SQL Server データベースから Azure Blob Storage にデータをコピーする
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure Data Factory ユーザー インターフェイス (UI) を使用して、SQL Server データベースから Azure Blob Storage にデータをコピーするデータ ファクトリ パイプラインを作成します。 セルフホステッド統合ランタイムを作成して使用すると、オンプレミス データ ストアとクラウド データ ストア間でデータを移動できます。
Note
この記事では、Data Factory の概要については詳しく取り上げません。 詳細については、Data Factory の概要に関するページをご覧ください。
このチュートリアルでは、以下の手順を実行します。
- データ ファクトリを作成します。
- セルフホステッド統合ランタイムを作成します。
- SQL Server と Azure Storage のリンクされたサービスを作成します。
- SQL Server と Azure BLOB のデータセットを作成します。
- コピー アクティビティでデータを移動するパイプラインを作成します。
- パイプラインの実行を開始します。
- パイプラインの実行を監視します。
前提条件
Azure サブスクリプション
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
Azure ロール
Data Factory インスタンスを作成するには、Azure へのサインインに使用するユーザー アカウントが、"共同作成者" または "所有者" ロールに属しているか、Azure サブスクリプションの "管理者" である必要があります。
サブスクリプションで自分が持っているアクセス許可を表示するには、Azure Portal に移動します。 右上隅にあるユーザー名を選択し、 [アクセス許可] を選択してください。 複数のサブスクリプションにアクセスできる場合は、適切なサブスクリプションを選択します。 ロールにユーザーを追加する手順の例については、「Azure portal を使用して Azure ロールを割り当てる」を参照してください。
SQL Server 2014、2016、2017
このチュートリアルでは、SQL Server データベースを "ソース" データ ストアとして使用します。 このチュートリアルで作成するデータ ファクトリ内のパイプラインは、この SQL Server データベース (ソース) から Blob Storage (シンク) にデータをコピーします。 SQL Server データベース内に emp という名前のテーブルを作成し、このテーブルにサンプル エントリをいくつか挿入します。
SQL Server Management Studio を起動します。 ご使用のマシンにまだインストールされていない場合は、「SQL Server Management Studio のダウンロード」にアクセスしてください。
自分の資格情報で SQL Server インスタンスに接続します。
サンプル データベースを作成します。 ツリー ビューで [データベース] を右クリックし、 [新しいデータベース] を選択します。
[新しいデータベース] ウィンドウで、データベースの名前を入力し、 [OK] を選択します。
emp テーブルを作成していくつかのサンプル データを挿入するために、次のクエリ スクリプトをデータベースに対して実行します。 ツリー ビューで、作成したデータベースを右クリックし、 [新しいクエリ] をクリックします。
CREATE TABLE dbo.emp ( ID int IDENTITY(1,1) NOT NULL, FirstName varchar(50), LastName varchar(50) ) GO INSERT INTO emp (FirstName, LastName) VALUES ('John', 'Doe') INSERT INTO emp (FirstName, LastName) VALUES ('Jane', 'Doe') GO
Azure ストレージ アカウント
このチュートリアルでは、コピー先/シンク データ ストアに汎用の Azure Storage アカウント (具体的には Blob Storage) を使用します。 汎用の Azure Storage アカウントがない場合は、「ストレージ アカウントの作成」をご覧ください。 このチュートリアルで作成するデータ ファクトリ内のパイプラインは、この SQL Server データベース (ソース) から Blob Storage (シンク) にデータをコピーします。
ストレージ アカウント名とアカウント キーの取得
このチュートリアルでは、ご利用のストレージ アカウントの名前とキーを使用します。 ご利用のストレージ アカウントの名前とキーを取得するには、次の手順を実行します。
Azure のユーザー名とパスワードを使用して、Azure Portal にサインインします。
左側のウィンドウで、 [すべてのサービス] を選択します。 「ストレージ」というキーワードでフィルタリングして、 [ストレージ アカウント] を選択します。
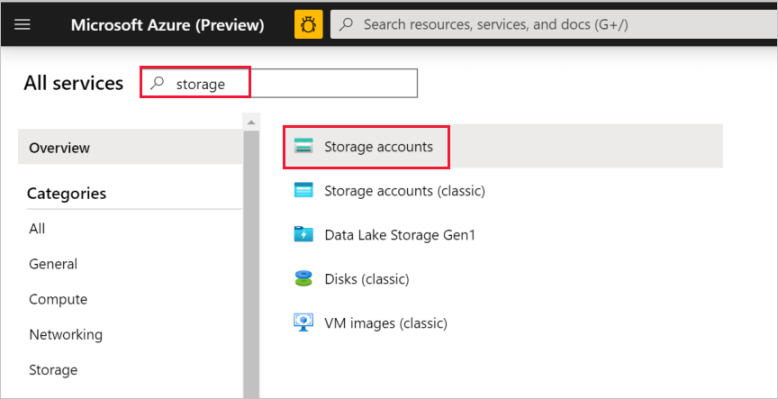
ストレージ アカウントの一覧で、必要に応じてご利用のストレージ アカウントをフィルターで抽出します。 次に、ストレージ アカウントを選択します。
[ストレージ アカウント] ウィンドウで [アクセス キー] を選択します。
[ストレージ アカウント名] ボックスと [key1] ボックスの値をコピーし、メモ帳などのエディターに貼り付けます。これらの値は、後でこのチュートリアルの中で使用します。
adftutorial コンテナーの作成
このセクションでは、adftutorial という名前の BLOB コンテナーを Blob Storage に作成します。
[ストレージ アカウント] ウィンドウで [概要] に移動し、 [コンテナー] を選択します。
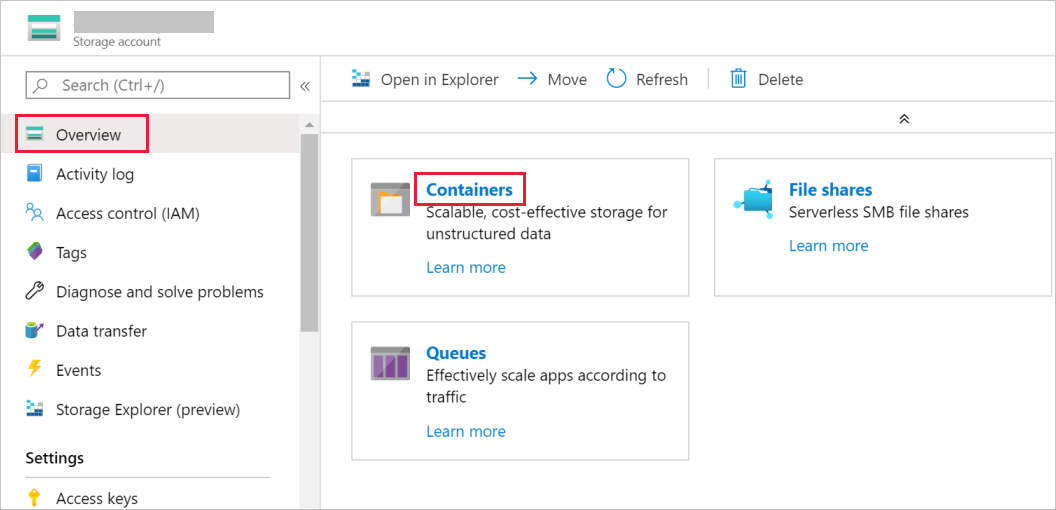
[コンテナー] ウィンドウで [+ コンテナー] を選択して新しいコンテナーを作成します。
[新しいコンテナー] ウィンドウの [名前] に「adftutorial」と入力します。 [作成] を選択します。
コンテナーの一覧で、作成した [adftutorial] を選択します。
adftutorial の [コンテナー] ウィンドウを開いたままにしておきます。 チュートリアルの最後で、このページを使用して出力を確認します。 このコンテナーには output フォルダーが Data Factory によって自動的に作成されます。手動で作成する必要はありません。
Data Factory の作成
この手順では、データ ファクトリを作成するほか、Data Factory UI を起動してそのデータ ファクトリにパイプラインを作成します。
Web ブラウザー (Microsoft Edge または Google Chrome) を開きます。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
![[新規] ペインでの Data Factory の選択](media/doc-common-process/new-azure-data-factory-menu.png)
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialDataFactory」と入力します。
データ ファクトリの名前は "グローバルに一意" にする必要があります。 名前フィールドで次のエラー メッセージが発生した場合は、データ ファクトリの名前を変更してください (yournameADFTutorialDataFactory など)。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関するページを参照してください。
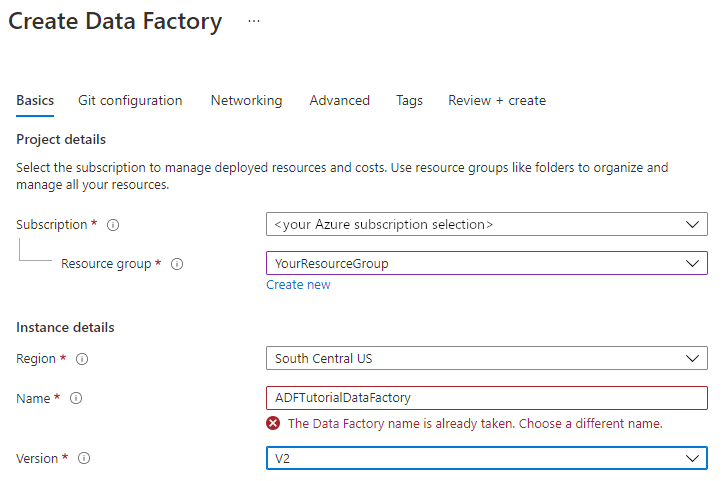
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] で、次の手順のいずれかを行います。
[Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
[新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
[バージョン] で、 [V2] を選択します。
[場所] で、データ ファクトリの場所を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 Data Factory によって使用されるデータ ストア (Storage、SQL Database など) やコンピューティング (Azure HDInsight など) は、他のリージョンに存在していてもかまいません。
[作成] を選択します
作成が完了すると、図に示されているような [Data Factory] ページが表示されます。
![[Open Azure Data Factory Studio] タイルを含む、Azure Data Factory のホーム ページ。](../reusable-content/ce-skilling/azure/media/data-factory/data-factory-home-page.png)
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブで Data Factory UI を起動します。
パイプラインを作成する
Azure Data Factory のホーム ページで、 [Orchestrate](調整) を選択します。 パイプラインが自動的に作成されます。 ツリー ビューのパイプラインとそのエディターが開かれるのがわかります。
![[オーケストレーション] ボタンが強調表示されたデータ ファクトリのホームページを示すスクリーンショット。](media/tutorial-data-flow/orchestrate.png)
[全般] パネルの [プロパティ] で、 [名前] に「SQLServerToBlobPipeline」を指定します。 次に、右上隅にある [プロパティ] アイコンをクリックしてパネルを折りたたみます。
[アクティビティ] ツール ボックスで [Move & Transform]\(移動と変換\) を展開します。 パイプライン デザイン サーフェイスに [コピー] アクティビティをドラッグ アンド ドロップします。 アクティビティの名前を「CopySqlServerToAzureBlobActivity」に設定します。
[プロパティ] ウィンドウの [ソース] タブに移動し、 [+ 新規] を選択します。
[新しいデータセット] ダイアログ ボックスで、SQL Server を検索します。 [SQL Server] を選択し、 [続行] を選択します。
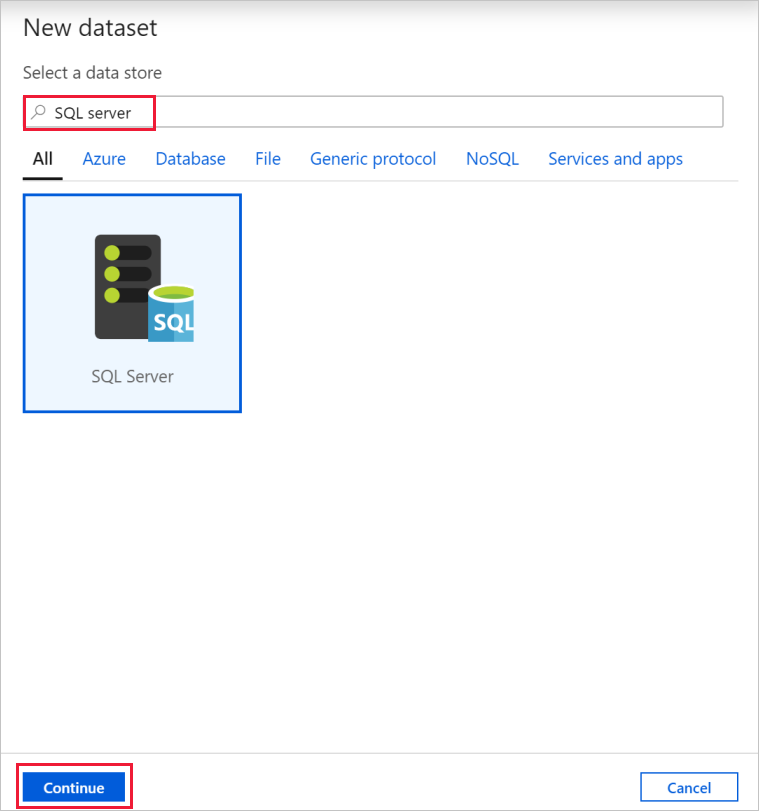
[プロパティの設定] ダイアログ ボックスの [名前] に、「SqlServerDataset」と入力します。 [リンクされたサービス] で [+ 新規] を選択します。 この手順でソース データ ストア (SQL Server データベース) への接続を作成します。
[New Linked Service](新しいリンクされたサービス) ダイアログ ボックスで、 [名前] に「SqlServerLinkedService」と入力します。 [Connect via integration runtime](統合ランタイム経由で接続) で [+新規] を選択します。 このセクションでは、セルフホステッド統合ランタイムを作成し、SQL Server データベースがあるオンプレミスのマシンに関連付けます。 セルフホステッド統合ランタイムは、マシンの SQL Server データベースから Blob Storage にデータをコピーするコンポーネントです。
[Integration Runtime セットアップ] ダイアログ ボックスで [Self-Hosted](セルフホステッド) を選択し、 [続行] を選択します。
[名前] に「TutorialIntegrationRuntime」と入力します。 [作成] を選択します。
[設定] の [Click here to launch the express setup for this computer](このコンピューターで高速セットアップを起動するにはここをクリック) を選択します。 この操作により、統合ランタイムがマシンにインストールされ、Data Factory に登録されます。 別の方法として、手動セットアップのオプションを使用できます。インストール ファイルをダウンロードして実行し、キーを使用して統合ランタイムを登録します。
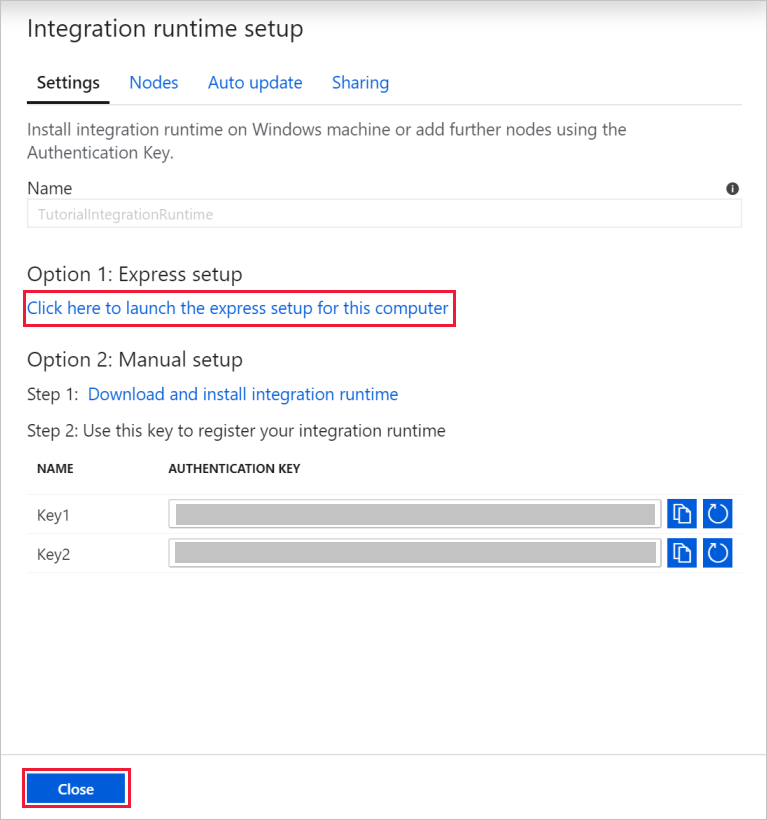
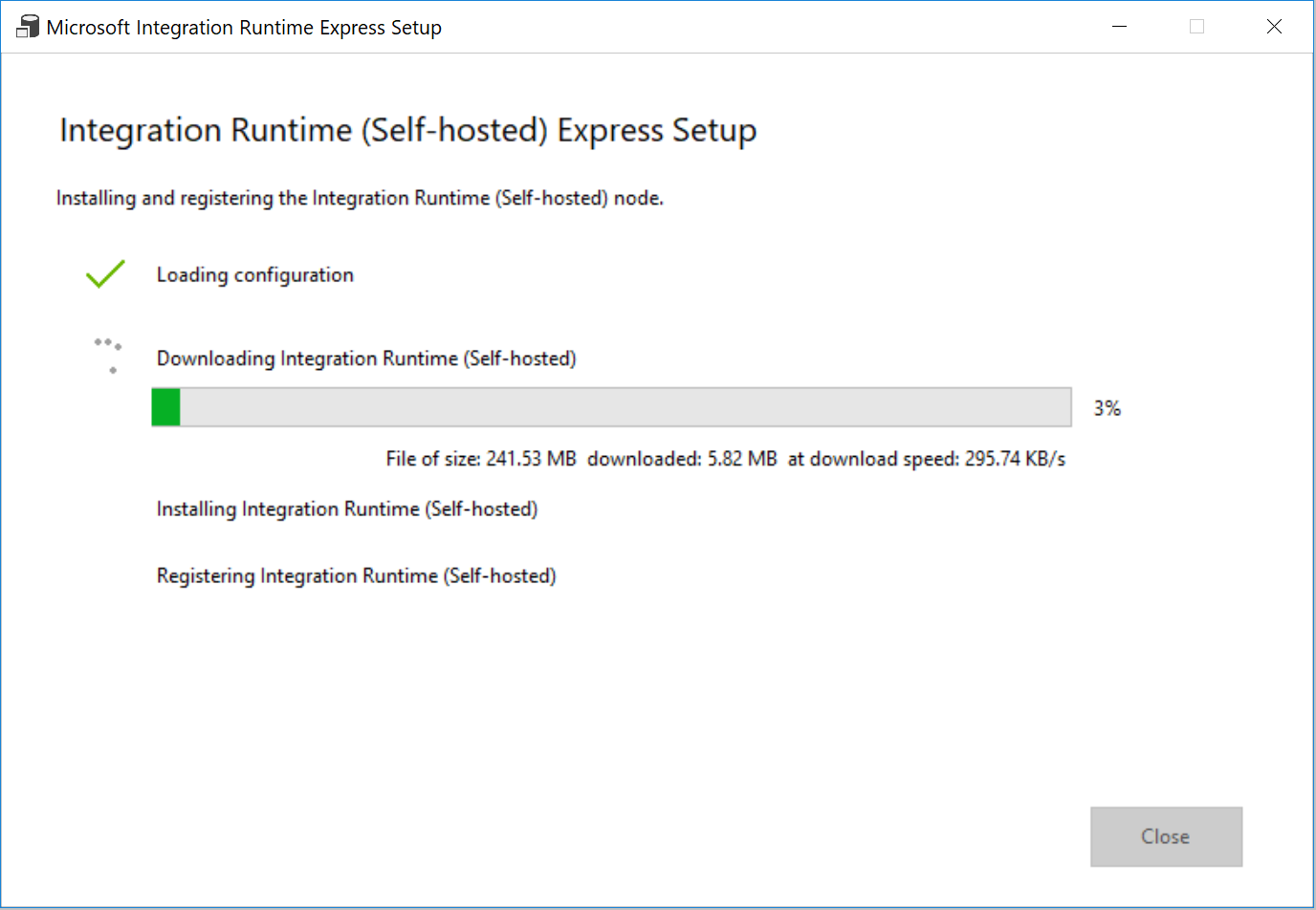
[Integration Runtime (セルフホステッド) 高速セットアップ] ウィンドウで、処理が完了したら [閉じる] を選択します。
[New linked service (SQL Server)](新しいリンクされたサービス (SQL Server)) ダイアログ ボックスで、 [Connect via integration runtime](統合ランタイム経由で接続) の TutorialIntegrationRuntime が選択されていることを確認します。 その後、次の手順を行います。
a. [名前] に「SqlServerLinkedService」と入力します。
b. [サーバー名] に SQL Server インスタンスの名前を入力します。
c. [データベース名] に、emp テーブルが含まれたデータベースの名前を入力します。
d. Data Factory が SQL Server データベースへの接続に使用する適切な認証の種類を [認証の種類] で選択します。
e. [ユーザー名] と [パスワード] に、ユーザー名とパスワードを入力します。 必要に応じて、ユーザー名として mydomain\myuser を使います。
f. [接続テスト] を選択します。 この手順は、作成したセルフホステッド統合ランタイムを使用して Data Factory が SQL Server データベースに接続できることを確認するために行います。
g. リンクされたサービスを保存するには、 [作成] を選択します。

リンクされたサービスが作成されると、SqlServerDataset の [プロパティの設定] ページに戻ります。 次の手順を実行します。
a. [リンクされたサービス] に SqlServerLinkedService が表示されていることを確認します。
b. [テーブル名] で [dbo].[emp] を選択します。
c. [OK] を選択します。
SQLServerToBlobPipeline のタブに移動するか、またはツリービューの SQLServerToBlobPipeline を選択します。
[プロパティ] ウィンドウの一番下にある [シンク] タブに移動し、 [+ 新規] を選択します。
[新しいデータセット] ダイアログ ボックスで、 [Azure Blob Storage] を選択します。 その後 [続行] を選択します。
[形式の選択] ダイアログ ボックスで、データ形式の種類を選択します。 その後 [続行] を選択します。

[プロパティの設定] ダイアログ ボックスで、[名前] に「AzureBlobDataset」と入力します。 [リンクされたサービス] ボックスの横にある [+ 新規] をクリックします。
[New Linked Service (Azure Blob Storage)](新しいリンクされたサービス (Azure Blob Storage)) ダイアログ ボックスで、名前として「AzureStorageLinkedService」と入力し、 [ストレージ アカウント] 名の一覧からご自身のストレージ アカウントを選択します。 接続をテストし、 [作成] を選択して、リンクされたサービスをデプロイします。
リンクされたサービスが作成されると、 [プロパティの設定] ページに戻ります。 [OK] を選択します。
シンク データセットを開きます。 [接続] タブで、次の手順を実行します。
a. [リンクされたサービス] で AzureStorageLinkedService が選択されていることを確認します。
b. [ファイルのパス] で、コンテナーまたはディレクトリの部分に「adftutorial/fromonprem」と入力します。 adftutorial コンテナーに出力フォルダーが存在しない場合、Data Factory によって自動的に出力フォルダーが作成されます。
c. ファイル部分については、 [動的なコンテンツの追加] を選択します。
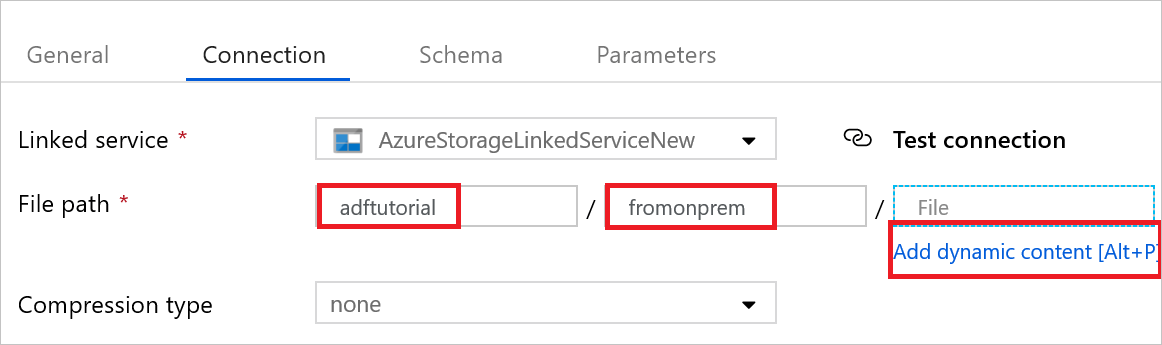
d.
@CONCAT(pipeline().RunId, '.txt')を追加し、 [完了] を選択します。 この操作で、ファイルの名前が PipelineRunID.txt に変更されます。パイプラインが開かれているタブに移動するか、ツリー ビューでパイプラインを選択します。 [Sink Dataset](シンク データセット) で AzureBlobDataset が選択されていることを確認します。
パイプライン設定を検証するには、パイプラインのツール バーにある [検証] を選択します。 [Pipe validation output](パイプ検証出力) を閉じるには、>> アイコンを選びます。
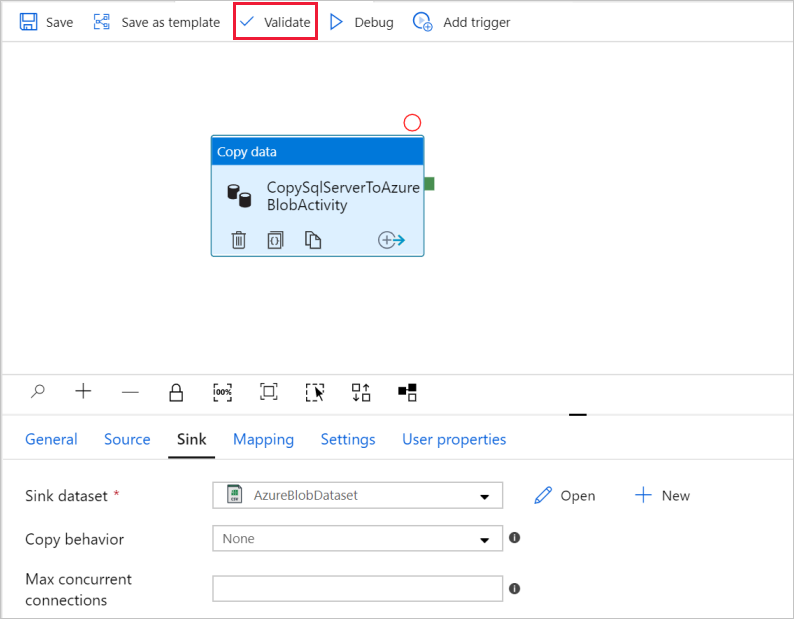
作成したエンティティを Data Factory に発行するには、 [すべて発行] を選択します。
発行が完了したことを示すポップアップが表示されるまで待ちます。 発行の状態を確認するには、ウィンドウの上部にある [通知の表示] リンクを選択します。 通知ウィンドウを閉じるには、 [閉じる] を選択します。
パイプラインの実行をトリガーする
パイプラインのツール バーの [トリガーの追加] を選択し、 [Trigger Now](今すぐトリガー) を選択します。
パイプラインの実行を監視します
[監視] タブに移動します。前の手順で手動でトリガーしたパイプラインを確認します。
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] の [SQLServerToBlobPipeline] リンクを選択します。

[アクティビティの実行] ページで [詳細] (眼鏡アイコン) リンクを選択し、コピー操作の詳細を確認します。 再度パイプラインの実行ビューに移動するには、一番上にある [すべてのパイプラインの実行] を選択します。
出力を検証する
このパイプラインは、adftutorial BLOB コンテナーに対して fromonprem という名前の出力フォルダーを自動的に作成します。 出力フォルダーに [pipeline().RunId].txt ファイルがあることを確認してください。
関連するコンテンツ
このサンプルのパイプラインは、Blob Storage 内のある場所から別の場所にデータをコピーするものです。 以下の方法を学習しました。
- データ ファクトリを作成します。
- セルフホステッド統合ランタイムを作成します。
- SQL Server と Storage のリンクされたサービスを作成します。
- SQL Server と Blob Storage のデータセットを作成します。
- コピー アクティビティでデータを移動するパイプラインを作成します。
- パイプラインの実行を開始します。
- パイプラインの実行を監視します。
Data Factory でサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。
次のチュートリアルに進んで、ソースからコピー先にデータを一括コピーする方法について学習しましょう。