Python (SDKv1) で時系列予測モデルをトレーニングするために AutoML を設定する
適用対象:  Python SDK azureml v1
Python SDK azureml v1
この記事では、Azure Machine Learning Python SDK で、Azure Machine Learning 自動 ML を使用して時系列予測モデルをトレーニングするために、AutoML を設定する方法を説明します。
これを行うには、次の手順を実行します。
- 時系列モデリング用のデータを準備します。
AutoMLConfigオブジェクトで特定の時系列パラメーターを構成します。- 時系列データで予測を実行します。
Azure Machine Learning スタジオの自動 ML を使用して、ロー コードで時系列予測を行う例は、「チュートリアル:自動機械学習を使用して需要を予測する」をご覧ください。
従来の時系列メソッドとは異なり、自動 ML では過去の時系列値が "ピボット" され、他の予測子と共にリグレッサーの追加のディメンションになります。 このアプローチでは、トレーニング中に複数のコンテキスト変数とそれらの相互関係を組み込みます。 複数の要因が予測に影響を与える可能性があるため、この方法は実際の予測シナリオに適しています。 たとえば、売上の予測では、履歴による傾向とのインタラクション、為替レート、および価格のすべてが、売上の結果に貢献します。
前提条件
この記事では、以下が必要です。
Azure Machine Learning ワークスペース。 ワークスペースを作成するには、「ワークスペース リソースの作成」を参照してください。
この記事では、自動化された機械学習実験の設定にある程度精通していることを前提としています。 方法に従って、自動化された機械学習実験の主要な設計パターンについて確認してください。
重要
この記事の Python コマンドでは、最新の
azureml-train-automlパッケージ バージョンが必要です。- 最新の
azureml-train-automlパッケージをローカル環境にインストールします。 - 最新の
azureml-train-automlパッケージの詳細については、リリース ノートを参照してください。
- 最新の
データをトレーニングして検証する
自動 ML 内の予測回帰タスク型と回帰タスク型の最大の違いは、有効な時系列を表す特徴量がトレーニング データに含まれているかどうかです。 通常の時系列には、明確に定義され一貫した頻度があり、連続した期間のすべてのサンプル ポイントで値があります。
重要
将来の値を予測するためにモデルをトレーニングするときは、目的のトレーニングで使用されるすべての機能が、意図した期間の予測を実行するときに使用できることを確認してください。 たとえば、需要の予測を作成するときに、現在の株価の機能を含めれば、トレーニングの精度を大幅に高めることができます。 ただし、長期間にわたり予測する予定の場合、将来の時系列ポイントに応じた将来の株価を正確に予測できない可能性があり、モデルの精度が低下することがあります。
AutoMLConfig オブジェクトには、個別のトレーニング データと検証データを直接指定できます。 AutoMLConfig の詳細について参照してください。
時系列の予測の場合、既定では、ローリング オリジン クロス検証 (ROCV) のみが検証に使用されます。 ROCV を使用すると、起点の時点を使用して系列をトレーニング データと検証データに分割することができます。 時間内の原点をスライドすると、クロス検証のフォールドが生成されます。 この戦略を使用すると、時系列データの整合性を維持し、データ漏えいのリスクを排除できます。
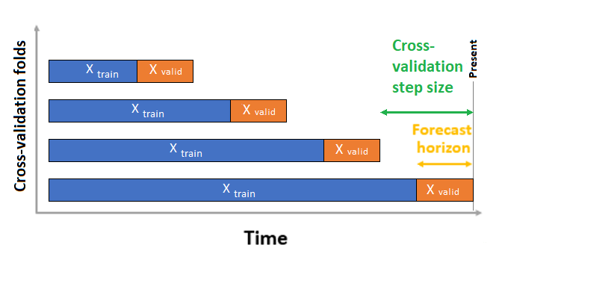
トレーニング データと検証データを 1 つのデータセットとしてパラメーター training_data に渡します。 パラメーター n_cross_validations でクロス検証フォールドの数を設定し、2 つの連続するクロス検証フォールドの間の期間の数を cv_step_size で設定します。 いずれかまたは両方のパラメーターを空のままにすることもでき、AutoML によって自動的に設定されます。
適用対象: Python SDK azureml v1
automl_config = AutoMLConfig(task='forecasting',
training_data= training_data,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
...
**time_series_settings)
また、独自の検証データを取り込むこともできます。詳細については、AutoML でのデータの分割とクロス検証の構成に関する記事を参照してください。
AutoML でクロス検証を適用してモデルのオーバーフィットを防止する方法について、詳細情報をご覧ください。
実験を構成する
AutoMLConfig オブジェクトは、自動化された機械学習タスクに必要な設定とデータを定義します。 予測モデルの構成は、標準の回帰モデルの設定に似ていますが、特定のモデル、構成オプション、および特徴量化の手順は時系列データ専用です。
サポートされているモデル
自動機械学習では、モデル作成とチューニング プロセスの一環として、さまざまなモデルとアルゴリズムが自動的に試行されます。 ユーザーは、アルゴリズムを指定する必要はありません。 予測実行では、ネイティブな時系列とディープ ラーニングのモデルはどちらも、レコメンデーション システムの一部です。
ヒント
従来の回帰モデルも、予測実験のレコメンデーション システムの一部としてテストされます。 サポートされているモデルの完全な一覧については、SDK リファレンス ドキュメントを参照してください。
構成設定
回帰の問題と同様に、タスクの種類、イテレーションの数、トレーニング データ、クロス検証の数など、標準的なトレーニング パラメーターを定義します。 予測タスクでは、実験を構成するために time_column_name パラメーターと forecast_horizon パラメーターが必要です。 データに複数の時系列が含まれている場合 (複数の店舗の売上データやさまざまな州のエネルギー データなど)、自動 ML によって自動的に検出され、time_series_id_column_names パラメーター (プレビュー) が設定されます。 実行の構成を向上させるために追加のパラメーターを含めることもできます。含められるものの詳細については、オプションの構成に関するセクションを参照してください。
重要
時系列の自動識別は、現在パブリック プレビュー中です。 このプレビュー バージョンは、サービス レベル アグリーメントなしに提供されます。 特定の機能はサポート対象ではなく、機能が制限されることがあります。 詳しくは、Microsoft Azure プレビューの追加使用条件に関するページをご覧ください。
| パラメーター名 | 説明 |
|---|---|
time_column_name |
時系列の構築とその頻度の推定に使用される入力データで、datetime 列を指定するために使用されます。 |
forecast_horizon |
予測する今後の期間の数を定義します。 horizon とは、時系列頻度の単位です。 単位は、月ごとや週ごとなどの予測を実行する必要があるトレーニング データの時間間隔に基づきます。 |
次のコードによって、以下の処理が実行されます。
ForecastingParametersクラスを使用して、実験トレーニング用の予測パラメーターを定義しますtime_column_nameをデータ セットのday_datetimeフィールドに設定します。- テスト セット全体を予測するために、
forecast_horizonを 50 に設定します。
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecasting_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
freq='W')
これらの forecasting_parameters は、forecasting のタスクの種類、プライマリ メトリック、終了基準、トレーニング データと共に、標準の AutoMLConfig オブジェクトに渡されます。
from azureml.core.workspace import Workspace
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
import logging
automl_config = AutoMLConfig(task='forecasting',
primary_metric='normalized_root_mean_squared_error',
experiment_timeout_minutes=15,
enable_early_stopping=True,
training_data=train_data,
label_column_name=label,
n_cross_validations="auto", # Could be customized as an integer
cv_step_size = "auto", # Could be customized as an integer
enable_ensembling=False,
verbosity=logging.INFO,
forecasting_parameters=forecasting_parameters)
自動 ML で予測モデルを正常にトレーニングするために必要なデータ量は、AutoMLConfig の構成時に指定した forecast_horizon、n_cross_validations、および target_lags または target_rolling_window_size の値の影響を受けます。
次の式では、時系列機能を構築するために必要な履歴データ量が計算されます。
必要な最小履歴データ: (2 x forecast_horizon) + #n_cross_validations + max (max (target_lags), target_rolling_window_size)
指定された関連する設定に必要な履歴データ量が満たされていないデータセット内では、すべての系列に対して Error exception が発生します。
特徴量化の手順
自動機械学習におけるあらゆる実験では、自動スケーリングと正規化の手法が既定でデータに適用されます。 これらの手法は、さまざまなスケールの特徴に反応する "特定" のアルゴリズムを支援する特徴量化の一種です。 既定の特徴量化の手順の詳細については、AutoML での特徴量化に関するページを参照してください。
ただし、次の手順は forecasting のタスクの種類に対してのみ実行されます。
- 時系列のサンプル頻度 (たとえば、1 時間ごと、毎日、毎週) を検出し、存在しない時間ポイントについて新しいレコードを作成して時系列を連続にします。
- ターゲット列 (前方フィルにより) および機能列 (メジアン列値を使用) の欠損値を補完します
- さまざまな系列で一定の効果を可能にする時系列識別子に基づく機能を作成します
- 季節のパターンの学習に役立つ時間ベースの機能を作成します
- カテゴリ変数を数量にエンコードします
- 非定常時系列を検出し、それらを自動的に差分して、ユニット ルートの影響を軽減します。
時系列データから生成される、エンジニアリングされた機能の一覧については、「TimeIndexFeaturizer クラス」を参照してください。
注意
自動化された機械学習の特徴付け手順 (機能の正規化、欠損データの処理、テキストから数値への変換など) は、基になるモデルの一部になります。 このモデルを予測に使用する場合、トレーニング中に適用されたのと同じ特徴付けの手順がご自分の入力データに自動的に適用されます。
特徴量化のカスタマイズ
ML モデルのトレーニングに使用されたデータと特徴から確実に適切な予測が得られるよう、特徴量化の設定をカスタマイズすることもできます。
forecasting タスクでサポートされるカスタマイズは次のとおりです。
| カスタマイズ | 定義 |
|---|---|
| 列の目的の更新 | 指定した列の自動検出された特徴の種類をオーバーライドします。 |
| トランスフォーマー パラメーターの更新 | 指定したトランスフォーマーのパラメーターを更新します。 現在は、Imputer (fill_value および median) がサポートされています。 |
| 列の削除 | 特徴量化から削除する列を指定します。 |
SDK を使用して特徴量化をカスタマイズするには、AutoMLConfig オブジェクト内で "featurization": FeaturizationConfig を指定します。 カスタムの特徴量化について、詳細情報をご覧ください。
Note
列の削除機能は、SDK バージョン 1.19 以降は非推奨となっています。 自動 ML 実験で使用する前に、データ クレンジングの一環としてデータセットから列を削除します。
featurization_config = FeaturizationConfig()
# `logQuantity` is a leaky feature, so we remove it.
featurization_config.drop_columns = ['logQuantitity']
# Force the CPWVOL5 feature to be of numeric type.
featurization_config.add_column_purpose('CPWVOL5', 'Numeric')
# Fill missing values in the target column, Quantity, with zeroes.
featurization_config.add_transformer_params('Imputer', ['Quantity'], {"strategy": "constant", "fill_value": 0})
# Fill mising values in the `INCOME` column with median value.
featurization_config.add_transformer_params('Imputer', ['INCOME'], {"strategy": "median"})
Azure Machine Learning Studio を実験に使用している場合は、Studio で特徴量化をカスタマイズする方法に関する記事を参照してください。
オプションの構成
ディープ ラーニングの有効化やターゲットのローリング ウィンドウ集計の指定など、予測タスクに対して他のオプションの構成を使用できます。 その他のパラメーターの完全な一覧については、ForecastingParameters SDK リファレンス ドキュメントを参照してください。
頻度とターゲット データの集計
頻度 (freq) パラメーターを使用して、不規則なデータによる障害が発生しないようにします。 不規則なデータには、毎時や毎日のデータなど、一定の周期に従わないデータが含まれます。
非常に不規則なデータやさまざまなビジネス ニーズに対しては、ユーザーは必要に応じて目的の予測頻度 freq を設定し、target_aggregation_function を指定して時系列のターゲット列を集計することができます。 AutoMLConfig オブジェクトでこれらの 2 つの設定を使用すると、データの準備にかかる時間を節約するのに役立ちます。
ターゲット列の値に対してサポートされている集計操作は次のとおりです。
| 機能 | 説明 |
|---|---|
sum |
ターゲット値の合計 |
mean |
ターゲット値の中数または平均 |
min |
ターゲットの最小値 |
max |
ターゲットの最大値 |
ディープ ラーニングを有効にする
注意
自動機械学習での予測のための DNN サポートはプレビュー段階です。ローカルでは実行できず、Databricks で開始して実行することもできません。
深層ニューラル ネットワーク (DNN) を使用したディープ ラーニングを利用し、モデルのスコアを向上させることもできます。 自動 ML のディープ ラーニングを使用すると、一変量および多変量の時系列データを予測できます。
ディープ ラーニング モデルには、3 つの組み込み機能があります。
- 入力から出力への任意のマッピングから学習できる
- 複数の入力と出力をサポートする
- 長いシーケンスにまたがる入力データのパターンを自動的に抽出できる
ディープ ラーニングを有効にするには、AutoMLConfig オブジェクトの enable_dnn=True を設定します。
automl_config = AutoMLConfig(task='forecasting',
enable_dnn=True,
...
forecasting_parameters=forecasting_parameters)
警告
SDK を使用して作成された実験に対して DNN を有効にすると、最適なモデル説明が無効になります。
Azure Machine Learning スタジオで作成された AutoML 実験用の DNN を有効にするには、Studio UI 入門にあるタスクの種類の設定に関するページを参照してください。
ターゲットのローリング ウィンドウ集計
多くの場合、予測器にとって最高の情報はターゲットの最近の値です。 ターゲットのローリング ウィンドウ集計を使用すると、データ値のローリング集計を特徴として追加できます。 これらの特徴を追加のコンテキスト データとして生成および使用すると、トレーニング モデルの精度が向上します。
たとえば、エネルギー需要を予測するとします。 3 日間のローリング ウィンドウの特徴を追加して、暖房が入っている空間の熱変化を考慮することもできます。 この例では、AutoMLConfig コンストラクターで target_rolling_window_size= 3 を設定して、このウィンドウを作成します。
この表は、ウィンドウ集計が適用されたときに発生する特徴エンジニアリングを示しています。 最小値、最大値、合計値の列は、定義された設定に基づいて、3 のスライディング ウィンドウで生成されます。 各行には新しい計算済みの特徴があります。2017 年 9 月 8 日の午前 4:00 のタイムスタンプの場合、最大値、最小値、合計値は、2017 年 9 月 8 日午前 1:00 から午前 3:00 までの需要値を使用して計算されます。 この 3 のウィンドウは、残りの行のデータを設定するためにシフトされます。

ターゲットのローリング ウィンドウ集計の特徴を利用した Python コードの例を参照してください。
短い系列の処理
自動 ML では、モデル開発のトレーニングと検証のフェーズを実施するのに十分なデータ ポイントがない場合、時系列は短い系列と見なされます。 データ ポイントの数は実験ごとに異なり、max_horizon、クロス検証の分割の数、モデルのルックバックの長さ (時系列の特徴を構成するために必要な最大の履歴) に依存します。
自動 ML は、既定では ForecastingParameters オブジェクトの short_series_handling_configuration パラメーターを使用して、短い系列の処理を提供します。
短い系列の処理を有効にするには、freq パラメーターも定義する必要があります。 時間単位の頻度を定義するには、freq='H' を設定します。 Pandas 時系列ページの DataOffset オブジェクト セクションにアクセスして、頻度文字列のオプションを表示します。 既定の動作 short_series_handling_configuration = 'auto' を変更するには、ForecastingParameter オブジェクトの short_series_handling_configuration パラメーターを更新します。
from azureml.automl.core.forecasting_parameters import ForecastingParameters
forecast_parameters = ForecastingParameters(time_column_name='day_datetime',
forecast_horizon=50,
short_series_handling_configuration='auto',
freq = 'H',
target_lags='auto')
次の表は、short_series_handling_config のために設定できる項目をまとめたものです。
| 設定 | 説明 |
|---|---|
auto |
短い系列処理の既定値。 - "すべての系列が短い" 場合は、データを埋め込みます。 - "すべてが短い系列というわけではない" 場合は、短い系列をドロップします。 |
pad |
short_series_handling_config = pad の場合、自動 ML によって、検出されたそれぞれの短い系列に対してランダムの値が追加されます。 次に、列の型と、それらに埋め込まれる内容を示します。- オブジェクト列には NAN - 数値列には 0 - ブール/論理列には False - ターゲット列には、平均が 0、標準偏差が 1 のランダムな値が埋め込まれます。 |
drop |
short_series_handling_config = drop の場合、短い系列は自動 ML によってドロップされ、トレーニングや予測には使用されません。 これらの系列の予測では、NAN が返されます。 |
None |
埋め込まれる、またはドロップされる系列はありません。 |
警告
失敗せずに過去のトレーニングが受けられるように人為的なデータを用いるため、データが埋め込まれると、結果のモデルの精度に影響が及ぶ可能性があります。 短い系列が多くなる場合、説明可能性の結果に影響が生じる可能性があります。
非定常な時系列の検出と処理
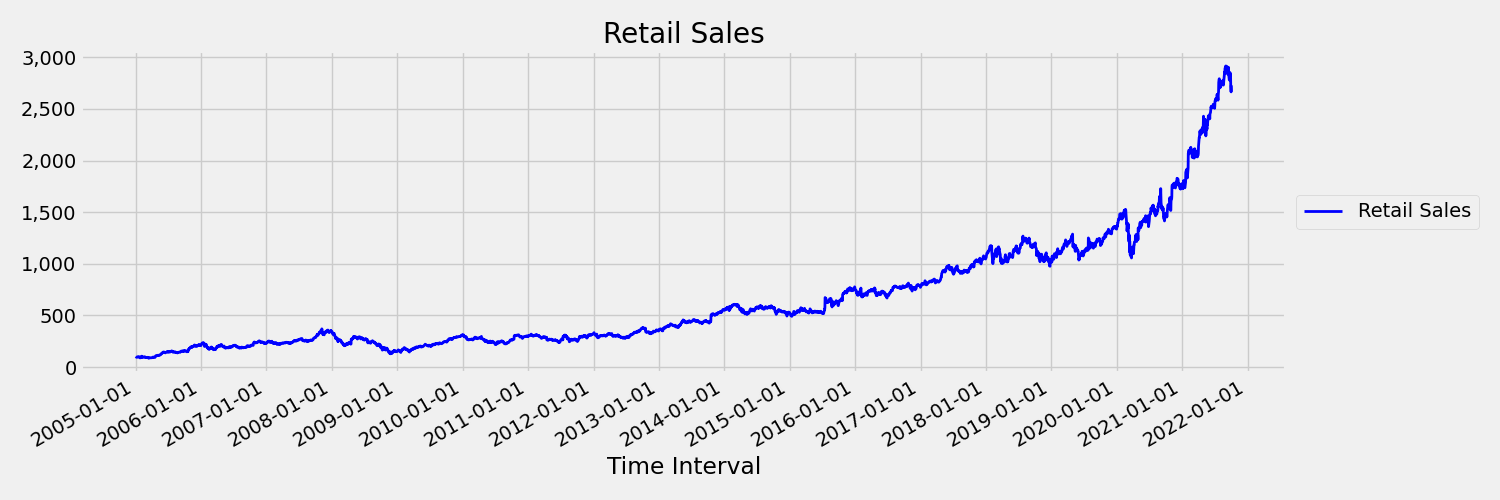
時間の経過に伴ってモーメント (平均と分散) が変化する時系列を非定常と呼びます。 たとえば、確率的傾向を示す時系列は、本質的に非定常です。 これを視覚化するために、次の画像では、全般的に上昇傾向にある系列をプロットします。 次に、系列の前半と後半の平均値を計算して比較します。 これらは同じでしょうか? ここで、プロットの前半の系列の平均は、後半よりも低くなっています。 系列の平均が、見ている時間間隔に依存するという事実は、時系列モーメントの 1 つの例です。 ここで、系列の平均は最初のモーメントです。
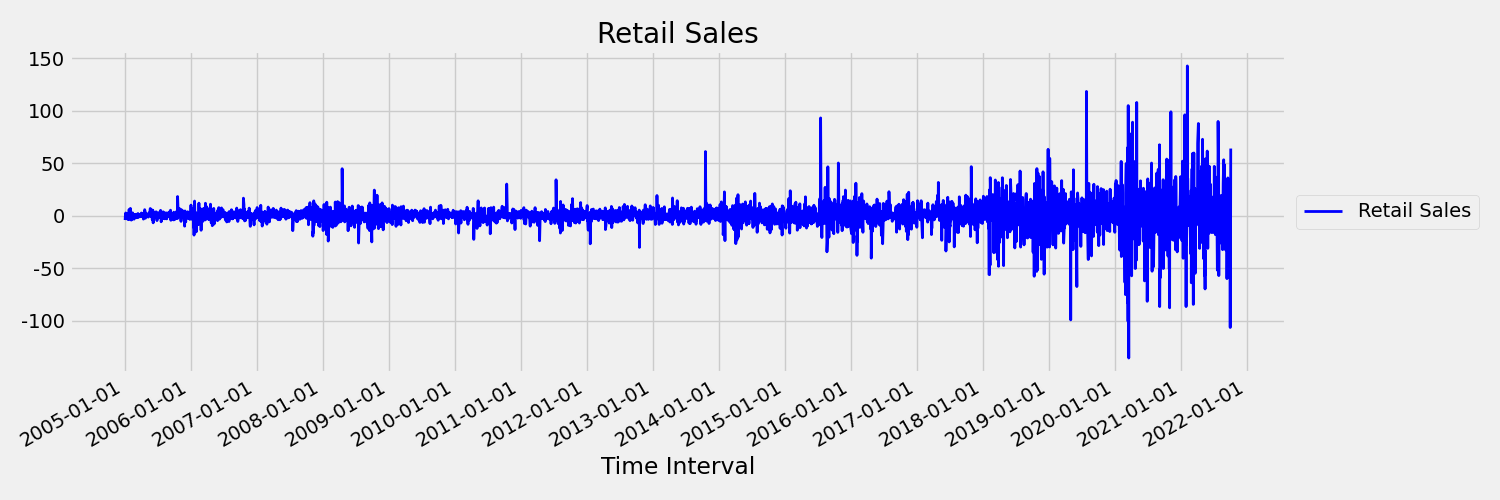
次に、最初の差分 $x_t = y_t - y_{t-1}$ で元の系列をプロットする図を見てみましょう。ここで、$x_t$ は小売売上高の変化であり、$y_t$ と $y_{t-1}$ はそれぞれ元の系列とその最初のラグを表します。 系列の平均は、見ている期間に関係なく、ほぼ一定です。 これは、first order 定常時系列の例です。 first order という用語を追加した理由は、最初のモーメント (平均) が時間間隔によって変化しないためです。分散については同じことは言えません。これは 2 番目のモーメントです。
AutoML 機械学習モデルでは、本質的に確率的傾向や、非定常時系列に関連するその他の既知の問題に対処することはできません。 その結果、そのような傾向がある場合、サンプル外の予測精度は "低" です。
AutoML では、時系列データセットが自動的に分析され、それが定常か否かを確認します。 非定常時系列が検出されると、非定常時系列の影響を軽減するために、AutoML によって自動的に差分変換が適用されます。
実験を実行する
AutoMLConfig オブジェクトの準備が整ったら、実験を送信できます。 モデルの終了後、最適な実行イテレーションを取得します。
ws = Workspace.from_config()
experiment = Experiment(ws, "Tutorial-automl-forecasting")
local_run = experiment.submit(automl_config, show_output=True)
best_run, fitted_model = local_run.get_output()
最適モデルによる予測
モデルのトレーニングに使用されなかったデータの値を予測するには、最適モデルの反復処理を使用します。
ローリング予測を使用したモデルの精度の評価
モデルを運用する前に、トレーニング データから提供されたテスト セットでその精度を評価する必要があります。 ベスト プラクティスの手順は、いわゆるローリング評価です。これは、トレーニングされた予測機能をテスト セット全体で時間的にロール フォワードし、複数の予測ウィンドウでエラー メトリックを平均して、選択したメトリック セットの統計的に頑健性がある推定値を取得します。 理想的には、評価のテスト セットは、モデルの予測期間と比べて長くなります。 予測エラーの推定値は、統計的にノイズが多いため、信頼性が低い可能性があります。
たとえば、日次売上のモデルをトレーニングして、将来最大 2 週間 (14 日) の需要を予測するとします。 使用可能な十分な履歴データがある場合は、テスト セットのデータの最後の数か月から 1 年間を予約できます。 ローリング評価は、テスト セットの最初の 2 週間の 14 日前の予測の生成から始まります。 その後、予測機能はテスト セットで数日進み、新しい位置から別の 14 日前の予測を生成します。 このプロセスは、テスト セットの最後に到達するまで続行されます。
ローリング評価を行うには、fitted_model の rolling_forecast メソッドを呼び出し、結果に対して必要なメトリックを計算します。 たとえば、test_features_df というテスト セット機能が pandas DataFrame にあり、test_target という numpy 配列内にターゲットのテスト セットの実際の値があるとします。 平均二乗誤差を使用したローリング評価を次のコード サンプルに示します。
from sklearn.metrics import mean_squared_error
rolling_forecast_df = fitted_model.rolling_forecast(
test_features_df, test_target, step=1)
mse = mean_squared_error(
rolling_forecast_df[fitted_model.actual_column_name], rolling_forecast_df[fitted_model.forecast_column_name])
このサンプルでは、ローリング予測のステップ サイズは 1 に設定されています。これは、予測機能が各イテレーションで 1 期間、つまり需要予測の例では 1 日進んでいることを意味します。 したがって、rolling_forecast によって返される予測の合計数は、テスト セットの長さとこのステップ サイズによって異なります。 詳細と例については、rolling_forecast() のドキュメントとトレーニング データからの予測に関するノートブックを参照してください。
将来への予測
forecast_quantiles() 関数を使用すると、予測を開始するタイミングを指定できます。これは、分類と回帰のタスクに通常使用される predict() メソッドとは異なります。 forecast_quantiles () メソッドでは既定で、不確実性の円すいを生じない、ポイント予測または平均/中央値予測が生成されます。 詳細については、「トレーニング データ ノートブックから離れた予測」を参照してください。
次の例では、最初に y_pred のすべての値を NaN に置き換えます。 このケースでは、予測の始まりはトレーニング データの最後です。 ただし、y_pred の後半部分のみを NaN に置き換えた場合、この関数では前半の数値を変更しないまま、後半の NaN の値を予測します。 この関数は、予測値と調整された特徴の両方を返します。
forecast_quantiles() 関数の forecast_destination パラメーターを使用して、指定した日付までの値を予測することもできます。
label_query = test_labels.copy().astype(np.float)
label_query.fill(np.nan)
label_fcst, data_trans = fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
多くの場合、お客様は分布の特定の分位点での予測を把握しようとします。 たとえば、予測を使用して、在庫 (食料品や、クラウド サービスの仮想マシンなど) を制御します。 このような場合、コントロール ポイントは通常、"その品目を在庫として持ち、間違いなく不足にはならないようにしたい" といったことです。 以下は、予測で確認する分位点 (50 や 95 パーセンタイルなど) を指定する方法を示しています。 前述のコード例のように分位点を指定しない場合、50 パーセンタイルの予測のみが生成されます。
# specify which quantiles you would like
fitted_model.quantiles = [0.05,0.5, 0.9]
fitted_model.forecast_quantiles(
test_dataset, label_query, forecast_destination=pd.Timestamp(2019, 1, 8))
モデルのパフォーマンスを見積もるのに役立つ、二乗平均平方根誤差 (RMSE) や平均絶対誤差率 (MAPE) のようなモデル メトリックを計算できます。 例については、Bike share demand ノートブックの Evaluate セクションを参照してください。
モデル全体の精度が判別した後、最も現実的な次の手順は、モデルを使用して不明な将来の値を予測することです。
テスト セット test_dataset と同じ形式ですが将来の日時を使用してデータ セットを提供すると、結果の予測セットは時系列手順ごとに予測された値になります。 データ セット内の最後の時系列レコードは 2018 年 12 月 31 日のものだったとします。 次の日 (または予測する必要のある数の期間、< = forecast_horizon) の需要を予測するには、2019 年 1 月 1 日の店舗ごとに 1 つの時系列レコードを作成します。
day_datetime,store,week_of_year
01/01/2019,A,1
01/01/2019,A,1
必要な手順を繰り返して、この将来のデータをデータフレームに読み込んで、best_run.forecast_quantiles(test_dataset) を実行して将来の値を予測します。
注意
target_lags や target_rolling_window_size が有効になっている場合、サンプル内の予測は、自動 ML を使用した予測ではサポートされません。
大規模な予測
機械学習モデルの数が 1 つでは不十分で、複数の機械学習モデルが必要になるシナリオがあります。 たとえば、1 つのブランドについて店舗ごとに売上を予測したり、個々のユーザーに合わせてエクスペリエンスを調整したりするような場合です。 インスタンスごとにモデルを構築すると、多くの機械学習の問題で結果が向上する可能性があります。
グループ化とは、時系列を組み合わせてグループごとに個々のモデルをトレーニングできる時系列予測の概念です。 このアプローチは、平滑化やフィリングが必要な時系列がある場合、つまりグループ内で他のエンティティの履歴や傾向が役立つ可能性があるエンティティがある場合に特に役立ちます。 多数モデルおよび階層型時系列予測は、これらの大規模な予測シナリオ向けに自動機械学習を利用したソリューションです。
多数モデル
自動機械学習を備えた Azure Machine Learning 多数モデル ソリューションを使用すると、ユーザーは何百万ものモデルを並列でトレーニングおよび管理できます。 多数モデル ソリューション アクセラレータでは、Azure Machine Learning パイプラインを利用してモデルをトレーニングします。 具体的には、Pipeline オブジェクトと ParalleRunStep が使用されるため、ParallelRunConfig を介して設定された特定の構成パラメーターが必要です。
次の図は、多数モデル ソリューションのワークフローを示しています。

次のコードは、ユーザーが多数モデルの実行を設定するために必要な主要なパラメーターを示しています。 多くのモデル予測の例については、「多くのモデル - 自動 ML ノートブック」を参照してください
from azureml.train.automl.runtime._many_models.many_models_parameters import ManyModelsTrainParameters
partition_column_names = ['Store', 'Brand']
automl_settings = {"task" : 'forecasting',
"primary_metric" : 'normalized_root_mean_squared_error',
"iteration_timeout_minutes" : 10, #This needs to be changed based on the dataset. Explore how long training is taking before setting this value
"iterations" : 15,
"experiment_timeout_hours" : 1,
"label_column_name" : 'Quantity',
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
"time_column_name": 'WeekStarting',
"max_horizon" : 6,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,}
mm_paramters = ManyModelsTrainParameters(automl_settings=automl_settings, partition_column_names=partition_column_names)
階層型時系列予測
ほとんどのアプリケーションでは、お客様はマクロとマイクロのレベルでビジネスの予測を理解する必要があります。 予測によって、異なる地理的な場所での製品の売上の見込みを立てたり、企業のさまざまな組織に対して予想される労働力需要を把握したりすることができます。 機械学習モデルをトレーニングして階層データをインテリジェントに予測する機能が不可欠です。
階層型時系列は、地域や製品の種類などのディメンションに基づいて、一意の各系列が階層に配置される構造です。 次の例は、階層を形成する一意の属性を含むデータを示しています。 この階層は、ヘッドフォンやタブレットなどの製品の種類、製品の種類をアクセサリーとデバイスに分割する製品カテゴリ、製品が販売されている地域によって定義されます。

これをさらに視覚化するために、階層のリーフ レベルには、属性値の一意の組み合わせを含むすべての時系列が含まれています。 階層内のレベルを 1 つ上がるごとに、時系列を定義するためのディメンションが 1 つ少なくなると考えられ、下位レベルの子ノードの各セットが親ノードに集計されます。

階層型時系列ソリューションは、多数モデル ソリューションを基盤として構築され、同じ構成設定を共有します。
次のコードは、階層型時系列予測の実行を設定するための主要なパラメーターを示しています。 エンド ツー エンドの例については、「階層時系列 - 自動化された ML ノートブック」を参照してください。
from azureml.train.automl.runtime._hts.hts_parameters import HTSTrainParameters
model_explainability = True
engineered_explanations = False # Define your hierarchy. Adjust the settings below based on your dataset.
hierarchy = ["state", "store_id", "product_category", "SKU"]
training_level = "SKU"# Set your forecast parameters. Adjust the settings below based on your dataset.
time_column_name = "date"
label_column_name = "quantity"
forecast_horizon = 7
automl_settings = {"task" : "forecasting",
"primary_metric" : "normalized_root_mean_squared_error",
"label_column_name": label_column_name,
"time_column_name": time_column_name,
"forecast_horizon": forecast_horizon,
"hierarchy_column_names": hierarchy,
"hierarchy_training_level": training_level,
"track_child_runs": False,
"pipeline_fetch_max_batch_size": 15,
"model_explainability": model_explainability,# The following settings are specific to this sample and should be adjusted according to your own needs.
"iteration_timeout_minutes" : 10,
"iterations" : 10,
"n_cross_validations" : "auto", # Could be customized as an integer
"cv_step_size" : "auto", # Could be customized as an integer
}
hts_parameters = HTSTrainParameters(
automl_settings=automl_settings,
hierarchy_column_names=hierarchy,
training_level=training_level,
enable_engineered_explanations=engineered_explanations
)
サンプルの Notebook
次のような高度な予測の構成の詳細なコード例については、予測サンプル ノートブックを参照してください。
次のステップ
- 詳細については、「AutoML モデルをオンライン エンドポイントにデプロイする方法」を参照してください。
- 解釈可能性: 自動機械学習のモデルの説明 (プレビュー) について学習する。
- AutoML で予測モデルを構築する方法について学習する。