Azure Machine Learning は、機械学習モデルとワークフローの作成、操作、消費に関するヘルプなど、機械学習のライフサイクルを開始から終了まで管理するための統合プラットフォームです。 サービスのいくつかの利点を次に示します。
機能は、実験の管理、データへのアクセス、ジョブの追跡、ハイパーパラメーターのチューニング、ワークフローの自動化を支援することで、作成者が生産性を向上させることができます。
モデルの容量について説明し、再現し、監査し、DevOps と統合し、豊富なセキュリティ制御モデルを使用すると、オペレーターがガバナンスとコンプライアンスの要件を満たすことができます。
マネージ推論機能と Azure コンピューティングおよびデータ サービスとの堅牢な統合により、サービスの使用方法を簡素化できます。
Azure Machine Learning では、データ サイエンス ライフサイクルのすべての側面がカバーされています。 モデル デプロイへのデータ ストアとデータセットの登録がカバーされています。 従来の機械学習からディープ ラーニングまで、あらゆる種類の機械学習に使用できます。 教師あり学習と教師なし学習が含まれます。 Python または R のコードを記述するか、またはデザイナーなどのコード不要またはローコード オプションを使用するかにかかわらず、Azure Machine Learning ワークスペースで正確な機械学習およびディープ ラーニング モデルの構築、トレーニング、追跡を行えます。
Azure Machine Learning、Azure プラットフォーム、Azure AI サービスを連携させることで、機械学習のライフサイクルを管理できます。 機械学習の専門家は、Azure Synapse Analytics、Azure SQL Database、または Microsoft Power BI を使用して、データの分析を開始し、プロトタイプの分析、実験の管理、運用化を行うための Azure Machine Learning への移行を行うことができます。 Azure ランディング ゾーンでは、Azure Machine Learning をデータ製品と見なすことができます。
クラウド規模の分析での Azure Machine Learning
クラウド導入フレームワーク (CAF) のランディング ゾーンの基盤、クラウド規模の分析のデータ ランディング ゾーン、Azure Machine Learning の構成により、機械学習の専門家には、新しい機械学習 ワークロードを繰り返しデプロイしたり、既存のワークロードを移行したりすることができる構成済みの環境が設定されます。 これらの機能は、機械学習の専門家が時間の機敏性と価値を高めるのに役立ちます。
次の設計原則を使用して、Azure Machine Learning の Azure ランディング ゾーンを実装することができます。
データアクセスの高速化: Azure Machine Learning ワークスペースのデータストアとして、ランディングゾーンのストレージコンポーネントを事前に構成します。
有効なコラボレーション: プロジェクトごとにワークスペースを整理し、ランディングゾーンリソースのアクセス管理を一元化して、Data Engineering、データサイエンス、機械学習の専門家による共同作業をサポートします。
セキュリティで保護された実装: 各デプロイの既定値として、ベストプラクティスに従い、ネットワーク分離、 ID 、アクセス管理を使用してデータ資産をセキュリティで保護します。
セルフサービス: 機械学習の専門家は、新しいプロジェクトリソースをデプロイするためのオプションを調べて、機敏性と組織を向上させることができます。
データ管理とデータ消費の間の懸念事項の分離: ID パススルーは、Azure Machine Learning およびストレージの既定の認証の種類です。
より高速なデータ アプリケーション (ソースへの適合済み): Azure Machine Learning にリンクするため、Azure Data Factory、Azure Synapse Analytics、Databricks ランディング ゾーンを事前に構成できます。
可観測性: 中央ログ記録と参照構成は、環境の監視に役立ちます。
実装の概要
注意
このセクションでは、クラウド規模の分析に固有の構成をお勧めします。 これにより、Azure Machine Learning のドキュメントとクラウド導入フレームワークのベスト プラクティスが補完されます。
ワークスペースの組織とセットアップ
ワークロードに必要な機械学習ワークスペースの数と、デプロイするすべてのランディングゾ ーンをデプロイできます。 次の推奨事項は、のセットアップに役立ちます。
プロジェクトごとに少なくとも1つの機械学習ワークスペースをデプロイします。
機械学習プロジェクトのライフサイクルに応じて、1つの開発 (開発) ワークスペースを使用して、プロトタイプのユースケースを作成し、データを早期に調査します。 継続的な実験、テスト、デプロイが必要な作業については、ステージングと運用のワークスペースをデプロイします。
データ ランディング ゾーンの開発、ステージング、運用の各ワークスペースに複数の環境が必要な場合は、各環境を同じ実稼働データ ランディング ゾーンに配置することで、データの重複を回避することをお勧めします。
Azure Machine Learning リソースを整理および設定する方法の詳細については、Azure MachineLearning 環境の整理とセットアップを参照してください。
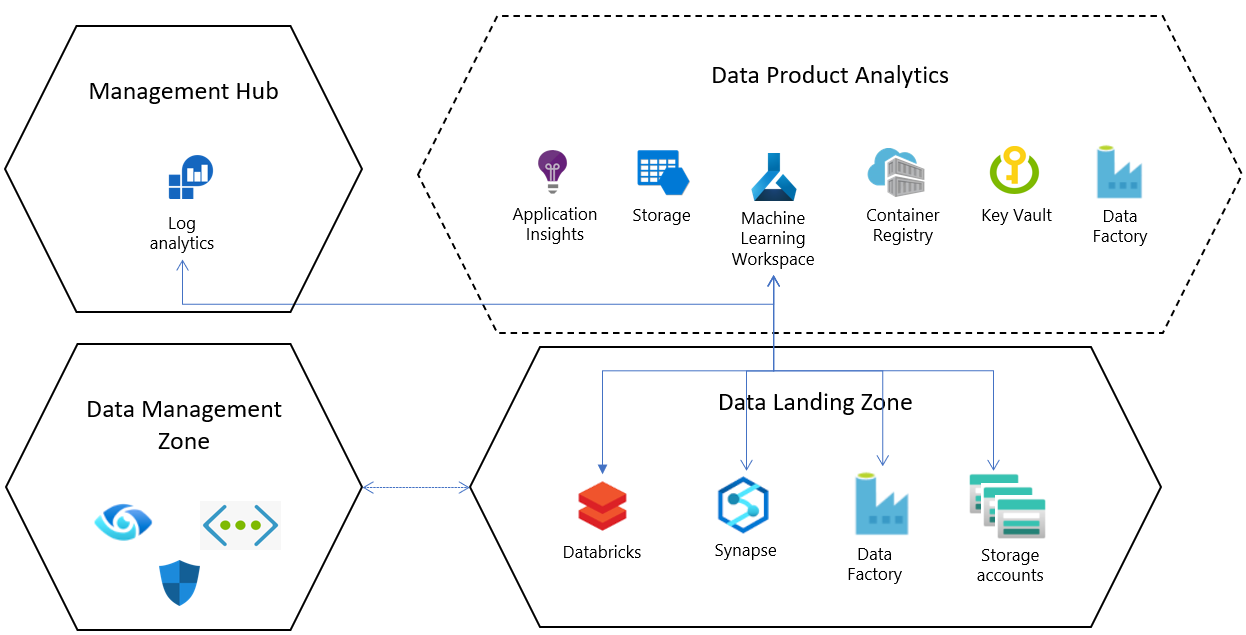
データ ランディング ゾーンでの既定のリソース構成ごとに、Azure Machine Learning service は、次の構成と依存リソースを持つ専用のリソース グループにデプロイされます。
- Azure Key Vault
- Application Insights
- Azure Container Registry
- Azure Machine Learning を使用して Azure Storage アカウントと Microsoft Entra ID ベースの認証に接続し、ユーザーがアカウントに接続できるようにします。
- 診断ログは、ワークスペースごとに設定され、エンタープライズ規模の中央の Log Analytics リソースに構成されます。これは、 Azure Machine Learning のジョブの状態とリソースのステータスを、ランディングゾーン内およびランディングゾーン間で一元的に分析するのに役立ちます。
- Azure Machine Learning リソースと依存関係の詳細については、 Azure Machine Learning ワークスペースとはを参照してください。
データ ランディング ゾーン コア サービスとの統合
データ ランディング ゾーンには、コア サービス レイヤーにデプロイされるサービスの既定のセットが付属しています。 これらのコア サービスは、Azure Machine Learning がデータ ランディング ゾーンにデプロイされるときに構成できます。
Azure Synapse Analytics または Databricks ワークスペースをリンクされたサービスとして Connect して、データを統合し、ビッグデータを処理します。
既定では、データ レイク サービスはデータ ランディング ゾーンでプロビジョニングされ、Azure Machine Learning 製品のデプロイには、これらのストレージアカウントに事前に構成された接続 (データストア) が付属します。
ネットワーク接続
Azure ランディング ゾーンで Azure Machine Learning を実装するためのネットワークは、Azure Machine Learning のセキュリティのベスト プラクティスおよび CAF ネットワークのベスト プラクティスを使用して準備されます。 これらのベスト プラクティスには、次の構成が含まれます。
- Azure Machine Learning と依存リソースは、プライベート リンク エンドポイントを使用するように構成されます。
- マネージド コンピューティング リソースは、プライベート IP アドレスを使用してのみデプロイされます。
- Azure Machine Learning パブリック基本イメージ リポジトリと、Azure Artifacts のようなパートナー サービスへのネットワーク接続は、ネットワーク レベルで構成できます。
ID 管理とアクセス管理
Azure の Azure Machine Learning でのユーザー ID とアクセスの管理については、次の推奨事項を考慮してください。
Azure Machine Learning のデータストアは、資格情報または ID ベースの認証を使用するように構成できます。 Azure Data Lake Storage Gen2 でアクセスの制御とデータ レイクの構成を使用する場合は、ID ベースの認証を使用するようにデータストアを構成します。これにより、Azure Machine Learning はストレージのユーザーアクセス許可を最適化できます。
Microsoft Entra グループを使用して、ストレージと機械学習のリソースに対するユーザーのアクセス許可を管理します。
Azure Machine Learning では、アクセス制御のためにユーザー割り当ての管理対象 IDを使用し、Azure Container Registry、キー コンテナー、Azure Storage、Application Insights へのアクセス範囲を制限できます。
Azure Machine Learning で作成されたマネージド コンピューティング クラスターにユーザー割り当てのマネージド ID を作成します。
セルフサービスによるインフラストラクチャのプロビジョニング
セルフサービスは、 Azure Machine Learning のポリシーで有効にすることができます。 次の表に、Azure Machine Learning をデプロイするときの既定のポリシーの一覧を示します。 詳細については、Azure Machine Learning 用の Azure Policy 組み込みポリシー定義に関する記事を参照してください。
| ポリシー | Type | リファレンス |
|---|---|---|
| Azure Machine Learning ワークスペースでは、 Azure Private Link を使用する必要があります。 | 組み込み | Azure portal で表示 |
| Azure Machine Learning ワークスペースではユーザー割り当てマネージド ID を使用する必要があります。 | 組み込み | Azure portal で表示 |
| [プレビュー]: 指定された Azure Machine Learning コンピューティングで許可されるレジストリを構成します | 組み込み | Azure portal で表示 |
| プライベート エンドポイントを使用して Azure Machine Learning ワークスペースを構成します。 | 組み込み | Azure portal で表示 |
| 機械学習 コンピューティングを構成してローカル認証方法を無効にします。 | 組み込み | Azure portal で表示 |
| Append-machinelearningcompute-setupscriptscreationscript | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearning-hbiworkspace | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearning-publicaccesswhenbehindvnet | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearning-AKS | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearningcompute-subnetid | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearningcompute-vmsize | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearningcomputecluster-remoteloginportpublicaccess | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
| Deny-machinelearningcomputecluster-scale | カスタム (CAF ランディング ゾーン) | GitHub 上で表示 |
環境を管理するための推奨事項
クラウド規模の分析のデータ ランディング ゾーンによって、反復可能なデプロイのための参照実装の概要が形成されています。これは、管理しやすい環境を設定するのに役立ちます。 Azure Machine Learning を使用して環境を管理する場合は、次の推奨事項を考慮してください。
Microsoft Entra グループを使用して、機械学習リソースへのアクセスを管理します。
中央監視ダッシュボードを発行して、機械学習のパイプラインの正常性、コンピューティング使用率、クォータ管理を監視します。
従来、組み込みの Azure ポリシーを使用していて、追加のコンプライアンス要件を満たす必要がある場合は、カスタム Azure ポリシーを作成して、ガバナンスとセルフサービスを強化します。
研究および開発コストを追跡するには、使用事例の初期段階で共有リソースとして、ランディング ゾーン内に1つの機械学習ワークスペースをデプロイします。
重要
運用レベルのモデル トレーニングには Azure Machine Learning クラスターを使用し、運用レベルのデプロイには Azure Kubernetes Service (AKS) を使用します。
ヒント
データ サイエンス プロジェクトには Azure Machine Learning を使用します。 サブサービスと機能を含むエンドツーエンドのワークフローがカバーされ、プロセスを完全に自動化できます。
次の手順
Data Product Analytics テンプレートとガイダンスを使用して Azure Machine Learning をデプロイし、Azure Machine Learning ドキュメントとチュートリアルを参照して、ソリューションの構築を開始します。
次の 4 つのクラウド導入フレームワークに関する記事に進んで、Azure Machine Learning のデプロイと管理に関する企業向けのベストプラクティスについて説明します。
Azure Machine Learning 環境の整理とセットアップ: Azure Machine Learning のデプロイを計画する場合、ワークスペースのセットアップ方法によって、チームの構造、環境、またはリソースの geography がどのように影響するかを検討します。
Azure Machine Learning のエンタープライズセキュリティに関するベストプラクティス: Azure Machine Learning を使用して環境とリソースをセキュリティで保護する方法について説明します。
Azure Machine Learning の予算、コスト、クォータを組織規模で管理: 組織は、Azure Machine Learning から発生したワークロード、チーム、ユーザーのコンピューティングコストを管理する際に、多くの管理と最適化の課題に直面しています。
機械学習の DevOps (MLOps) は、人、プロセス、テクノロジの組み合わせに依存して、堅牢でスケーラブル、かつ信頼性が高く自動化された方法で、機械学習ソリューションを提供するための組織改革です。 このガイドでは、Azure Machine Learning を使用して機械学習 DevOps を採用するためのベストプラクティスと情報をまとめています。