クイックスタート: Azure portal を使用して Azure Cosmos DB for NoSQL アカウントを作成する
適用対象: ![]() NoSQL
NoSQL
このクイックスタートでは、Azure portal で新しい Azure Cosmos DB for NoSQL アカウントを作成します。 その後、Azure portal 内でデータ エクスプローラー エクスペリエンスを使用して、必要なすべての設定を構成するデータベースとコンテナーを作成します。 最後に、コンテナーにサンプル データを追加し、基本的なクエリを発行します。
前提条件
- アクティブなサブスクリプションが含まれる Azure アカウント。 無料でアカウントを作成できます。
アカウントを作成する
新しい Azure Cosmos DB for NoSQL アカウントの作成して開始する
Azure portal (https://portal.azure.com) にサインインします。
グローバル検索バーに「Azure Cosmos DB」と入力します。

[サービス] で [Azure Cosmos DB] を選択します。
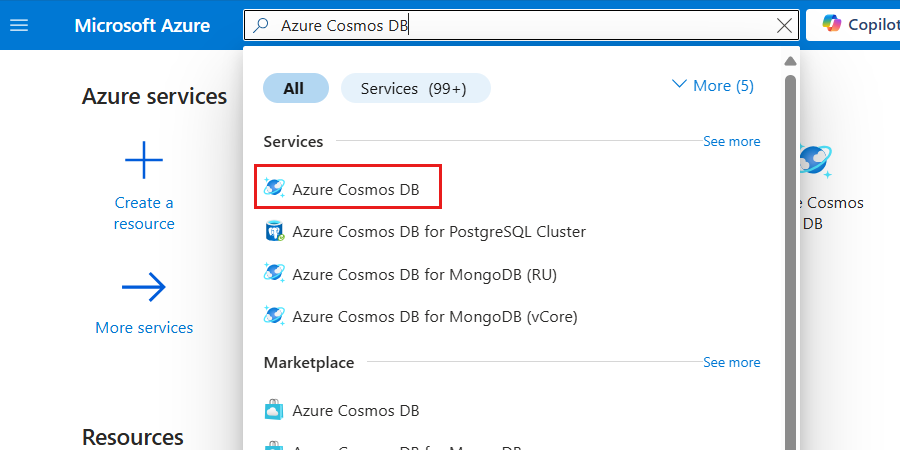
[Azure Cosmos DB アカウントの作成] ウィンドウで、[作成]、[Azure Cosmos DB for NoSQL] の順に選択します。
![Azure サービス ウィンドウ内の [作成] オプションを示すスクリーンショット。](media/quickstart-portal/create-resource-option.png)
![API for NoSQL が強調表示されている [Azure Cosmos DB API オブジェクトの選択と表示] ウィンドウを示すスクリーンショット。](media/quickstart-portal/api-nosql-option.png)
[基本情報] ウィンドウで、次のオプションを構成し、[レビュー + 作成] を選択します。
Value サブスクリプション お使いの "Azure サブスクリプション" を選択します リソース グループ 新しいリソース グループを作成する、あるいは既存のリソース グループを選択します 取引先企業名 グローバルに一意の名前を指定します 可用性ゾーン 無効にする Location サブスクリプションでサポートされている Azure リージョンを選択します ![Azure Cosmos DB for NoSQL リソース作成の [基本] ウィンドウを示すスクリーンショット。](media/quickstart-portal/basics-pane.png)
ヒント
指令されていないオプションは既定値のままでかまいません。 アカウントの合計処理能力を 1 秒あたり 1,000 要求ユニット (RU/秒) に制限し、Free レベルを有効にしてコストを最小限に抑えるようにアカウントを構成することもできます。
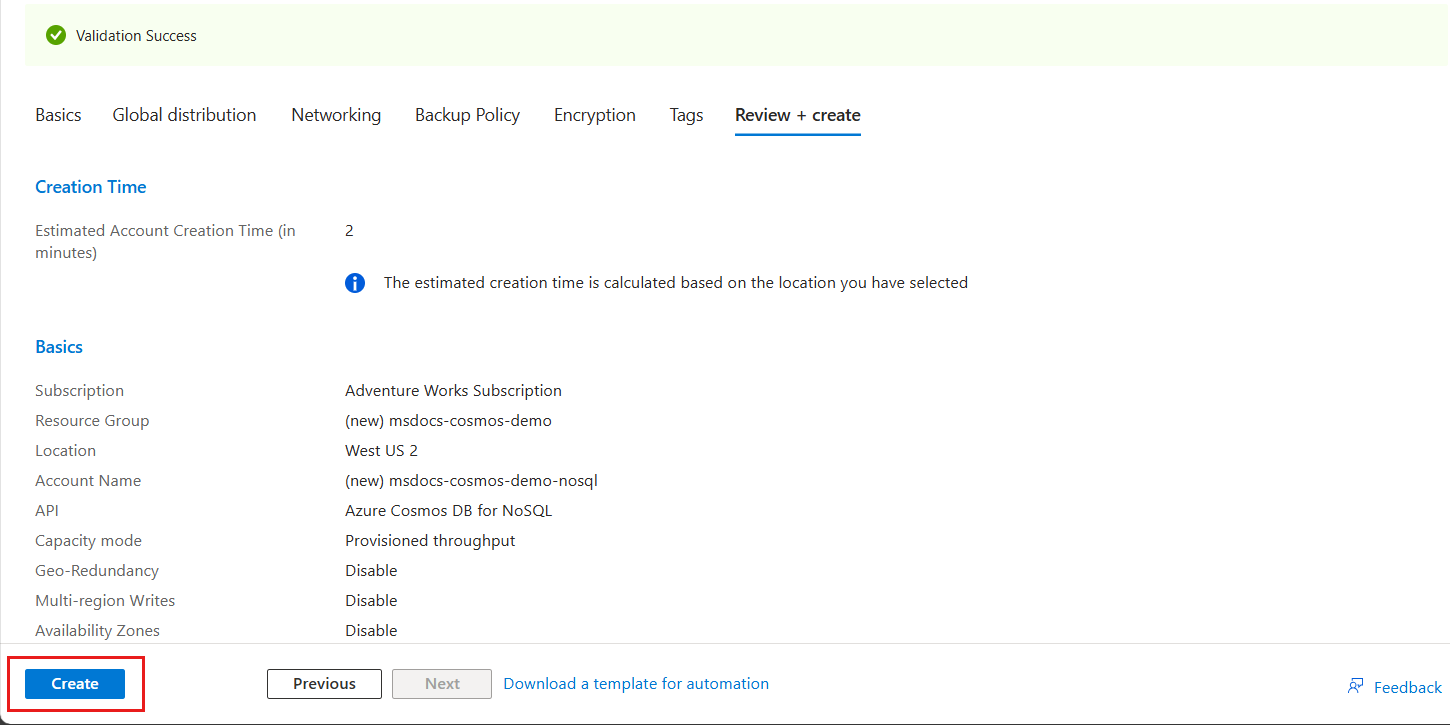
[レビュー + 作成] ウィンドウで、アカウントの検証が正常に完了するまで待ってから、[作成] を選択します。
Portal は自動的に [展開] ウィンドウに移動します。 デプロイが完了するまで待ちます。
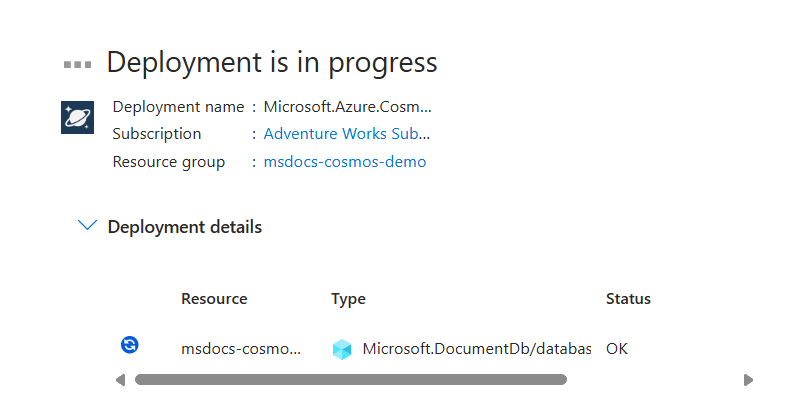
展開が完了したら、[リソースに移動] を選択して、新しい Azure Cosmos DB for NoSQL アカウントに移動します。
![[リソースに移動] オプションが強調表示されている、完全に配置されたリソースを示すスクリーンショット。](media/quickstart-portal/deployment-finalized.png)

データベースとコンテナーを作成する
次に、データ エクスプローラーを使用して、データベースとコンテナーを作成します。
[アカウント リソース] ウィンドウで、サービス メニューの [データ エクスプローラー] を選択します。
![アカウントのサービス メニューの [データ エクスプローラー] オプションを示すスクリーンショット。](media/quickstart-portal/service-menu-data-explorer.png)
[データ エクスプローラー] ウィンドウで、[新しいコンテナー] オプションを選択します。
![データ エクスプローラー内の [新しいコンテナー] オプションを示すスクリーンショット。](media/quickstart-portal/new-container-option.png)
[新しいコンテナー] ダイアログで、次の値を設定して [OK] を選択します。
値 データベース 新規作成 データベース ID cosmicworksコンテナー間でスループットを共有する 選択しません コンテナー ID employeesパーティション キー department/nameコンテナーのスループット (自動スケーリング) Autoscale コンテナーの最大 RU/秒 1000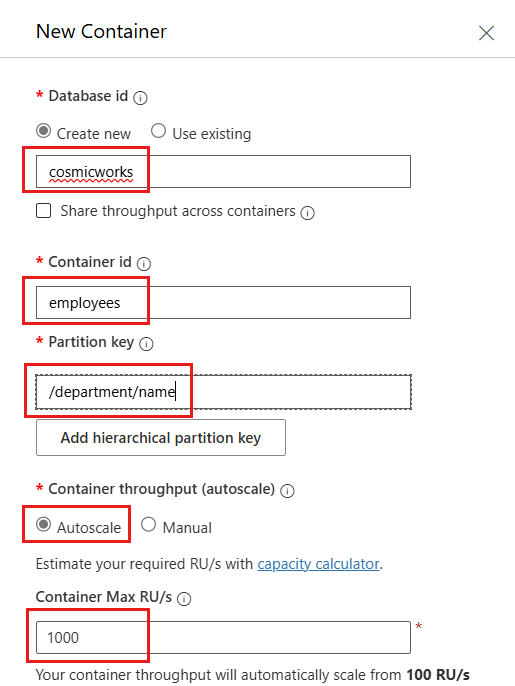
demo.bicepparam または (
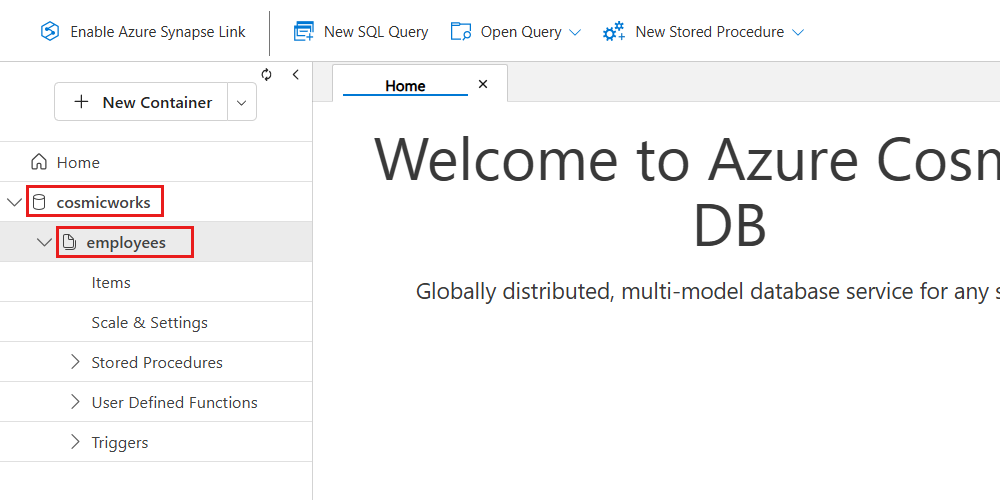
demo.bicepparam) という名前の新しいファイルを作成します。データ エクスプローラーの階層内で、新しく作成されたデータベースとコンテナーを確認します。
ヒント
必要に応じて、コンテナー ノードを展開して、追加のプロパティと構成設定を確認できます。
サンプル データの追加とクエリ
最後に、データ エクスプローラーを使用してサンプル品目を作成し、コンテナーに基本的なクエリを発行します。
データ エクスプローラーのツリーで、[従業員] コンテナーのノードを展開します。 次に、[品目] オプションを選択します。
![データ エクスプローラー階層のコンテナー内の [項目] オプションを示すスクリーンショット。](media/quickstart-portal/data-explorer-container-items.png)
[データ エクスプローラー] メニューで [新しい品目] を選択します。
![[データ エクスプローラー] メニュー内の [新しい品目] オプションを示すスクリーンショット。](media/quickstart-portal/data-explorer-container-new-item.png)
まず、[従業員] コンテナーに新しい品目に対して次の JSON を挿入し、[保存] を選択します。
{ "id": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb", "name": { "first": "Kai", "last": "Carter" }, "email": "<kai@adventure-works.com>", "department": { "name": "Logistics" } }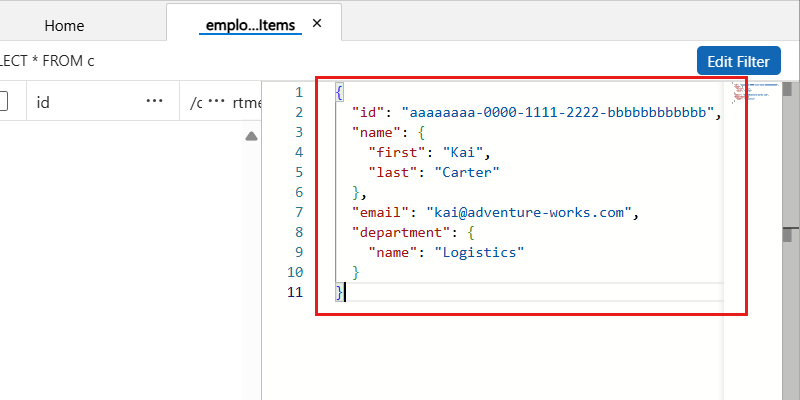
[データ エクスプローラー] メニューで [新しい SQL クエリ] を選択します。
![データ エクスプローラー メニュー内の [新しい SQL クエリ] オプションを示すスクリーンショット。](media/quickstart-portal/data-explorer-new-query.png)
まず、次の NoSQL クエリを挿入して、大文字と小文字を区別しない検索を使用して、
logistics部門のすべての品目を取得します。 その後、クエリによって、出力が構造化された JSON オブジェクトとして書式設定されます。 クエリを実行するには [クエリの実行] を選択します。SELECT VALUE { "name": CONCAT(e.name.last, " ", e.name.first), "department": e.department.name, "emailAddresses": [ e.email ] } FROM employees e WHERE STRINGEQUALS(e.department.name, "logistics", true)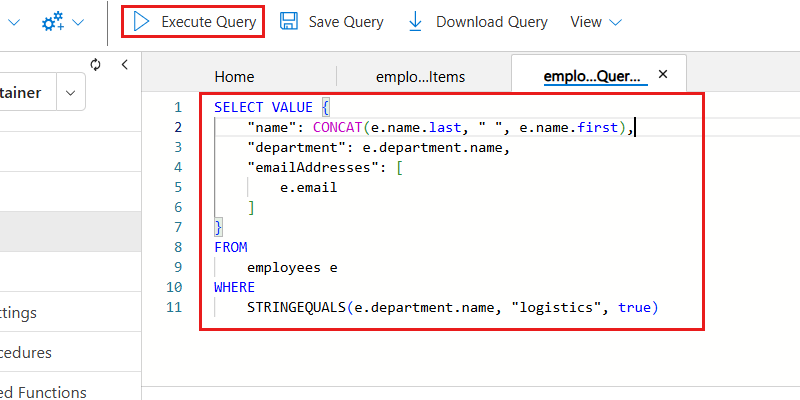
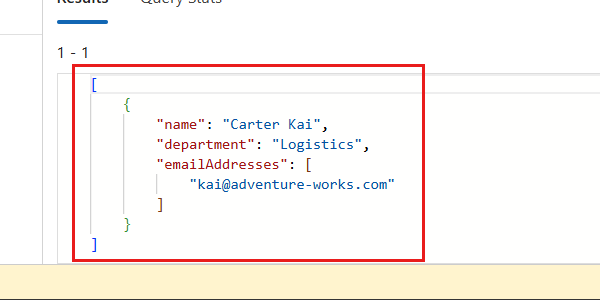
クエリからの JSON 配列の出力を確認します。
[ { "name": "Carter Kai", "department": "Logistics", "emailAddresses": [ "kai@adventure-works.com" ] } ]