自動機械学習 (AutoML) とは
適用対象:  Python SDK azureml v1
Python SDK azureml v1
自動機械学習 (自動 ML または AutoML とも呼ばれます) は、時間のかかる反復的な機械学習モデルの開発タスクを自動化するプロセスです。 これにより、データ サイエンティスト、アナリスト、開発は、モデルの品質を維持しながら、高いスケール、効率性、生産性で ML モデルを構築することができます。 Azure Machine Learning の 自動 ML は、Microsoft Research 部門の最先端技術に基づいています。
機械学習モデルの従来の開発はリソース集約型であり、ドメインに関する広範な知識と多数のモデルを生成して比較するための大量の時間を必要とします。 自動機械学習を使用することで、すぐに実稼働環境で使用できる ML モデルを取得するための時間を、容易にかつ効率的に短縮することができます。
Azure Machine Learning で AutoML を使用する方法
Azure Machine Learning には、自動 ML を使用するための次の 2 つのエクスペリエンスが用意されています。 以降のセクションを参照して、各エクスペリエンスで利用可能な機能 (v1) について理解してください。
コードの経験がある場合: Azure Machine Learning Python SDK に関する記事。 「チュートリアル: 自動機械学習を使用してタクシー料金を予測する (v1)」を開始します。
コードの経験があまりない、またはない場合: Azure Machine Learning スタジオ (https://ml.azure.com)。 次のチュートリアルを開始します。
実験の設定
次の設定を使用して、自動 ML の実験を構成できます。
| Python SDK | Studio Web エクスペリエンス | |
|---|---|---|
| データをトレーニングおよび検証セットに分割する | ✓ | ✓ |
| ML タスクのサポート: 分類、回帰、予測 | ✓ | ✓ |
| Computer Vision タスクのサポート: 画像分類、物体検出、インスタンスのセグメント化 | ✓ | |
| プライマリ メトリックに基づいて最適化する | ✓ | ✓ |
| コンピューティング先として Azure Machine Learning コンピューティングをサポート | ✓ | ✓ |
| 予測期間、ターゲットのラグ、ローリング期間を構成する | ✓ | ✓ |
| 終了条件を設定する | ✓ | ✓ |
| コンカレント イテレーションを設定する | ✓ | ✓ |
| 列の削除 | ✓ | ✓ |
| ブロック アルゴリズム | ✓ | ✓ |
| クロス検証 | ✓ | ✓ |
| Azure Databricks クラスターでのトレーニングをサポートする | ✓ | |
| エンジニアリング機能の名前を表示する | ✓ | |
| 特徴付けの概要 | ✓ | |
| 休日の特徴付け | ✓ | |
| ログ ファイルの詳細度 | ✓ |
モデルの設定
これらの設定は、自動 ML 実験の結果として最適なモデルに適用できます。
| Python SDK | Studio Web エクスペリエンス | |
|---|---|---|
| 最適なモデルの登録、デプロイ、説明可能性 | ✓ | ✓ |
| 投票アンサンブルとスタック アンサンブル モデルを有効にする | ✓ | ✓ |
| プライマリ メトリック以外に基づいて最適なモデルを表示する | ✓ | |
| ONNX モデルの互換性を有効または無効にする | ✓ | |
| モデルのテスト | ✓ | ✓ (プレビュー) |
ジョブ制御の設定
これらの設定を使用すると、実験のジョブとその子ジョブを確認し、制御することができます。
| Python SDK | Studio Web エクスペリエンス | |
|---|---|---|
| ジョブの概要テーブル | ✓ | ✓ |
| ジョブおよび子ジョブを取り消す | ✓ | ✓ |
| ガードレールを取得する | ✓ | ✓ |
| ジョブを一時停止および再開する | ✓ |
AutoML を使用する場合: 分類、回帰、予測、Computer Vision と NLP
指定したターゲット メトリックを使用して自分の代わりに Azure Machine Learning にモデルのトレーニングと調整を行わせる場合は、自動 ML を適用します。 自動 ML を使うと、誰でも機械学習モデルの開発プロセスを使用でき、ユーザーはデータ サイエンスの専門知識に関係なく、どの問題についてもエンド ツー エンドの機械学習パイプラインを識別することができます。
さまざまな業界の ML プロフェッショナルと開発者は、自動化された ML を使用して次のことができます。
- 広範なプログラミング知識なしで ML ソリューションを実装する
- 時間とリソースを節約する
- データ サイエンスのベスト プラクティスを活用する
- アジャイルな問題解決を提供する
分類
分類は、一般的な機械学習タスクの 1 つです。 分類は、モデルでトレーニング データを使用して学習を行い、得られた知識を新しいデータに適用する、教師あり学習の一種です。 Azure Machine Learning には、これらのタスクに特化した特徴付けが用意されています (分類用のディープ ニューラル ネットワーク テキスト特徴抽出器など)。 「特徴付け (v1) のオプション」を参照してください。
分類モデルの主な目的は、トレーニング データから学習した知識に基づいて、新しいデータがどのカテゴリに分類されるかを予測することです。 一般的な分類の例には、不正行為の検出、手書き認識、オブジェクトの検出などがあります。 詳細と例については、自動 ML を使用した分類モデルの作成 (v1) に関するページを参照してください。
分類と自動機械学習の例については、次の Python ノートブックを参照してください: 不正行為の検出、マーケティング予測、ニュースグループ データの分類
回帰
分類と同様に、回帰タスクも一般的な教師あり学習の 1 つです。
予測される出力値がカテゴリである分類とは異なり、回帰モデルでは、独立した予測子に基づいて数値の出力値が予測されます。 回帰の目的は、1 つの変数が他の変数にどのように影響するかを推定することによって、独立した予測変数間の関係を確立することです。 たとえば、自動車の価格は、燃費効率や安全性の評価などの特徴に基づいています。 自動機械学習を使用した回帰 (v1) に関する記事で、詳細と例を確認してください。
予測のための回帰と自動機械学習の例については、次の Python ノートブックを参照してください: CPU パフォーマンスの予測。
時系列予測
予測を行うことは、収益、在庫、販売、顧客需要にかかわらず、あらゆるビジネスに不可欠です。 自動化された ML を使用してテクニックとアプローチを組み合わせて、推奨される高品質な時系列予測を得ることができます。 詳細については、時系列予測のための自動機械学習 (v1) に関する記事を参照してください。
自動化された時系列の実験は、多変量回帰問題として扱われます。 過去の時系列値は "ピボット" されて、他の予測因子とともにリグレッサーの追加ディメンションとなります。 このアプローチには、従来の時系列手法と異なり、トレーニング中に複数のコンテキスト変数とその関係を自然に取り込めるという利点があります。 自動 ML では、データセットと予測期間内のすべての項目について、単一ではあるがしばしば内部的に分岐するモデルが学習されます。 したがって、モデルのパラメーターを見積もるために多くのデータを使用でき、目に見えない系列の一般化が可能になります。
高度な予測構成には次のものが含まれます。
- 休日の検出と特性付け
- 時系列と DNN 学習 (自動 ARIMA、Prophet、ForecastTCN)
- グループ化による多くのモデルのサポート
- ローリング オリジン クロス検証
- 構成可能なラグ
- ローリング ウィンドウの集計機能
予測を行うための回帰と自動機械学習の例については、Python ノートブック (売上予測、需要予測、 GitHub の毎日のアクティブユーザーの予測) をご覧ください。
Computer Vision
Computer Vision タスクのサポートにより、画像分類や物体検出などのシナリオで、画像データでトレーニングされたモデルを簡単に生成できます。
この機能を使用して、次のことができます。
- Azure Machine Learning のデータのラベル付け機能とシームレスに統合する
- ラベル付けされたデータを使用して画像モデルを生成する
- モデル アルゴリズムを指定し、ハイパーパラメーターを調整することで、モデルのパフォーマンスを最適化します。
- 結果のモデルを Web サービスとして Azure Machine Learning でダウンロードまたはデプロイします。
- Azure Machine Learning の MLOps と ML パイプライン (v1) の機能を活用して、大規模に運用できるようにします。
ビジョン タスク用の AutoML モデルの作成は、Azure Machine Learning Python SDK を介してサポートされます。 結果として得られる実験ジョブ、モデル、出力には、Azure Machine Learning スタジオ UI からアクセスできます。
Computer Vision モデルの AutoML トレーニングを設定する方法を確認してください。

画像の自動 ML では、次の Computer Vision タスクがサポートされます。
| タスク | 説明 |
|---|---|
| 複数クラスの画像分類 | クラスのセットから 1 つのラベルのみに画像が分類されるタスク (例: 各画像は、"猫" または "犬" または "アヒル" の画像として分類されます) |
| 複数ラベルの画像分類 | ラベルのセットから 1 つまたは複数のラベルが画像に適用される可能性のあるタスク (例: 1 つの画像に "猫" と "犬" の両方がラベル付けされる可能性があります) |
| オブジェクトの検出 | 画像内の物体を識別し、境界ボックスを使用して各物体を特定するタスク (例: 画像内のすべての犬と猫を見つけ、それぞれの周囲に境界ボックスを描画します)。 |
| インスタンスのセグメント化 | 画像内の物体をピクセル レベルで識別し、画像の各物体の周囲にポリゴンを描画するタスク。 |
自然言語処理: NLP
自動 ML で自然言語処理 (NLP) タスクをサポートすることで、テキストデータに対してトレーニングされたモデルを簡単に生成し、テキスト分類と名前付きエンティティの認識シナリオを実現できます。 自動 ML トレーニング済み NLP モデルの作成は、Azure Machine Learning Python SDK を通じてサポートされています。 結果として得られる実験ジョブ、モデル、出力には、Azure Machine Learning スタジオ UI からアクセスできます。
NLP 機能は次をサポートします。
- 最新のトレーニング済み BERT モデルを使用したエンドツーエンドのディープニューラルネットワーク NLP トレーニング
- Azure Machine Learning データラベルとのシームレスな統合
- ラベル付けされたデータを使用して画像モデルを生成する
- 104 の言語による多言語サポート
- Horovod を使用した分散トレーニング
NLP モデルの AutoML トレーニングを設定 (v1) する方法について説明します。
自動 ML の動作
トレーニング中、Azure Machine Learning は、さまざまなアルゴリズムとパラメーターを試行する多数のパイプラインを並列に作成します。 サービスは、機能選択と組み合わせた ML アルゴリズムを介して反復し、それぞれの反復で、トレーニング スコアを含むモデルを生成します。 このスコアが高いほど、モデルがデータに「適合している」と見なされます。 実験に定義されている終了基準に到達すると停止します。
Azure Machine Learning を利用するとき、次の手順で自動 ML トレーニング実験を設計し、実験できます。
解決すべき ML 問題を特定します。分類、予測、回帰、または Computer Vision。
Python SDK と Studio Web エクスペリエンスのどちらを使用するかを選択します。Python SDK と Studio Web エクスペリエンスの同等性を確認してください。
- コードの経験があまりない、またはない場合は、Azure Machine Learning Studio Web エクスペリエンスを https://ml.azure.com で試してください
- Python 開発者は、Azure Machine Learning Python SDK (v1) に関するページを参照してください
ラベルの付いたトレーニング データのソースとフォーマットを指定します。Numpy 配列または Pandas データフレーム
ローカル コンピューター、Azure Machine Learning コンピューティング、リモート VM、Azure Databricks と SDK v1 など、モデル トレーニングのためのコンピューティング先を構成します。
さまざまなモデルでの繰り返しの回数、ハイパーパラメーター設定、前処理/特徴付けの詳細、最良のモデルを決定するときに考慮されるメトリックを決定する自動化された機械学習のパラメーターを構成します。
トレーニング ジョブを送信します。
結果を確認します
このプロセスを説明する図を次に示します。
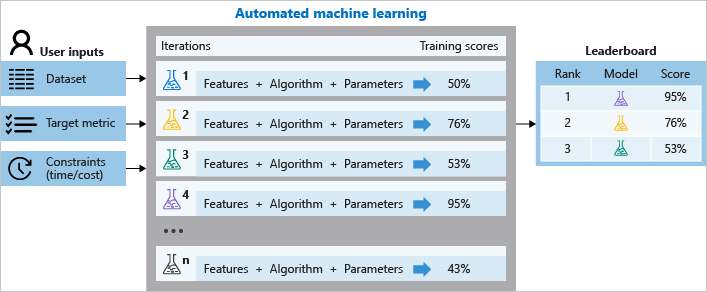
ログに記録されたジョブ情報を調べることもできます。これには、ジョブ中に収集したメトリックが含まれています。 トレーニング ジョブでは、モデルおよびデータ前処理を含む Python シリアル化オブジェクト (.pkl ファイル) が生成されます。
モデルの構築は自動ですが、生成されたモデルにとって特徴がどれだけ重要であるか、または関連性があるかを学ぶこともできます。
ローカルおよびリモートで管理されている ML のコンピューティング先に関するガイダンス
自動 ML 用の Web インターフェイスでは、常にリモートのコンピューティング先が使用されます。 ただし、Python SDK を使用する場合は、自動 ML のトレーニング用にローカルのコンピューティング先またはリモートのコンピューティング先のどちらかを選択します。
- ローカル コンピューティング:ローカルのノート PC または VM のコンピューティング上でトレーニングが行われます。
- リモート コンピューティング:Machine Learning コンピューティング クラスター上でトレーニングが行われます。
コンピューティング先の選択
使用するコンピューティング先を選択するときに、次の要素を考慮してください。
- ローカル コンピューティングを選択する: 小規模のデータと短いトレーニング (つまり、子ジョブあたり数秒または数分) を使用する、初期探索またはデモのためのシナリオの場合は、ローカル コンピューター上でのトレーニングが適している場合があります。 セットアップ時間はかからず、インフラストラクチャ リソース (お使いの PC または VM) を直接使用できます。
- リモート ML コンピューティング クラスターを選択する:より長いトレーニングが必要なモデルを作成する運用環境でのトレーニングのように、より大きなデータセットを使用してトレーニングを行う場合、リモート コンピューティングを選択するとエンド ツー エンドの時間のパフォーマンスが大幅に向上します。
AutoMLによってクラスターのノード間でトレーニングが並列化されるためです。 リモート コンピューティングでは、内部インフラストラクチャの起動時間によって子ジョブあたり約 1.5 分が加算され、VM がまだ稼働していない場合はクラスター インフラストラクチャ用にさらに数分がかかります。
長所と短所
ローカルとリモートのどちらを使用するかを選択する場合は、以下の長所と短所を考慮してください。
| 長所 (利点) | 短所 (欠点) | |
|---|---|---|
| ローカル コンピューティング先 | ||
| リモート ML コンピューティング クラスター |
使用可能な機能
次の表に示すように、リモート コンピューティングを使用するとより多くの機能を使用できます。
| 機能 | Remote | ローカル |
|---|---|---|
| データ ストリーミング (大規模なデータのサポート、最大 100 GB) | ✓ | |
| DNN-BERT ベースのテキストの特徴量化とトレーニング | ✓ | |
| すぐに使用できる GPU サポート (トレーニングと推論) | ✓ | |
| 画像の分類とラベル付けのサポート | ✓ | |
| 予測のための自動 ARIMA、Prophet、および ForecastTCN モデル | ✓ | |
| 並列での複数のジョブ/反復 | ✓ | |
| AutoML スタジオ Web エクスペリエンス UI で解釈可能なモデルを作成する | ✓ | |
| スタジオ Web エクスペリエンス UI での特徴エンジニアリングのカスタマイズ | ✓ | |
| Azure Machine Learning ハイパーパラメーターのチューニング | ✓ | |
| Azure Machine Learning パイプライン ワークフローのサポート | ✓ | |
| ジョブを続行する | ✓ | |
| 予測 | ✓ | ✓ |
| ノートブックで実験を作成して実行する | ✓ | ✓ |
| UI で実験の情報とメトリックを登録して視覚化する | ✓ | ✓ |
| データ ガードレール | ✓ | ✓ |
トレーニング、検証、テストのデータ
自動 ML では、トレーニング データを与えて ML モデルをトレーニングします。実行するモデル検証の種類を指定できます。 自動 ML では、トレーニングの一環としてモデルが検証されます。 つまり、自動 ML では検証データを利用し、適用されているアルゴリズムに基づき、モデルのハイパーパラメーターを調整し、トレーニング データに最適な組み合わせを見つけます。 ただし、調整が繰り返されるとき、同じ検証データが使用され、モデルの評価が偏ります。これは、モデルは向上を継続するものであり、検証データに合わせるためです。
このような偏りが最終的な推奨モデルに適用されないように、自動 ML ではテスト データを利用し、自動 ML から実験の最後に推奨される最終モデルが評価されます。 自動 ML 実験の構成でテスト データを与えるとき、実験の最後に既定でこの推奨モデルがテストされます (プレビュー)。
重要
生成されたモデルを評価するためにテスト データセットを使ってモデルをテストする機能はプレビュー段階です。 この機能は試験段階のプレビュー機能であり、随時変更される可能性があります。
SDK (v1) または Azure Machine Learning スタジオを利用し、テスト データを使用するように AutoML 実験を構成する (プレビュー) 方法を確認してください。
独自のテスト データを与えるか、トレーニング データの一部を取っておくことで、子ジョブのモデルなどの既存の自動 ML モデルをテストすることもできます (プレビュー) (v1)。
機能エンジニアリング
特徴エンジニアリングは、データに関するドメインの知識を活用して、ML アルゴリズムの学習を支援する機能を作成するプロセスです。 Azure Machine Learning では、特徴エンジニアリングを容易にするために、スケーリングと正規化の手法が適用されます。 これらの手法と特徴エンジニアリングは、まとめて "特徴量化" と呼ばれます。
自動機械学習の実験において、特徴量化は自動的に適用されますが、データに基づいてカスタマイズすることもできます。 特徴量化の内容 (v1) と、AutoML がいかにしてモデルのオーバーフィットと不均衡データを回避するかについて学習してください。
注意
自動化された機械学習の特徴付け手順 (機能の正規化、欠損データの処理、テキストから数値への変換など) は、基になるモデルの一部になります。 このモデルを予測に使用する場合、トレーニング中に適用されたのと同じ特徴付けの手順がご自分の入力データに自動的に適用されます。
特徴量化のカスタマイズ
その他の特徴エンジニアリング手法 (エンコードや変換など) も使用できます。
この設定は次の方法で有効にできます。
Azure Machine Learning Studio: これらの (v1) 手順に従って、[View additional configuration](追加構成の表示) セクションで [Automatic featurization](自動特性付け) を有効にします。
Python SDK:AutoMLConfig オブジェクトで
"feauturization": 'auto' / 'off' / 'FeaturizationConfig'を指定します。 特性付けを有効にする (v1) 方法に関する詳細を参照してください。
アンサンブル モデル
自動機械学習では、既定で有効になっているアンサンブル モデルがサポートされています。 アンサンブル学習では、1 つのモデルを使用するのではなく、複数のモデルを組み合わせることによって、機械学習の結果と予測パフォーマンスが改善されます。 アンサンブル イテレーションは、ジョブの最終イテレーションとして表示されます。 自動機械学習では、モデルの結合に投票とスタッキングの両方のアンサンブル方法を使用します。
- 投票: 予測されたクラス確率 (分類タスクの場合) または予測された回帰ターゲット (回帰タスクの場合) の加重平均に基づいて予測します。
- スタッキング: スタッキングは異種のモデルを結合し、個々のモデルの出力に基づいてメタモデルをトレーニングします。 現在の既定のメタモデルは、分類タスクの場合は LogisticRegression、回帰/予測タスクの場合は ElasticNet です。
初期アンサンブルが並べ替えられた Caruana のアンサンブル選択アルゴリズムを使用して、アンサンブル内で使用するモデルを決定します。 大まかに言えば、このアルゴリズムでは、最適な個別スコアを持つ最大 5 つのモデルを使用してアンサンブルを初期化し、これらのモデルが最適なスコアの 5% のしきい値内にあることを確認して、不適切な初期アンサンブルを回避します。 その後、各アンサンブルの繰り返しに対して、新しいモデルが既存のエンティティに追加され、結果のスコアが計算されます。 新しいモデルによって既存のアンサンブル スコアが向上した場合、アンサンブルはその新しいモデルを含むように変更されます。
自動化された機械学習の既定のアンサンブル設定を変更する方法については、ハウツー (v1) を参照してください。
AutoML & ONNX
Azure Machine Learning では、自動化された ML を使用して Python モデルを構築し、それを ONNX 形式に変換できます。 ONNX 形式になったモデルは、さまざまなプラットフォームやデバイスで実行することができます。 ONNX での ML モデルの能率化に関する詳細をご覧ください。
ONNX 形式に変換する方法については、この Jupyter ノートブックの例を参照してください。 ONNX でサポートされているアルゴリズム (v1) についてご確認ください。
ONNX ランタイムは C# にも対応しています。そのため、コードを書き直す必要がなく、また、REST エンドポイントで発生するネットワークの遅延なく、C# アプリで自動的に構築されたモデルを使用できます。 ML.NET を使用する .NET アプリケーションでの AutoML ONNX モデルの使用と ONNX ランタイム C# API を使用した ONNX モデルの推論に関するページを参照してください。
次のステップ
AutoML の使用を開始する方法がわかるリソースが複数あります。
チュートリアルと方法
チュートリアルでは、AutoML シナリオのサンプルを端から端まで紹介します。
コード ファースト エクスペリエンスについては、「チュートリアル: AutoML と Python を使用して回帰モデルをトレーニングする (v1)」に従ってください。
わずかなコードまたはコードなしのエクスペリエンスについては、「チュートリアル: Azure Machine Learning スタジオでコードなし AutoML を使用して分類モデルをトレーニングする」を参照してください。
AutoML を使用した Computer Vision モデルのトレーニングについては、「チュートリアル: AutoML と Python を使用して物体検出モデルをトレーニングする (v1)」を参照してください。
操作方法の記事では、自動 ML が提供する機能について詳しく説明しています。 たとえば、次のように入力します。
自動トレーニング実験の設定を構成してください
時系列データを使用して予測モデルをトレーニングする (v1) 方法について学習します。
Python を使用して Computer Vision モデルをトレーニングする (v1) 方法について学習します。
自動 ML モデルからの生成コードを表示する方法について説明します。
Jupyter Notebook のサンプル
GitHub の自動機械学習サンプルのノートブック リポジトリで詳しいコード サンプルやユース ケースを確認してください。
Python SDK リファレンス
AutoML クラス リファレンス ドキュメントでは、SDK デザイン パターンとクラス仕様の知識を深めることができます。
注意
自動機械学習機能は、ML.NET、HDInsight、Power BI、SQL Server などの他の Microsoft ソリューションでも使用できます