Azure Data Factory を使用してオンプレミスの Hadoop クラスターから Azure Storage にデータを移行する
適用対象:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Azure Data Factory には、オンプレミスの HDFS から Azure Blob Storage または Azure Data Lake Storage Gen2 に大量のデータを移行するための、パフォーマンスと信頼性が高くコスト効率に優れたメカニズムが用意されています。
Data Factory には、オンプレミスの HDFS から Azure にデータを移行するための 2 つの基本的な方法が用意されています。 ご自分のシナリオに基づいて方法を選択できます。
- Data Factory DistCp モード (推奨): Data Factory では、DistCp (分散コピー) を使用して、ファイルをそのまま Azure Blob Storage (ステージング コピーを含む) または Azure Data Lake Store Gen2 にコピーできます。 DistCp と統合された Data Factory を使用すると、既存の強力なクラスターを利用して最適なコピー スループットを実現できます。 また、Data Factory の柔軟なスケジュール設定と、統合された監視エクスペリエンスの利点も得られます。 ご使用の Data Factory の構成によっては、コピー アクティビティにより DistCp コマンドが自動的に作成され、Hadoop クラスターに送信され、コピー状態が監視されます。 オンプレミスの Hadoop クラスターから Azure にデータを移行するには、Data Factory DistCp モードをお勧めします。
- Data Factory ネイティブ統合ランタイム モード: DistCp は、すべてのシナリオで使えるオプションではありません。 たとえば、Azure Virtual Network 環境では、DistCp ツールは、Azure Storage 仮想ネットワーク エンドポイントとの Azure ExpressRoute プライベート ピアリングがサポートされていません。 また、クラスターに大きな負荷をかけると、既存の ETL ジョブのパフォーマンスに影響する可能性があるため、既存の Hadoop クラスターをデータ移行のためのエンジンとして使用したくない場合もあります。 代わりに、Data Factory 統合ランタイムのネイティブ機能を、オンプレミスの HDFS から Azure にデータをコピーするエンジンとして使用できます。
この記事では、両方の方法について次の情報を提供します。
- パフォーマンス
- 回復性のコピー
- ネットワークのセキュリティ
- 概要ソリューション アーキテクチャ
- 実装のベスト プラクティス
パフォーマンス
Data Factory DistCp モードでは、スループットは DistCp ツールを個別に使用する場合と同じです。 Data Factory DistCp モードを使用すると、既存の Hadoop クラスターの容量が最大化されます。 DistCp は、大規模なクラスター間またはクラスター内のコピーに使用できます。
DistCp では、MapReduce を使用して、その配布、エラー処理と復旧、およびレポートが有効にされます。 ファイルとディレクトリのリストがタスク マッピングの入力に展開されます。 各タスクでは、ソース リストで指定されているファイル パーティションがコピーされます。 DistCp と統合された Data Factory を使用してパイプラインを構築すると、ネットワーク帯域幅およびストレージの IOPS と帯域幅を十分に活用して、環境のデータ移動のスループットを最大限に高めることができます。
Data Factory ネイティブ統合ランタイム モードでは、さまざまなレベルで並列処理を行うこともできます。 並列処理を使用すると、ネットワーク帯域幅、ストレージ IOPS、帯域幅を最大限に活用して、データ移動のスループットを最大限に高めることができます。
- 1 回のコピー アクティビティで、スケーラブルなコンピューティング リソースを利用できます。 セルフホステッド統合ランタイムを使用すると、マシンを手動でスケールアップすることも、複数のマシン (最大 4 ノード) にスケールアウトすることもできます。 1 回のコピー アクティビティで、ファイル セットがすべてのノードにわたってパーティション分割されます。
- 1 回のコピー アクティビティで、複数のスレッドを使用したデータ ストアの読み取りと書き込みが行われます。
- Data Factory 制御フローでは、複数のコピー アクティビティを並列で開始できます。 たとえば、For each ループを使用できます。
詳細については、コピー アクティビティのパフォーマンス ガイドを参照してください。
回復力
Data Factory DistCp モードでは、回復性のレベルごとに異なる DistCp コマンドライン パラメーター (たとえば、エラーを無視する -i、またはソース ファイルと宛先ファイルのサイズが異なる場合にデータを書き込む -update) を使用できます。
Data Factory ネイティブ統合ランタイム モードでは、1 回のコピー アクティビティの実行で、Data Factory に組み込みの再試行メカニズムが作成されます。 データ ストアまたは基になるネットワークで、特定レベルの一時的なエラーを処理できます。
オンプレミスの HDFS から BLOB ストレージ、およびオンプレミスの HDFS から Data Lake Store Gen2 にバイナリ コピーを実行しているときに、Data Factory ではチェックポイント処理がかなりの部分まで自動的に行われます。 コピー アクティビティの実行が失敗、またはタイムアウトした場合、後続の再試行 (再試行回数が 1 を超える場合) では、最初から開始するのではなく、最後の障害個所からコピーが再開されます。
ネットワークのセキュリティ
Data Factory では既定で、HTTPS プロトコル経由の暗号化された接続を使用して、オンプレミスの HDFS から BLOB ストレージまたは Azure Data Lake Storage Gen2 にデータが転送されます。 HTTPS によって転送中のデータが暗号化され、盗聴や中間者攻撃が防止されます。
または、パブリック インターネット経由でデータを転送しない場合は、セキュリティを強化するために、ExpressRoute を介してプライベート ピアリング リンク経由でデータを転送できます。
ソリューションのアーキテクチャ
この画像は、パブリック インターネット経由でのデータの移行を示しています。
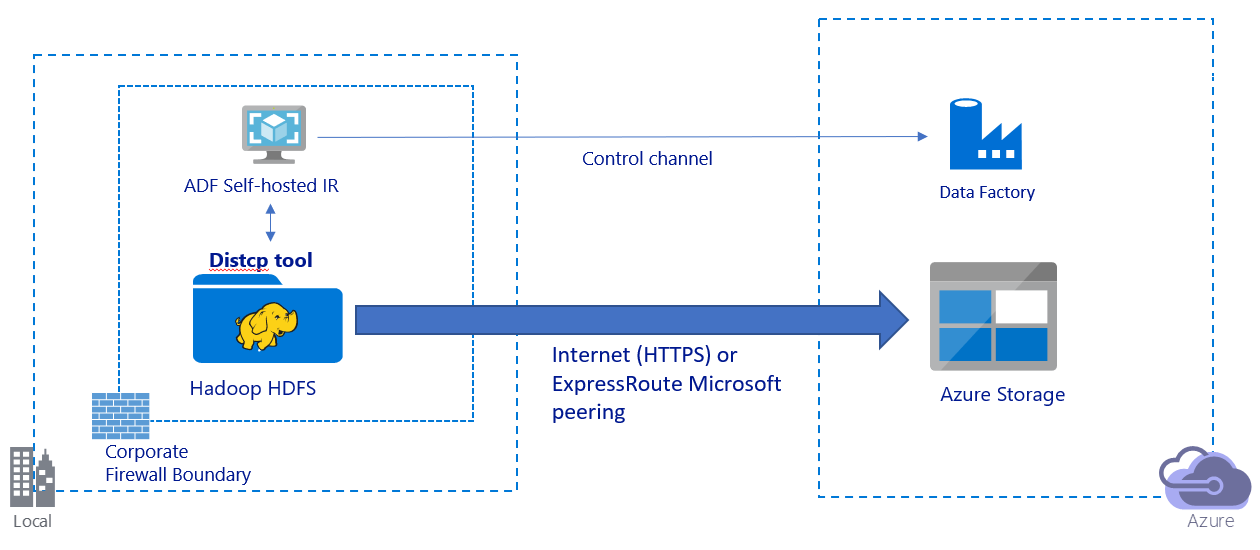
- このアーキテクチャでは、データはパブリック インターネット経由で HTTPS を使用して安全に転送されます。
- Data Factory DistCp モードはパブリック ネットワーク環境で使用することをお勧めします。 既存の強力なクラスターを活用して、最適なコピー スループットを実現できます。 また、Data Factory の柔軟なスケジュール設定と、統合された監視エクスペリエンスの利点も得られます。
- このアーキテクチャでは、Hadoop クラスターに DistCp コマンドを送信し、コピー状態を監視するには、Data Factory セルフホステッド統合ランタイムを企業ファイアウォール内の Windows マシンにインストールする必要があります。 マシンはデータを移動するエンジンではないので (制御目的のみ)、マシンの容量がデータ移動のスループットに影響することはありません。
- DistCp コマンドの既存のパラメーターがサポートされています。
この画像は、プライベート リンク経由でのデータの移行を示しています。
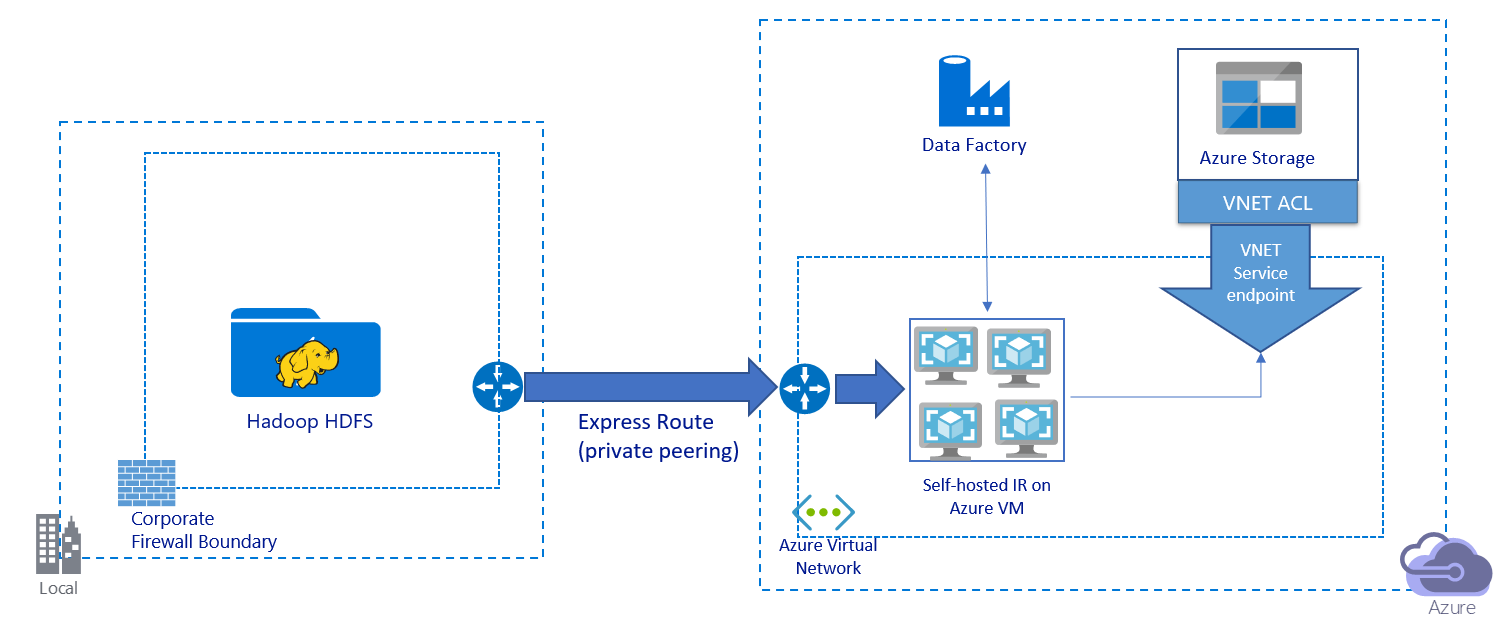
- このアーキテクチャでは、データは Azure ExpressRoute 経由でプライベート ピアリングリンクを介して移行されます。 データがパブリック インターネット経由で転送されることはありません。
- DistCp ツールでは、Azure Storage 仮想ネットワーク エンドポイントを使用した ExpressRoute プライベート ピアリングはサポートされていません。 データを移行するには、統合ランタイム経由で Data Factory のネイティブ機能を使用することをお勧めします。
- このアーキテクチャでは、Azure 仮想ネットワークの Windows VM に Data Factory セルフホステッド統合ランタイムをインストールする必要があります。 VM を手動でスケールアップするか、複数の VM にスケールアウトすることで、ネットワークとストレージの IOPS または帯域幅を十分に活用できます。
- (Data Factory セルフホステッド統合ランタイムがインストールされた) 各 Azure VM に対して最初に推奨される構成は、32 vCPU と 128 GB のメモリが搭載された Standard_D32s_v3 です。 データ移行中に VM の CPU とメモリの使用率を監視して、パフォーマンスを向上させるために VM をスケールアップする必要があるか、またはコストを削減するために VM をスケールダウンする必要があるかどうかを確認できます。
- また、1 つのセルフホステッド統合ランタイムに最大 4 つの VM ノードを関連付けてスケールアウトすることもできます。 セルフホステッド統合ランタイムに対して実行される 1 回のコピー ジョブで、ファイル セットが自動的にパーティション分割され、すべての VM ノードを利用してファイルが並列でコピーされます。 高可用性を実現するには、データ移行中の単一障害点シナリオを回避するために、2 つの VM ノードから始めることをお勧めします。
- このアーキテクチャを使用すると、初回のスナップショット データ移行と差分のデータ移行が使用できます。
実装のベスト プラクティス
データ移行を実装するときは、次のベスト プラクティスに従うことをお勧めします。
認証と資格情報の管理
- HDFS に対して認証を行うには、Windows (Kerberos) または匿名のいずれかを使用できます。
- Azure Blob Storage に接続するために複数の認証の種類がサポートされています。 Azure リソースのマネージド ID を使用することを強くお勧めします。 マネージド ID は Microsoft Entra ID で自動的に管理される Data Factory ID をベースに構築されており、リンク サービス定義で資格情報を指定せずにパイプラインを構成できます。 または、サービス プリンシパル、共有アクセス署名、またはストレージ アカウント キーを使用して BLOB ストレージに対する認証を行うこともできます。
- Data Lake Storage Gen2 に接続するために複数の認証の種類もサポートされています。 Azure リソースのマネージド ID を使用することを強くお勧めしますが、サービス プリンシパルまたはストレージ アカウント キーを使用することもできます。
- Azure リソースのマネージド ID を使用しない場合は、簡単にするために、Azure Key Vault に資格情報を格納して、Data Factory のリンクされたサービスを変更せずに、キーを一元的に管理およびローテーションすることを強くお勧めします。 これも CI/CD のベスト プラクティスです。
初回のスナップショット データ移行
Data Factory DistCp モードでは、1 つのコピー アクティビティを作成して DistCp コマンドを送信し、さまざまなパラメーターを指定して最初のデータ移行動作を制御できます。
Data Factory ネイティブ統合ランタイムモードでは、特に 10 TB を超えるデータを移行する場合には、データ パーティションをお勧めします。 データをパーティション分割するには、HDFS のフォルダー名を使用します。 これにより、各 Data Factory コピー ジョブで一度に 1 つのフォルダー パーティションをコピーできるようになります。 複数の Data Factory コピー ジョブを同時に実行して、スループットを向上させることができます。
ネットワークまたはデータ ストアの一時的な問題によってコピー ジョブが失敗した場合は、失敗したコピー ジョブを再実行して、その特定のパーティションを HDFS から読み込むことができます。 読み込むパーティションが異なるその他のコピー ジョブは影響を受けません。
差分のデータ移行
Data Factory DistCp モードで差分データを移行するには、DistCp コマンドライン パラメーター -update (ソース ファイルと宛先ファイルのサイズが異なる場合にデータを書き込む) を使用できます。
Data Factory ネイティブ統合モードで、HDFS から新しいファイルまたは変更されたファイルを特定する最もパフォーマンスの高い方法は、時間でパーティション分割された名前付け規則を使用することです。 HDFS 内のデータが、ファイル名またはフォルダー名のタイム スライス情報 (/yyyy/mm/dd/file.csv など) を使用して時間でパーティション分割されている場合、パイプラインでは、増分的にコピーするファイルとフォルダーをパイプラインで簡単に識別できます。
または、HDFS のデータが時間でパーティション分割されていない場合、Data Factory では新しいファイルまたは変更されたファイルがその LastModifiedDate 値を使用して識別されます。 Data Factory により、HDFS からすべてのファイルがスキャンされ、設定値よりも大きい最終更新のタイムスタンプを持つ新しいファイルおよび更新されたファイルのみがコピーされます。
HDFS に多くのファイルがある場合、フィルター条件に一致するファイルの数に関係なく、初回のファイル スキャンに時間がかかる場合があります。 このシナリオでは、最初のスナップショットの移行に使用したのと同じパーティションを使用して、最初にデータをパーティション分割することをお勧めします。 これにより、ファイルのスキャンを並列で実行できます。
料金の見積もり
HDFS から Azure Blob Storage にデータを移行するために、次のパイプラインを考慮してください。
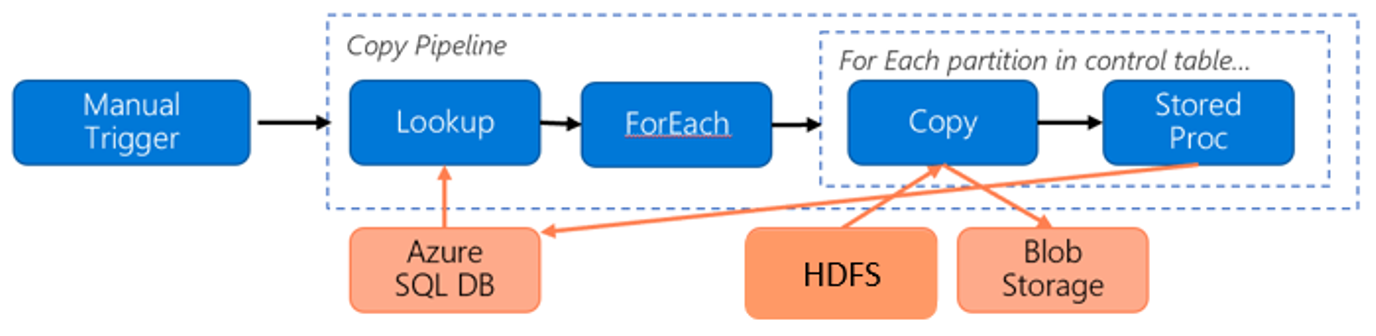
次の情報の場合を考えてみましょう。
- 合計データ量は 1 PB。
- Data Factory ネイティブ統合ランタイムモードを使用してデータを移行する。
- 1 PB が 1,000 のパーティションに分割され、コピーのたびに 1 つのパーティションが移行される。
- 各コピー アクティビティは、4 台のマシンに関連付けられた 1 つのセルフホステッド統合ランタイムを使用して構成され、500 MBps のスループットを実現する。
- ForEach の同時実行数は 4 に設定され、合計スループットは 2 GBps。
- 合計では、移行が完了するまでに 146 時間かかる。
この前提条件に基づく推定料金は次のとおりです。
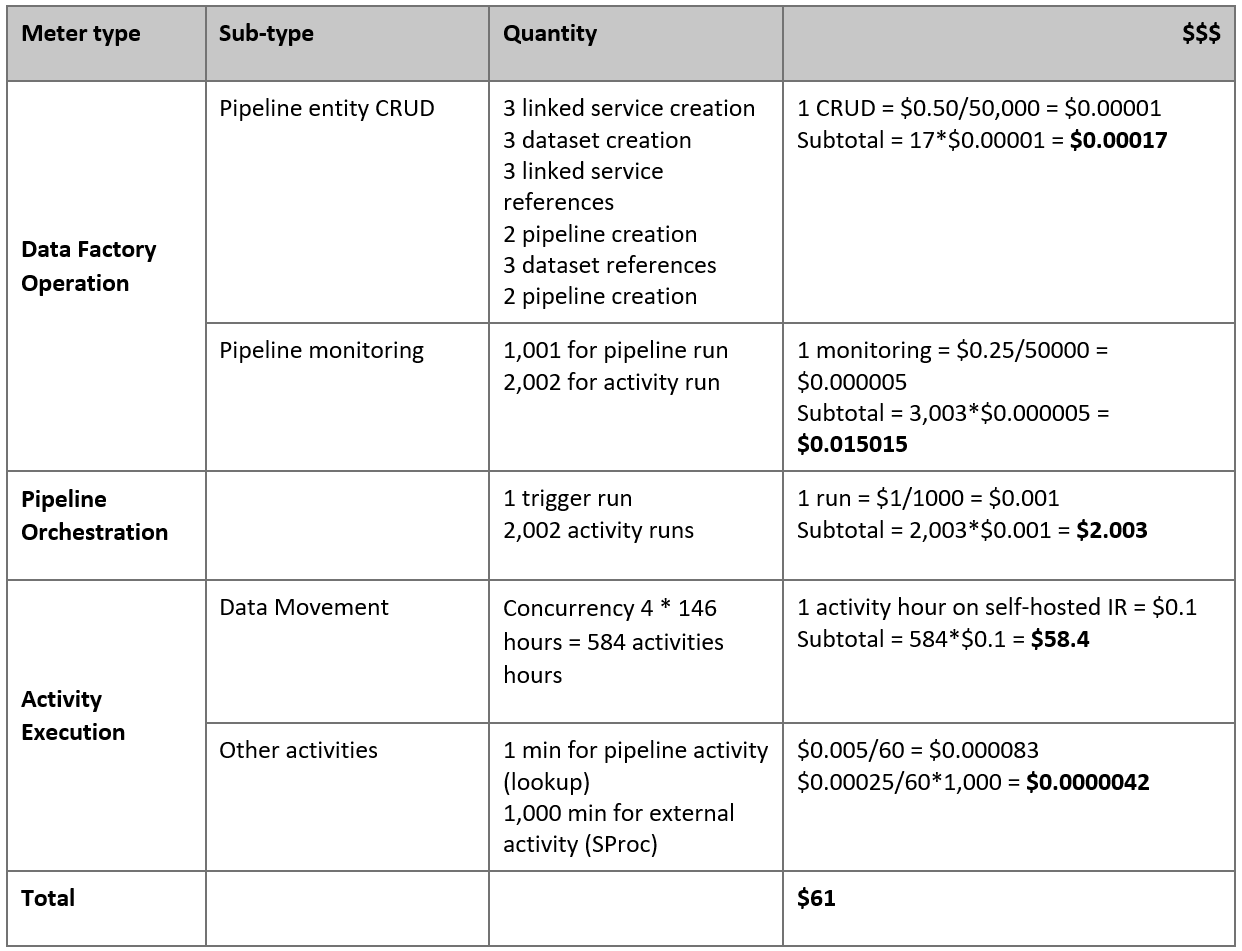
注意
これは仮定の料金例です。 実際の料金は、環境の実際のスループットによって変わります。 (セルフホステッド統合ランタイムがインストールされている) Azure Windows VM の料金は含まれていません。
その他の参照情報
- HDFS コネクタ
- Azure BLOB ストレージ コネクタ
- Azure Data Lake Storage Gen2 コネクタ
- コピー アクティビティのパフォーマンスとチューニングに関するガイド
- セルフホステッド統合ランタイムを作成して構成する
- セルフホステッド統合ランタイムの高可用性とスケーラビリティ
- データ移動のセキュリティに関する考慮事項
- Azure Key Vault への資格情報の格納
- 時間でパーティション分割されたファイル名に基づいてファイルを増分コピーする
- LastModifiedDate に基づいて新しいファイルと変更されたファイルをコピーする
- Data Factory の価格ページ