Azure portal で Azure Data Factory を使用して複数のテーブルを一括コピーする
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure SQL Database から Azure Synapse Analytics に多数のテーブルをコピーする方法について説明します。 同じパターンは他のコピー シナリオでも適用できます。 たとえば、SQL Server や Oracle から Azure SQL Database、Azure Synapse Analytics、Azure BLOB にテーブルをコピーしたり、BLOB から Azure SQL Database テーブルにさまざまなパスをコピーしたりする作業が該当します。
注意
Azure Data Factory を初めて使用する場合は、「Azure Data Factory の概要」を参照してください。
このチュートリアルは大まかに次の手順で構成されます。
- データ ファクトリを作成します。
- Azure SQL Database、Azure Synapse Analytics、および Azure Storage のリンクされたサービスを作成します。
- Azure SQL Database および Azure Synapse Analytics データセットを作成します。
- コピーするテーブルを検索するためのパイプラインと、実際のコピー操作を実行するためのもう 1 つのパイプラインを作成します。
- パイプラインの実行を開始します。
- パイプラインとアクティビティの実行を監視します。
このチュートリアルでは、Azure Portal を使用します。 その他のツールまたは SDK を使ってデータ ファクトリを作成する方法については、クイックスタートを参照してください。
エンド ツー エンド ワークフロー
このシナリオでは、Azure Synapse Analytics にコピーする必要のあるテーブルが Azure SQL Database に多数存在します。 以下の図は、パイプラインのワークフロー ステップを論理的な発生順に並べたものです。

- 1 つ目のパイプラインでは、シンク データ ストアにコピーするテーブルの一覧が検索されます。 代わりに、シンク データ ストアにコピーするすべてのテーブルが列挙されたメタデータ テーブルを用意する方法もあります。 次に、1 つ目のパイプラインによって 2 つ目のパイプラインがトリガーされ、データベース内の各テーブルを反復処理しながらデータのコピー操作が実行されます。
- 実際のコピーは 2 つ目のパイプラインによって実行されます。 このパイプラインは、テーブルの一覧をパラメーターとして受け取ります。 その一覧の各テーブルについて、Azure SQL Database 内の特定のテーブルを Azure Synapse Analytics 内の該当するテーブルにコピーします。この処理には、パフォーマンスを最大限に高めるために、Blob Storage と PolyBase によるステージング コピーが使用されます。 この例では、1 つ目のパイプラインからパラメーターの値としてテーブルの一覧が渡されます。
Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
前提条件
- Azure Storage アカウント。 この Azure ストレージ アカウントは、一括コピー操作のステージング BLOB ストレージとして使用されます。
- Azure SQL データベース。 ソース データが格納されているデータベースです。 Azure SQL Database のデータベースの作成に関する記事に従い、Adventure Works LT サンプル データを使って SQL Database にデータベースを作成します。 このチュートリアルでは、このサンプル データベースからすべてのテーブルを Azure Synapse Analytics にコピーします。
- Azure Synapse Analytics。 SQL データベースからコピーされたデータは、このデータ ウェアハウスに格納されます。 Azure Synapse Analytics ワークスペースがない場合は、「Azure Synapse Analytics の使用を開始する」の記事の作成手順を参照してください。
SQL サーバーにアクセスするための Azure サービス
SQL Database と Azure Synapse Analytics の両方について、SQL サーバーへのアクセスを Azure サービスに許可します。 サーバーで [Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] 設定をオンにしてください。 この設定により、Data Factory サービスで Azure SQL Database からデータを読み取ったり、Azure Synapse Analytics にデータを書き込んだりすることができます。
この設定を確認して有効にするには、サーバーで [セキュリティ] > [ファイアウォールと仮想ネットワーク] の順に移動して、[Azure サービスおよびリソースにこのサーバーへのアクセスを許可する] を [オン] に設定します。
Data Factory の作成
Web ブラウザー (Microsoft Edge または Google Chrome) を起動します。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
Azure ポータルにアクセスします。
Azure portal の左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] の順に選択します。
![[新規] ペインでの Data Factory の選択](media/doc-common-process/new-azure-data-factory-menu.png)
[新しいデータ ファクトリ] ページで、 [名前] に「ADFTutorialBulkCopyDF」と入力します。
Azure データ ファクトリの名前は グローバルに一意にする必要があります。 [名前] フィールドで次のエラーが発生した場合は、データ ファクトリの名前を変更してください (yournameADFTutorialBulkCopyDF など)。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関する記事を参照してください。
Data factory name "ADFTutorialBulkCopyDF" is not availableデータ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] について、次の手順のいずれかを行います。
[Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
[新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、 リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
バージョンとして [V2] を選択します。
データ ファクトリの 場所 を選択します。 現在 Data Factory が利用できる Azure リージョンの一覧については、次のページで目的のリージョンを選択し、 [分析] を展開して [Data Factory] を探してください。リージョン別の利用可能な製品 データ ファクトリで使用するデータ ストア (Azure Storage、Azure SQL Database など) やコンピューティング (HDInsight など) は他のリージョンに配置できます。
Create をクリックしてください。
作成後、 [リソースに移動] を選択して、 [Data factory] ページに移動します。
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブで Data Factory UI アプリケーションを起動します。
リンクされたサービスを作成します
データ ストアやコンピューティングをデータ ファクトリにリンクするには、リンクされたサービスを作成します。 リンクされたサービスは、Data Factory サービスが実行時にデータ ストアに接続するために使用する接続情報を持っています。
このチュートリアルでは、ご自分のデータ ファクトリに Azure SQL Database、Azure Synapse Analytics、および Azure Blob Storage の各データ ストアをリンクします。 Azure SQL Database はソース データ ストアです。 Azure Synapse Analytics はシンク (コピー先) データ ストアです。 データは、Azure Blob Storage にステージングされてから、PolyBase を使用して Azure Synapse Analytics に読み込まれます。
ソース Azure SQL Database のリンクされたサービスを作成する
この手順では、Azure SQL Database のデータベースをデータ ファクトリに接続するためのリンクされたサービスを作成します。
左ペインから [管理] タブを開きます。
[リンクされたサービス] ページの [+ 新規] を選択して、リンクされたサービスを新規作成します。
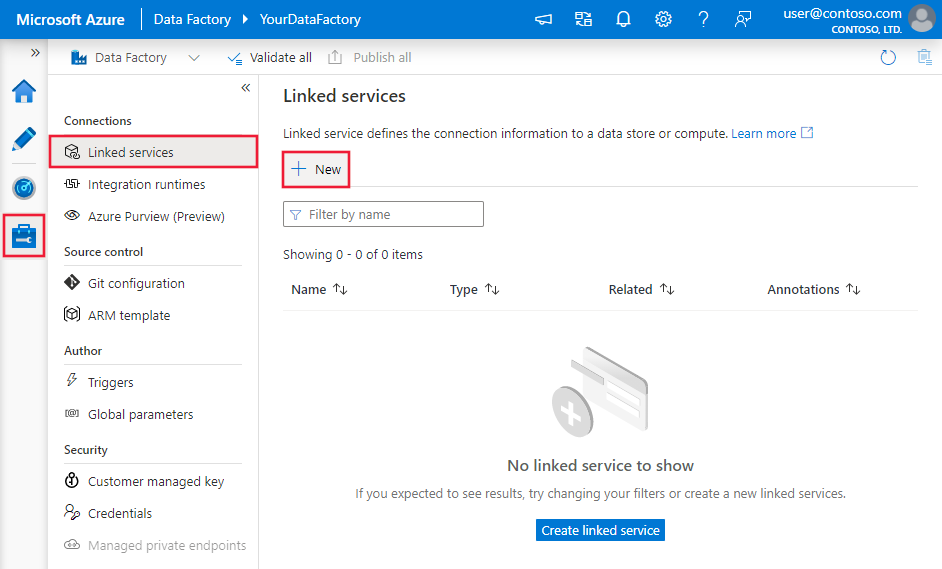
[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure SQL Database] を選択し、 [続行] をクリックします。
[New Linked Service (Azure SQL Database)] (新しいリンクされたサービス (Azure SQL Database)) ウィンドウで、次の手順を実行します。
a. [名前] に「AzureSqlDatabaseLinkedService」と入力します。
b. [サーバー名] で、サーバーを選択します
c. [データベース名] で、データベースを選択します。
d. [ユーザー名] に、データベースに接続するユーザーの名前を入力します。
e. [パスワード] に、そのユーザーのパスワードを入力します。
f. 指定した情報を使用してデータベースへの接続をテストするために、 [テスト接続] をクリックします。
g. [作成] をクリックして、リンクされたサービスを保存します。
シンク Azure Synapse Analytics のリンクされたサービスを作成する
[接続] タブで、再度ツールバーの [+ 新規] をクリックします。
[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure Synapse Analytics] を選択し、 [続行] をクリックします。
[New Linked Service (Azure Synapse Analytics)](新しいリンクされたサービス (Azure Synapse Analytics)) ウィンドウで、次の手順を実行します。
a. [名前] に「AzureSqlDWLinkedService」と入力します。
b. [サーバー名] で、サーバーを選択します
c. [データベース名] で、データベースを選択します。
d. [ユーザー名] に、データベースに接続するユーザーの名前を入力します。
e. [パスワード] に、そのユーザーのパスワードを入力します。
f. 指定した情報を使用してデータベースへの接続をテストするために、 [テスト接続] をクリックします。
g. Create をクリックしてください。
ステージング Azure Storage のリンクされたサービスを作成する
このチュートリアルでは、PolyBase でコピーのパフォーマンスを高めるために、中間ステージング領域として Azure BLOB ストレージを使用しています。
[接続] タブで、再度ツールバーの [+ 新規] をクリックします。
[New Linked Service](新しいリンクされたサービス) ウィンドウで [Azure Blob Storage] を選択し、 [続行] をクリックします。
[New Linked Service (Azure Blob Storage)] (新しいリンクされたサービス (Azure Blob Storage)) ウィンドウで、次の手順を実行します。
a. [名前] に「AzureStorageLinkedService」と入力します。
b. [ストレージ アカウント名] で、使用する Azure ストレージ アカウントを選択します。c. Create をクリックしてください。
データセットを作成する
このチュートリアルでは、データの格納場所を指定するための、ソースとシンクのデータセットを作成します。
入力データセット AzureSqlDatabaseDataset は、AzureSqlDatabaseLinkedService を参照します。 このリンクされたサービスには、データベースに接続するための接続文字列が指定されています。 データセットには、ソース データが含まれているデータベースとテーブルの名前を指定します。
出力データセット AzureSqlDWDataset は、AzureSqlDWLinkedService を参照します。 リンクされたサービスは、Azure Synapse Analytics に接続するための接続文字列を指定します。 データセットには、データのコピー先となるデータベースとテーブルを指定します。
このチュートリアルでは、データセットの定義にソースとコピー先の SQL テーブルをハード コーディングしません。 代わりに、実行時に ForEach アクティビティで、テーブルの名前をコピー アクティビティに渡します。
ソース SQL Database のデータセットを作成する
左側のペインにある [作成者] タブを選択します。
左側のペインにある +(正符号)、次に [データセット] の順に選択します。
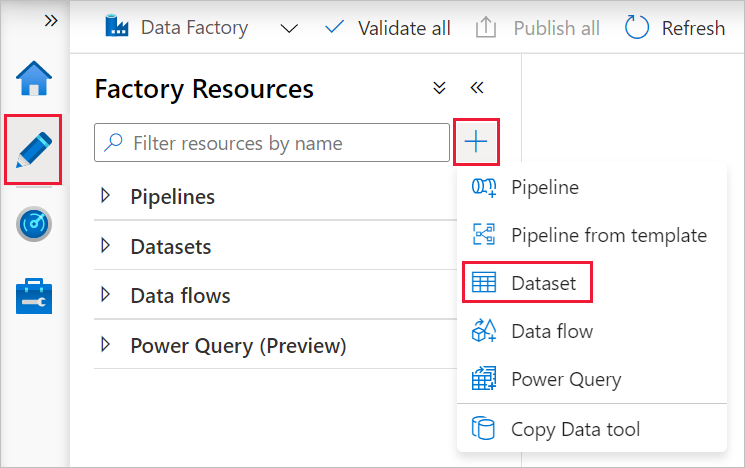
[新しいデータセット] ウィンドウで [Azure SQL Database] を選択し、 [続行] を選択します。
[Set properties] (プロパティの設定) ウィンドウの [名前] の下に、「AzureSqlDatabaseDataset」と入力します。 [リンクされたサービス] の下で [AzureSqlDatabaseLinkedService] を選択します。 次に、 [OK] をクリックします
[接続] タブに切り替えて、 [テーブル] で任意のテーブルを選択します。 このテーブルはダミーのテーブルです。 パイプラインを作成するときに、ソース データセットに対するクエリを指定します。 このクエリは、データベースからデータを抽出するために使用します。 または、 [編集] チェック ボックスをオンにして、テーブル名として「dbo.dummyName」と入力してもかまいません。
シンク Azure Synapse Analytics 用のデータセットを作成する
左ウィンドウで [+](プラス記号) をクリックし、 [データセット] をクリックします。
[新しいデータセット] ウィンドウで [Azure Synapse Analytics] を選択し、 [続行] をクリックします。
[Set properties] (プロパティの設定) ウィンドウの [名前] の下に、「AzureSqlDWDataset」と入力します。 [リンクされたサービス] で [AzureSqlDWLinkedService] を選択します。 次に、 [OK] をクリックします
[パラメーター] タブに切り替えて [+ 新規] をクリックし、パラメーター名として「DWTableName」と入力します。 [+ 新規] をもう一度クリックし、パラメーター名として「DWSchema」と入力します。 ページからこの名前をコピーして貼り付ける場合は、DWTableName および DWSchema の末尾に末尾空白文字がないことを確認してください。
[接続] タブに切り替えます。
[テーブル] で、 [編集] オプションをオンにします。 最初の入力ボックスを選択し、下の [動的なコンテンツの追加] リンクをクリックします。 [動的なコンテンツの追加] ページの [パラメーター] の下の [DWSchema] をクリックします。これで、自動的に上部の式テキストボックスに
@dataset().DWSchemaが入力されます。次に、 [完了] をクリックします。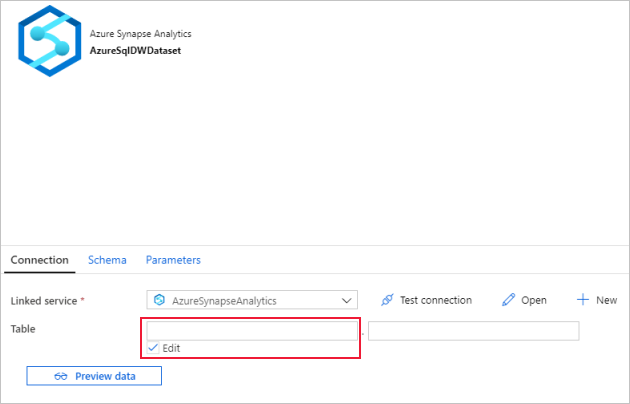
2 つ目の入力ボックスを選択し、下の [動的なコンテンツの追加] リンクをクリックします。 [動的なコンテンツの追加] ページの [パラメーター] の下の [DWTAbleName] をクリックします。これで、自動的に上部の式テキストボックスに
@dataset().DWTableNameが入力されます。次に、 [完了] をクリックします。データセットの tableName プロパティに設定される値は、DWSchema および DWTableName パラメーターの引数として渡されます。 ForEach アクティビティによってテーブルのリストが反復処理され、コピー アクティビティに 1 つずつ渡されます。
パイプラインを作成する
このチュートリアルでは、2 つのパイプラインを作成します。IterateAndCopySQLTables と GetTableListAndTriggerCopyData です。
GetTableListAndTriggerCopyData パイプラインは、次の 2 つのアクションを実行します。
- Azure SQL Database システム テーブルを検索してコピーするテーブルの一覧を取得します。
- パイプライン IterateAndCopySQLTables をトリガーし、実際のデータ コピーを実行します。
IterateAndCopySQLTables パイプラインは、テーブルの一覧をパラメーターとして受け取ります。 その一覧の各テーブルについて、ステージング コピーと PolyBase を使って、Azure SQL Database 内のテーブルから Azure Synapse Analytics にデータがコピーされます。
パイプライン IterateAndCopySQLTables を作成する
左ウィンドウで [+](プラス記号) をクリックし、 [パイプライン] をクリックします。
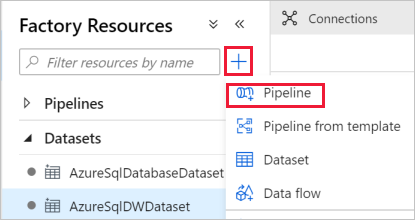
[全般] パネルの [プロパティ] の下で、 [名前] に「IterateAndCopySQLTables」と指定します。 次に、右上隅にある [プロパティ] アイコンをクリックしてパネルを折りたたみます。
[パラメーター] タブに切り替えて、次の手順を実行します。
a. [+ 新規] をクリックします。
b. [名前] に、パラメーター名として「tableList」と入力します。
c. [種類] に [配列] を選択します。
[アクティビティ] ツール ボックスで [Iteration & Conditions]\(繰り返しと条件\) を展開し、パイプライン デザイナー画面に [ForEach] アクティビティをドラッグ アンド ドロップします。 [アクティビティ] ツールボックスで、アクティビティを検索することもできます。
a. 下部にある [全般] タブで、 [名前] に「IterateSQLTables」と入力します。
b. [設定] タブに切り替えて、 [項目] の入力ボックスをクリックしてから、下の [動的なコンテンツの追加] リンクをクリックします。
c. [動的なコンテンツの追加] ページで、 [システム変数] と [関数] のセクションを折りたたんで、 [パラメーター] の tableList をクリックします。これで、自動的に上部の式テキスト ボックスに
@pipeline().parameter.tableListが入力されます。 [完了] をクリックします。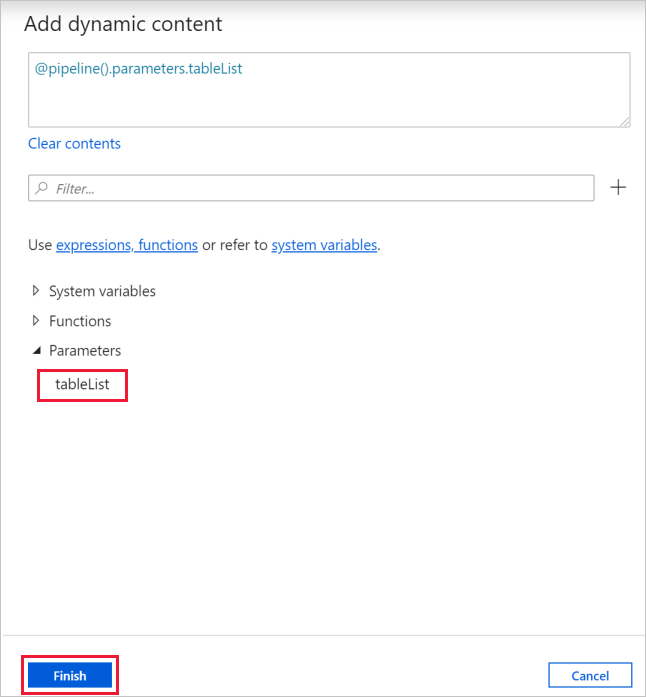
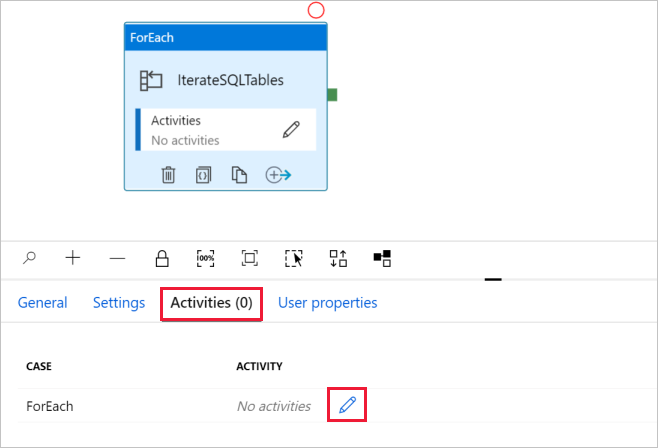
d. [アクティビティ] タブに切り替えて鉛筆アイコンをクリックし、子アクティビティを ForEach アクティビティに追加します。
[アクティビティ] ツールボックスで [Move & Transfer]\(移動および転送\) を展開し、[データのコピー] アクティビティをパイプライン デザイナー画面にドラッグ アンド ドロップします。 ウィンドウの上部に階層リンク メニューがあります。 IterateAndCopySQLTable はパイプライン名で、IterateSQLTables は ForEach アクティビティ名です。 現在のデザイナー画面には、アクティビティの範囲が表示されています。 ForEach エディターからパイプライン エディターにデザイナー画面を切り替えるには、階層リンク メニューのリンクをクリックできます。
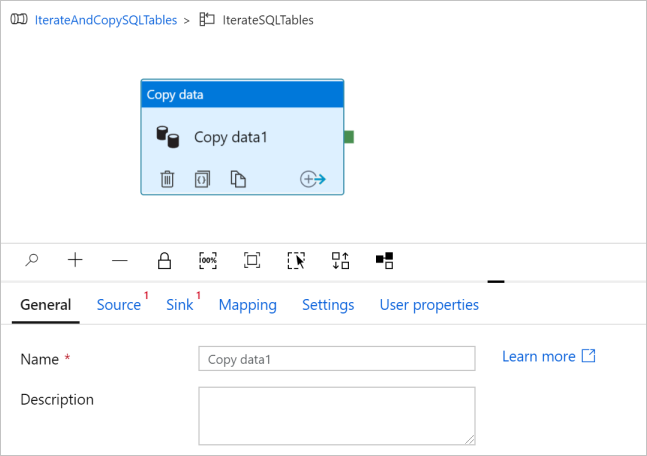
[ソース] タブに切り替えて、次の手順を実行します。
[Source Dataset](ソース データセット) で「AzureSqlDatabaseDataset」を選択します。
[クエリの使用] で [クエリ] オプションを選択します。
[クエリ] 入力ボックスをクリックして、下の [動的なコンテンツの追加] を選択します。次に、[クエリ] に次の式を入力して、[完了] を選択します。
SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]
[シンク] タブに切り替えて、次の手順を実行します。
[Sink Dataset](シンク データセット) で「AzureSqlDWDataset」を選択します。
DWTableName パラメーターの [値] の入力ボックスをクリックして、下の [動的なコンテンツの追加] を選択します。次に、
@item().TABLE_NAME式をスクリプトとして入力して、[完了] を選択します。DWSchema パラメーターの [値] の入力ボックスをクリックして、下の [動的なコンテンツの追加] を選択します。次に、
@item().TABLE_SCHEMA式をスクリプトとして入力して、[完了] を選択します。[Copy method](コピー メソッド) で [PolyBase] を選択します。
[使用型の既定] オプションをオフにします。
[Table option](テーブル オプション) の既定の設定は [None](なし) です。 まだシンク Azure Synapse Analytics にテーブルを作成していない場合は、 [テーブルの自動作成] オプションを有効にしてください。コピー アクティビティにより、ソース データに基づいて自動的にテーブルが作成されます。 詳細については、「シンク テーブルの自動作成」を参照してください。
[Pre-copy Script](コピー前スクリプト) 入力ボックスをクリックして、下の [動的なコンテンツの追加] を選択します。次に、以下の式をスクリプトとして入力し、[完了] を選択します。
IF EXISTS (SELECT * FROM [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]) TRUNCATE TABLE [@{item().TABLE_SCHEMA}].[@{item().TABLE_NAME}]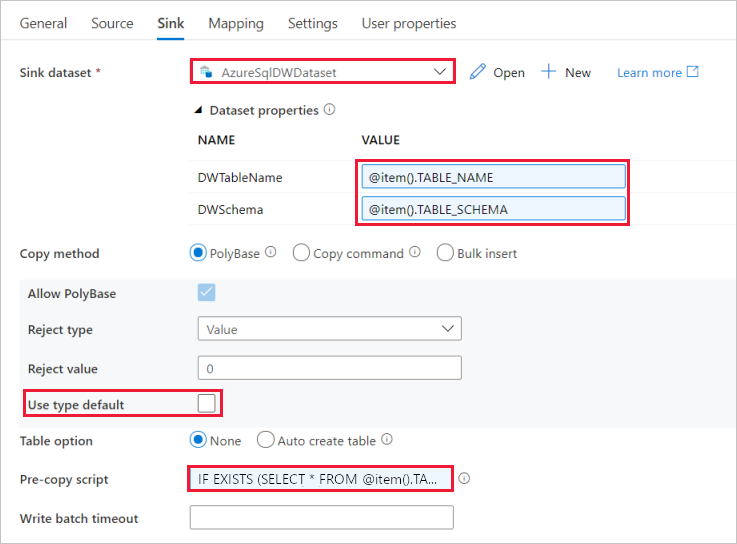
[設定] タブに切り替えて、次の手順を実行します。
- [Enable Staging] (ステージングを有効にする) のチェック ボックスをオンにします。
- [Store Account Linked Service](ストア アカウントのリンクされたサービス) で [AzureStorageLinkedService] を選択します。
パイプライン設定を検証するには、上部のパイプライン ツール バーにある [検証] をクリックします。 検証エラーがないことを確認します。 [Pipeline Validation Report](パイプライン検証レポート) を閉じるには、二重山かっこ (>>) をクリックします。
パイプライン GetTableListAndTriggerCopyData を作成する
このパイプラインは、次の 2 つのアクションを実行します。
- Azure SQL Database システム テーブルを検索してコピーするテーブルの一覧を取得します。
- パイプライン "IterateAndCopySQLTables" をトリガーして実際にデータのコピーを実行します。
パイプラインを作成する手順を次に示します。
左ウィンドウで [+](プラス記号) をクリックし、 [パイプライン] をクリックします。
[プロパティ] の下の [全般] パネルで、パイプラインの名前を「GetTableListAndTriggerCopyData」に変更します。
[アクティビティ] ツール ボックスで [全般] を展開し、パイプライン デザイナー画面に [検索] アクティビティをドラッグ アンド ドロップして、次のステップを実行します。
- [名前] に「LookupTableList」と入力します。
- [説明] に「データベースからテーブル リストを取得する」と入力します。
[設定] タブに切り替えて、次の手順を実行します。
[Source Dataset](ソース データセット) で「AzureSqlDatabaseDataset」を選択します。
[クエリの使用] で [クエリ] を選択します。
[クエリ] に次の SQL クエリを入力します。
SELECT TABLE_SCHEMA, TABLE_NAME FROM information_schema.TABLES WHERE TABLE_TYPE = 'BASE TABLE' and TABLE_SCHEMA = 'SalesLT' and TABLE_NAME <> 'ProductModel'[First row only](先頭行のみ) フィールドのチェック ボックスをオフにします。
![検索アクティビティ - [設定] ページ](media/tutorial-bulk-copy-portal/lookup-settings-page.png)
[アクティビティ] ツール ボックスからパイプライン デザイナー画面に [パイプラインの実行] アクティビティをドラッグ アンド ドロップし、名前を「TriggerCopy」に設定します。
[検索] アクティビティを [パイプラインの実行] アクティビティに接続するために、[検索] アクティビティの横に付いている緑の四角を [パイプラインの実行] アクティビティの左へドラッグします。
[Execute Pipeline](パイプラインの実行) アクティビティの [設定] タブに切り替え、以下の手順を実行します。
[Invoked pipeline](呼び出されたパイプライン) で [IterateAndCopySQLTables] を選択します。
[Wait on completion](完了時に待機) チェック ボックスをオフにします。
[パラメーター] セクションで、[値] の入力ボックスをクリックして、下の [動的なコンテンツの追加] を選択します。次に、「
@activity('LookupTableList').output.value」をテーブル名の値として入力して、[完了] を選択します。 これで、2 つ目のパイプラインへの入力として検索アクティビティの結果一覧が設定されます。 結果一覧には、コピー先にコピーする必要があるデータが格納されたテーブルの一覧が含まれています。![パイプラインの実行アクティビティ - [設定] ページ](media/tutorial-bulk-copy-portal/execute-pipeline-settings-page.png)
パイプラインを検証するために、ツール バーの [検証] をクリックします。 検証エラーがないことを確認します。 [Pipeline Validation Report](パイプライン検証レポート) を閉じるには、>> をクリックします。
エンティティ (データセットやパイプラインなど) を Data Factory サービスに発行するには、ウィンドウの上部にある [すべて公開] をクリックします。 発行が成功するまで待機します。
パイプラインの実行をトリガーする
パイプライン GetTableListAndTriggerCopyData に移動し、上部のパイプライン ツール バーで [トリガーの追加] 、 [Trigger Now] (今すぐトリガー) の順にクリックします。
[Pipeline run](パイプラインの実行) ページで [完了] を選択します。
パイプラインの実行を監視します
[監視] タブに切り替えます。ソリューションの両方のパイプラインが実行されるまで、 [最新の情報に更新] をクリックします。 状態が [成功] になるまで一覧を更新します。
GetTableListAndTriggerCopyData パイプラインに関連付けられているアクティビティの実行を表示するには、対応するパイプライン名のリンクをクリックします。 このパイプラインの実行の 2 つのアクティビティの実行が表示されます。
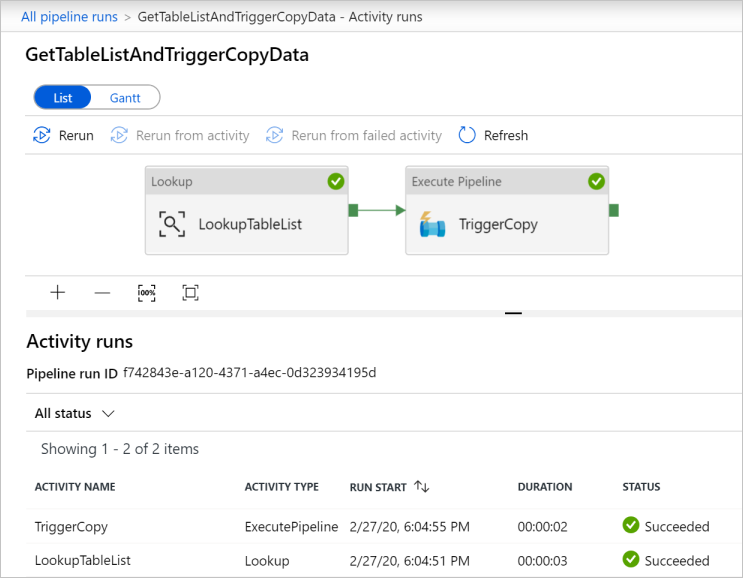
[検索] アクティビティの出力を表示するには、 [アクティビティ名] 列で、そのアクティビティの横にある [出力] リンクをクリックします。 [出力] ウィンドウは最大化したり元のサイズに戻したりできます。 確認したら、 [X] をクリックして [出力] ウィンドウを閉じます。
{ "count": 9, "value": [ { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Customer" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Product" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductModelProductDescription" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "ProductCategory" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "Address" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "CustomerAddress" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderDetail" }, { "TABLE_SCHEMA": "SalesLT", "TABLE_NAME": "SalesOrderHeader" } ], "effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)", "effectiveIntegrationRuntimes": [ { "name": "DefaultIntegrationRuntime", "type": "Managed", "location": "East US", "billedDuration": 0, "nodes": null } ] }[Pipeline Runs](パイプラインの実行) ビューに戻るには、階層リンク メニューの上部にある [すべてのパイプラインの実行] リンクをクリックします。 [パイプライン名] 列の [IterateAndCopySQLTables] リンクをクリックすると、そのパイプラインのアクティビティの実行が表示されます。 検索アクティビティの出力には、テーブルごとにコピー アクティビティの実行が 1 回ずつあることがわかります。
このチュートリアルで使用したターゲット Azure Synapse Analytics にデータがコピーされていることを確認します。
関連するコンテンツ
このチュートリアルでは、以下の手順を実行しました。
- データ ファクトリを作成します。
- Azure SQL Database、Azure Synapse Analytics、および Azure Storage のリンクされたサービスを作成します。
- Azure SQL Database および Azure Synapse Analytics データセットを作成します。
- コピーするテーブルを検索するためのパイプラインと、実際のコピー操作を実行するためのもう 1 つのパイプラインを作成します。
- パイプラインの実行を開始します。
- パイプラインとアクティビティの実行を監視します。
次のチュートリアルに進んで、ソースからコピー先にデータを増分コピーする方法について学習しましょう。