Azure Monitor を使用して仮想マシンを監視する: アラート
この記事は、「Azure Monitor で仮想マシンとそのワークロードを監視する」のガイドの一部です。 Azure Monitor のアラートでは、監視データの興味深いデータやパターンを事前に通知します。 仮想マシン用に事前に構成されたアラート ルールはありませんが、Azure Monitor エージェントから収集したデータに基づいて独自のものを作成することができます。 この記事では、仮想マシンに固有のアラートの概念と、他の Azure Monitor のお客様にも使用されている一般的なアラート ルールについて説明します。
このシナリオでは、Azure とハイブリッド仮想マシン環境の完全な監視を実装する方法について説明します。
最初の Azure 仮想マシンの監視を開始するには、Azure 仮想マシンの監視に関する記事を参照してください。
推奨される一連のアラートをすばやく有効にするには、「Azure 仮想マシンの推奨アラート ルールを有効にする」を参照してください。
重要
ほとんどのアラート ルールには、ルールの種類、含まれるディメンションの数、実行頻度に応じてかかるコストがあります。 アラート ルールを作成する前に、「Azure Monitor の価格」の「アラート ルール」セクションを参照してください。
データ コレクション
アラート ルールは、Azure Monitor で既に収集されているデータを検査します。 アラート ルールを作成する前に、特定のシナリオのデータが収集されていることを確認する必要があります。 この記事内のすべてのアラート ルールを含む、さまざまなシナリオでのデータ収集の構成に関するガイダンスについては、「Azure Monitor を使用して仮想マシンを監視する: データを収集する」を参照してください。
推奨されるアラート ルール
Azure Monitor には、任意の Azure 仮想マシンに対してすばやく有効にできる一連の推奨アラート ルールが用意されています。 これらのルールは、基本的な監視の出発点として最適です。 ただし、以下の理由により、ほとんどのエンタープライズ実装に対して十分なアラートは提供されません。
- 推奨されるアラートは Azure 仮想マシンにのみ適用され、ハイブリッド マシンには適用されません。
- 推奨されるアラートにはホスト メトリックのみが含まれており、ゲスト メトリックやログは含まれません。 これらのメトリックは、マシン自体の正常性を監視するのに役立ちます。 しかし、マシンで実行されるワークロードとアプリケーションの可視性は、最低限しか得られません。
- 推奨されるアラートは個々のマシンに関連付けられ、過剰な数のアラート ルールが作成されます。 個々のマシンに対するこの方法を使用する代わりに、複数のマシンに対して最小限のアラート ルールを使用する方法については、「アラート ルールのスケーリング」を参照してください。
アラートの種類
Azure Monitor における最も一般的な種類の警告ルールは、メトリック警告とログ検索警告です。 特定のシナリオのために作成するアラート ルールの種類は、アラートの対象となるデータの場所に応じて異なります。
場合によっては、特定のアラート シナリオのデータをメトリックとログの両方で使用できることがあります。 その場合は、使用するルールの種類を決定する必要があります。 また、特定のデータを収集する方法を設定し、アラート ルールの種類を決定してデータ収集方法を決定する柔軟性も得られます。
メトリック アラート
メトリック アラートの一般的な用途:
- 特定のメトリックがしきい値を超えたときにアラートを作成します。 たとえば、コンピューターの CPU が高い使用率で実行されているときなどです。
メトリック アラートのデータ ソース:
- 自動的に収集される Azure 仮想マシンのホスト メトリック
- Azure Monitor エージェントによってゲスト オペレーティング システムから収集されるメトリック
ログ検索アラート
ログ検索警告の一般的な用途:
- Windows イベント ログまたは Syslog に特定のイベントまたはイベントのパターンが見つかった場合にアラートを作成します。 これらのアラート ルールでは、通常、クエリから返されるテーブル行を測定します。
- 複数のマシンにわたる数値データの計算に基づくアラート。 これらのアラート ルールでは、通常、クエリ結果の数値列の計算を測定します。
ログ検索警告のデータ ソース:
- Log Analytics ワークスペースで収集されたすべてのデータ
アラート ルールのスケーリング
同じ監視を必要とする仮想マシンが多数ある場合があるため、それぞれに個別のアラート ルールを作成する必要があるのは好ましくありません。 また、ルールの種類に応じて、管理が必要なアラート ルールの数を制限するさまざまな戦略を立てる必要もあります。 これらの戦略がうまく機能するかは、アラート ルールのターゲット リソースをどれほど理解しているかにかかっています。
メトリック アラート ルール
仮想マシンでは、複数のリソースの監視に関する説明に従って、複数のリソースのメトリック アラート ルールがサポートされます。 この機能により、同じリージョン内のリソース グループまたはサブスクリプション内のすべての仮想マシンに適用される 1 つのメトリック アラート ルールを作成できます。
推奨されるアラートから開始し、サブスクリプションまたはリソース グループをターゲット リソースとして使用して、それぞれに対応するルールを作成します。 複数のリージョンにマシンがある場合は、リージョンごとに重複するルールを作成する必要があります。
より多くのメトリック アラート ルールの要件を特定するときは、次のために、サブスクリプションまたはリソース グループをターゲット リソースとして使用してこの同じ戦略に従います。
- 管理する必要があるアラート ルールの数を最小限に抑えます。
- 新しいマシンに自動的に適用されるようにします。
ログ検索警告ルール
ログ検索警告ルールのターゲット リソースを特定のマシンに設定すると、クエリはそのマシンに関連付けられたデータに限定され、それに関する個々の警告が作成されるようになります。 この配置には、マシンごとに個別のアラート ルールが必要になります。
ログ検索警告ルールのターゲット リソースを Log Analytics ワークスペースに設定すると、そのワークスペース内のすべてのデータにアクセスできます。 このため、1 つのルールでワークグループ内のすべてのマシンのデータに対してアラートを生成できます。 この配置によって、すべてのマシンに対して 1 つのアラートを作成することができます。 その後、ディメンションを使用して、マシンごとに個別のアラートを作成できます。
たとえば、任意のコンピューターによって Windows イベント ログにエラー イベントが作成されたときにアラートを生成できます。 Log Analytics ワークスペースの Event テーブルにこれらのイベントを送信するには、「Azure Monitor エージェントを使用してデータを収集する」に関する説明に従って、データ収集ルールを作成する必要があります。 その後、ターゲット リソースとしてワークスペース、そして次の図に示す条件を使用して、このテーブルに対してクエリを実行するアラート ルールを作成します。
クエリから、任意のコンピューター上のエラー メッセージのレコードが返されます。 [ディメンション別に分割] オプションで [_ResourceId] を指定することで、結果に複数のマシンが返された場合に、各マシンのアラートを作成するようにルールを指定します。

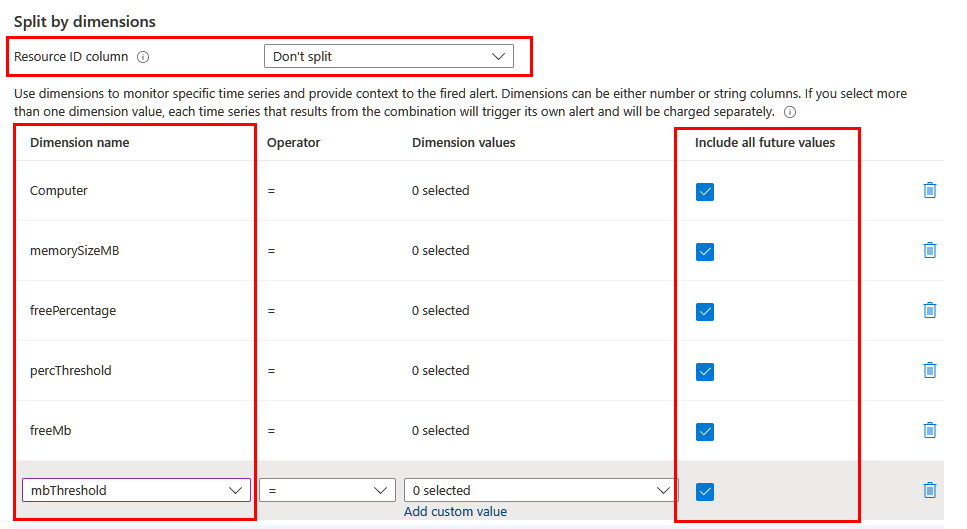
Dimensions
アラートに含める情報によっては、異なるディメンションを使用して分割する必要がある場合があります。 この場合は、project または extend 演算子を使用して、必要なディメンションがクエリに投影されていることを確認します。 [リソース ID 列] フィールドを [分割しない] に設定し、すべての意味のあるディメンションを一覧に含めます。 [今後のすべての値を含める] が選択されていることを確認して、クエリから返されるすべての値が含まれるようにします。
動的しきい値
ログ検索警告ルールを使用する別の利点は、しきい値を決定するための複雑なロジックをクエリに含めることができることです。 しきい値をハードコーディングしたり、すべてのリソースに適用したり、一部のフィールドまたは計算値に基づいて動的に計算したりできます。 しきい値は、特定の条件に従ってリソースにのみ適用されます。 たとえば、使用可能なメモリに基づいてアラートを作成できますが、特定の量の合計メモリを持つマシンに対してのみアラートを作成できます。
一般的なアラート ルール
次のセクションでは、Azure Monitor の仮想マシンに関する一般的なアラート ルールを示します。 それぞれのメトリック警告とログ検索警告の詳細が表示されます。 使用するアラートの種類のガイダンスについては、「アラートの種類」を参照してください。 Azure Monitor で警告ルールを作成するプロセスに慣れていない場合は、 新しい警告ルールを作成する手順を参照してください。
Note
以下に示すログ検索警告の詳細では、クライアント オペレーティング システムの一連の一般的なパフォーマンス カウンターを提供する、VM Insights を使用して収集されたデータを使用しています。 この名前は、オペレーティング システムの種類とは関係ありません。
マシンの可用性
仮想マシンの最も一般的な監視要件の 1 つは、実行が停止した場合にアラートを作成することです。 最適な方法は、現在パブリック プレビュー段階にある VM 可用性メトリックを使って、Azure Monitor でメトリック アラート ルールを作成することです。 このメトリックのチュートリアルについては、「Azure 仮想マシンの可用性アラート ルールを作成する」を参照してください。
アラート ルールは、1 つのアクティビティ ログ シグナルに制限されます。 そのため、すべての条件に対して、1 つのアラート ルールを作成する必要があります。 たとえば、"仮想マシンを開始または停止する" には、2 つのアラート ルールが必要です。 ただし、VM の再起動時にアラートを受け取るには、アラート ルールは 1 つだけ必要です。
「アラート ルールのスケーリング」で説明されているように、サブスクリプションまたはリソース グループをターゲット リソースとして使用して可用性アラート ルールを作成します。 このルールは、アラート ルールの後に作成する新しいマシンを含む複数の仮想マシンに適用されます。
エージェント ハートビート
エージェント ハートビートは、Azure Monitor エージェントに依存してハートビートを送信するため、マシンを使用できない場合のアラートとは若干異なります。 エージェント ハートビートでは、マシンが実行されているが、エージェントが応答していない場合にアラートを生成できます。
メトリック アラート ルール
各 Log Analytics ワークスペースには、ハートビートと呼ばれるメトリックが含まれています。 そのワークスペースに接続されている各仮想マシンは、1 分ごとにハートビート メトリックの値を送信します。 そのコンピューターがメトリックのディメンションであるため、どのコンピューターもハートビートの送信に失敗したときに、アラートが起動するようにできます。 [集計の種類] を [データの個数] に設定し、 [しきい値] を [評価の粒度] と一致する値に設定します。
ログ検索警告ルール
ログ検索警告は、各コンピューターから 1 分ごとにハートビート レコードを取得するハートビート テーブルを使用します。
次のクエリを使ったルールを使用します。
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
CPU アラート
このセクションでは、CPU アラートについて説明します。
メトリック アラート ルール
| 移行先 | メトリック |
|---|---|
| Host | CPU 使用率 (推奨されるアラートに含まれます) |
| Windows ゲスト | \Processor Information(_Total)% Processor Time |
| Linux ゲスト | cpu/usage_active |
ログ検索警告ルール
CPU 使用率
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
メモリのアラート
このセクションでは、メモリ アラートについて説明します。
メトリック アラート ルール
| 移行先 | メトリック |
|---|---|
| Host | 使用可能なメモリ バイト (プレビュー) (推奨されるアラートに含まれます) |
| Windows ゲスト | \Memory% Committed Bytes in Use \Memory\Available Bytes |
| Linux ゲスト | mem/available mem/available_percent |
ログ検索警告ルール
Note
1 つのディスクにアラートを指定する必要がある場合は、次をクエリに追加します: | where parse_json(Tags).["vm.azm.ms/mountId"] == "C:"MB 単位の利用可能なメモリ
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
使用可能なメモリ (%)
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
ディスク アラート
このセクションでは、ディスク アラートについて説明します。
メトリック アラート ルール
| 移行先 | メトリック |
|---|---|
| Windows ゲスト | \Logical Disk(_Total)% Free Space \Logical Disk(_Total)\Free Megabytes |
| Linux ゲスト | disk/free disk/free_percent |
ログ検索警告ルール
使用されている論理ディスク - 各コンピューター上のすべてのディスク
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
使用されている論理ディスク - 個々のディスク
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
論理ディスクの IOPS
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
論理ディスクのデータ速度
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
ネットワーク アラート
メトリック アラート ルール
| 移行先 | メトリック |
|---|---|
| Host | 受信ネットワーク合計、送信ネットワーク合計 (推奨されるアラートに含まれます) |
| Windows ゲスト | \Network Interface\Bytes Sent/sec \Logical Disk(_Total)\Free Megabytes |
| Linux ゲスト | disk/free disk/free_percent |
ログ検索警告ルール
ネットワーク インターフェイスの受信バイト数 - すべてのインターフェイス
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
ネットワーク インターフェイスの受信バイト数 - 個々のインターフェイス
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
ネットワーク インターフェイスの送信バイト数 - すべてのインターフェイス
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
ネットワーク インターフェイスの送信バイト数 - 個々のインターフェイス
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Windows および Linux イベント
次の例では、特定の Windows イベントが作成されたときにアラートが作成されます。 メトリック測定アラート ルールを使用して、コンピューターごとに個別のアラートが作成されます。
特定の Windows イベントに対するアラート ルールを作成します。 この例では、アプリケーション ログのイベントを表示します。 しきい値として 0 および連続する違反が 0 より大きいことを指定します。
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)特定の重大度の Syslog イベントに対するアラート ルールを作成します。 次の例では、エラー認可イベントを表示します。 しきい値として 0 および連続する違反が 0 より大きいことを指定します。
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
カスタム パフォーマンス カウンター
カウンターの最大値に関するアラートを作成します。
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by Computerカウンターの平均値に関するアラートを作成します。
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer