ステップ 1. コード リポジトリのクローンとコンピューティングの作成
このセクションのサンプル コードは GitHub リポジトリを参照してください。 リポジトリ コードをテンプレートとして使用して、独自の AI アプリケーションを作成することもできます。
次の手順に従って、サンプル コードを Databricks ワークスペースに読み込み、アプリケーションのグローバル設定を構成します。
要件
- サーバーレス コンピューティングおよび Unity Catalog 対応の Azure Databricks ワークスペース。
- 既存の Mosaic AI ベクトル検索エンドポイント、または新しいベクトル検索エンドポイントを作成するためのアクセス許可 (この場合、セットアップ ノートブックで作成します)。
- 解析およびチャンクされたドキュメントとベクトル検索インデックスを含む出力 Delta テーブルが格納されている既存の Unity Catalog スキーマへの書き込みアクセス権限、または新しいカタログとスキーマを作成するためのアクセス許可 (この場合、セットアップ ノートブックで作成します)。
- インターネットにアクセスできる DBR 14.3 以降を実行している単一ユーザー クラスター。 必要な Python とシステム パッケージのダウンロードにはインターネット アクセスが必要です。 Databricks Runtime for Machine Learning を実行中のクラスターは使用しないでください。これらのチュートリアルでは Databricks Runtime ML と Python パッケージが競合するためです。
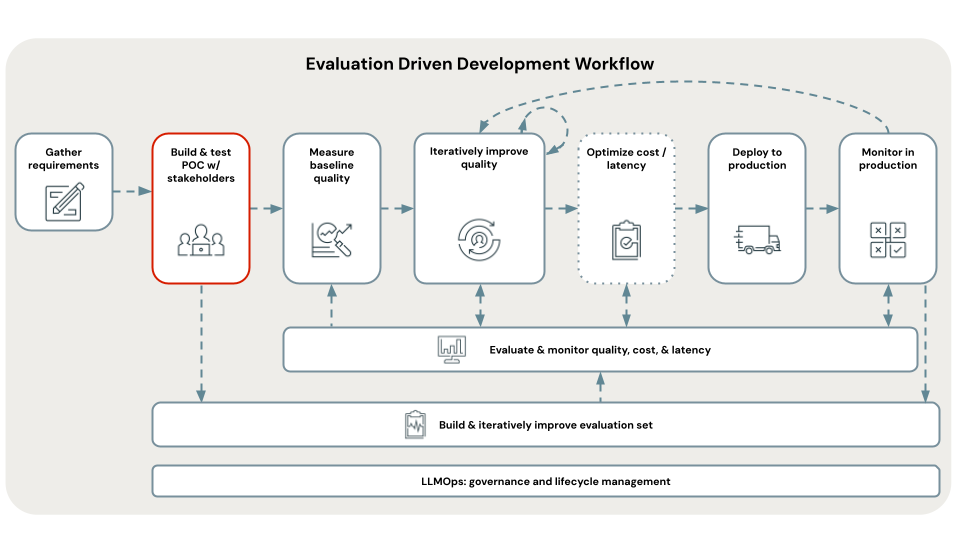
チュートリアル フロー図
この図は、このチュートリアルで使用する手順のフローを示しています。
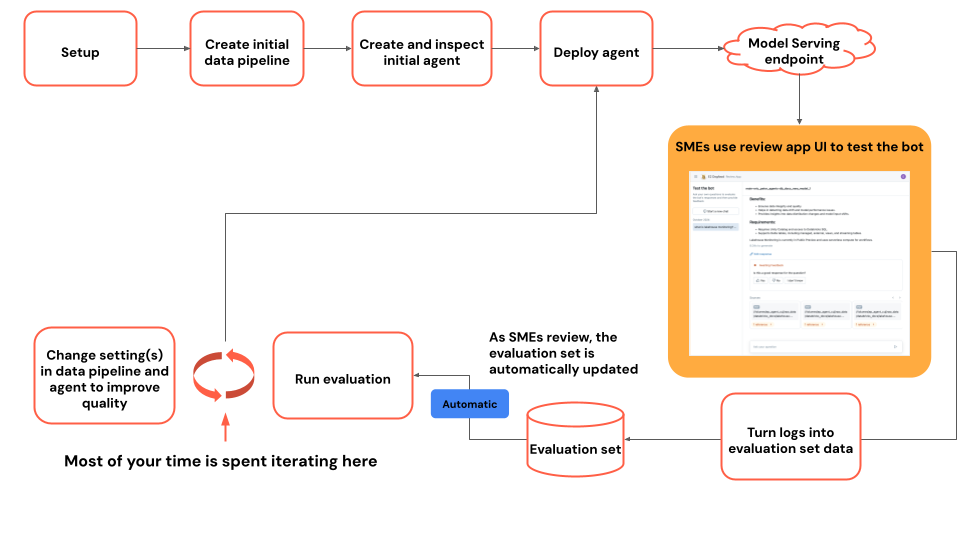
手順
Git フォルダー を使用して、このリポジトリをワークスペースにクローンします。
rag_app_sample_code/00_global_config ノートブックを開き、そこで設定を調整します。
# The name of the RAG application. This is used to name the chain's model in Unity Catalog and prepended to the output Delta tables and vector indexes RAG_APP_NAME = 'my_agent_app' # Unity Catalog catalog and schema where outputs tables and indexes are saved # If this catalog/schema does not exist, you need create catalog/schema permissions. UC_CATALOG = f'{user_name}_catalog' UC_SCHEMA = f'rag_{user_name}' ## Name of model in Unity Catalog where the POC chain is logged UC_MODEL_NAME = f"{UC_CATALOG}.{UC_SCHEMA}.{RAG_APP_NAME}" # Vector Search endpoint where index is loaded # If this does not exist, it will be created VECTOR_SEARCH_ENDPOINT = f'{user_name}_vector_search' # Source location for documents # You need to create this location and add files SOURCE_PATH = f"/Volumes/{UC_CATALOG}/{UC_SCHEMA}/source_docs"
次のステップ
「POC のデプロイ」に進みます。