ワークフローのサーバーレス コンピューティングを使用して Azure Databricks ジョブを実行する
ワークフローのサーバーレス コンピューティングを使うと、インフラストラクチャを構成してデプロイしなくても、Azure Databricks ジョブを実行できます。 サーバーレス コンピューティングでは、ユーザーはデータ処理と分析パイプラインの実装に集中し、ワークロード用のコンピューティングの最適化やスケーリングなどのコンピューティング リソースの管理は、Azure Databricks によって効率的に行われます。 ジョブを実行するコンピューティング リソースでは、自動スケーリングと Photon が自動的に有効になります。
ワークフローのサーバーレス コンピューティングは、インスタンスの種類、メモリ、処理エンジンなどのインフラストラクチャを自動的かつ継続的に最適化し、ワークロードの特定の処理要件に基づいて最適なパフォーマンスを確保します。
Databricks は、Databricks Runtime バージョンを自動的にアップグレードして、Azure Databricks ジョブの安定性を確保しながら、プラットフォームに対する機能強化とアップグレードをサポートします。 ワークフローのサーバーレス コンピューティングで使われている現在の Databricks Runtime バージョンについては、「サーバーレス コンピューティングのリリース ノート」をご覧ください。
クラスター作成アクセス許可は必要ないため、すべてのワークスペース ユーザーがサーバーレス コンピューティングを使ってワークフローを実行できます。
この記事では、サーバーレス コンピューティングを使用するジョブを、Azure Databricks ジョブ UI を使って作成して実行する方法について説明します。 サーバーレス コンピューティングを使用するジョブの作成と実行は、Jobs API、Databricks アセット バンドル、Databricks SDK for Python を使って自動化することもできます。
- ジョブ API を使って、サーバーレス コンピューティングを使用するジョブを作成および実行する方法については、REST API リファレンスの「ジョブ」をご覧ください。
- Databricks アセット バンドルを使って、サーバーレス コンピューティングを使用するジョブを作成および実行する方法については、「Databricks アセット バンドルを使用して Azure Databricks でジョブを開発する」をご覧ください。
- Databricks SDK for Python を使って、サーバーレス コンピューティングを使用するジョブを作成および実行する方法については、「Databricks SDK for Python」をご覧ください。
要件
Azure Databricks ワークスペースで Unity カタログが有効になっている必要があります。
ワークフローのサーバーレス コンピューティングでは共有アクセス モードが使われるため、ワークロードでこのアクセス モードをサポートする必要があります。
Databricks ワークスペースは、サポートされているリージョンに存在する必要があります。 「利用可能なリージョンに制限がある機能」を参照してください。
Azure Databricks アカウントでサーバーレス コンピューティングが有効になっている必要があります。 「サーバーレス コンピューティングを有効にする」をご覧ください。
サーバーレス コンピューティングを使用するジョブを作成する
Note
ワークフローのサーバーレス コンピューティングにより、ワークロードを実行するための十分なリソースが確実にプロビジョニングされるため、大量のメモリを必要とする、または多数のタスクを含む Azure Databricks ジョブを実行するときに、起動時間が長くなる可能性があります。
サーバーレス コンピューティングは、ノートブック、Python スクリプト、dbt、Python wheel のタスクの種類でサポートされています。 既定では、新しいジョブを作成し、これらのサポートされているタスクの種類のいずれかを追加すると、サーバーレス コンピューティングがコンピューティングの種類として選択されます。
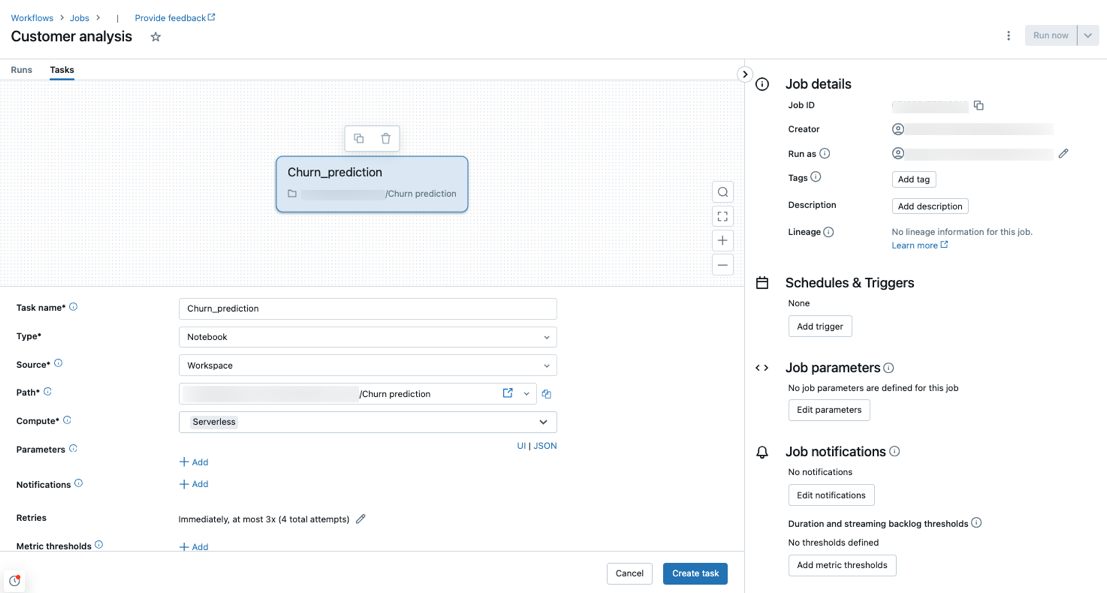
Databricks では、すべてのジョブ タスクにサーバーレス コンピューティングを使うことをお勧めします。 ジョブのタスクに対して、異なるコンピューティングの種類を指定することもできます。これは、タスクの種類がワークフローのサーバーレス コンピューティングでサポートされていない場合に、必要になることがあります。
ジョブの外向きネットワーク接続を管理するには、「サーバーレスエグレス制御とは」を参照してください。
サーバーレス コンピューティングを使用するように既存のジョブを構成する
ジョブを編集するときに、サポートされているタスクの種類でサーバーレス コンピューティングを使うように、既存のジョブを切り替えることができます。 サーバーレス コンピューティングに切り替えるには、次のいずれかを行います。
- [ジョブの詳細] サイド パネルで、[コンピューティング] の下の [スワップ] をクリックして、[新規] をクリックし、設定を入力または更新して、[更新] をクリックします。
- [コンピューティング] ドロップダウンメニューで [
 ] をクリックし、[サーバーレス] を選択します。
] をクリックし、[サーバーレス] を選択します。

サーバーレス コンピューティングを使用するノートブックをスケジュールする
ジョブ UI を使ってサーバーレス コンピューティングを使用するジョブを作成してスケジュールするだけでなく、Databricks ノートブックから直接サーバーレス コンピューティングを使用するジョブを作成して実行できます。 「スケジュールされたノートブック ジョブの作成と管理」をご覧ください。
サーバーレス使用の予算ポリシーを選択する
重要
この機能はパブリック プレビュー段階にあります。
予算ポリシーを使用すると、組織はサーバーレスの使用状況にカスタム タグを適用して、詳細な課金属性を設定できます。
ワークスペースで予算ポリシーを使用してサーバーレス使用量を属性付けする場合は、ジョブの詳細 UI の [予算ポリシー 設定を使用して、ジョブの予算ポリシーを選択できます。 1 つの予算ポリシーにのみ割り当てられている場合は、新しいジョブに対してポリシーが自動的に選択されます。
Note
予算ポリシーが割り当てられた後、既存のジョブにはポリシーのタグが自動的に付けされません。 ポリシーをアタッチする場合は、既存のジョブを手動で更新する必要があります。
予算ポリシーの詳細については、「 予算ポリシーを使用したサーバーレス使用の実行」を参照してください。
Spark 構成パラメーターを設定する
サーバーレス コンピューティングでの Spark の構成を自動化するために、Databricks では特定の Spark 構成パラメーターのみを設定できます。 使用可能なパラメーターの一覧については、「サポートされている Spark 構成パラメーター を参照してください。
Spark 構成パラメーターは、セッション レベルでのみ設定できます。 これを行うには、ノートブックに設定し、パラメーターを使用するのと同じジョブに含まれるタスクにノートブックを追加します。 ノートブックで Apache Spark 構成プロパティを取得および設定する方法についてはをご覧ください。
環境と依存関係を構成する
サーバーレス コンピューティングを使用してライブラリと依存関係をインストールする方法については、「 ノートブックの依存関係のインストールを参照してください。
再試行を禁止するようにサーバーレス コンピューティングの自動最適化を構成する
ワークフローのサーバーレス コンピューティングの自動最適化は、ジョブの実行に使われるコンピューティングを自動的に最適化し、失敗したタスクを再試行します。 自動最適化は既定で有効になっており、Databricks では、重要なワークロードが少なくとも 1 回は正常に実行されるように、有効のままにしておくことをお勧めします。 ただし、べき等ではないジョブなど、多くても 1 回しか実行してはならないワークロードがある場合は、タスクを追加または編集するときに自動最適化をオフにできます。
- [再試行] の横にある [追加] をクリックします (または、再試行ポリシーが既にある場合は
![[編集] アイコン](../_static/images/icons/edit-icon.png) )。
)。 - [再試行ポリシー] ダイアログで、[サーバーレス自動最適化を有効にする (追加の再試行を含むことができる)] をオフにします。
- [Confirm]\(確認\) をクリックします。
- タスクを追加している場合は、[タスクの作成] をクリックします。 タスクを編集している場合は、[タスクの保存] をクリックします。
ワークフローのサーバーレス コンピューティングを使用するジョブのコストを監視する
課金対象の使用状況システム テーブル クエリを実行することで、ワークフローに対してサーバーレス コンピューティングを使用するジョブのコストを監視できます。 この表は、サーバーレス コストに関するユーザー属性とワークロード属性を含むように更新されます。 「課金対象の使用状況システム テーブル リファレンス」を参照してください。
現在の価格とプロモーションについては、「 ワークフローの価格」ページを参照してください。
ジョブ実行のクエリの詳細を表示する
メトリックやクエリ プランなど、Spark ステートメントの詳細なランタイム情報を表示できます。
ジョブ UI からクエリの詳細にアクセスするには、次の手順を使用します。
サイドバーの
![[ワークフロー] アイコン](../_static/images/icons/workflows-icon.png) [ワークフロー] をクリックします。
[ワークフロー] をクリックします。表示するジョブの名前をクリックします。
表示する特定の実行をクリックします。
Timeline をクリックして、個々のタスクに分割された実行をタイムラインとして表示します。
タスク名の横にある矢印をクリックすると、クエリ ステートメントとそのランタイムが表示されます。
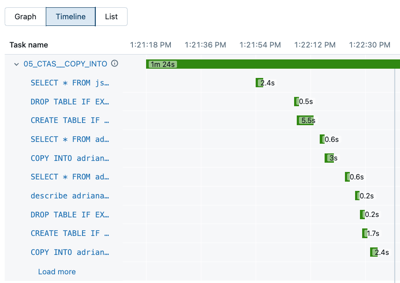
ステートメントをクリックして、 query の詳細 パネルを開きます。 このパネルで使用できる情報の詳細についてはクエリの詳細を参照してください。
タスクのクエリ履歴を表示するには:
- [タスクの実行] サイド パネルの [コンピューティング] セクションで [クエリ履歴] をクリックします。
- 自分が行っていたタスクのタスク実行 ID に基づいて事前にフィルター処理された Query History にリダイレクトされます。
クエリ履歴の使用に関する情報については、「Delta Live Tables パイプラインのクエリ履歴へのアクセス」および「クエリ履歴」を参照してください。
制限事項
ワークフローの制限に関するサーバーレス コンピューティングの一覧については、サーバーレス コンピューティングのリリース ノート サーバーレス コンピューティングの制限 を参照してください。