Azure HDInsight での対話型クエリとは
対話型クエリ (別名 Apache Hive LLAP または Low Latency Analytical Processing) は、Azure HDInsight のクラスターの一種です。 対話型クエリではインメモリ キャッシュがサポートされるため、Apache Hive クエリの速度と対話性が向上します。 顧客は、対話型クエリを使用して、Azure ストレージと Azure Data Lake Storage に格納されているデータに対するクエリを超高速で実行します。 対話型クエリにより、開発者およびデータ サイエンティストは、お気に入りの BI ツールを使用して容易にビッグ データを操作できるようになります。 HDInsight の対話型クエリは、簡単な方法でビッグ データにアクセスするためにいくつかのツールをサポートします。
対話型クエリ クラスターは、Apache Hadoop クラスターとは異なり、 Hive サービスのみが含まれます。
対話型クエリ クラスター内の Hive サービスには、Apache Ambari Hive View、Beeline、および Microsoft Hive Open Database Connectivity ドライバー (Hive ODBC) からのみアクセスできます。 Hive コンソール、Templeton、Azure クラシック CLI、Azure PowerShell からはアクセスできません。
対話型クエリ クラスターの作成
HDInsight クラスターの作成について詳しくは、HDInsight 内での Apache Hadoop クラスターの作成に関する記事をご覧ください。 対話型クエリのクラスターの種類を選択します。
重要
対話型クエリ クラスターのヘッドノードの最小サイズは Standard_D13_v2 です。 詳細については、「Azure 仮想マシンのサイズ変更チャート」を参照してください。
対話型クエリから Apache Hive クエリを実行する
Hive クエリを実行するには、次のオプションがあります。
| Method | 説明 |
|---|---|
| Microsoft Power BI | Azure HDInsight 上の Power BI を使用した対話型クエリの Apache Hive データの視覚化に関する記事および Azure HDInsight 上の Power BI を使用したビッグ データの視覚化に関する記事をご覧ください。 |
| Visual Studio | Data Lake Tools for Visual Studio を使用した Azure HDInsight への接続と Apache Hive クエリの実行に関するページをご覧ください。 |
| Visual Studio Code | Apache Hive、LLAP、pySpark に Visual Studio Code を使用する方法に関する記事を参照してください。 |
| Apache Ambari Hive ビュー | Azure HDInsight 上の Apache Hadoop で Apache Hive ビューを使用する方法に関する記事をご覧ください。 HDInsight 4.0 では、Hive ビューは使用できません。 |
| Apache Beeline | Beeline による HDInsight 上の Apache Hive と Apache Hadoop の使用に関する記事をご覧ください。 Beeline はヘッド ノードまたは空のエッジ ノードから使用できます。 空のエッジ ノードから Beeline を使用することをお勧めします。 空のエッジ ノードを使って HDInsight クラスターを作成する方法の詳細については、「HDInsight での空のエッジ ノードの使用」を参照してください。 |
| Hive ODBC | Microsoft Hive ODBC ドライバーを使用した Excel から Apache Hadoop への接続に関するページをご覧ください。 |
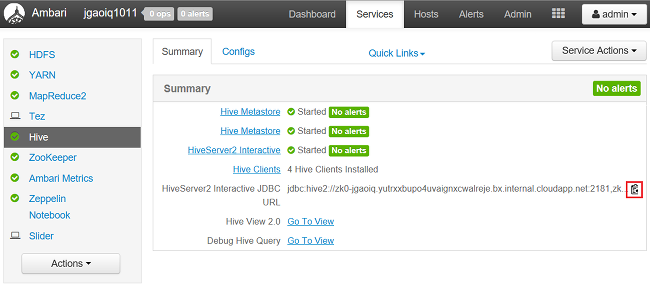
Java Database Connectivity (JDBC) 接続文字列は次の方法で調べることができます。
Web ブラウザーから、
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryに移動します。ここで、CLUSTERNAMEはクラスターの名前です。URL をコピーするには、クリップボード アイコンを選択します。