前提条件: 要件を収集する
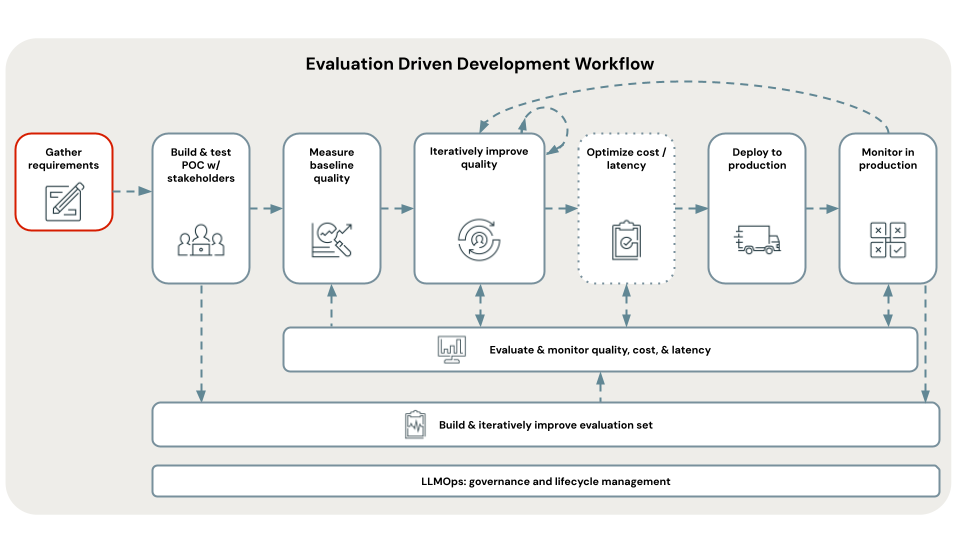
明確で包括的なユース ケース要件を定義することは、成功する RAG アプリケーションを開発するための重要な第一歩です。 これらの要件には主に 2 つの目的があります。 まず、RAG が特定のユース ケースに最適なアプローチであるかどうかを判断するのに役立ちます。 RAG が実際に適している場合は、これらの要件がソリューションの設計、実装、評価の決定に役立ちます。 プロジェクトの初期段階で詳細な要件を収集することに時間をかけることで、開発プロセスの後半で大きな課題や後退を防ぐことができます。また、結果として得られるソリューションでエンドユーザーや関係者のニーズを確実に満たすことができます。 明確に定義された要件は、これから説明する開発ライフサイクルの後続のステージの基礎となります。
このセクションのサンプル コードは GitHub リポジトリを参照してください。 リポジトリ コードをテンプレートとして使用して、独自の AI アプリケーションを作成することもできます。
ユース ケースは RAG に適していますか?
最初に確認する必要があるのは、RAG が自分のユース ケースに適したアプローチであるかどうかです。 RAG に対する過剰な期待から、RAG をあらゆる問題の解決策として考えがちです。 ただし、RAG が適している場合とそうでない場合には微妙な違いがあります。
RAG は次の場合に適しています。
- LLM のコンテキスト ウィンドウに収まりきらない取得情報 (構造化されていないものと構造化されたものの両方) を分析する場合
- 複数のソースの情報を合成する場合 (たとえば、あるトピックに関するさまざまな記事から重要なポイントの概要を生成するなど)
- ユーザー クエリに基づく動的な取得が必要 (たとえば、ユーザー クエリに対して、どのデータ ソースから検索するかを決定するなど)
- このユース ケースでは、取得情報に基づいて新しいコンテンツを生成する必要があります (質問に答える、説明を提供する、推奨事項を提供するなど)。
次の場合、RAG は最適ではない可能性があります。
- このタスクではクエリ固有の取得は必要ありません。 たとえば、通話記録の概要を生成するなどです。個々のトランスクリプトが LLM プロンプトのコンテキストとして提供された場合でも、各概要の取得情報は同じままです。
- 取得する情報セット全体が LLM のコンテキスト ウィンドウ内に収まります
- 極めて短い待機時間の応答が必要です (たとえば、ミリ秒単位の応答が必要な場合)
- 単純な規則ベースまたはテンプレート化された応答で十分です (たとえば、キーワードに基づいて事前に定義した応答を提供するカスタマー サポート チャットボット)
検出する要件
RAG が自分のユース ケースに適していることを確認したら、具体的な要件を把握するために次の質問を検討してください。 要件の優先順位は次のとおりです。
🟢 P0: POC を開始する前にこの要件を定義する必要があります。
🟡 P1: 運用環境に移行する前に定義する必要がありますが、POC 中に繰り返し調整できます。
⚪ P2: あれば良い程度の要件です。
これは網羅的な質問一覧ではありません。 そうではなく、RAG ソリューションの主要な要件を把握する際に確かな基盤となるものです。
ユーザー エクスペリエンス
ユーザーが RAG システムとどのようにやり取りするか、どのような種類の応答が想定されるかを定義します
🟢 [P0] RAG チェーンに対する一般的な要求はどのようなものですか? 関係者に見込みユーザーのクエリ例を尋ねてください。
🟢 [P0] ユーザーはどのような応答を想定しますか (短い答え、長い形式の説明、その組み合わせなど)?
🟡 [P1] ユーザーはシステムとどのようにやり取りしますか? チャット インターフェイス、検索バー、またはその他のモダリティを使用しますか?
🟡 [P1] どのようなトーンまたはスタイルで応答を生成する必要がありますか? (フォーマル、口語的、技術的?)
🟡 [P1] アプリケーションは、あいまい、不完全、または無関係なクエリをどのように処理すべきですか? そのような場合、何らかの形でフィードバックやガイダンスを提供する必要がありますか?
⚪ [P2] 生成される出力に特定の形式またはプレゼンテーションの要件はありますか? 出力にはチェーンの応答に加えてメタデータを含める必要がありますか?
データ
RAG ソリューションで使用されるデータの性質、ソース、品質を決定します。
🟢 [P0] 使用できるソースは何ですか?
各データ ソースについて:
- 🟢 [P0] データは構造化されていますか、それとも構造化されていませんか?
- 🟢 [P0] 取得データのソースはどのような形式ですか (たとえば、PDF、画像や表を含むドキュメント、構造化 API 応答)?
- 🟢 [P0] そのデータはどこにありますか?
- 🟢 [P0] 使用できるデータの量はどのくらいですか?
- 🟡 [P1] データはどのくらいの頻度で更新されますか? このような更新プログラムはどのように処理する必要がありますか?
- 🟡 [P1] データ ソースごとに既知のデータ品質の問題や不整合はありますか?
たとえば、この情報を統合するために、次のような在庫テーブルを作成することを検討してください。
| データ ソース | ソース | ファイルの種類 | サイズ | 更新の頻度 |
|---|---|---|---|---|
| データ ソース 1 | Unity Catalog ボリューム | JSON | 10 GB | 毎日 |
| データ ソース 2 | パブリック API | XML | NA (API) | リアルタイム |
| データ ソース 3 | SharePoint | PDF、.docx | 500 MB | 月ごと |
パフォーマンスの制約
RAG アプリケーションのパフォーマンスとリソースの要件を把握します。
🟡 [P1] 応答を生成する際に許容できる最長待機時間はどのくらいですか?
🟡 [P1] 最初のトークンに許容できる最長時間はどのくらいですか?
🟡 [P1] 出力がストリーミングされている場合、合計待機時間が長くても許容されますか?
🟡 [P1] 推論に使用できるコンピューティング リソースにコスト制限はありますか?
🟡 [P1] 予想される使用パターンとピーク負荷はどのようなものですか?
🟡 [P1] システムで処理できる同時ユーザーまたは要求の数はどのくらいですか? Databricks は、Model Serving を使用して自動的にスケーリングする機能により、このようなスケーラビリティ要件をネイティブに処理します。
評価
RAG ソリューションを時間の経過と共にどのように評価し、改善するかを確立します。
🟢 [P0] 影響を与えたいビジネス目標または KPI は何ですか? 基準値値とターゲットは何ですか?
🟢 [P0] どのユーザーまたは関係者が初期および継続的なフィードバックを提供しますか?
🟢 [P0] 生成された応答の品質を評価するには、どのようなメトリックを使用する必要がありますか? Mosaic AI Agent Evaluation には、使用するメトリックの推奨セットが用意されています。
🟡 [P1] RAG アプリを運用環境に移行するために得意でなければならない質問セットは何ですか?
🟡 [P1] [評価セット] は存在しますか? ユーザー クエリの評価セットと、真実の回答、(省略可能) 取得する必要がある正しい裏付けドキュメントを取得することはできますか?
🟡 [P1] ユーザー フィードバックはどのように収集され、システムに組み込まれますか?
セキュリティ
セキュリティとプライバシーに関する考慮事項を特定します。
🟢 [P0] 慎重に取り扱う必要がある機密データはありますか?
🟡 [P1] ソリューションにアクセス制御を実装する必要がありますか (たとえば、特定のユーザーは制限されたドキュメントのセットからのみ取得できるなど)?
展開
RAG ソリューションがどのように統合、デプロイ、保守されるかを理解してください。
🟡 RAG ソリューションは既存のシステムやワークフローとどのように統合すべきですか?
🟡 モデルをどのようにデプロイ、スケーリング、バージョン管理する必要がありますか? このチュートリアルでは、MLflow、Unity Catalog、Agent SDK、Model Serving を使用して Databricks でエンドツーエンドのライフサイクルを処理する方法について説明します。
例
たとえば、Databricks カスタマー サポート チームが使用するこのサンプル RAG アプリケーションに、これらの質問がどのように適用されるかを考えてみましょう。
| 面グラフ | 考慮事項 | 要件 |
|---|---|---|
| ユーザー エクスペリエンス | - 対話型モダリティ。 - 一般的なユーザー クエリの例。 - 想定される応答の形式とスタイル。 - あいまいまたは無関係なクエリの処理。 |
- Slack と統合されたチャット インターフェイス。 - クエリの例:「クラスターの起動時間を短縮する操作方法は?」 「どのようなサポート プランがありますか?」 - コード スニペットや関連ドキュメントへのリンクを適切に用いた、明確で技術的な応答。 - 状況に応じた提案を示し、必要に応じてサポート エンジニアにエスカレーションします。 |
| データ | - データ ソースの数と種類。 - データの形式と場所。 - データ サイズと更新頻度。 - データの品質と一貫性。 |
- 3 つのデータ ソース。 - 会社のドキュメント (HTML、PDF)。 - 解決済みサポート チケット (JSON)。 - コミュニティ フォーラムの投稿 (Delta テーブル)。 - Unity カタログに格納され、毎週更新されるデータ。 - 合計データ サイズ: 5 GB。 - 専任のドキュメント作成チームとサポート チームにより、一貫したデータ構造と品質が維持されています。 |
| パフォーマンス | - 許容できる最長待機時間。 - コストの制約。 - 予想される使用量とコンカレンシー。 |
- 最長待機時間の要件。 - コストの制約。 - 予想されるピーク時の負荷。 |
| 評価 | - 評価データセットの可用性。 - 品質メトリック。 - ユーザー フィードバックの収集。 |
- 各製品分野の専門家が、アウトプットのレビューと誤った回答の調整を支援し、評価データセットを作成します。 - ビジネス KPI。 - サポート チケット解決率の向上。 - サポート チケットごとのユーザー対応時間の短縮。 - 品質メトリック。 - LLM の判断による回答の正確性と関連性。 - LLM は評価の精度を判断します。 - ユーザーの賛成票または反対票。 - フィードバックの収集。 - Slack に評価機能が組み込まれ、サムズアップ/ダウンが可能になります。 |
| セキュリティ | - 機密データの処理。 - アクセス制御の要件。 |
- 機密性の高い顧客データを取得ソースに含めてはなりません。 - Databricks Community SSO によるユーザー認証。 |
| 展開 | - 既存のシステムとの統合。 - デプロイとバージョン管理。 |
- サポート チケット システムとの統合。 - Databricks Model Serving エンドポイントとしてデプロイされたチェーン。 |