Azure でのクラウド規模の分析のデータ製品
データ製品は、製品として提供されるデータで、ポリグロットな永続化サービスによって計算、保存、および提供され、特定のユース ケースで必要になる場合があります。 データ製品を作成して提供するプロセスには、データ ランディング ゾーン のコア サービスに含まれていないサービスとテクノロジが必要になる場合があります。 たとえば、コンプライアンスや税金の報告など、ニッチな要件を含むレポートがあります。
設計上の考慮事項
データ ランディング ゾーンは、同じデータ ランディング ゾーン内または複数のデータ ランディング ゾーン全体からデータを取り込むことによって作成される、複数のデータ製品を提供することができます。 これを次の図に示します。
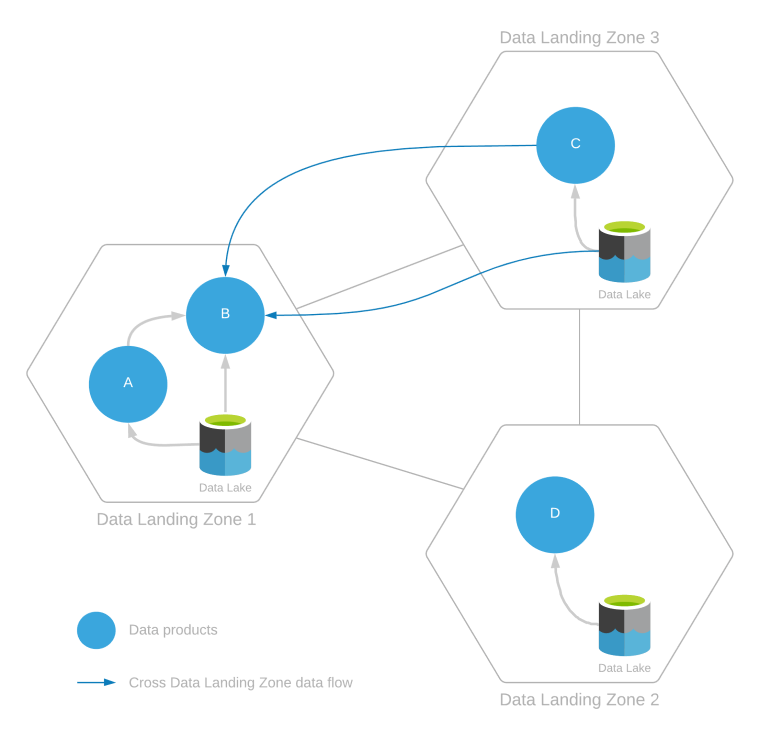
上記の例では、次のことが示されています。
- ゾーン内データの消費量:
- データ製品 B は、データ製品 A および自身のランディング ゾーン内のデータ レイクに存在する他のデータまたはデータ製品からのデータを使用します。
- データ製品 C と D は、それぞれのデータ ランディング ゾーン内のみでデータを使用します。
- ゾーン間のデータ消費量:
- データ製品 B は、データ製品 C のデータと、ランディング ゾーン 3 のデータ レイクのデータも使用します。
重要
ゾーン間のデータ消費の場合、データ製品 B はデータ ランディング ゾーン 3 からの読み取りで作成されるため、この読み取りアクセスにはデータ ランディング ゾーン 3 のデータ ランディング ゾーン運用チームおよび統合運用チームからの承認が必要になります。
重要
データ製品 B は、データ製品 A および C のデータを使用します。これが行われる前に、データ製品 B からデータ共有契約を通じてデータ製品の消費が登録される必要があります。 このデータ共有契約では、データ製品 A からデータ製品 B への、およびデータ製品 C からデータ製品 B への系列を更新する必要があります。
データ製品のリソース グループには、データ製品の作成と保守に必要なすべてのサービスが含まれます。 このリソース グループをデータ アプリケーションと呼びます。 データ アプリケーションに含まれる可能性のあるサービスの例としては、Azure Functions、Azure App Service、Logic Apps、Azure Analysis Services、Azure Cognitive Services、Azure Machine Learning、Azure SQL Database、Azure Database for MySQL、Azure Cosmos DB などがあります。 詳細については、「データ アプリケーションの例」を参照してください。
データ製品は、いくつかのデータ変換が適用された READ データ ソースのデータを所有します。 たとえば、新しくキュレーションされたデータセットや BI レポートなどです。
設計の推奨事項
データ ガバナンスによるスケーリングを可能にする設計原則に従って、データ ランディング ゾーン内でデータ製品を構築します。 次のセクションでは、データ アプリケーション エコシステムを計画する際に役立つ設計の推奨事項を示します。
複数のリソース グループをデプロイする
各データ アプリケーションは 1 つのリソース グループです。 データ アプリケーションはコンピューティング サービス、ポリグロットな永続化サービス、またはその両方であるため、特定のユース ケースによってのみ必要になる場合があります。 そのため、オプションのデータ ランディング ゾーン コンポーネントであると見なされます。 データ アプリケーションが必要な場合は、次の図に示すように、データ アプリケーション別に複数のリソース グループを作成します。

ガードレールを設定する
Azure Policy によって、データ ランディング ゾーン内のサービスの既定の構成が推進されます。 運用分析は、データ製品チームが標準のサービス カタログに要求できる複数のリソース グループと見なしてください。 Azure Policy を使用すると、セキュリティ境界と必要な機能セットを構成できます。
重要
一貫性を推進するには、データ アプリケーションごとに 1 つの Azure Policy を構成します。
複数の場所からのデータを消費する
データ アプリケーションは、複数のデータアセットからのデータを管理、整理、理解し、得られた分析情報を提示するものです。 データ製品は、データ ランディング ゾーン内の 1 つまたは複数のデータ アプリケーションからのデータの結果です。 必要に応じて、データ アプリケーションが複数のさまざまなソースからデータにアクセスできるようにします。
必要に応じてスケーリングする
データ アプリケーションを構成するサービスは、データ ランディング ゾーンへの増分デプロイです。 必要に応じてデータ アプリケーションをスケーリングします。
データ検出を有効にする
データのスキャンを許可するために、Azure Purview などのデータ カタログにデータ製品を自動的に登録します。
データ製品を特定する
データ ランディング ゾーンの計画を開始するときに、データ製品のアプリケーション アーキテクチャを推進するために必要な数のデータ製品 (およびそれらを出力して維持するデータ アプリケーション) を特定します。 プラットフォーム ガバナンスの実装への準拠は、意思決定において最大の役割を果たす必要があります。
データ アプリケーションが他のものに対して、どのようにデータのプロデューサーおよびコンシューマーであるかに焦点を合わせます。 たとえば、データを生成および使用する一連のデータ製品 (A、B、C、D) を特定したと仮定しましょう。 データ製品 B のためのデータ アプリケーション B のデータのソースとして、データ製品 A と D が必要です。データ製品 B は、データ 製品 A と D からデータ アプリケーション B が使用するデータから作成されます。データ アプリケーション B はデータ プロデューサー自体として機能し、データ製品 C のデータも生成します。
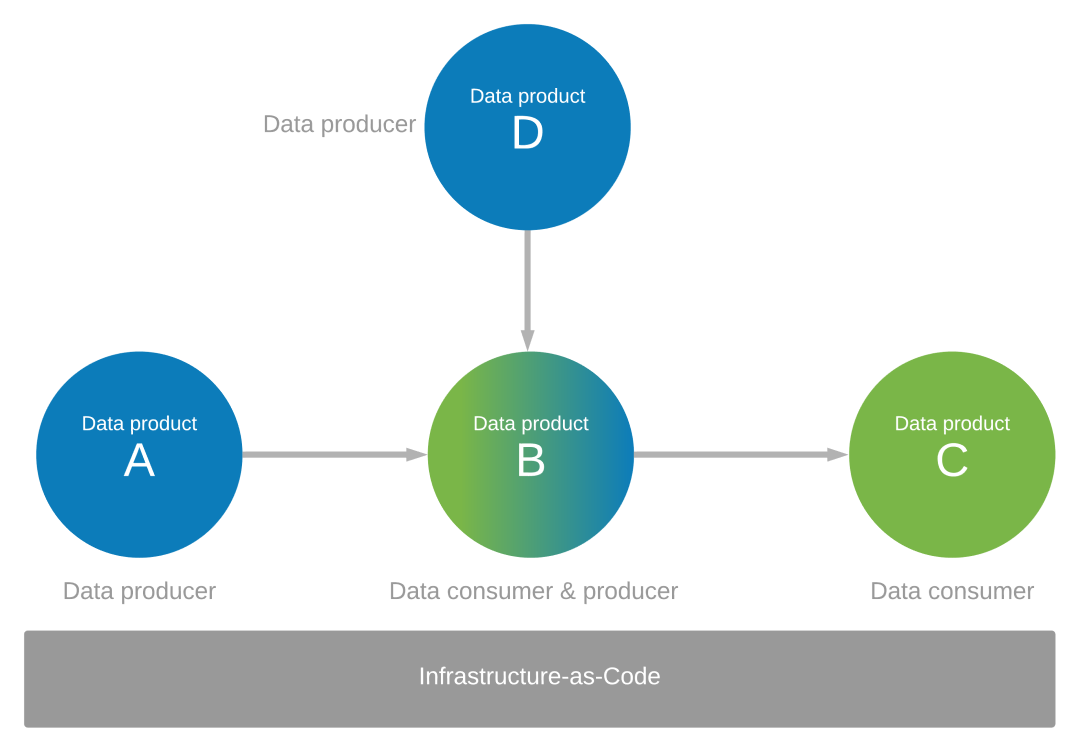
Infrastructure as Codeを使用してデータ アプリケーション環境を制御する
上記の図に示すように、ガバナンスとInfrastructure as Codeによって、データ製品エコシステム全体にわたるデータ アプリケーション環境を制御する必要があります。
データ モデルを公開する
データ製品チームは、データ モデルをモデリング リポジトリに公開する必要があります。
データ製品ユーザーの期待値を設定する
データ製品の潜在的なユーザーに正確な期待値を伝えるために、データ製品のサービス レベル アグリーメントと証明書を使用してデータ共有コントラクトを更新します。
系列の取り込み
データ製品 A と D のデータからデータ製品 B を作成する場合は、系列を A と D から B にキャプチャする必要があります。データ製品 B のデータを使用して作成されるため、データ製品 C についてもさらに系列をキャプチャする必要があります。更新された系列は、必ずデータ製品のリリースの前にデータ系列アプリケーションでキャプチャする必要があります。
Note
Azure Pipelines を使用すると、承認ゲートを構築して関数を呼び出し、メタデータ、系列、および SLA が適切なガバナンス サービスに登録されていることを確認できます。
データ アプリケーション アーキテクチャを定義する
他のデータ製品との関係、依存関係、およびアクセス要件を完全に定義する各データ製品の詳細なアーキテクチャを作成する必要があります。
設計シナリオの例
アーキテクチャ定義プロセスを理解するために、金融機関とそのクレジット監視データ製品に関する次の例を見ていきます。
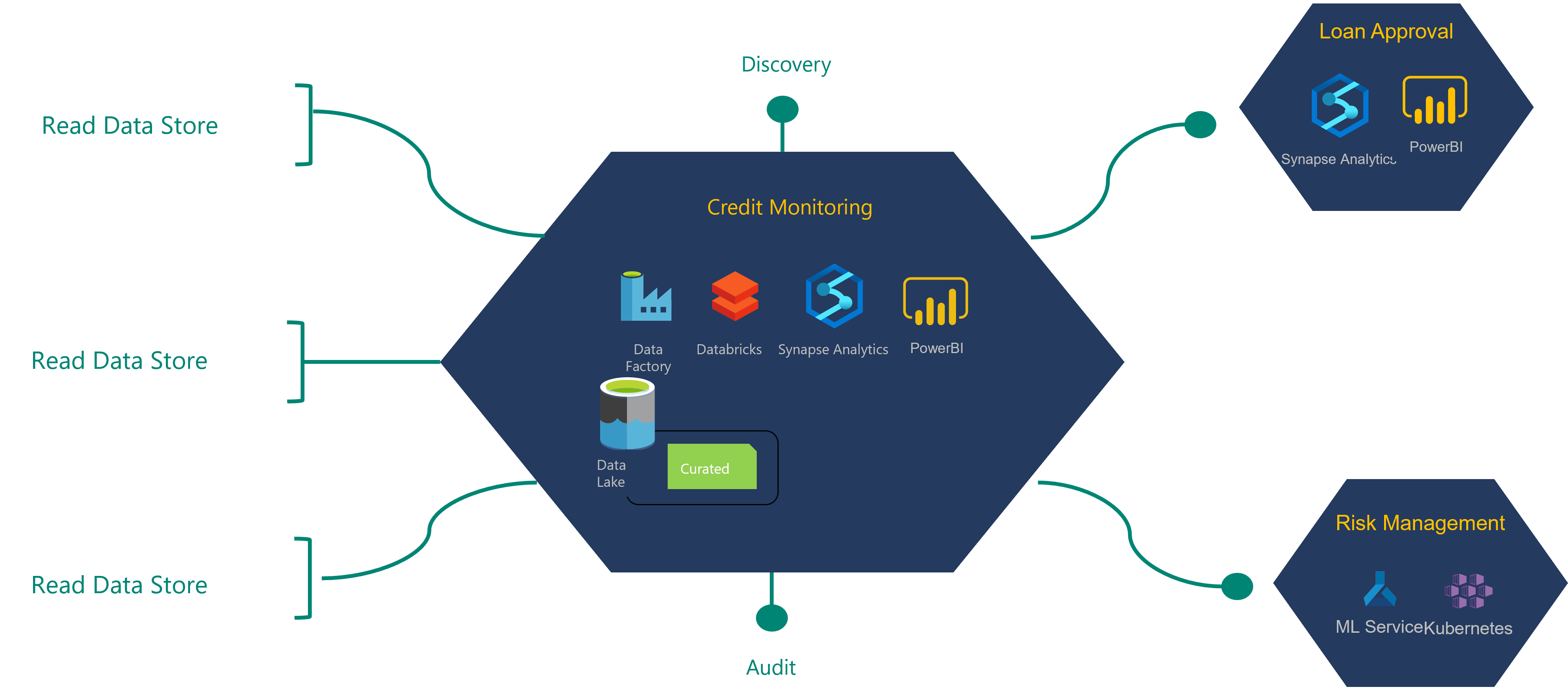
この図に示したクレジット監視データ製品の場合、"統合運用チーム" によって取り込まれた "読み取りデータ ストア" のデータを使用します。 また、他の 2 つのデータ製品によって使用されるデータ製品も生成されます。
Note
読み取りデータ ソースまたはストアは、ゴールデン レコード ソースとも呼ばれます。 このデータ ソースはクリーニング済みですが、変換が適用されていません。
クレジット監視データ製品チームは、データ製品の作成に必要な読み取りデータ ストアへの読み取りアクセス権を要求します。 このような要求は、承認のためにデータの所有者にルーティングされます。 承認を受けると、製品チームはデータ アプリケーションの構築を開始できます。
読み取りデータ ソースのデータは、クレジット監視データ製品に変換されます。 新しいデータ製品はすべて、データ レイクのキュレーションされたレイヤーに格納されます。 これらの新しいデータ製品と新しいデータ系列は、DevOps デプロイ プロセスの一環として登録される必要があります。 関数によって、登録されたメタデータをデータアセットの物理的な構造に照らしてチェックできます。 それによって、読み取りデータ ソースのデータアセットとデータ製品に対する依存関係を登録することになります。
ローン承認データ製品チームは、クレジット監視データ製品の一部に依存しています。 ローン承認チームは、データ製品に必要なクレジット監視データ製品への読み取りアクセスを要求する可能性があります。 ローン承認データ製品とそのデータ アプリケーションがリリースされたら、すべてのデータ製品アセット、系列、モデルを関連するガバナンス サービスに登録する必要があります。
データ アプリケーションの例
次のセクションには、データ アプリケーションのシナリオをさらに詳しく説明するためのデータ アプリケーションの例が含まれています。
データ分析とデータ サイエンスのデータ アプリケーション
データ分析とデータ サイエンスのためのアプリケーションには、データ アプリケーションの例 product-analytics-rg に示すサービスが含まれている可能性があります。

Note
上記のデータ アプリケーションをテンプレートとして使用できます。 このテンプレートは、データ分析とデータ サイエンスに使用できる一連のサービスをデプロイします。 このデータ製品アプリケーション テンプレートを使用すると、部門を超えたチームのための環境を迅速に作成できます。 不要なサービスはすべて、明示的に無効にする必要があります。
データ製品分析テンプレートには、クラウド規模の分析シナリオのデータ ランディング ゾーン内に分析およびデータ サイエンス用のデータ製品をデプロイするためのすべてのテンプレートが含まれています。
デプロイとコード成果物には、次のサービスが含まれます。
- Machine Learning
- Key Vault
- Application Insights
- Storage
- コンテナー レジストリ
- Cognitive Services (オプション)
- Data Factory (Data Factory と Synapse のどちらかを選択)
- Synapse ワークスペース (Data Factory と Synapse のどちらかを選択)
- Azure Search (オプション)
- SQL プール (オプション)
- BigData プール (オプション)
バッチ データ アプリケーション
バッチ データ アプリケーション テンプレートには、クラウド規模の分析シナリオのデータ ランディング ゾーン内にバッチ データ処理用のデータ製品をデプロイするためのすべてのテンプレートが含まれています。
デプロイとコード成果物には、次のサービスが含まれます。

- Key Vault
- Data Factory (Data Factory と Synapse のどちらかを選択)
- Azure Cosmos DB (オプション)
- Synapse ワークスペース (Data Factory と Synapse のどちらかを選択)
- MySQL Database (オプション)
- Azure SQL Database (オプション)
- PostgreSQL Database (オプション)
- MariaDB Database (オプション)
- SQL プール (オプション)
- SQL Server (オプション)
- SQL エラスティック プール (オプション)
- BigData プール
ストリーミング データ アプリケーション
ストリーミング データ アプリケーション テンプレートには、クラウド規模の分析シナリオのデータ ランディング ゾーン内にリアルタイム データ処理用のデータ製品をデプロイするためのすべてのテンプレートが含まれています。
デプロイとコード成果物には、次のサービスが含まれます。

- Key Vault
- Event Hubs
- IoT Hub
- Stream Analytics (オプション)
- Azure Cosmos DB (オプション)
- Synapse ワークスペース
- Azure SQL Database (オプション)
- SQL プール (オプション)
- SQL Server (オプション)
- SQL エラスティック プール (オプション)
- BigData プール
- Data Explorer (オプション)
前述のデプロイ テンプレートを含むリポジトリを見つけるには、クラウド規模の分析用のデプロイ テンプレートに関するページを参照してください