実稼働環境のモデルからデータを収集する

この記事では、Azure Kubernetes Service (AKS) クラスターにデプロイされた Azure Machine Learning モデルからデータを収集する方法について説明します。 収集したデータは、Azure Blob ストレージに格納されます。
収集を有効にすると、収集したデータで次のことができるようになります。
収集した実稼働データについてデータの誤差を監視する。
Power BI または Azure Databricksを使用して、収集したデータを分析する。
モデルの再トレーニングや最適化の時期をより適切に判断する。
収集したデータを使用してモデルを再トレーニングする。
制限事項
- モデル データ収集機能は、Ubuntu 18.04 イメージでのみ機能できます。
重要
2023 年 3 月 10 日の時点で、Ubuntu 18.04 イメージは非推奨になりました。 Ubuntu 18.04 イメージのサポートは、2023 年 4 月 30 日に EOL に達した 2023 年 1 月から削除されます。
MDC 機能は、Ubuntu 18.04 以外のどのイメージとも互換性はなく、Ubuntu 18.04 イメージが非推奨になった後は使用できません。
参照できるその他の情報:
注意
データ収集機能は現在プレビュー段階であり、どのプレビュー機能も運用環境のワークロードにはお勧めできません。
収集されるデータとその行き先
次のデータを収集できます。
AKS クラスターにデプロイされた Web サービスのモデル入力データ。 音声オーディオ、画像、および動画は、収集 "されません"。
実稼働環境入力データを使用したモデル予測
注意
このデータの事前集計および事前計算は、現時点では収集サービスの一部ではありません。
出力は BLOB ストレージに保存されます。 データは BLOB ストレージに追加されるため、分析の実行には任意のツールを選択できます。
出力データは、BLOB 内で次のような構文のパスに保存されます。
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv
# example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv
注意
バージョン 0.1.0a16 より前の Azure Machine Learning SDK for Python のバージョンでは、designation 引数が identifier という名前になっています。 以前のバージョンで開発したコードは、これに応じて更新する必要があります。
前提条件
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
Azure Machine Learning ワークスペース、スクリプトを保存するローカル ディレクトリ、および Azure Machine Learning SDK for Python をインストールする必要があります。 これらのインストール方法については、開発環境を構成する方法に関するページを参照してください。
AKS にデプロイするトレーニング済みの機械学習モデルが必要です。 モデルがない場合は、画像分類モデルのトレーニングに関するチュートリアルを参照してください。
AKS クラスターが必要です。 モデルを作成してデプロイする方法については、「機械学習モデルを Azure にデプロイする」を参照してください。
環境を設定し、Azure Machine Learning Monitoring SDK をインストールします。
Ubuntu 18.04 に基づく Docker イメージを使用します。これには、modeldatacollector の本質的な依存関係である
libssl 1.0.0が付属しています。 事前構築済みのイメージを参照できます。
データ収集を有効にする
データ収集は、Azure Machine Learning または他のツールを使用してデプロイするモデルに関係なく、有効にすることができます。
データ コレクションを有効にするには、次の操作を行う必要があります。
スコア付けファイルを開きます。
ファイルの先頭に次のコードを追加します。
from azureml.monitoring import ModelDataCollectorinit関数でデータ収集変数を宣言します。global inputs_dc, prediction_dc inputs_dc = ModelDataCollector("best_model", designation="inputs", feature_names=["feat1", "feat2", "feat3", "feat4", "feat5", "feat6"]) prediction_dc = ModelDataCollector("best_model", designation="predictions", feature_names=["prediction1", "prediction2"])CorrelationId は省略可能なパラメーターです。 モデルで必要ない場合は、使用する必要はありません。 CorrelationId を使用すると、LoanNumber、CustomerId などの他のデータとより簡単にマッピングできます。
Identifier パラメーターは、BLOB でフォルダー構造を構築するために後で使用します。 生データと処理済みデータの区別に使用できます。
run(input_df)関数に次のコード行を追加します。data = np.array(data) result = model.predict(data) inputs_dc.collect(data) #this call is saving our input data into Azure Blob prediction_dc.collect(result) #this call is saving our prediction data into Azure BlobAKS にサービスをデプロイしても、データ コレクションは自動的には true に設定 "されません"。 次の例のように、構成ファイルを更新してください。
aks_config = AksWebservice.deploy_configuration(collect_model_data=True)また、この構成を変更して、サービス監視のために Application Insights を有効にすることもできます。
aks_config = AksWebservice.deploy_configuration(collect_model_data=True, enable_app_insights=True)新しいイメージを作成し、機械学習モデルをデプロイするには、「機械学習モデルを Azure にデプロイする」を参照してください。
Web サービス環境の conda 依存関係に "Azure-Monitoring" pip パッケージを追加します。
env = Environment('webserviceenv')
env.python.conda_dependencies = CondaDependencies.create(conda_packages=['numpy'],pip_packages=['azureml-defaults','azureml-monitoring','inference-schema[numpy-support]'])
データ収集を無効にする
データ コレクションはいつでも停止できます。 Python コードを使用してデータ コレクションを無効にします。
## replace <service_name> with the name of the web service
<service_name>.update(collect_model_data=False)
データを検証して分析する
任意のツールを選択して、BLOB ストレージに収集されたデータを分析できます。
BLOB データにすばやくアクセスする
Azure ポータルにサインインします。
ワークスペースを開きます。
[ストレージ] を選択します。

次のような構文の、BLOB の出力データへのパスをたどります。
/modeldata/<subscriptionid>/<resourcegroup>/<workspace>/<webservice>/<model>/<version>/<designation>/<year>/<month>/<day>/data.csv # example: /modeldata/1a2b3c4d-5e6f-7g8h-9i10-j11k12l13m14/myresourcegrp/myWorkspace/aks-w-collv9/best_model/10/inputs/2018/12/31/data.csv

Power BI を使用してモデル データを分析する
Power BI Desktop をダウンロードして開きます。
[データを取得] を選択し、Azure Blob Storage を選択します。
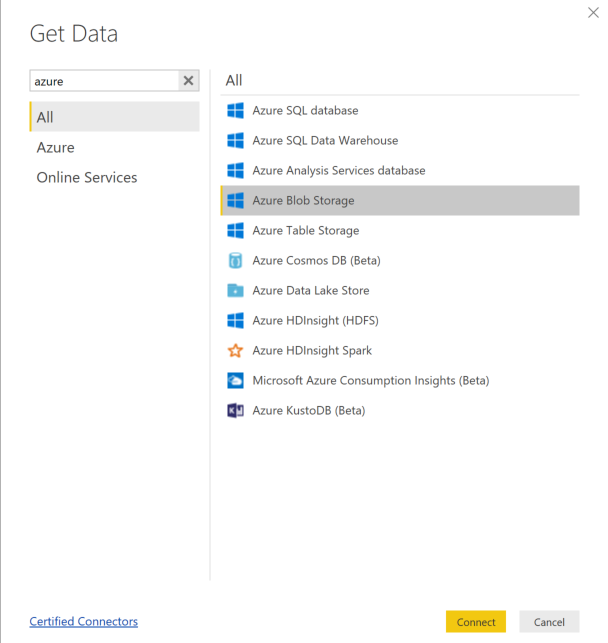
ストレージ アカウント名を追加し、ストレージ キーを入力します。 この情報は、BLOB で [設定]>[アクセス キー] の順に選択して確認できます。
[modeldata] コンテナーを選択し、 [編集] を選択します。
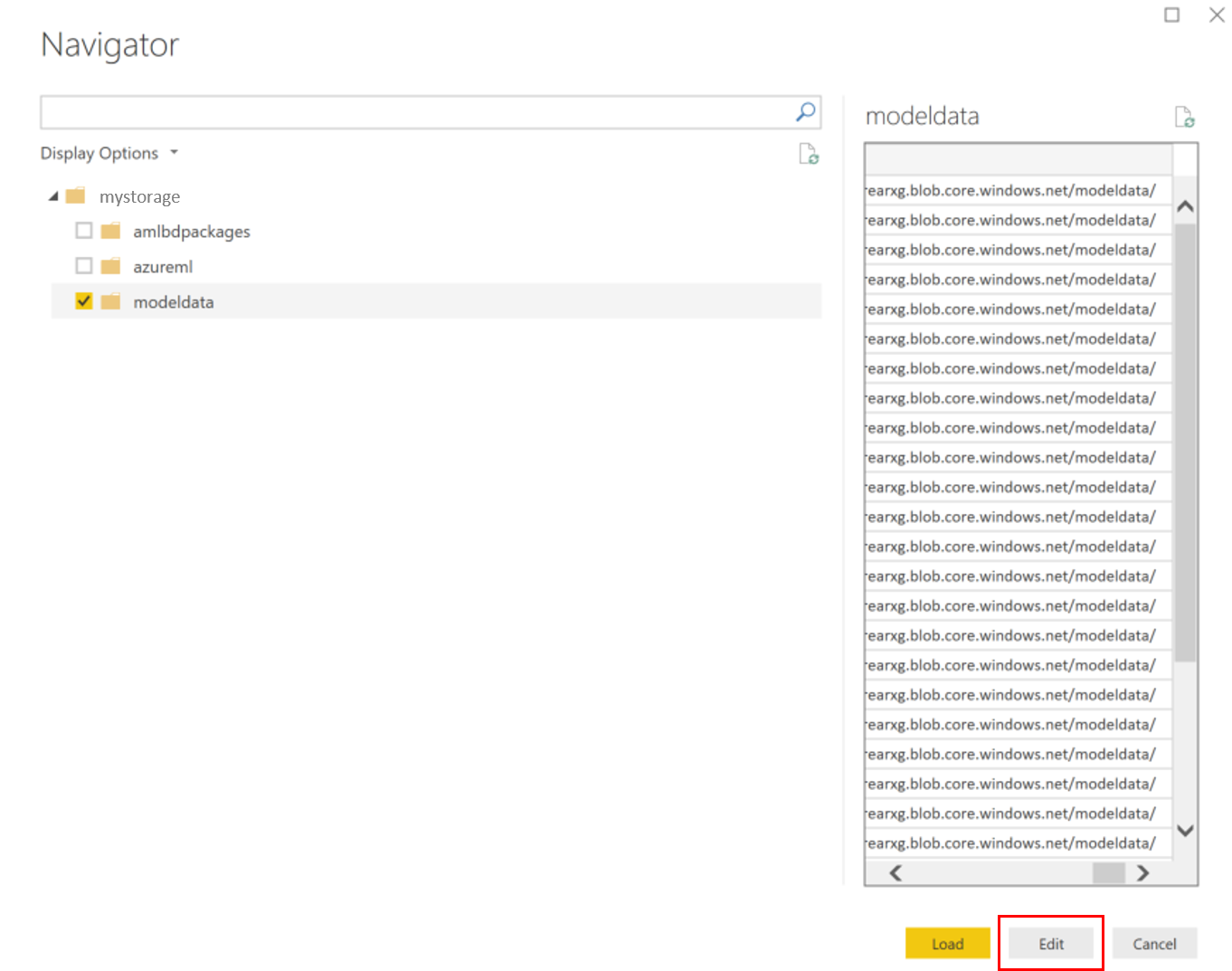
クエリ エディターで、 [名前] 列の下をクリックし、ストレージ アカウントを追加します。
モデルのパスをフィルターに入力します。 特定の年または月のファイルだけを検索する場合は、そのフィルター パスだけを展開します。 たとえば、3 月のデータのみを検索するには、次のフィルター パスを使用します。
/modeldata/<subscriptionid>/<resourcegroupname>/<workspacename>/<webservicename>/<modelname>/<modelversion>/<designation>/<year>/3
[名前] の値に基づいて、関連するデータをフィルター処理します。 予測と入力を格納した場合は、それぞれに対するクエリを作成する必要があります。
ファイルを結合するには、 [コンテンツ] の列見出しの横にある下向きの二重矢印を選択します。
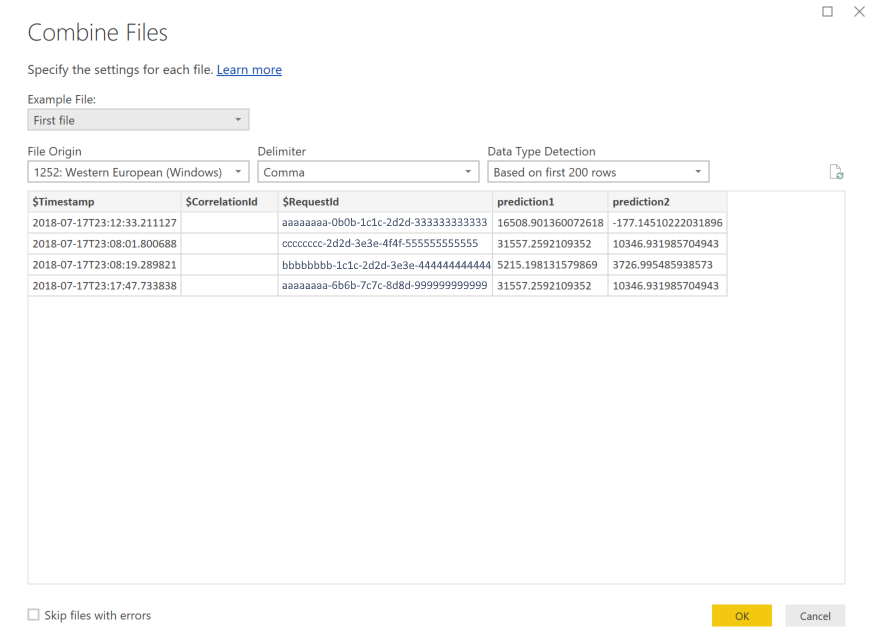
[OK] を選択します。 データがプリロードされます。
[Close and Apply](閉じて適用する) を選択します。
入力と予測を追加した場合、テーブルは RequestId の値によって自動的に並べ替えられます。
モデル データでのカスタム レポートの作成を開始します。




Azure Databricks を使用してモデル データを分析する
Azure Databricks ワークスペースを作成します。
Databricks ワークスペースに移動します。
Databricks ワークスペースで、 [データのアップロード] を選択します。
![Databricks の [データのアップロード] オプションの選択の様子を示すスクリーンショット。](media/how-to-enable-data-collection/databricks-upload.png?view=azureml-api-1)
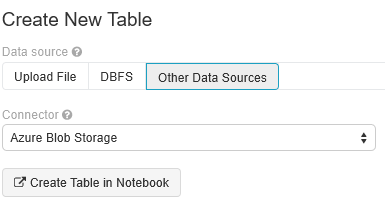
[新しいテーブルの作成] を選択し、 [他のデータ ソース]>[Azure Blob Storage]>[Create Table in Notebook](ノートブックにテーブルを作成) の順に選択します。
データの場所を更新します。 例を次に示します。
file_location = "wasbs://mycontainer@storageaccountname.blob.core.windows.net/*/*/data.csv" file_type = "csv"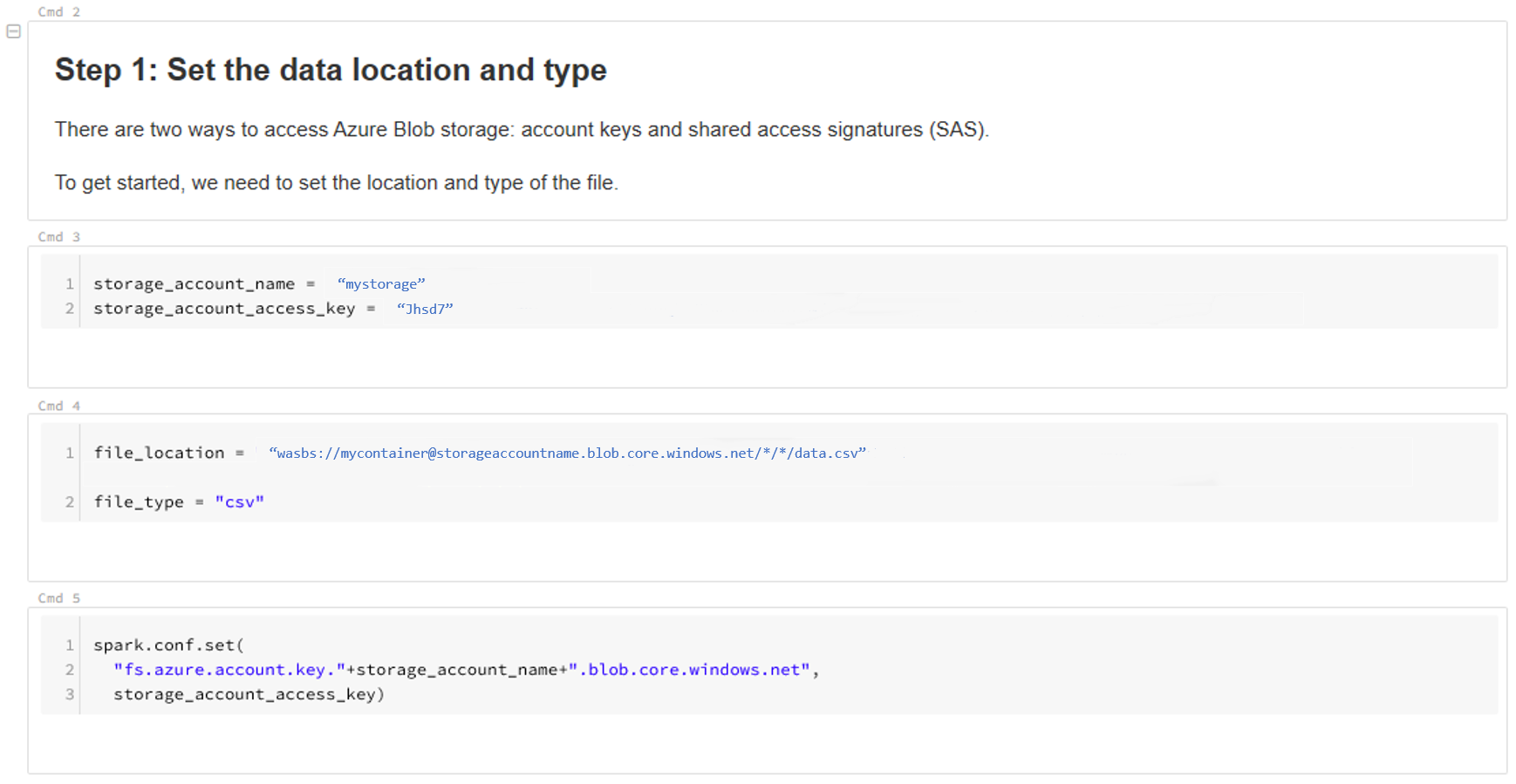
データを表示および分析するには、テンプレートの手順に従います。
![Databricks の [データのアップロード] オプションの選択の様子を示すスクリーンショット。](media/how-to-enable-data-collection/databricks-upload.png?view=azureml-api-1#lightbox)


次のステップ
収集したデータについてデータの誤差を検出します。