Azure Machine Learning のエンタープライズ セキュリティに関するベスト プラクティス
この記事では、セキュリティで保護された Azure Machine Learning のデプロイを計画または管理するためのセキュリティに関するベスト プラクティスについて説明します。 ベスト プラクティスは、Azure Machine Learning に関する Microsoft およびカスタマー エクスペリエンスに基いています。 各ガイドラインでは、慣例とその根拠について説明します。 この記事には、方法とリファレンス ドキュメントへのリンクも示されています。
推奨されるネットワーク セキュリティ アーキテクチャ (マネージド ネットワーク)
推奨される機械学習ネットワーク セキュリティ アーキテクチャは、マネージド仮想ネットワークです。 Azure Machine Learning のマネージド仮想ネットワークは、ワークスペース、関連する Azure リソース、およびすべてのマネージド コンピューティング リソースをセキュリティで保護します。 必要な出力を事前に構成し、ネットワーク内にマネージド リソースを自動的に作成することで、ネットワーク セキュリティの構成と管理が簡素化されます。 プライベート エンドポイントを使用して、Azure サービスがネットワークにアクセスできるようにしたり、必要に応じて、ネットワークがインターネットにアクセスできるようにアウトバウンド規則を定義したりできます。
マネージド仮想ネットワークは、次の 2 つのモードを構成できます。
[Allow internet outbound](インターネット アウトバウンドを許可する) - このモードでは、パブリック PyPi や Anaconda パッケージ リポジトリなど、インターネット上にあるリソースとのアウトバウンド通信が許可されます。

[Allow only approved outbound](承認済みのアウトバウンドのみを許可する) - このモードでは、ワークスペースが機能するために必要な最小限のアウトバウンド通信のみが許可されます。 このモードは、インターネットから分離する必要があるワークスペースに推奨されます。 または、サービス エンドポイント、サービス タグ、または完全修飾ドメイン名を介して特定のリソースに対してのみアウトバウンド アクセスが許可される場合です。

詳細については、マネージド仮想ネットワーク分離に関する記事をご覧ください。
推奨されるネットワーク セキュリティ アーキテクチャ (Azure Virtual Network)
ビジネス要件のためにマネージド仮想ネットワークを使用できない場合は、次のサブネットを持つ Azure 仮想ネットワークを使用できます。
- トレーニングには、トレーニングに使用されるコンピューティング リソース (Machine Learning コンピューティング インスタンスやコンピューティング クラスターなど) が含まれています。
- スコアリングには、スコアリングに使用されるコンピューティング リソース (Azure Kubernetes Service (AKS) など) が含まれています。
- ファイアウォールには、パブリック インターネットとの間のトラフィックを許可するファイアウォール (Azure Firewall など) が含まれています。
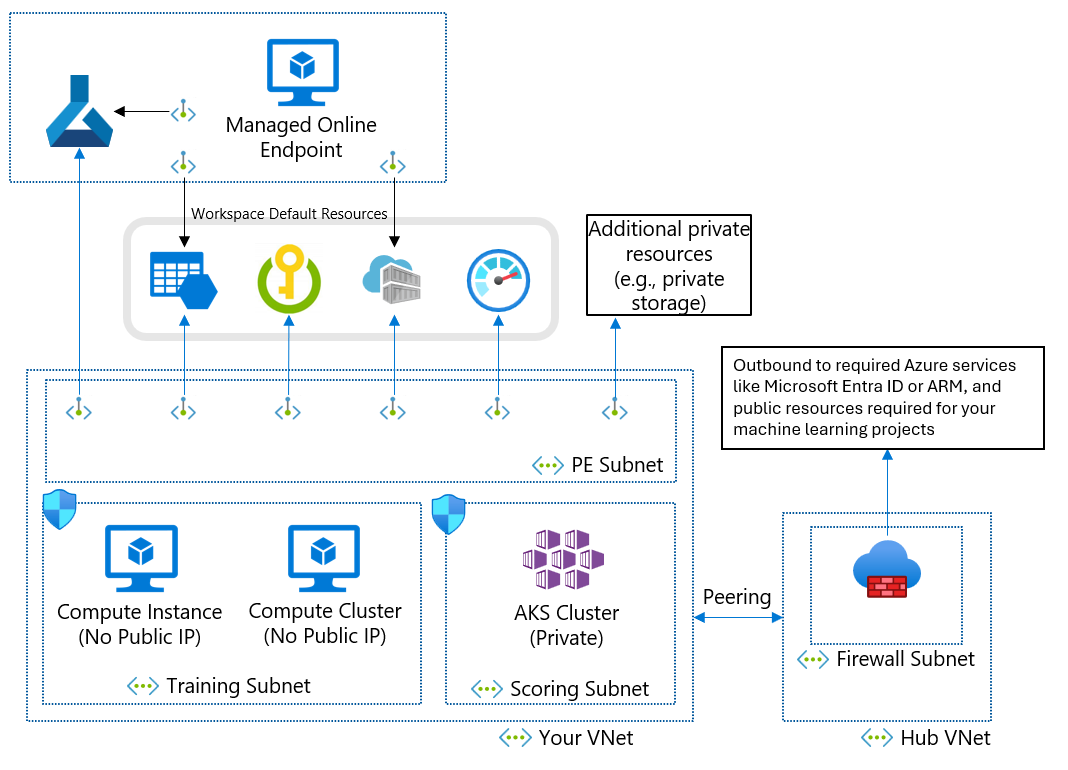
仮想ネットワークには、機械学習ワークスペースと次の依存サービス用の "プライベート エンドポイント" も含まれています。
- Azure ストレージ アカウント
- Azure Key Vault
- Azure Container Registry
仮想ネットワークからの "送信方向" の通信は、次の Microsoft サービスに到達できる必要があります。
- 機械学習
- Microsoft Entra ID
- Azure Container Registry、Microsoft が管理する特定のレジストリ
- Azure Front Door
- Azure Resource Manager
- Azure Storage
リモート クライアントは、Azure ExpressRoute または仮想プライベート ネットワーク (VPN) 接続を使用して、仮想ネットワークに接続します。
仮想ネットワークとプライベート エンドポイントの設計
Azure Virtual Network、サブネット、プライベート エンドポイントを設計する際は、次の要件を考慮してください。
一般に、トレーニングとスコアリング用に別々のサブネットを作成し、すべてのプライベート エンドポイントに対してトレーニング サブネットを使用します。
IP アドレス指定の場合、コンピューティング インスタンスにはそれぞれ 1 つのプライベート IP が必要です。 コンピューティング クラスターには、ノードごとに 1 つのプライベート IP が必要です。 AKS クラスターには多数のプライベート IP アドレスが必要です (AKS クラスターの IP アドレス指定の計画に関する記事に説明があります)。 少なくとも AKS 用に別個のサブネットを使用すると、IP アドレスの枯渇を防ぐのに役立ちます。
トレーニングとスコアリングの各サブネット内のコンピューティング リソースは、ストレージ アカウント、キー コンテナー、コンテナー レジストリにアクセスする必要があります。 ストレージ アカウント、キー コンテナー、およびコンテナー レジストリ用の各プライベート エンドポイントを作成します。
Machine Learning ワークスペースの既定のストレージには、2 つのプライベート エンドポイントが必要です。1 つは Azure Blob Storage 用で、もう 1 つは Azure File Storage 用です。
Azure Machine Learning スタジオを使用する場合、ワークスペースとストレージのプライベート エンドポイントは同じ仮想ネットワーク内に存在する必要があります。
複数のワークスペースがある場合は、ワークスペースごとに 1 つの仮想ネットワークを使用し、ワークスペース間に明示的なネットワーク境界を作成します。
プライベート IP アドレスを使用する
プライベート IP アドレスを使用すると、インターネットへの Azure リソースの露出を最小限に抑えられます。 Machine Learning では多数の Azure リソースが使用されるため、Machine Learning ワークスペースのプライベート エンドポイントは、エンドツーエンドのプライベート IP には十分ではありません。 次の表に、機械学習で使用される主要なリソースと、そのリソースのプライベート IP を有効にする方法を示します。 コンピューティング インスタンスとコンピューティング クラスターのみが、プライベート IP 機能を持たないリソースです。
| リソース | プライベート IP のソリューション | ドキュメント |
|---|---|---|
| ワークスペース | プライベート エンドポイント | Azure Machine Learning ワークスペース用にプライベート エンドポイントを構成する |
| レジストリ | プライベート エンドポイント | Azure Machine Learning レジストリを使ったネットワーク分離 |
| 関連付けられているリソース | ||
| ストレージ | プライベート エンドポイント | サービス エンドポイントを使用して Azure Storage アカウントをセキュリティで保護する |
| Key Vault | プライベート エンドポイント | Azure Key Vault をセキュリティで保護する |
| Container Registry | プライベート エンドポイント | Azure Container Registry の有効化 |
| トレーニングのリソース | ||
| コンピューティング インスタンス | プライベート IP (パブリック IP なし) | トレーニング環境の保護 |
| コンピューティング クラスター | プライベート IP (パブリック IP なし) | トレーニング環境の保護 |
| ホスティング リソース | ||
| マネージド オンライン エンドポイント | プライベート エンドポイント | マネージド オンライン エンドポイントでのネットワークの分離 |
| オンライン エンドポイント (Kubernetes) | プライベート エンドポイント | Azure Kubernetes Service オンライン エンドポイントをセキュリティで保護する |
| バッチ エンドポイント | プライベート IP (コンピューティング クラスターから継承) | バッチ エンドポイントでのネットワークの分離 |
仮想ネットワークの受信および送信トラフィックを制御する
仮想ネットワークの受信および送信トラフィックを制御するには、ファイアウォールまたは Azure ネットワーク セキュリティ グループ (NSG) を使用します。 受信および送信の要件の詳細については、「ネットワークの着信トラフィックおよび送信トラフィックを構成する」を参照してください。 コンポーネント間のトラフィック フローの詳細については、セキュリティで保護されたワークスペースのネットワーク トラフィック フローに関する記事を参照してください。
ワークスペースへのアクセスを確保する
プライベート エンドポイントが Machine Learning ワークスペースに確実にアクセスできるようにするには、次の手順を実行します。
VPN 接続、ExpressRoute、Azure Bastion へのアクセス権を持つジャンプボックス仮想マシン (VM) を使用して仮想ネットワークにアクセスできることを確認します。 プライベート エンドポイントには自身の仮想ネットワークからのみアクセスできるため、パブリック ユーザーはこれを使用して Machine Learning ワークスペースにアクセスすることはできません。 詳細については、仮想ネットワークを使用してワークスペースを保護することに関するページを参照してください。
プライベート IP アドレスを使用してワークスペースの完全修飾ドメイン名 (FQDN) を解決できることを確認します。 独自のドメイン ネーム システム (DNS) サーバーまたは一元化された DNS インフラストラクチャを使用する場合は、DNS フォワーダーを構成する必要があります。 詳細については、「カスタム DNS サーバーでワークスペースを使用する方法」を参照してください。
ワークスペースのアクセス管理
Machine Learning の ID およびアクセス管理の制御を定義するとき、Azure リソースへのアクセスを定義する制御と、データ資産へのアクセスを管理する制御を分離することができます。 ユース ケースに応じて、"セルフサービス"、"データ中心"、または "プロジェクト中心" の ID およびアクセス管理の使用するかどうかを検討します。
セルフサービスのパターン
セルフサービスのパターンでは、データ サイエンティストがワークスペースを作成し、管理できます。 このパターンは、さまざまな構成を試す柔軟性が必要な概念実証の状況に最適です。 欠点は、Azure リソースをプロビジョニングする専門知識がデータ サイエンティストに必要であることです。 この手法は、厳密な制御、リソースの使用、監査トレース、データ アクセスが必要な場合にはあまり適していません。
Azure ポリシーを定義して、許可されるクラスター サイズや VM の種類など、リソースのプロビジョニングと使用についての安全対策を設定します。
ワークスペースを保持するためのリソース グループを作成し、そのリソース グループでの共同作成者ロールをデータ サイエンティストに付与します。
これにより、データ サイエンティストはセルフサービスの方法でワークスペースを作成し、リソース グループのリソースを関連付けられるようになりました。
データ ストレージにアクセスするには、ユーザー割り当てのマネージド ID を作成し、ストレージに対する読み取りアクセス ロールをそれらの ID に付与します。
データ サイエンティストは、コンピューティング リソースを作成するとき、マネージド ID をコンピューティング インスタンスに割り当ててデータ アクセスを取得できます。
ベスト プラクティスについては、「Azure でのクラウド規模の分析の認証」を参照してください。
データ中心のパターン
データ中心のパターンでは、ワークスペースは、複数のプロジェクトに取り組む可能性がある 1 人のデータ サイエンティストに属しています。 この手法の利点は、データ サイエンティストがプロジェクト間でコードまたはトレーニング パイプラインを再利用できることです。 ワークスペースが 1 人のユーザーに限定されている限り、ストレージ ログの監査時、データ アクセスはそのユーザーまで遡ることができます。
欠点は、データ アクセスがプロジェクトごとに区分化も制限もされないため、ワークスペースに追加されたすべてのユーザーが同じ資産にアクセスできることです。
ワークスペースを作成します。
システム割り当てマネージド ID を有効にしたコンピューティング リソースを作成します。
データ サイエンティストが特定のプロジェクトのデータにアクセスする必要がある場合は、コンピューティング マネージド ID に、そのデータに対する読み取りアクセスを付与します。
トレーニング用のカスタム Docker イメージを含むコンテナー レジストリなど、その他の必要なリソースへのアクセス権を、コンピューティング マネージド ID に付与します。
また、ワークスペースのマネージド ID に、データに対する読み取りアクセス ロールを付与して、データ プレビューを有効にします。
データ サイエンティストに、ワークスペースへのアクセス権を付与します。
これで、データ サイエンティストは、プロジェクトに必要なデータにアクセスするためのデータ ストアを作成し、そのデータを使用するトレーニングの実行を送信できるようになります。
必要に応じて、Microsoft Entra セキュリティ グループを作成し、データに対する読み取りアクセス権をそれに付与してから、マネージド ID をセキュリティ グループに追加します。 この手法により、リソースに対するロールの直接割り当ての数が削減され、ロール割り当てのサブスクリプション制限に達することが回避されます。
プロジェクト中心のパターン
プロジェクト中心のパターンでは、特定のプロジェクト用の Machine Learning ワークスペースが作成され、多くのデータ サイエンティストが同じワークスペース内で共同作業を行います。 データ アクセスが特定のプロジェクトに限定されるため、この手法は機密データの処理によく適しています。 また、プロジェクトに対してデータ サイエンティストを追加または削除することも簡単です。
この手法の欠点は、プロジェクト間での資産の共有が困難な場合があることです。 また、監査中にデータ アクセスを特定のユーザーまでたどることも困難です。
ワークスペースを作成する
プロジェクトに必要なデータ ストレージ インスタンスを特定し、ユーザー割り当てマネージド ID を作成して、ストレージに対する読み取りアクセス権をその ID に付与します。
必要に応じて、ワークスペースのマネージド ID に、データ ストレージへのアクセス権を付与して、データ プレビューを許可します。 プレビューに適さない機密データについては、このアクセスを除外できます。
ストレージ リソース用に資格情報を使用しないデータ ストアを作成します。
ワークスペース内にコンピューティング リソースを作成し、マネージド ID をコンピューティング リソースに割り当てます。
トレーニング用のカスタム Docker イメージを含むコンテナー レジストリなど、その他の必要なリソースへのアクセス権を、コンピューティング マネージド ID に付与します。
プロジェクトに取り組むデータ サイエンティストに、ワークスペースに対するロールを付与します。
Azure ロールベースのアクセス制御 (RBAC) を使用することにより、データ サイエンティストがさまざまなマネージド ID を使用して新しいデータストアや新しいコンピューティング リソースを作成することを制限できます。 この方法により、プロジェクトに固有ではないデータへのアクセスが阻止されます。
必要に応じて、プロジェクト メンバーシップ管理を簡略化するために、プロジェクト メンバー用の Microsoft Entra セキュリティ グループを作成し、そのグループにワークスペースへのアクセス権を付与できます。
資格情報のパススルーを備えた Azure Data Lake Storage
Machine Learning スタジオからの対話型ストレージ アクセスには、Microsoft Entra ユーザー ID を使用できます。 階層型名前空間が有効になっている Data Lake Storage では、ストレージとコラボレーションのためにデータ資産の編成を強化できます。 Data Lake Storage 階層型名前空間を使用すると、異なるフォルダーおよびファイルへのアクセス制御リスト (ACL) ベースのアクセス権を異なるユーザーに付与することで、データ アクセスを区分化できます。 たとえば、機密データへのアクセス権をユーザーのサブセットにのみ付与できます。
RBAC とカスタム ロール
Azure RBAC は、機械学習リソースにアクセスできるユーザーを管理したり、操作を実行できるユーザーを構成したりするのに役立ちます。 たとえば、コンピューティング リソースを管理するために、ワークスペース管理者ロールを特定のユーザーのみに付与することが必要な場合があります。
アクセス スコープは環境によって異なる可能性があります。 運用環境では、推論エンドポイントを更新するユーザーの機能を制限することが必要な場合もあります。 代わりに、承認されたサービス プリンシパルにそのアクセス許可を付与する場合もあります。
Machine Learning には、所有者、共同作成者、閲覧者、データ サイエンティストという既定のロールがあります。 たとえば組織の構造を反映するアクセス許可を作成するために、独自のカスタム ロールを作成することもできます。 詳細については、「Azure Machine Learning ワークスペースへのアクセスの管理」を参照してください。
時間の経過に伴い、チームの構成が変わる可能性があります。 チーム ロールとワークスペースごとに Microsoft Entra グループを作成する場合は、Azure RBAC ロールを Microsoft Entra グループに割り当て、リソース アクセスとユーザー グループを個別に管理できます。
ユーザー プリンシパルとサービス プリンシパルは、同じ Microsoft Entra グループの一部であってもかまいません。 たとえば、Azure Data Factory で使用されるユーザー割り当てマネージド ID を作成して Machine Learning パイプラインをトリガーする場合、このマネージド ID を ML パイプライン実行者 Microsoft Entra グループに含めることができます。
Docker イメージの一元管理
Azure Machine Learning では、トレーニングとデプロイに使用できるキュレーション Docker イメージが提供されます。 ただし、企業のコンプライアンス要件により、会社が管理するプライベート リポジトリからのイメージの使用が義務付けられている場合もあります。 Machine Learning には、中央リポジトリを使用する方法が 2 つあります。
中央リポジトリのイメージを基本イメージとして使用する。 Machine Learning の環境管理によってパッケージがインストールされ、トレーニングまたは推論コードが実行される Python 環境が作成されます。 この手法では、基本イメージを変更することなく、パッケージの依存関係を簡単に更新できます。
イメージをそのまま使用し、Machine Learning の環境管理を使用しない。 この手法では、より高いレベルの制御が可能になりますが、イメージの一部として Python 環境を慎重に構築する必要もあります。 コードを実行するために必要なすべての依存関係を満たす必要があり、新しい依存関係が追加されるたびにイメージのリビルドが必要になります。
詳細については、「環境を管理する」を参照してください。
データの暗号化
Machine Learning の保存データには、2 つのデータ ソースがあります。
ストレージには、トレーニング データやトレーニング済みのモデル データなど、メタデータを除くすべてのデータが含まれています。 ストレージの暗号化はご自身で行う必要があります。
Azure Cosmos DB には、実験名や実験の送信日時などの実行履歴情報を含むメタデータが含まれます。 ほとんどのワークスペースでは、Azure Cosmos DB は Microsoft サブスクリプションに含まれ、Microsoft マネージド キーによって暗号化されます。
独自のキーを使用してメタデータを暗号化する必要がある場合は、カスタマー マネージド キーのワークスペースを使用できます。 欠点は、自分のサブスクリプション内に Azure Cosmos DB を用意し、そのコストを支払う必要がある点です。 詳細については、Azure Machine Learning を使用したデータの暗号化に関するページを参照してください。
転送中のデータを Azure Machine Learning で暗号化する方法については、「転送中の暗号化」を参照してください。
監視
Machine Learning リソースをデプロイする場合は、監視のログ記録と監査制御を設定します。 データを監視する目的は、データを調べるユーザーによって異なる場合があります。 シナリオには以下が含まれます。
機械学習の実務者や運用チームは、機械学習パイプラインの正常性を監視する必要があります。 これらの監視者は、スケジュールされた実行の問題、またはデータ品質や予期されたトレーニング パフォーマンスに関する問題を把握する必要があります。 Azure Machine Learning データを監視する Azure ダッシュボードを作成したり、イベント ドリブン ワークフローを作成したりできます。
容量マネージャー、機械学習の実務者、または運用チームは、コンピューティングとクォータの使用率を監視するためのダッシュボードを作成する必要がある場合もあります。 複数の Azure Machine Learning ワークスペースを含むデプロイを管理するには、一元的なダッシュボードを作成してクォータ使用率を把握することを検討してください。 クォータはサブスクリプション レベルで管理されるため、環境全体の表示は、最適化を推進するために重要です。
IT および運用チームは、ワークスペース内のリソース アクセスとイベントの変更を監査するために診断ログを設定できます。
Machine Learning と、ストレージなどの依存リソースに対して、インフラストラクチャの全体的な正常性を監視するダッシュボードを作成することを検討します。 たとえば、Azure Storage メトリックをパイプライン実行データと組み合わせると、パフォーマンス向上のためにインフラストラクチャを最適化したり、問題の根本原因を検出したりする際に役立ちます。
Azure では、プラットフォームのメトリックとアクティビティ ログが自動的に収集され、格納されます。 診断設定を使用することで、他の場所にデータをルーティングできます。 複数のワークスペース インスタンスにわたる可観測性を実現するためには、一元化された Log Analytics ワークスペースへの診断ログを設定します。 この一元化された Log Analytics ワークスペースに新しい Machine Learning ワークスペースのログを自動的に設定するには、Azure Policy を使用します。
Azure Policy
Azure Policy を通じて、ワークスペースでのセキュリティ機能の使用を強制および監査できます。 推奨事項は次のとおりです。
- カスタム マネージド キーの暗号化を強制します。
- Azure Private Link とプライベート エンドポイントを強制します。
- プライベート DNS ゾーンを強制します。
- Secure Shell (SSH) など、Azure AD 以外の認証を無効にします。
詳細については、Azure Machine Learning 用の組み込みポリシー定義に関する記事を参照してください。
また、カスタム ポリシー定義を使用すると、ワークスペースのセキュリティを柔軟な方法で管理できます。
コンピューティング クラスターおよびインスタンス
Machine Learning コンピューティング クラスターおよびインスタンスには、次の考慮事項とレコメンデーションが適用されます。
ディスクの暗号化
コンピューティング インスタンスまたはコンピューティング クラスター ノードのオペレーティング システム (OS) ディスクは Azure Storage に格納され、Microsoft マネージド キーで暗号化されます。 各ノードには、ローカル一時ディスクもあります。 hbi_workspace = True パラメーターを使用してワークスペースを作成した場合、この一時ディスクも Microsoft マネージド キーで暗号化されます。 詳細については、Azure Machine Learning を使用したデータの暗号化に関するページを参照してください。
マネージド ID
コンピューティング クラスターでは、マネージド ID を使用した Azure リソースへの認証がサポートされています。 クラスターにマネージド ID を使用すると、コード内で資格情報を露出させることなく、リソースに対する認証が可能になります。 詳細については、「Azure Machine Learning コンピューティング クラスターの作成」を参照してください。
セットアップ スクリプト
セットアップ スクリプトを使用すると、作成時にコンピューティング インスタンスのカスタマイズと構成を自動化できます。 管理者は、ワークスペースにすべてのコンピューティング インスタンスを作成する際に使用するカスタマイズ スクリプトを記述できます。 Azure Policy を使用すると、セットアップ スクリプトを使用してすべてのコンピューティング インスタンスを作成するように強制できます。 詳細については、「Azure Machine Learning コンピューティング インスタンスの作成と管理」を参照してください。
代理での作成
データ サイエンティストにコンピューティング リソースをプロビジョニングさせたくない場合は、代わりに自分でコンピューティング インスタンスを作成し、それをデータ サイエンティストに割り当てることができます。 詳細については、「Azure Machine Learning コンピューティング インスタンスの作成と管理」を参照してください。
プライベート エンドポイントが有効なワークスペース
プライベート エンドポイントが有効なワークスペースを含むコンピューティング インスタンスを使用します。 そのコンピューティング インスタンスでは、仮想ネットワークの外部からのすべてのパブリック アクセスが拒否されます。 この構成ではパケット フィルタリングも防止されます。
Azure Policy のサポート
Azure 仮想ネットワークを使用する場合は、Azure Policy を使用して、すべてのコンピューティング クラスターまたはインスタンスを仮想ネットワーク内に確実に作成し、既定の仮想ネットワークとサブネットを指定できます。 コンピューティング リソースはマネージド仮想ネットワークに自動的に作成されるため、"マネージド仮想ネットワーク" を使用する場合には、ポリシーは必要ありません。
また、ポリシーを使用して、SSH など、Azure AD 以外の認証を無効にすることもできます。
次のステップ
Machine Learning のセキュリティ構成の詳細を理解する:
Machine Learning のテンプレート ベースのデプロイを開始する:
Machine Learning のデプロイにおけるアーキテクチャ上の考慮事項に関する記事をさらに読む:
チームの構造、環境、またはリージョンの制約がワークスペースのセットアップに与える影響について理解します。
チームとユーザーにわたってコンピューティング コストと予算を管理する方法を確認します。
人、プロセス、技術の組み合わせて使用する機械学習 DevOps (MLOps) と、堅牢で信頼性の高い自動機械学習ソリューションを提供する技術について理解します。