Azure Data Factory または Synapse Analytics を使用して Netezza からデータをコピーする
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory および Azure Synapse Analytics パイプラインで Copy アクティビティを使用して、Netezza からデータをコピーする方法について説明します。 この記事は、Copy アクティビティの概要を説明する Copy アクティビティに関する記事に基づいています。
ヒント
Netezza から Azure へのデータ移行のシナリオの詳細については、「オンプレミスの Netezza サーバーから Azure へのデータの移行」をご覧ください。
サポートされる機能
この Netezza コネクタは、次の機能でサポートされています。
| サポートされる機能 | IR |
|---|---|
| Copy アクティビティ (ソース/-) | ① ② |
| Lookup アクティビティ | ① ② |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
コピー アクティビティでソースおよびシンクとしてサポートされているデータ ストアの一覧については、「サポートされるデータ ストアと形式」を参照してください。
Netezza コネクタでは、以下がサポートされます。
- ソースからの並列コピー。 詳細については、「Netezza からの並列コピー」セクションを参照してください。
- Netezza Performance Server バージョン 11。
- この記事の Windows バージョン。
このサービスでは、接続を行うための組み込みのドライバーが提供されます。 このコネクタを使用するためにドライバーを手動でインストールする必要はありません。
前提条件
データ ストアがオンプレ ミスネットワーク、Azure 仮想ネットワーク、または Amazon Virtual Private Cloud 内にある場合は、それに接続するようセルフホステッド統合ランタイムを構成する必要があります。
データ ストアがマネージド クラウド データ サービスである場合は、Azure Integration Runtime を使用できます。 ファイアウォール規則で承認されている IP にアクセスが制限されている場合は、Azure Integration Runtime の IP を許可リストに追加できます。
また、Azure Data Factory のマネージド仮想ネットワーク統合ランタイム機能を使用すれば、セルフホステッド統合ランタイムをインストールして構成しなくても、オンプレミス ネットワークにアクセスすることができます。
Data Factory によってサポートされるネットワーク セキュリティ メカニズムやオプションの詳細については、「データ アクセス戦略」を参照してください。
はじめに
コピー アクティビティを使用するパイプラインは、.NET SDK、Python SDK、Azure PowerShell、REST API、または Azure Resource Manager テンプレートを使用して作成できます。 Copy アクティビティを使用したパイプライン作成の詳細な手順については、Copy アクティビティのチュートリアルを参照してください。
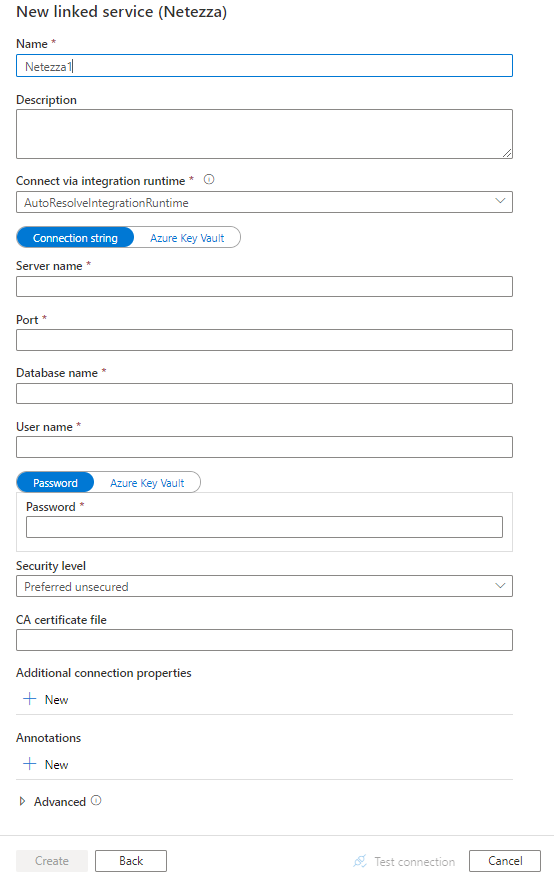
UI を使用して Netezza のリンク サービスを作成する
次の手順を使用して、Azure portal UI で Netezza のリンク サービスを作成します。
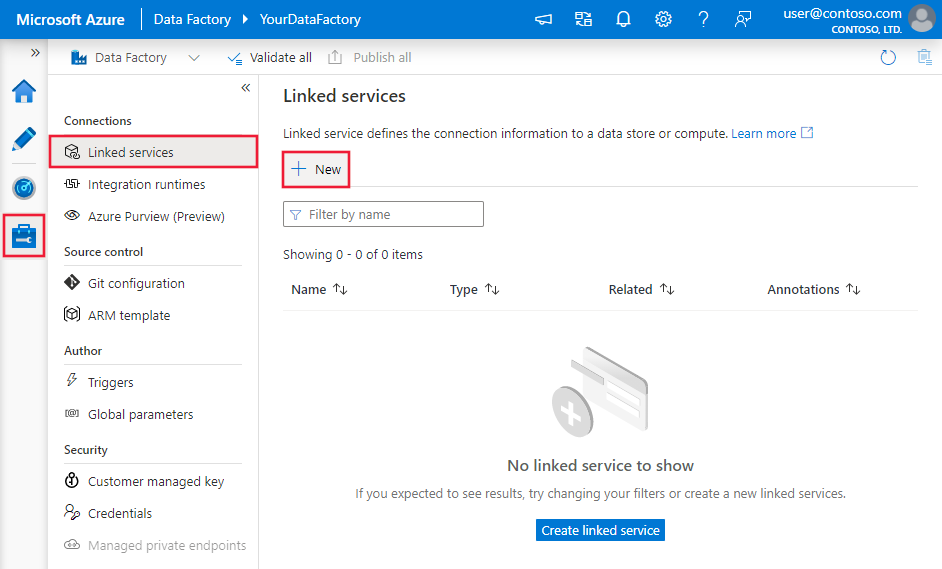
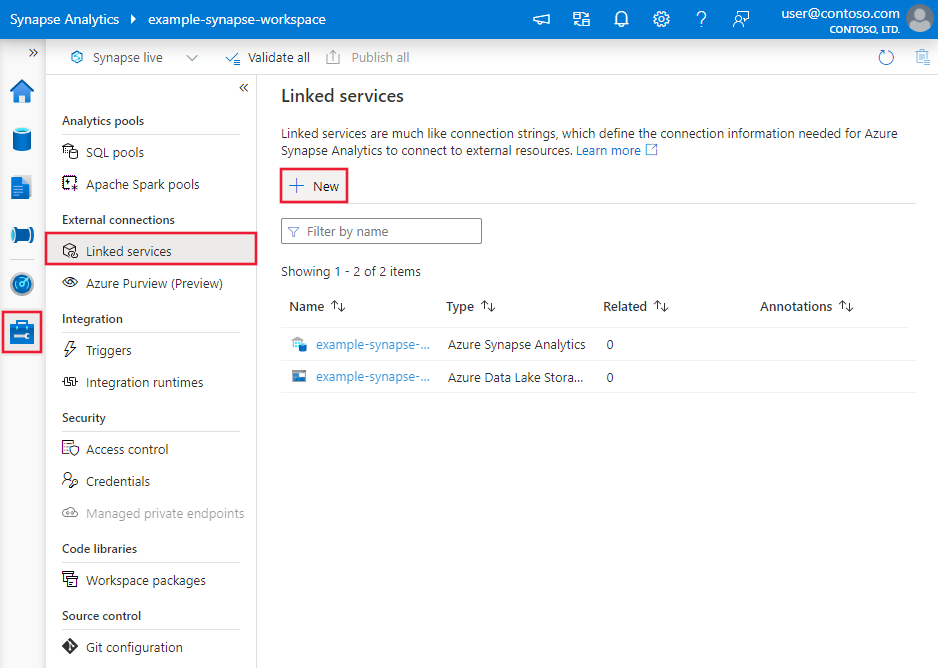
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] をクリックします。
Netezza を検索し、Netezza コネクタを選択します。

サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
以下のセクションでは、Netezza コネクタに固有のエンティティの定義に使用できるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Netezza のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティを Netezza に設定する必要があります。 | はい |
| connectionString | Netezza に接続するための ODBC 接続文字列。 パスワードを Azure Key Vault に格納して、接続文字列から pwd 構成をプルすることもできます。 詳細については、下記の例と、「Azure Key Vault への資格情報の格納」の記事を参照してください。 |
はい |
| connectVia | データ ストアに接続するために使用される Integration Runtime。 詳細については、「前提条件」セクションを参照してください。 指定されていない場合は、既定の Azure Integration Runtime が使用されます。 | いいえ |
一般的な接続文字列は Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password> です。 次の表では、設定できる他のプロパティについて説明します。
| プロパティ | 内容 | 必須 |
|---|---|---|
| SecurityLevel | ドライバーがデータ ストアへの接続に使用するセキュリティのレベル。 例: SecurityLevel=preferredUnSecured。 サポートされる値は次のとおりです。- セキュリティで保護されていない接続のみ (onlyUnSecured):ドライバーで SSL を使用しません。 - セキュリティで保護されていない接続を優先 (preferredUnSecured) (既定値) :サーバーによって選択肢が提供される場合、ドライバーでは SSL を使用しません。 |
いいえ |
Note
SSLv3 は、Netezza によって正式に非推奨とされているため、コレクタではサポートされていません。
例
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
例: パスワードを Azure Key Vault に格納する
{
"name": "NetezzaLinkedService",
"properties": {
"type": "Netezza",
"typeProperties": {
"connectionString": "Server=<server>;Port=<port>;Database=<database>;UID=<user name>;",
"pwd": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
データセットのプロパティ
このセクションでは、Netezza データセットでサポートされているプロパティの一覧を示します。
データセットの定義に使用できるセクションとプロパティの完全な一覧については、データセットに関するページをご覧ください。
Netezza からデータをコピーするには、データセットの type プロパティを NetezzaTable に設定します。 次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、次のように設定する必要があります:NetezzaTable | はい |
| schema | スキーマの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| table | テーブルの名前。 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
| tableName | スキーマがあるテーブルの名前。 このプロパティは下位互換性のためにサポートされています。 新しいワークロードでは、schema と table を使用します。 |
いいえ (アクティビティ ソースの "query" が指定されている場合) |
例
{
"name": "NetezzaDataset",
"properties": {
"type": "NetezzaTable",
"linkedServiceName": {
"referenceName": "<Netezza linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
コピー アクティビティのプロパティ
このセクションでは、Netezza ソースでサポートされているプロパティの一覧を示します。
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインに関する記事を参照してください。
ソースとしての Netezza
ヒント
データのパーティション分割を使用して Netezza からデータを効率的に読み込む方法の詳細については、「Netezza からの並列コピー」セクションを参照してください。
Netezza からデータをコピーするには、コピー アクティビティの source のタイプを NetezzaSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティを NetezzaSource に設定する必要があります。 | はい |
| query | カスタム SQL クエリを使用してデータを読み取ります。 例: "SELECT * FROM MyTable" |
いいえ (データセットの "tableName" が指定されている場合) |
| partitionOptions | Netezza からのデータの読み込みに使用されるデータ パーティション分割オプションを指定します。 指定できる値は、None (既定値)、DataSlice、DynamicRange です。 パーティション オプションが有効になっている場合 (つまり、 None ではない場合)、Netezza データベースから同時にデータを読み込む並列処理の次数は、コピー アクティビティの parallelCopies の設定によって制御されます。 |
いいえ |
| partitionSettings | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
| partitionColumnName | 並列コピーの範囲パーティション分割で使用される整数型のソース列の名前を指定します。 指定されていない場合は、テーブルの主キーが自動検出され、パーティション列として使用されます。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionColumnName をフックします。 例については、「Netezza からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionUpperBound | データをコピーするパーティション列の最大値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionUpbound をフックします。 例については、「Netezza からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionLowerBound | データをコピーするパーティション列の最小値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionLowbound をフックします。 例については、「Netezza からの並列コピー」セクションを参照してください。 |
いいえ |
例:
"activities":[
{
"name": "CopyFromNetezza",
"type": "Copy",
"inputs": [
{
"referenceName": "<Netezza input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Netezza からの並列コピー
Data Factory の Netezza コネクタは、Netezza からデータを並列でコピーするために、組み込みのデータ パーティション分割を提供します。 データ パーティション分割オプションは、コピー アクティビティの [ソース] テーブルにあります。

パーティション分割されたコピーを有効にすると、サービスによって Netezza ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Netezza データベースからデータの一部を取得します。
特に、Netezza データベースから大量のデータを読み込む場合は、データ パーティション分割を使用した並列コピーを有効にすることをお勧めします。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 大きなテーブル全体を読み込む。 |
パーティション オプション: データ スライス。 実行中に、サービスによって Netezza の組み込みデータ スライスに基づいてデータが自動的にパーティション分割され、パーティションごとにデータがコピーされます。 |
| カスタム クエリを使用して大量のデータを読み込む。 |
パーティション オプション: データ スライス。 クエリ: SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>実行中にサービスによって ?AdfPartitionCount (コピー アクティビティで並列コピー番号が設定されています) と ?AdfDataSliceCondition がデータ スライス パーティション ロジックに置き換えられ、Netezza に送信されます。 |
| カスタム クエリを使用して大量のデータを読み込む (範囲パーティション分割のために値が均等に分散されている整数列がある場合)。 |
パーティション オプション: 動的範囲パーティション。 クエリ: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>パーティション列: データのパーティション分割に使用される列を指定します。 整数データ型の列に対してパーティション分割を実行できます。 パーティションの上限とパーティションの下限: パーティション列に対してフィルター処理を実行して、下限から上限までの範囲内のデータのみを取得する場合に指定します。 実行中に、サービスによって ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound、?AdfRangePartitionLowbound が各パーティションの実際の列名および値の範囲に置き換えられ、Netezza に送信されます。 たとえば、パーティション列 "ID" で下限が 1、上限が 80 に設定され、並列コピーが 4 に設定されている場合、サービスは 4 つのパーティションでデータを取得します。 これらの ID の範囲はそれぞれ [1, 20]、[21, 40]、[41, 60]、[61, 80] です。 |
例: データ スライス パーティションを使用してクエリを実行する
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE mod(datasliceid, ?AdfPartitionCount) = ?AdfDataSliceCondition AND <your_additional_where_clause>",
"partitionOption": "DataSlice"
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "NetezzaSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<dynamic_range_partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Lookup アクティビティのプロパティ
プロパティの詳細については、Lookup アクティビティに関するページを参照してください。
関連するコンテンツ
コピー アクティビティでソースおよびシンクとしてサポートされているデータ ストアの一覧については、「サポートされるデータ ストアと形式」を参照してください。