデータを出力するダミーのエントリ スクリプトを使用します。
import json
def init():
print("This is init")
def run(data):
test = json.loads(data)
print(f"received data {test}")
return f"test is {test}"
このファイルを source_dir と いう名前のディレクトリ内にecho_score.py として保存します。 このダミー スクリプトによって、送信したデータが返されるため、モデルは使用されません。 ただし、スコアリング スクリプトが実行されていることをテストするのに役立ちます。
推論構成を定義する
推論構成には、Web サービスの初期化時に使用する Docker コンテナーとファイルを記述します。 Web サービスを展開するときは、ソース ディレクトリにあるすべてのファイル (サブディレクトリを含む) を圧縮してクラウドにアップロードします。
下の推論構成では、展開する機械学習サービスで、./source_dir ディレクトリの echo_score.py ファイルによって受信要求を処理することと、project_environment 環境で指定した Python パッケージを Docker イメージで使用することを指定しています。
プロジェクトの環境を作成するときは、任意の Azure Machine Learning 推論でキュレーションされた環境を、ベースの Docker イメージとして使用できます。 必要な依存関係がそこにインストールされ、作成された Docker イメージが、皆さまのワークスペースに紐付いたレポジトリに保存されます。
注意
Azure Machine Learning の推論ソース ディレクトリのアップロードでは、 .gitignore または .amlignore が考慮されません
適用対象:Azure CLI ml extension v1
最小限の推論構成は、次のように記述することができます。
{
"entryScript": "echo_score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "1"
}
}
dummyinferenceconfig.json という名前でこのファイルを保存します。
推論構成に関する詳細な説明については、こちらの記事を参照してください。
デプロイ構成を定義する
デプロイ構成では、Web サービスが実行するために必要とするメモリとコアの量を指定します。 また、基になる Web サービスの構成の詳細も提供します。 展開構成ではたとえば、メモリ 2 GB、CPU コア 2 個、GPU コア 1 個をサービスで使用し、自動スケーリングを有効にすることを指定できます。
デプロイ構成で使用できるオプションは、選択するコンピューティング ターゲットによって異なります。 ローカルに展開する場合は、Web サービスで使用するポートだけを指定できます。
適用対象:Azure CLI ml extension v1
deploymentconfig.json ドキュメントのエントリは、LocalWebservice.deploy_configuration のパラメーターにマッピングされます。 次の表は、JSON ドキュメントのエントリとメソッド用パラメーターの間のマッピングについてまとめたものです。
| JSON エンティティ | メソッド パラメーター | 説明 |
|---|---|---|
computeType |
NA | コンピューティング ターゲット。 ローカル ターゲットの場合、値は local である必要があります。 |
port |
port |
サービスの HTTP エンドポイントを公開するローカル ポート。 |
この JSON は、CLI で使用するデプロイ構成の例です。
{
"computeType": "local",
"port": 32267
}
この JSON を deploymentconfig.json という名前のファイルとして保存します。
詳しくは、デプロイ スキーマに関するページを参照してください。
機械学習モデルをデプロイする
これでモデルをデプロイする準備が整いました。
適用対象:Azure CLI ml extension v1
bidaf_onnx:1 を、モデルの名前とそのバージョン番号に置き換えます。
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic dummyinferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
モデルに対する呼び出しを行う
エコー モデルを正しく展開できたことを確認しましょう。 単純な liveness の要求やスコアリング要求を実行できるはずです。
適用対象:Azure CLI ml extension v1
curl -v http://localhost:32267
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
エントリ スクリプトを定義する
ここでは、モデルをロードします。 最初にエントリ スクリプトを修正します。
import json
import numpy as np
import os
import onnxruntime
from nltk import word_tokenize
import nltk
def init():
nltk.download("punkt")
global sess
sess = onnxruntime.InferenceSession(
os.path.join(os.getenv("AZUREML_MODEL_DIR"), "model.onnx")
)
def run(request):
print(request)
text = json.loads(request)
qw, qc = preprocess(text["query"])
cw, cc = preprocess(text["context"])
# Run inference
test = sess.run(
None,
{"query_word": qw, "query_char": qc, "context_word": cw, "context_char": cc},
)
start = np.asscalar(test[0])
end = np.asscalar(test[1])
ans = [w for w in cw[start : end + 1].reshape(-1)]
print(ans)
return ans
def preprocess(word):
tokens = word_tokenize(word)
# split into lower-case word tokens, in numpy array with shape of (seq, 1)
words = np.asarray([w.lower() for w in tokens]).reshape(-1, 1)
# split words into chars, in numpy array with shape of (seq, 1, 1, 16)
chars = [[c for c in t][:16] for t in tokens]
chars = [cs + [""] * (16 - len(cs)) for cs in chars]
chars = np.asarray(chars).reshape(-1, 1, 1, 16)
return words, chars
このファイルを score.py という名前で source_dir の中に保存します。
AZUREML_MODEL_DIR 環境変数で、登録したモデルの場所を確認できます。 これで、いくつかの pip パッケージを追加できました。
適用対象:Azure CLI ml extension v1
{
"entryScript": "score.py",
"sourceDirectory": "./source_dir",
"environment": {
"docker": {
"arguments": [],
"baseDockerfile": null,
"baseImage": "mcr.microsoft.com/azureml/openmpi3.1.2-ubuntu18.04",
"enabled": false,
"sharedVolumes": true,
"shmSize": null
},
"environmentVariables": {
"EXAMPLE_ENV_VAR": "EXAMPLE_VALUE"
},
"name": "my-deploy-env",
"python": {
"baseCondaEnvironment": null,
"condaDependencies": {
"channels": [],
"dependencies": [
"python=3.6.2",
{
"pip": [
"azureml-defaults",
"nltk",
"numpy",
"onnxruntime"
]
}
],
"name": "project_environment"
},
"condaDependenciesFile": null,
"interpreterPath": "python",
"userManagedDependencies": false
},
"version": "2"
}
}
このファイルを inferenceconfig.json として保存します
もう一度サービスを展開して呼び出す
もう一度サービスを展開します。
適用対象:Azure CLI ml extension v1
bidaf_onnx:1 を、モデルの名前とそのバージョン番号に置き換えます。
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
次に、POST 要求をサービスに送信できることを確認します。
適用対象:Azure CLI ml extension v1
curl -v -X POST -H "content-type:application/json" \
-d '{"query": "What color is the fox", "context": "The quick brown fox jumped over the lazy dog."}' \
http://localhost:32267/score
コンピューティング ターゲットを選択する
モデルをホストするために使用するコンピューティング先は、デプロイされているエンドポイントのコストと可用性に影響を及ぼします。 次のテーブルを使用して、適切なコンピューティング先を選択します。
| コンピューティング ターゲット | 使用目的 | GPU のサポート | 説明 |
|---|---|---|---|
| ローカル Web サービス | テスト/デバッグ | 制限付きのテストとトラブルシューティングに使用。 ハードウェア アクセラレーションは、ローカル システムでのライブラリの使用に依存します。 | |
| Azure Machine Learning Kubernetes | リアルタイムの推論 | はい | クラウドで推論ワークロードを実行します。 |
| Azure Container Instances | リアルタイムの推論 開発/テスト目的でのみ推奨されます。 |
必要な RAM が 48 GB より少ない低スケール CPU ベース ワークロードに使用。 クラスターを管理する必要はありません。 サイズが 1 GB 未満のモデルにのみ適しています。 デザイナーでサポートされています。 |
注意
クラスター SKU を選択する場合は、まずスケールアップしてからスケールアウトします。モデルで必要とされる RAM の 150% が搭載されたマシンから始め、結果をプロファイルして、必要なパフォーマンスを備えたマシンを見つけます。 これについて学習した後は、同時推定のニーズに合うようにマシンの数を増やします。
Note
Azure Machine Learning のエンドポイント (v2) では、デプロイが改善され、シンプルになります。 エンドポイントは、リアルタイム シナリオとバッチ推論の両方をサポートします。 エンドポイントは、複数のコンピューティングの種類にわたってモデル デプロイを起動および管理するための統一インターフェイスを提供します。 「Azure Machine Learning エンドポイントとは」を参照してください。
クラウドにデプロイする
サービスがローカルで動作することを確認してリモートのコンピューティング先を選んだら、クラウドに展開する準備は完了です。
選択したコンピューティング先 (この場合は Azure Container Instances) に合わせて展開構成を変更します。
適用対象:Azure CLI ml extension v1
デプロイ構成で使用できるオプションは、選択するコンピューティング ターゲットによって異なります。
{
"computeType": "aci",
"containerResourceRequirements":
{
"cpu": 0.5,
"memoryInGB": 1.0
},
"authEnabled": true,
"sslEnabled": false,
"appInsightsEnabled": false
}
このファイルを re-deploymentconfig.json として保存します。
詳細については、こちらのリファレンスを参照してください。
もう一度サービスを展開します。
適用対象:Azure CLI ml extension v1
bidaf_onnx:1 を、モデルの名前とそのバージョン番号に置き換えます。
az ml model deploy -n myservice \
-m bidaf_onnx:1 \
--overwrite \
--ic inferenceconfig.json \
--dc re-deploymentconfig.json \
-g <resource-group> \
-w <workspace-name>
サービス ログを表示するには、次のコマンドを使用します。
az ml service get-logs -n myservice \
-g <resource-group> \
-w <workspace-name>
リモートの Web サービスを呼び出す
リモートでデプロイを行う場合は、キー認証が有効になっている場合があります。 下の例では、推論要求を行うために Python でサービス キーを取得する方法を示します。
import requests
import json
from azureml.core import Webservice
service = Webservice(workspace=ws, name="myservice")
scoring_uri = service.scoring_uri
# If the service is authenticated, set the key or token
key, _ = service.get_keys()
# Set the appropriate headers
headers = {"Content-Type": "application/json"}
headers["Authorization"] = f"Bearer {key}"
# Make the request and display the response and logs
data = {
"query": "What color is the fox",
"context": "The quick brown fox jumped over the lazy dog.",
}
data = json.dumps(data)
resp = requests.post(scoring_uri, data=data, headers=headers)
print(resp.text)print(service.get_logs())他の言語のクライアントの例は、Web サービスのクライアント アプリケーションに関する記事をご覧ください。
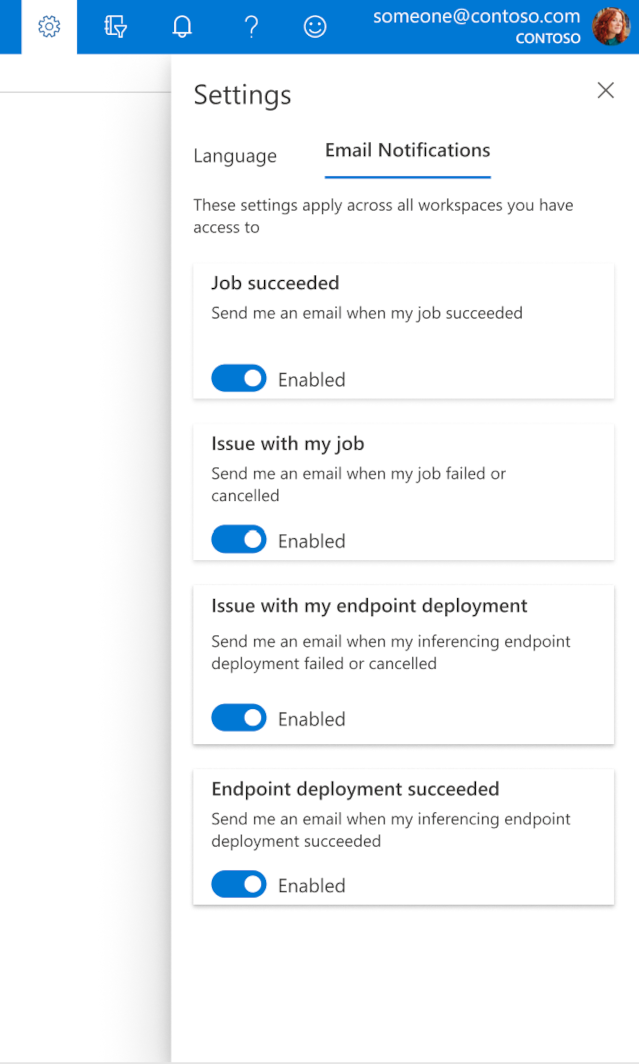
スタジオでメールを構成する方法
ジョブ、オンライン エンドポイント、またはバッチ エンドポイントが完了したとき、または問題 (失敗、キャンセル) が発生した場合のメールの受け取りを始めるには、次の手順のようにします。
- Azure ML スタジオで、歯車アイコンを選んで設定に移動します。
- [電子メール通知] タブを選択します。
- 特定のイベントの電子メール通知を有効または無効に切り替えます。
サービスの状態について
モデルのデプロイ中に、完全にデプロイされるまでの間に、サービスの状態が変化することがあります。
次の表で、サービスの各状態について説明します。
| Web サービスの状態 | 説明 | 最終的な状態 |
|---|---|---|
| 移行中 | サービスはデプロイ処理中です。 | いいえ |
| 異常 | サービスはデプロイされましたが、現在アクセスできません。 | いいえ |
| スケジュール不可 | リソースが不足しているため、現時点ではサービスをデプロイできません。 | いいえ |
| 失敗 | エラーまたはクラッシュが発生したため、サービスをデプロイできませんでした。 | はい |
| Healthy | サービスは正常であり、エンドポイントを使用できます。 | はい |
ヒント
デプロイ時に、コンピューティング ターゲットの Docker イメージが構築され、Azure Container Registry (ACR) から読み込まれます。 既定では、Azure Machine Learning により、basic サービス レベルを使用する ACR が作成されます。 ワークスペースの ACR を standard レベルまたは premium レベルに変更すると、イメージを構築してコンピューティング ターゲットにデプロイするための時間を短縮することができます。 詳細については、「Azure Container Registry サービス階層」を参照してください。
注意
Azure Kubernetes Service (AKS) にモデルをデプロイする場合は、そのクラスターで Azure Monitor を有効にすることをお勧めします。 これは、全体的なクラスターの正常性とリソースの使用状況を把握するのに役立ちます。 また、次のリソースも役立つ場合があります。
異常または過負荷のクラスターにモデルをデプロイしようとすると、問題が発生することが予想されます。 AKS クラスターでの問題のトラブルシューティングに関するヘルプが必要な場合は、AKS サポートにお問い合わせください。
リソースを削除する
適用対象:Azure CLI ml extension v1
# Get the current model id
import os
stream = os.popen(
'az ml model list --model-name=bidaf_onnx --latest --query "[0].id" -o tsv'
)
MODEL_ID = stream.read()[0:-1]
MODEL_IDaz ml service delete -n myservice
az ml service delete -n myaciservice
az ml model delete --model-id=<MODEL_ID>
デプロイされた Web サービスを削除するには、az ml service delete <name of webservice> を使用します。
ワークスペースから登録済みのモデルを削除するには、az ml model delete <model id> を使用します。
Web サービスの削除とモデルの削除に関する詳細を確認してください。