Azure portal を使用して Azure SQL Database から Azure Blob Storage にデータを増分読み込みする
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
このチュートリアルでは、Azure SQL Database 内のテーブルから Azure Blob Storage に差分データを読み込むパイプラインを使用して Azure データ ファクトリを作成します。
このチュートリアルでは、以下の手順を実行します。
- 基準値を格納するためのデータ ストアを準備します。
- データ ファクトリを作成します。
- リンクされたサービスを作成します。
- ソース データセット、シンク データセット、および基準値データセットを作成します。
- パイプラインを作成します。
- パイプラインを実行します。
- パイプラインの実行を監視します。
- 結果の確認
- ソースにデータを追加します。
- パイプラインを再実行します。
- 2 回目のパイプラインの実行を監視します
- 2 回目の実行の結果を確認します
概要
ソリューションの概略図を次に示します。

このソリューションを作成するための重要な手順を次に示します。
基準値列を選択する。 ソース データ ストアのいずれか 1 つの列を選択します。実行ごとに新しいレコードまたは更新されたレコードを切り分ける目的で使用されます。 通常、行が作成または更新されたときに常にデータが増える列を選択します (last_modify_time、ID など)。 この列の最大値が基準値として使用されます。
基準値を格納するためのデータ ストアを準備する。 このチュートリアルでは、SQL データベースに基準値を格納します。
次のワークフローを含んだパイプラインを作成する。
このソリューションのパイプラインには、次のアクティビティがあります。
- 2 つのルックアップ アクティビティを作成する。 1 つ目のルックアップ アクティビティは、前回の基準値を取得するために使用します。 2 つ目のルックアップ アクティビティは、新しい基準値を取得するために使用します。 これらの基準値は、コピー アクティビティに渡されます。
- コピー アクティビティを作成する。これは基準値列の値がかつての基準値より大きく、かつ新しい基準値よりも小さい行をソース データ ストアからコピーするアクティビティです。 その差分データが、ソース データ ストアから新しいファイルとして BLOB ストレージにコピーされます。
- ストアド プロシージャ― アクティビティを作成する。これはパイプラインの次回実行に備えて基準値を更新するためのアクティビティです。
Azure サブスクリプションをお持ちでない場合は、開始する前に無料アカウントを作成してください。
前提条件
- Azure SQL データベース。 ソース データ ストアとして使うデータベースです。 Azure SQL Database のデータベースがない場合の作成手順については、Azure SQL Database のデータベースの作成に関するページを参照してください。
- Azure Storage。 シンク データ ストアとして使用する BLOB ストレージです。 Azure ストレージ アカウントがない場合の作成手順については、「ストレージ アカウントの作成」を参照してください。 adftutorial という名前のコンテナーを作成します。
SQL データベースにデータ ソース テーブルを作成する
SQL Server Management Studio を開きます。 サーバー エクスプローラーで目的のデータベースを右クリックし、 [新しいクエリ] を選択します。
SQL データベースに対して次の SQL コマンドを実行し、
data_source_tableという名前のテーブルをデータ ソース ストアとして作成します。create table data_source_table ( PersonID int, Name varchar(255), LastModifytime datetime ); INSERT INTO data_source_table (PersonID, Name, LastModifytime) VALUES (1, 'aaaa','9/1/2017 12:56:00 AM'), (2, 'bbbb','9/2/2017 5:23:00 AM'), (3, 'cccc','9/3/2017 2:36:00 AM'), (4, 'dddd','9/4/2017 3:21:00 AM'), (5, 'eeee','9/5/2017 8:06:00 AM');このチュートリアルでは、LastModifytime を基準値列として使用します。 データ ソース ストアに格納されているデータを次の表に示します。
PersonID | Name | LastModifytime -------- | ---- | -------------- 1 | aaaa | 2017-09-01 00:56:00.000 2 | bbbb | 2017-09-02 05:23:00.000 3 | cccc | 2017-09-03 02:36:00.000 4 | dddd | 2017-09-04 03:21:00.000 5 | eeee | 2017-09-05 08:06:00.000
高基準値の格納用としてもう 1 つテーブルを SQL データベースに作成する
SQL データベースに対して次の SQL コマンドを実行し、基準値の格納先として
watermarktableという名前のテーブルを作成します。create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );ソース データ ストアのテーブル名と組み合わせて高基準値の既定値を設定します。 このチュートリアルでは、テーブル名は data_source_table です。
INSERT INTO watermarktable VALUES ('data_source_table','1/1/2010 12:00:00 AM')watermarktableテーブル内のデータを確認します。Select * from watermarktable出力:
TableName | WatermarkValue ---------- | -------------- data_source_table | 2010-01-01 00:00:00.000
SQL データベースにストアド プロシージャを作成する
次のコマンドを実行して、SQL データベースにストアド プロシージャを作成します。
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
Data Factory の作成
Web ブラウザー (Microsoft Edge または Google Chrome) を起動します。 現在、Data Factory の UI がサポートされる Web ブラウザーは Microsoft Edge と Google Chrome だけです。
左側のメニューで、 [リソースの作成]>[統合]>[Data Factory] を選択します。
![[新規] ペインでの Data Factory の選択](media/doc-common-process/new-azure-data-factory-menu.png)
[新しいデータ ファクトリ] ページで、 [名前] に「ADFIncCopyTutorialDF」と入力します。
Azure Data Factory の名前は、グローバルに一意にする必要があります。 赤い感嘆符と次のエラーが表示される場合は、データ ファクトリの名前を変更して (yournameADFIncCopyTutorialDF など)、作成し直してください。 Data Factory アーティファクトの名前付け規則については、Data Factory の名前付け規則に関する記事を参照してください。
データ ファクトリ名 "ADFIncCopyTutorialDF" は利用できません
データ ファクトリを作成する Azure サブスクリプションを選択します。
[リソース グループ] について、次の手順のいずれかを行います。
[Use existing (既存のものを使用)] を選択し、ドロップダウン リストから既存のリソース グループを選択します。
[新規作成] を選択し、リソース グループの名前を入力します。
リソース グループの詳細については、 リソース グループを使用した Azure のリソースの管理に関するページを参照してください。
バージョンとして [V2] を選択します。
データ ファクトリの 場所 を選択します。 サポートされている場所のみがドロップダウン リストに表示されます。 データ ファクトリで使用するデータ ストア (Azure Storage、Azure SQL Database、Azure SQL Managed Instance など) とコンピューティング (HDInsight など) は他のリージョンに配置できます。
Create をクリックしてください。
作成が完了すると、図に示されているような [Data Factory] ページが表示されます。
![[Open Azure Data Factory Studio] タイルを含む、Azure Data Factory のホーム ページ。](../reusable-content/ce-skilling/azure/media/data-factory/data-factory-home-page.png)
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブで Azure Data Factory ユーザー インターフェイス (UI) を起動します。
パイプラインを作成する
このチュートリアルでは、2 つのルックアップ アクティビティ、1 つのコピー アクティビティ、そして 1 つのストアド プロシージャ アクティビティを 1 つに連結したパイプラインを作成します。
Data Factory UI のホーム ページで、 [Orchestrate](調整) タイルをクリックします。
![[オーケストレーション] ボタンが強調表示されたデータ ファクトリのホームページを示すスクリーンショット。](media/tutorial-data-flow/orchestrate.png)
[全般] パネルの [プロパティ] で、 [名前] に「IncrementalCopyPipeline」を指定します。 次に、右上隅にある [プロパティ] アイコンをクリックしてパネルを折りたたみます。
古い基準値を取得するための最初の検索アクティビティを追加します。 [アクティビティ] ツールボックスで [General](一般) を展開し、パイプライン デザイナー画面に [検索] アクティビティをドラッグ アンド ドロップします。 アクティビティの名前を LookupOldWaterMarkActivity に変更します。
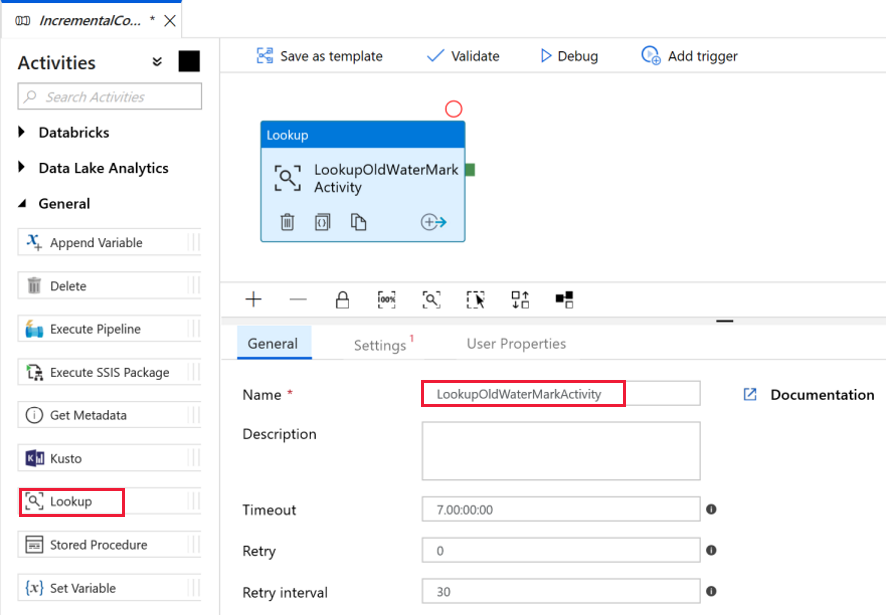
[設定] タブに切り替えて、 [Source Dataset](ソース データセット) の [+ 新規] をクリックします。 この手順では、watermarktable 内のデータを表すデータセットを作成します。 このテーブルには、前のコピー操作で使用されていた古い基準が含まれています。
[新しいデータセット] ウィンドウで [Azure SQL Database] を選択し、 [続行] をクリックします。 データセット用の新しいウィンドウが表示されます。
データセットの [プロパティの設定] ウィンドウで、 [名前] に「WatermarkDataset」と入力します。
[リンクされたサービス] で [新規] を選択して、次の手順を実行します。
[名前] に「AzureSqlDatabaseLinkedService」と入力します。
[サーバー名] で、サーバーを選択します。
ドロップダウン リストから [データベース名] を選択します。
[ユーザー名] と [パスワード] を入力します。
SQL データベースへの接続をテストするために、 [テスト接続] をクリックします。
[完了] をクリックします。
[リンクされたサービス] で AzureSqlDatabaseLinkedService が選択されていることを確認します。
![[New linked service]\(新しいリンクされたサービス\) ウィンドウ](media/tutorial-incremental-copy-portal/azure-sql-linked-service-settings.png)
[完了] を選択します。
[接続] タブで、 [テーブル] に [dbo].[watermarktable] を選択します。 テーブル内のデータをプレビューする場合は、 [データのプレビュー] をクリックします。
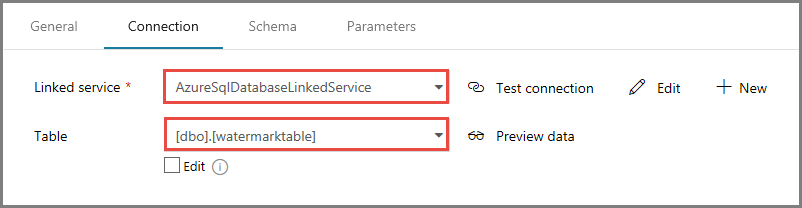
上部のパイプライン タブをクリックするか、左側のツリー ビューでパイプラインの名前をクリックして、パイプライン エディターに切り替えます。 [検索] アクティビティのプロパティ ウィンドウで、 [Source Dataset](ソース データセット) フィールドで [WatermarkDataset] が選択されていることを確認します。
[アクティビティ] ツールボックスで [General](一般) を展開し、パイプライン デザイナー画面にもう一つの [検索] アクティビティをドラッグ アンド ドロップし、プロパティ ウィンドウの [General](一般) タブで名前を「LookupNewWaterMarkActivity」に設定します。 この検索アクティビティは、ターゲットにコピーされるソース データを持つテーブルから新しい基準値を取得します。
2 つ目の [検索] アクティビティのプロパティ ウィンドウで [設定] タブに切り替え、 [新規] をクリックします。 新しい基準値 (LastModifyTime の最大値) が含まれているソース テーブルを指すデータセットを作成します。
[新しいデータセット] ウィンドウで [Azure SQL Database] を選択し、 [続行] をクリックします。
[プロパティの設定] ウィンドウで、 [名前] に「SourceDataset」と入力します。 [リンクされたサービス] で [AzureSqlDatabaseLinkedService] を選択します。
[テーブル] で [dbo].[data_source_table] を選択します。 チュートリアルの後の方で、このデータセットに対してクエリを指定します。 クエリは、この手順で指定するテーブルで優先されます。
[完了] を選択します。
上部のパイプライン タブをクリックするか、左側のツリー ビューでパイプラインの名前をクリックして、パイプライン エディターに切り替えます。 [検索] アクティビティのプロパティ ウィンドウで、 [Source Dataset](ソース データセット) フィールドで [SourceDataset] が選択されていることを確認します。
[クエリの使用] フィールドで [クエリ] を選択し、次のクエリを入力します。単に data_source_table で LastModifytime の最大値を選択しています。 また、 [First row only](先頭行のみ) チェック ボックスがオンになっていることを確認してください。
select MAX(LastModifytime) as NewWatermarkvalue from data_source_table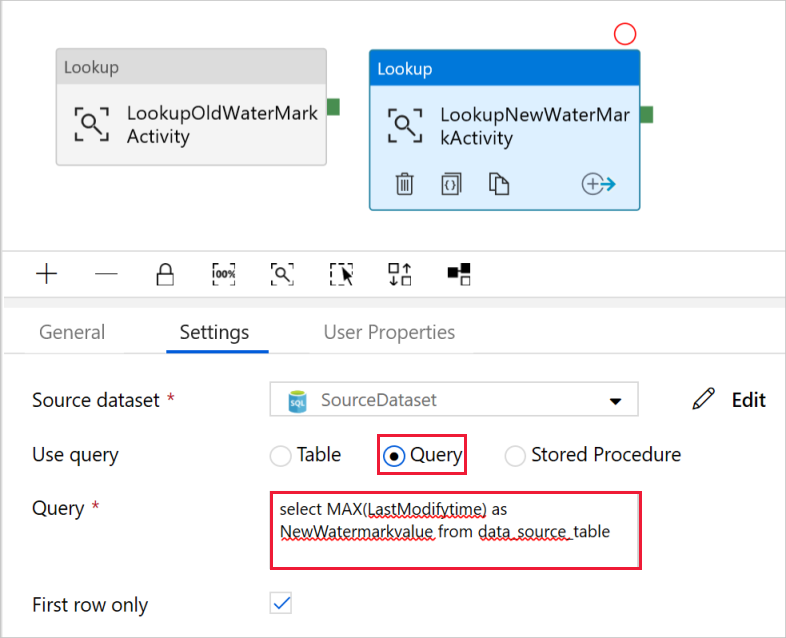
[アクティビティ] ツールボックスで [Move & Transform]\(移動と変換\) を展開し、[アクティビティ] ツールボックスから [コピー] アクティビティをドラッグ アンド ドロップして、名前を「IncrementalCopyActivity」に設定します。
検索アクティビティにアタッチされている緑のボタンをコピー アクティビティにドラッグして、両方の検索アクティビティをコピー アクティビティに接続します。 コピー アクティビティの境界線の色が青に変わったら、マウス ボタンを離します。
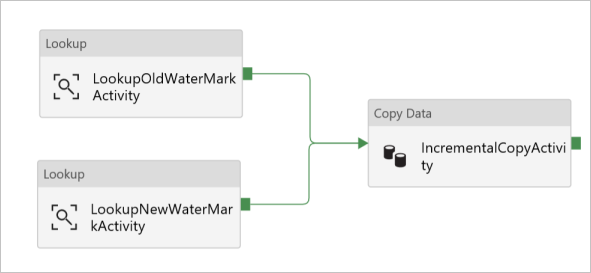
[コピー アクティビティ] を選択し、 [プロパティ] ウィンドウにアクティビティのプロパティが表示されることを確認します。
[プロパティ] ウィンドウで [ソース] タブに切り替え、以下の手順を実行します。
[Source Dataset](ソース データセット) フィールドで [SourceDataset] を選択します。
[クエリの使用] フィールドで [クエリ] を選択します。
[クエリ] フィールドに次の SQL クエリを入力します。
select * from data_source_table where LastModifytime > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and LastModifytime <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'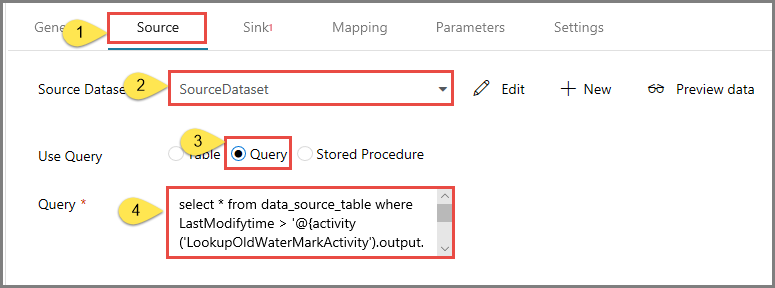
[シンク] タブに切り替えて、 [Sink Dataset](シンク データセット) フィールドの [+ 新規] をクリックします。
このチュートリアルでは、シンク データ ストアの種類は Azure Blob Storage です。 そのため、 [新しいデータセット] ウィンドウで [Azure Blob Storage] を選択し、 [続行] をクリックします。
[形式の選択] ウィンドウでデータの形式の種類を選択し、 [続行] をクリックします。
[プロパティの設定] ウィンドウで、 [名前] に「SinkDataset」と入力します。 [リンクされたサービス] で [+ 新規] を選択します。 この手順では、Azure Blob Storage への接続 (リンクされたサービス) を作成します。
[New Linked Service (Azure Blob Storage)] (新しいリンクされたサービス (Azure Blob Storage)) ウィンドウで、次の手順を実行します。
- [名前] に「AzureStorageLinkedService」と入力します。
- [ストレージ アカウント名] で、使用する Azure ストレージ アカウントを選択します。
- 接続をテストし、 [完了] をクリックします。
[プロパティの設定] ウィンドウで、 [リンクされたサービス] に [AzureStorageLinkedService] が選択されていることを確認します。 [完了] を選択します。
SinkDataset の [接続] タブに移動して、次の手順を実行します。
- [ファイル パス] フィールドに「adftutorial/incrementalcopy」と入力します。 adftutorial は BLOB コンテナー名であり、incrementalcopy はフォルダー名です。 このスニペットは、BLOB ストレージに adftutorial という名前の BLOB コンテナーがあることを前提としています。 このコンテナーが存在しない場合は作成するか、既存のコンテナーの名前を設定してください。 Azure Data Factory は、出力フォルダー incrementalcopy が存在しない場合は、自動的に作成します。 [ファイル パス] の [参照] ボタンを使用して、BLOB コンテナー内のフォルダーに移動することもできます。
- [ファイル パス] フィールドのファイル部分で [動的なコンテンツの追加 [Alt+P]] を選択し、表示されたウィンドウで「
@CONCAT('Incremental-', pipeline().RunId, '.txt')」と入力します。 [完了] を選択します。 ファイル名は、式を使用して動的に生成されます。 各パイプラインの実行には、一意の ID があります。 コピー アクティビティは、実行 ID を使用して、ファイル名を生成します。
上部のパイプライン タブをクリックするか、左側のツリー ビューでパイプラインの名前をクリックして、パイプライン エディターに切り替えます。
[アクティビティ] ツールボックスで [General](一般) を展開し、 [アクティビティ] ツールボックスからパイプライン デザイナー画面に [ストアド プロシージャ] アクティビティをドラッグ アンド ドロップします。 [コピー] アクティビティの緑 (成功) の出力を [ストアド プロシージャ] アクティビティに接続します。
パイプライン デザイナーで [ストアド プロシージャ アクティビティ] を選択し、その名前を StoredProceduretoWriteWatermarkActivity に変更します。
[SQL Account](SQL アカウント) タブに切り替えて、 [リンクされたサービス] で [AzureSqlDatabaseLinkedService] を選択します。
[ストアド プロシージャ] タブに切り替えて、次の手順を実行します。
[ストアド プロシージャ名] に [usp_write_watermark] を選択します。
ストアド プロシージャのパラメーターの値を指定するには、 [Import parameter](インポート パラメーター) をクリックし、各パラメーターに次の値を入力します。
名前 Type 値 LastModifiedtime DateTime @{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue} TableName String @{activity('LookupOldWaterMarkActivity').output.firstRow.TableName} 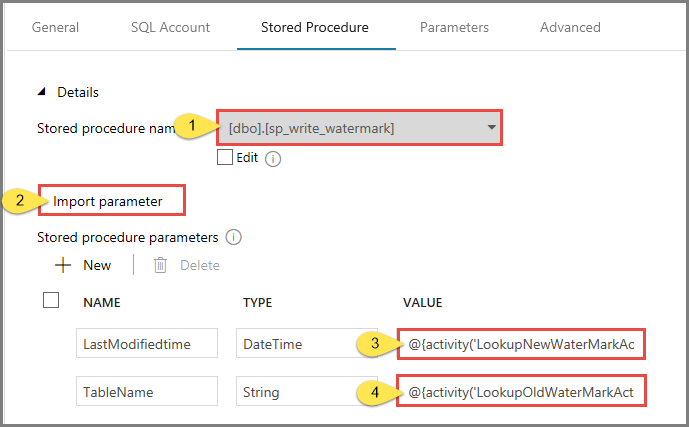
パイプライン設定を検証するには、ツール バーの [検証] をクリックします。 検証エラーがないことを確認します。 [Pipeline Validation Report](パイプライン検証レポート) ウィンドウを閉じるには、>> をクリックします。
[すべて公開] ボタンを選択して、エンティティ (リンクされたサービス、データセット、およびパイプライン) を Azure Data Factory サービスに発行します。 発行が成功したというメッセージが表示されるまで待機します。
パイプラインの実行をトリガーする
ツール バーの [トリガーの追加] をクリックし、 [Trigger Now](今すぐトリガー) をクリックします。
[Pipeline Run](パイプラインの実行) ウィンドウで [完了] を選択します。
パイプラインの実行を監視します
左側で [監視] タブに切り替えます。 手動トリガーによってトリガーされたパイプラインの実行の状態を確認します。 [パイプライン名] 列のリンクを使用して、実行の詳細を表示したりパイプラインを再実行したりできます。
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列のリンクを選択します。 アクティビティの実行の詳細を確認するには、 [ACTIVITY NAME](アクティビティ名) 列の [詳細] リンク (眼鏡アイコン) を選択します。 再度パイプラインの実行ビューに移動するには、一番上にある [すべてのパイプラインの実行] を選択します。 表示を更新するには、 [最新の情報に更新] を選択します。
結果の確認
Azure Storage Explorer などのツールを使用して、Azure Storage アカウントに接続します。 adftutorial コンテナーの incrementalcopy フォルダーに出力ファイルが作成されていることを確認します。
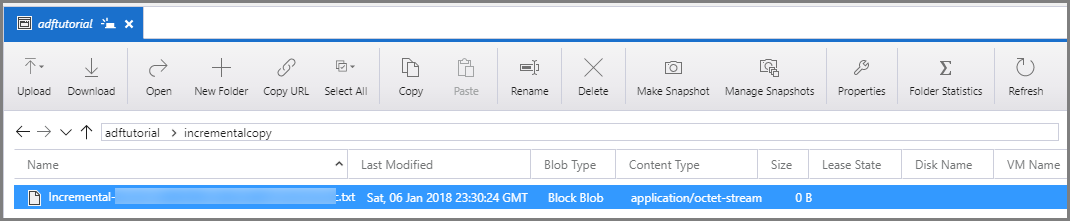
出力ファイルを開き、すべてのデータが data_source_table から BLOB ファイルにコピーされていることを確認します。
1,aaaa,2017-09-01 00:56:00.0000000 2,bbbb,2017-09-02 05:23:00.0000000 3,cccc,2017-09-03 02:36:00.0000000 4,dddd,2017-09-04 03:21:00.0000000 5,eeee,2017-09-05 08:06:00.0000000watermarktableの最新の値をチェックします。 基準値が更新されたことを確認できます。Select * from watermarktable出力内容は次のとおりです。
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-05 8:06:00.000 |
ソースにデータを追加する
データベース (データ ソース ストア) に新しいデータを挿入します。
INSERT INTO data_source_table
VALUES (6, 'newdata','9/6/2017 2:23:00 AM')
INSERT INTO data_source_table
VALUES (7, 'newdata','9/7/2017 9:01:00 AM')
データベース内の更新されたデータは次のとおりです。
PersonID | Name | LastModifytime
-------- | ---- | --------------
1 | aaaa | 2017-09-01 00:56:00.000
2 | bbbb | 2017-09-02 05:23:00.000
3 | cccc | 2017-09-03 02:36:00.000
4 | dddd | 2017-09-04 03:21:00.000
5 | eeee | 2017-09-05 08:06:00.000
6 | newdata | 2017-09-06 02:23:00.000
7 | newdata | 2017-09-07 09:01:00.000
もう一つのパイプラインの実行をトリガーする
[編集] タブに切り替えます。デザイナーでパイプラインが開かれていない場合は、ツリー ビューでパイプラインをクリックします。
ツール バーの [トリガーの追加] をクリックし、 [Trigger Now](今すぐトリガー) をクリックします。
2 回目のパイプラインの実行を監視します
左側で [監視] タブに切り替えます。 手動トリガーによってトリガーされたパイプラインの実行の状態を確認します。 [パイプライン名] 列のリンクを使用して、アクティビティの詳細を表示したりパイプラインを再実行したりできます。
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列のリンクを選択します。 アクティビティの実行の詳細を確認するには、 [ACTIVITY NAME](アクティビティ名) 列の [詳細] リンク (眼鏡アイコン) を選択します。 再度パイプラインの実行ビューに移動するには、一番上にある [すべてのパイプラインの実行] を選択します。 表示を更新するには、 [最新の情報に更新] を選択します。
2 つ目の出力を検証する
BLOB ストレージで、別のファイルが作成されたことを確認します。 このチュートリアルでは、
Incremental-<GUID>.txtが新しいファイルの名前になります。 このファイルを開くと、2 行のレコードが確認できます。6,newdata,2017-09-06 02:23:00.0000000 7,newdata,2017-09-07 09:01:00.0000000watermarktableの最新の値をチェックします。 基準値が再び更新されたことを確認できます。Select * from watermarktableサンプル出力:
| TableName | WatermarkValue | | --------- | -------------- | | data_source_table | 2017-09-07 09:01:00.000 |
関連するコンテンツ
このチュートリアルでは、以下の手順を実行しました。
- 基準値を格納するためのデータ ストアを準備します。
- データ ファクトリを作成します。
- リンクされたサービスを作成します。
- ソース データセット、シンク データセット、および基準値データセットを作成します。
- パイプラインを作成します。
- パイプラインを実行します。
- パイプラインの実行を監視します。
- 結果の確認
- ソースにデータを追加します。
- パイプラインを再実行します。
- 2 回目のパイプラインの実行を監視します
- 2 回目の実行の結果を確認します
このチュートリアルでは、パイプラインで SQL Database 内の単一のテーブルから BLOB ストレージにデータをコピーしました。 次のチュートリアルに進んで、SQL Server データベースにある複数のテーブルから SQL Database にデータをコピーする方法について学習しましょう。