HDInsight 上で JDBC ドライバーを使用して Apache Hive のクエリを実行する
Java アプリケーションから JDBC ドライバーを使用する方法について説明します。 Azure HDInsight で Apache Hadoop に Apache Hive クエリを送信します。 このドキュメントの情報では、プログラミングによって SQuirreL SQL クライアントから接続する方法を示します。
Hive JDBC インターフェイスの詳細については、 HiveJDBCInterfaceを参照してください。
前提条件
- HDInsight Hadoop クラスター。 その作成方法については、Azure HDInsight の概要に関するページをご覧ください。 サービス HiveServer2 が実行されていることを確認します。
- Java Developer Kit (JDK) バージョン 11 以降。
- SQuirreL SQL。 SQuirreL は、JDBC クライアント アプリケーションです。
JDBC 接続文字列
Azure の HDInsight クラスターに対する JDBC 接続はポート 443 を使用して行われます。 トラフィックは TLS/SSL を使用してセキュリティで保護されます。 クラスターが背後に存在するパブリックのゲートウェイは HiveServer2 が実際にリッスンするポートにトラフィックをリダイレクトします。 次の接続文字列は、HDInsight に使用する形式を示しています。
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
CLUSTERNAME を、使用する HDInsight クラスターの名前に置き換えます。
接続文字列のホスト名
接続文字列のホスト名 'CLUSTERNAME.azurehdinsight.net' は、お使いのクラスターの URL と同じです。 Azure portal を使用してそれを取得できます。
接続文字列のポート
Azure 仮想ネットワークの外部にある場所からクラスターに接続するには、ポート 443 のみを使用できます。 HDInsight は管理サービスです。これは、クラスターへのすべての接続がセキュリティで保護されたゲートウェイ経由で管理されることを意味します。 ポート 10001 または 10000 で HiveServer 2 に直接接続することはできません。 これらのポートは、外部には公開されません。
認証
接続を確立するときに、HDInsight クラスターの管理者名とパスワードを使用して認証を行います。 SQuirreL SQL などの JDBC クライアントから、クライアント設定で管理者名とパスワードを入力します。
Java アプリケーションから接続を確立する場合、名前とパスワードを使用する必要があります。 たとえば、次の Java コードは新しい接続を開きます。
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
SQuirreL SQL クライアントとの接続
SQuirreL SQL は、HDInsight クラスターを使用して Hive クエリをリモートから実行するために使用できる JDBC クライアントです。 次の手順では、既に SQuirreL SQL がインストールされていると仮定します。
クラスターからコピーする特定のファイルを含むディレクトリを作成します。
次のスクリプトで、
sshuserをクラスターの SSH ユーザー アカウント名に置き換えます。CLUSTERNAMEを HDInsight クラスター名に置き換えます。 作業ディレクトリをコマンドラインから前の手順で作成したものに変更し、次のコマンドを入力して HDInsight クラスターからファイルをコピーします。scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .SQuirreL SQL アプリケーションを起動します。 ウィンドウの左側から [Drivers] を選択します。
![ウィンドウの左側の [ドライバー] タブ。](media/apache-hadoop-connect-hive-jdbc-driver/hdinsight-squirreldrivers.png)
[Drivers(ドライバー)] ダイアログの上部にあるアイコンから、+ アイコンを選択してドライバーを作成します。
[追加されたドライバー] ダイアログで、次の情報を追加します。
プロパティ 値 名前 Hive Example URL (URL の例) jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Extra Class Path (追加クラス パス) [追加] ボタンを使って、以前にダウンロードしたすべての jar ファイルを追加します。 Class Name (クラス名) org.apache.hive.jdbc.HiveDriver 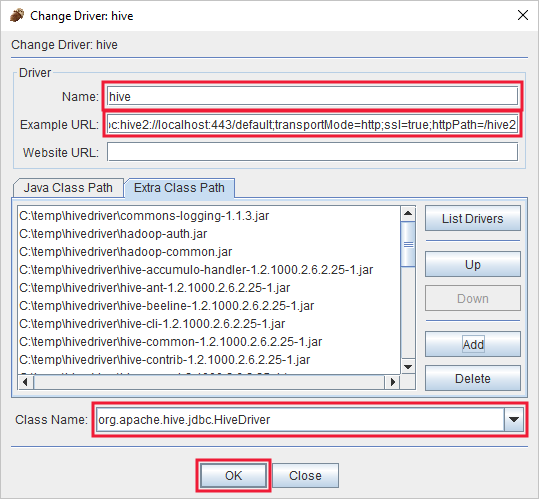
[OK] を選択してこれらの設定を保存します。
SQuirreL SQL ウィンドウの左側で、 [Aliases] を選択します。 次に + アイコンを選択して接続のエイリアスを作成します。
[Add Alias](エイリアスの追加) ダイアログでは次の値を使用します。
プロパティ 値 名前 HDInsight の Hive Driver ドロップダウンを使用して、Hive ドライバーを選択します。 URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. CLUSTERNAME を、使用する HDInsight クラスターの名前に置き換えます。[ユーザー名] HDInsight クラスターのクラスター ログイン アカウント名。 既定値は admin です。 Password クラスター ログイン アカウントのパスワード。 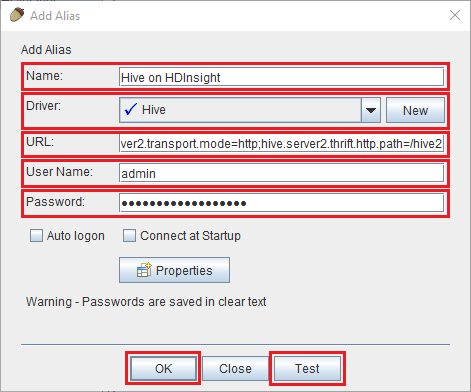
重要
[Test] ボタンを使用して、接続が機能することを確認します。 [Connect to: Hive on HDInsight] (接続先: HDInsight 上の Hive) ダイアログが表示されたら、 [接続] を選択してテストを実行します。 テストが成功した場合、 [Connection successful(接続成功)] ダイアログが表示されます。 エラーが発生した場合は、「トラブルシューティング」を参照してください。
[Add Alias(エイリアスの追加)] ダイアログの下部にある [OK] ボタンを使用して、接続エイリアスを保存します。
SQuirreL SQL の上部にある [Connect to] ドロップダウンから、 [Hive on HDInsight] を選択します。 メッセージが表示されたら、 [Connect] を選択します。
接続されたら、SQL クエリ ダイアログに次のクエリを入力し、 [Run](実行) アイコン (走っている人) を選択します。 結果領域にクエリの結果が表示されます。
select * from hivesampletable limit 10;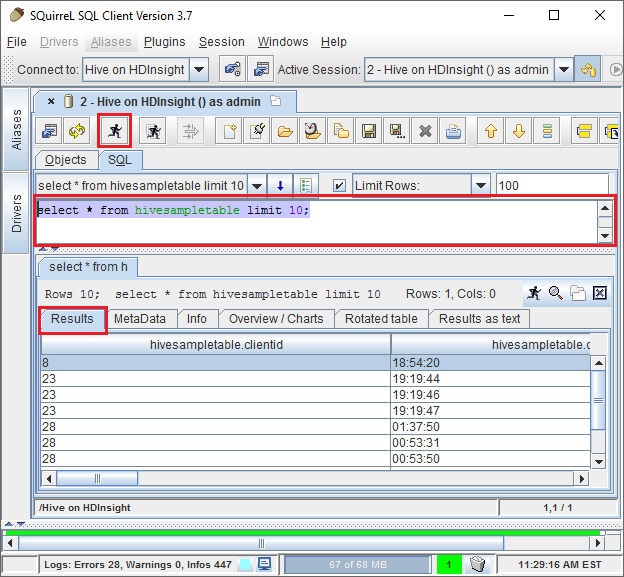
Java アプリケーションの例からの接続
Java クライアントを使って HDInsight の Hive をクエリする例は、https://github.com/Azure-Samples/hdinsight-java-hive-jdbc にあります。 リポジトリの指示に従い、サンプルを作成して実行します。
トラブルシューティング
SQL 接続を開こうとしたときに、予期しないエラーが発生した
現象:バージョン 3.3 以上の HDInsight クラスターに接続するときに、予期しないエラーが発生したというエラーを受け取る場合があります。 このエラーのスタック トレースは、次の行で始まります。
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
原因:このエラーは、SQuirreL に付属する commons-codec.jar ファイルのバージョンが古いために発生します。
解決方法:このエラーを解決するには、次の手順を使用します。
SQuirreL を終了し、SQuirreL がインストールされているシステム上のディレクトリに移動します (
C:\Program Files\squirrel-sql-4.0.0\libなど)。 SquirreL ディレクトリ内のlibディレクトリにある既存の commons-codec jar を、HDInsight クラスターからダウンロードしたファイルに置き換えます。SQuirreL を再起動します。 これで、HDInsight の Hive に接続するときにエラーが発生しなくなります。
HDInsight によって接続が切断される
症状: HDInsight で、JDBC/ODBC を介して大量のデータ (たとえば、数 GB) をダウンロードしようとすると、接続が予期せず切断されます。
原因: ゲートウェイ ノードの制限により、このエラーが発生します。 JDBC/ODBC からデータを取得する場合、すべてのデータがゲートウェイ ノードを通過する必要があります。 ただし、ゲートウェイは膨大な量のデータをダウンロードするように設計されていないため、ゲートウェイは、トラフィックを処理できない場合は接続を閉じることがあります。
解決方法:大量のデータをダウンロードする場合は、JDBC/ODBC ドライバーを使用しないようにします。 代わりに、BLOB ストレージから直接データをコピーします。
次のステップ
これで、JDBC を使用して Hive を操作する方法に関する説明は終わりです。次のリンクを使用して、Azure HDInsight を操作するその他の方法について調べることもできます。
- Azure HDInsight の Microsoft Power BI で Apache Hive データを視覚化する。
- Azure HDInsight の Power BI で対話型クエリの Hive データを視覚化する。
- Microsoft Hive ODBC Driver を使用して Excel を HDInsight に接続する。
- Power Query を使用して Excel を Apache Hadoop に接続する。
- HDInsight での Apache Hive の使用
- HDInsight での Apache Pig の使用
- HDInsight での MapReduce ジョブの使用