Azure Data Factory を使用して Azure Data Lake Storage Gen1 から Gen2 にデータをコピーする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新たに試用を開始する方法については、こちらをご覧ください。
Azure Data Lake Storage Gen2 は、Azure Blob Storage に組み込まれているビッグ データ分析専用の一連の機能です。 ファイル システムとオブジェクト ストレージの両方のパラダイムを使用して、データと連携させることができます。
現在 Azure Data Lake Storage Gen1 をお使いの場合は、Azure Data Factory を使用して Azure Data Lake Storage Gen1 から Gen2 にデータをコピーすることで、Azure Data Lake Storage Gen2 を評価できます。
Azure Data Factory は、フル マネージドのクラウドベースのデータ統合サービスです。 このサービスを使用して、オンプレミスとクラウドベースのデータストアの豊富なセットからのデータをレイクに入力し、分析ソリューションをビルドする際の時間を節約できます。 サポートされているコネクタの一覧は、サポートされているデータ ストアの表を参照してください。
Azure Data Factory では、スケール アウトしたマネージド データ移動ソリューションを提供しています。 Data Factory のスケールアウト アーキテクチャにより、高スループットでデータを取り込むことができます。 詳細については、コピー アクティビティのパフォーマンスを参照してください。
この記事では、Data Factory のデータのコピー ツールを使用して Azure Data Lake Storage Gen1 から Azure Data Lake Storage Gen2 にデータをコピーする方法を紹介しています。 その他の種類のデータ ストアからデータをコピーする場合も、同様の手順で実行できます。
前提条件
- Azure サブスクリプション。 Azure サブスクリプションをお持ちでない場合は、開始する前に 無料アカウント を作成してください。
- データを備えた Azure Data Lake Storage Gen1 アカウント。
- Data Lake Storage Gen2 が有効な Azure Storage アカウント。 ストレージ アカウントがない場合、作成します。
Data Factory の作成
データ ファクトリをまだ作成していない場合は、「クイック スタート: Azure portal と Azure Data Factory Studio を使用してデータ ファクトリを作成する」の手順に従って作成してください。 作成した後、Azure portal 内のデータ ファクトリに移動します。
![[Open Azure Data Factory Studio] タイルを含む、Azure Data Factory のホーム ページ。](../reusable-content/ce-skilling/azure/media/data-factory/data-factory-home-page.png)
[Open Azure Data Factory Studio](Azure Data Factory Studio を開く) タイルで [開く] を選択して、別のタブでデータ統合アプリケーションを起動します。
Azure Data Lake Storage Gen2 にデータを読み込む
ホーム ページで、 [取り込み] タイルを選択し、データのコピー ツールを起動します。
[プロパティ] ページで、 [タスクの種類] の [組み込みコピー タスク] を選択して、 [Task cadence or task schedule](タスクの周期またはタスクのスケジュール) の [Run once now](今すぐ 1 度だけ実行する) を選択し、 [次へ] を選択します。
[ソース データ ストア] ページで、 [+ 新しい接続] を選択します。
コネクタ ギャラリーから [Azure Data Lake Storage Gen1] を選択し、 [続行] を選択します。

[New connection (Azure Data Lake Storage Gen1)(新しい接続 (Azure Data Lake Storage Gen1))] ページで、次の手順を行います。
- アカウント名に対してお使いの Data Lake Storage Gen1 を選択し、 [テナント] を指定または確認します。
- [接続のテスト] を選択して設定を検証します。 [作成] を選択します。
重要
このチュートリアルでは、Azure リソースのマネージド ID を使用して、Azure Data Lake Storage Gen1 を認証します。 次の手順に従って、マネージド ID に Azure Data Lake Storage Gen1 のアクセス許可を適切に付与します。

[ソース データ ストア] ページで、次の手順を実行します。
- [接続] セクションで新しく作成した接続を選択します。
- [ファイルまたはフォルダー] で、コピーするフォルダーとファイルを参照します。 フォルダーまたはファイルを選択し、 [OK] を選択します。
- [再帰的] オプションと [バイナリ コピー] オプションを選択することで、コピーの動作を指定します。 [次へ] を選択します。
![[ソース データ ストア] ページを示すスクリーンショット。](media/load-azure-data-lake-storage-gen2-from-gen1/source-data-store-page.png)
[Destination data store](コピー先データ ストア) ページで [+ 新しい接続]>[Azure Data Lake Storage Gen2]>[続行] の順に選択します。
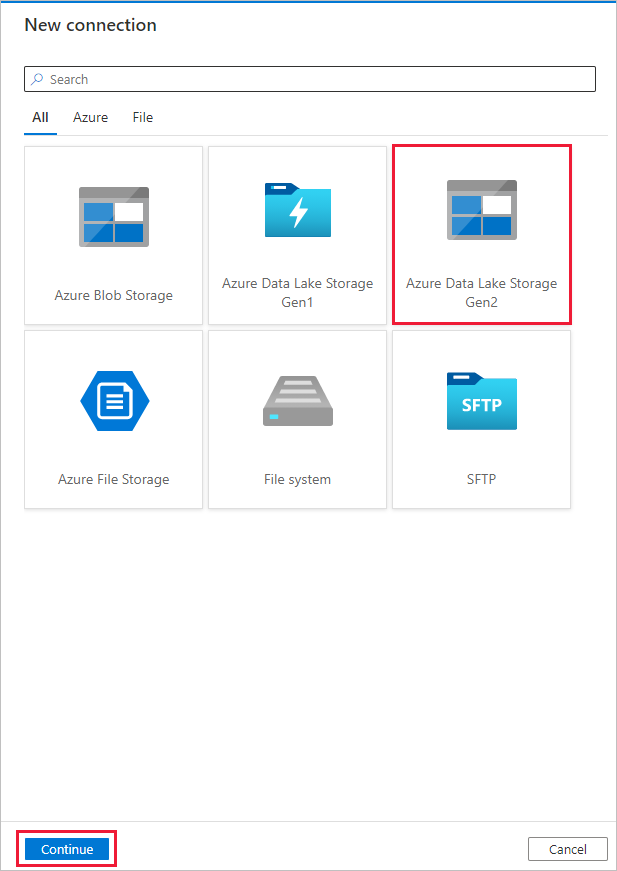
[New connection (Azure Data Lake Storage Gen2)(新しい接続 (Azure Data Lake Storage Gen2))] ページで、次の手順を行います。
- [ストレージ アカウント名] ドロップダウン リストから目的の Data Lake Storage Gen2 に対応するアカウントを選択します。
- [作成] を選択して接続を作成します。
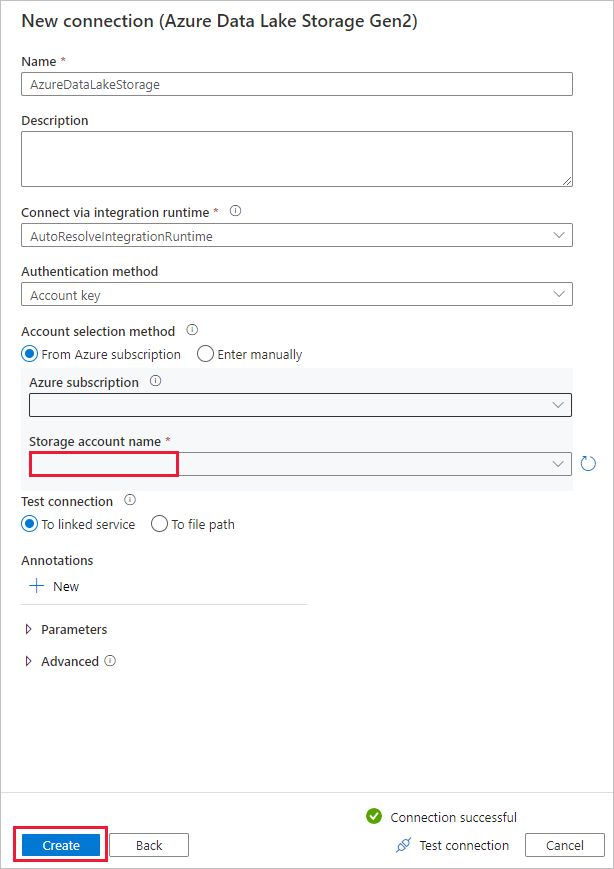
[コピー先データ ストア] ページで、次の手順を実行します。
- [接続] ブロックで新しく作成した接続を選択します。
- [フォルダー パス] で、出力フォルダー名として「copyfromadlsgen1」と入力し、 [次へ] を選択します。 対応する Azure Data Lake Storage Gen2 ファイル システムとサブフォルダーが存在しない場合、Data Factory により、コピー中、それらが作成されます。
![[コピー先データ ストア] ページを示すスクリーンショット。](media/load-azure-data-lake-storage-gen2-from-gen1/destination-data-store-page.png)
[設定] ページで、 [タスク名] フィールドに「CopyFromADLSGen1ToGen2」と指定し、 [次へ] を選択して既定の設定を使用します。
[サマリー] ページで設定を確認し、 [次へ] を選択します。
 ページを示すスクリーンショット。](media/load-azure-data-lake-storage-gen2-from-gen1/copy-summary.png)
[Deployment](デプロイ) ページで [Monitor](監視) を選択してパイプラインを監視します。
 ページを示すスクリーンショット。](media/load-azure-data-lake-storage-gen2-from-gen1/deployment-page.png)
左側の [監視] タブが自動的に選択されたことがわかります。 [パイプライン名] 列には、アクティビティの実行の詳細を表示するリンクとパイプラインを再実行するリンクが表示されます。
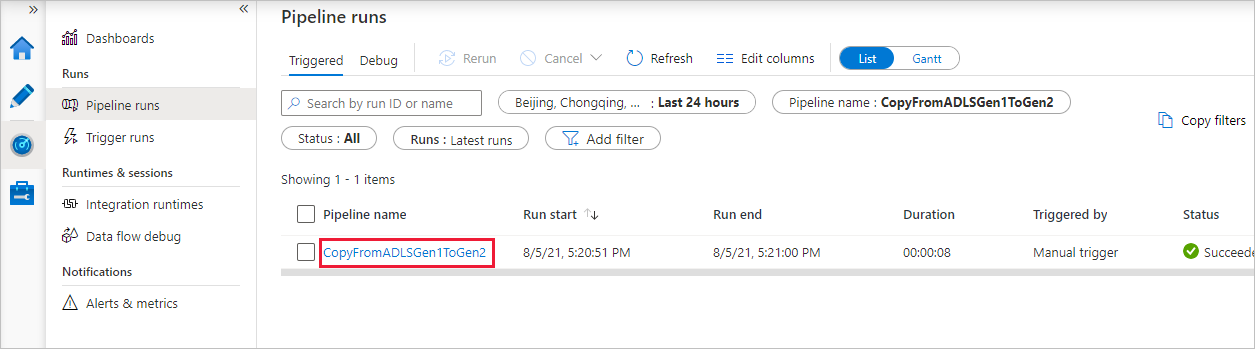
パイプラインの実行に関連付けられているアクティビティの実行を表示するには、 [パイプライン名] 列のリンクを選択します。 パイプライン内のアクティビティ (コピー アクティビティ) は 1 つだけなので、エントリは 1 つのみです。 [パイプラインの実行] ビューに戻るには、上部の階層リンク メニューの [すべてのパイプラインの実行] リンクを選択します。 [最新の情報に更新] を選択して、一覧を更新します。
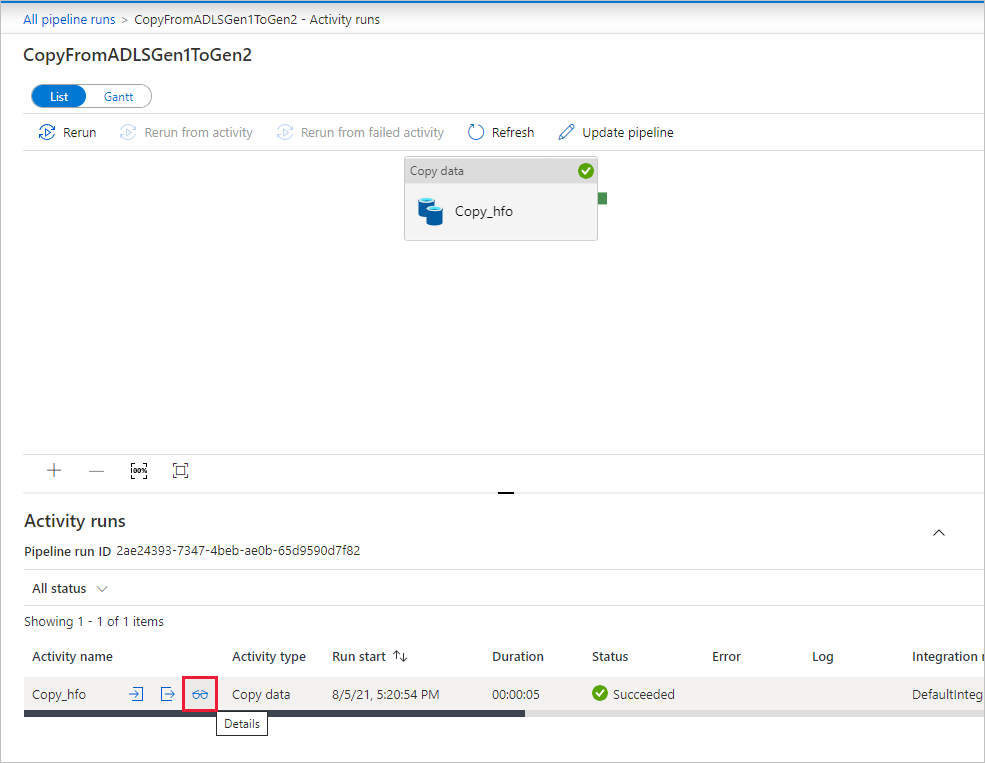
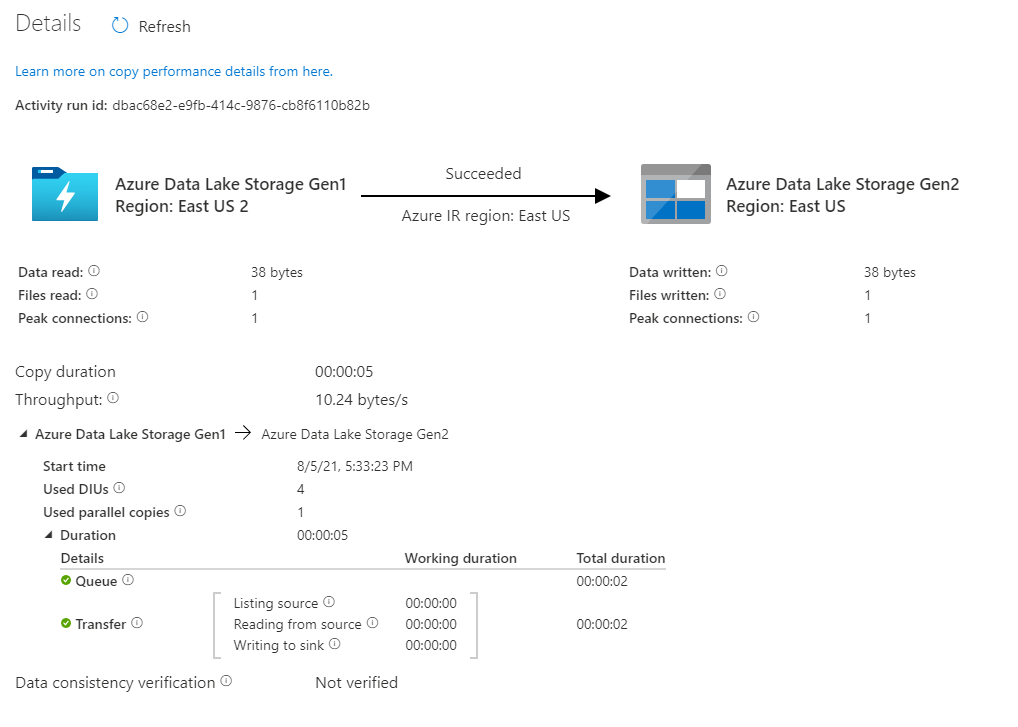
各コピー アクティビティの実行状況の詳細を監視するには、アクティビティ監視ビューの [アクティビティ名] 列の下の [詳細] リンク (眼鏡のイメージ) を選択します。 ソースからシンクにコピーされるデータの量、データのスループット、実行ステップと対応する期間、使用される構成などの詳細を監視できます。
データが Azure Data Lake Storage Gen2 アカウントにコピーされたことを確認します。
ベスト プラクティス
Azure Data Lake Storage Gen1 から Azure Data Lake Storage Gen2 からへのアップグレードの評価の概要については、「ビッグ データ分析ソリューションを Azure Data Lake Storage Gen1 から Azure Data Lake Storage Gen2 にアップグレードする」をご覧ください。 後続のセクションでは、データ ファクトリを使用して Data Lake Storage Gen1 から Data Lake Storage Gen2 にデータをアップグレードする際のベスト プラクティスについて紹介しています。
初回のスナップショット データ移行
パフォーマンス
ADF には、さまざまなレベルで並列処理を可能にするサーバーレス アーキテクチャが用意されています。そのため、開発者は、ネットワーク帯域幅だけでなくストレージの IOPS と帯域幅を利用して、データ移動のスループットが環境に合わせて最大限になるパイプラインを構築できます。
複数のお客様が、スループットを 2 GBps 以上に維持したまま、Data Lake Storage Gen1 から Gen2 に数百万個単位のファイルで構成されるペタバイト単位のデータを移行することに成功しています。
さまざまなレベルの並列処理を適用して、優れたデータ移動速度を実現できます。
- 1 回のコピー アクティビティで、スケーラブルなコンピューティング リソースを利用できます。Azure Integration Runtime を使用する場合は、サーバーレス方式で各コピー アクティビティに対して最大 256 データ統合単位 (DIU) を指定できます。セルフホステッド統合ランタイムを使用する場合は、手動でマシンをスケールアップするか、複数のマシン (最大 4 ノード) にスケールアウトすることができます。また、1 回のコピー アクティビティによって、すべてのノードでファイル セットがパーティション分割されます。
- 1 回のコピー アクティビティで、複数のスレッドを使用したデータ ストアの読み取りと書き込みが行われます。
- ADF 制御フローでは、複数のコピー アクティビティを並列して開始できます。たとえば、For Each ループを使用します。
データ パーティション
Data Lake Storage Gen1 の合計データ サイズが 10 TB より小さく、ファイルの数が 100 万個より少ない場合は、1 回のコピー アクティビティの実行ですべてのデータをコピーできます。 コピーするデータの量が多い場合、あるいはバッチでデータ移行を管理し、それぞれのバッチを特定の概算時間内に完了させたい場合は、データをパーティション分割します。 パーティション分割ではまた、予想外の問題が発生するリスクが減ります。
ファイルをパーティション化する方法は、コピー アクティビティのプロパティで name range- listAfter/listBefore を使用することです。 各 Copy アクティビティは、一度に 1 つのパーティションをコピーするように構成できます。そのため、複数の Copy アクティビティで 1 つの Data Lake Storage Gen1 アカウントから同時にデータをコピーできます。
レート制限
ベスト プラクティスとして、代表的なサンプル データセットを使用してパフォーマンス POC を実施し、適切なパーティションのサイズを決定できるようにします。
既定の DIU 設定を使用して、1 つのパーティションと 1 回のコピー アクティビティから始めます。 常に、並列コピーを空 (既定) .として設定することをお勧めします。 コピーのスループットが適切ではない場合、パフォーマンス チューニングの手順に従って、パフォーマンスのボトルネックを特定して解決します。
ネットワークの帯域幅制限またはデータ ストアの IOPS/帯域幅制限に達するまで、または1 回のコピー アクティビティで許可される最大 256 DIU に達するまで、DIU 設定を徐々に増やします。
1 回のコピー アクティビティのパフォーマンスを最大化したが、お使いの環境のスループットの上限にまだ達していない場合、複数のコピー アクティビティを並行して実行できます。
コピー アクティビティの監視で多数の調整エラーが発生した場合、ストレージ アカウントの容量制限に達したと示されます。 ADF はスロットル エラーのたびに自動的に再試行し、データの消失を防ぎますが、再試行回数が多すぎるとコピーのスループットが低下します。 このような場合、大量のスロットリング エラーを避けるため、同時に実行する Copy アクティビティの数を減らすことをお勧めします。 1 つのコピー アクティビティを使用してデータをコピーしている場合、DIU を減らすことをお勧めします。
差分のデータ移行
Data Lake Storage Gen1 から新規ファイルまたは更新されたファイルのみを読み込むには、いくつかの方法があります。
- 日時でパーティション分割されたフォルダーまたはファイル名により、新しいファイルまたは更新されたファイルを読み込みます。 たとえば、/2019/05/13/* です。
- LastModifiedDate で新しいファイルまたは更新されたファイルを読み込みます。 大量のファイルをコピーする場合、1 回のコピー アクティビティで Data Lake Storage Gen1 アカウント全体をスキャンして新しいファイルを特定する動作によるコピー スループットの低下を回避するために、最初にパーティションを作成します。
- サードパーティ製のツールまたはソリューションで新しいファイルまたは更新されたファイルを特定します。 次に、パラメーター、テーブル、またはファイルを利用し、データ ファクトリ パイプラインにファイルまたはフォルダーの名前を渡します。
増分読み込みを行う適切な頻度は、Azure Data Lake Storage Gen1 内のファイルの合計数と、毎回読み込まれる新しいファイルまたは更新されたファイルのボリュームに依存します。
ネットワークのセキュリティ
ADF の既定では、HTTPS プロトコル経由の暗号化された接続を使用して、Azure Data Lake Storage Gen1 から Gen2 へデータを転送します。 HTTPS によって転送中のデータが暗号化され、盗聴や中間者攻撃が防止されます。
また、パブリック インターネット経由でデータを転送しない場合は、プライベート ネットワーク経由でデータを転送することで、より高いセキュリティを実現できます。
ACL の保持
Data Lake Storage Gen1 から Data Lake Storage Gen2 にアップグレードするときに、ACL をデータ ファイルと共にレプリケートする必要がある場合は、「Data Lake Storage Gen1 の ACL を保持する」をご覧ください。
回復力
ADF には、1 回のコピー アクティビティの実行で、データ ストアまたは基になるネットワークの特定のレベルの一時的なエラーを処理できる組み込みの再試行メカニズムがあります。 10 TB を超えるデータを移行する場合は、データをパーティション分割して、予期しない問題が発生するリスクを軽減することをお勧めします。
また、コピー アクティビティでフォールト トレランスを有効にして、定義済みのエラーをスキップすることもできます。 また、コピー アクティビティでデータ整合性検証を有効にして、追加の検証を行い、データがコピー元ストアからコピー先ストアに正常にコピーされたことを確認するだけでなく、コピー元ストアとコピー先ストアの間でデータに整合性があることも検証できます。
アクセス許可
データ ファクトリでは、Data Lake Storage Gen1 コネクタは、Azure リソース認証のために、サービス プリンシパルとマネージド ID がサポートされています。 Data Lake Storage Gen2 コネクタでは、Azure リソース認証のために、アカウント キー、サービス プリンシパル、マネージド ID がサポートされています。 必要なすべてのファイルまたはアクセス制御リスト (ACL) を Data Factory でナビゲートしたり、コピーしたりできるようにするには、アカウントにファイルのアクセス、読み取り、書き込み、ACL の設定 (選択した場合) を行うことができる十分なアクセス許可を付与します。 移行期間中にアカウントにスーパーユーザーまたは所有者ロールを付与し、移行が完了した後に管理者特権のアクセス許可を削除する必要があります。