プロフェッショナル音声モデルをトレーニングする
この記事では、Speech Studio ポータルを使用してカスタム ニューラル音声をトレーニングする方法について説明します。
重要
カスタム ニューラル音声トレーニングは、現在一部のリージョンでのみ使用できます。 サポートされているリージョンでトレーニングが完了した音声モデルは、必要に応じて別のリージョンの Speech リソースにコピーできます。 詳細については、Speech Service テーブルの脚注を参照してください。
トレーニング期間は、使用するデータ量によって異なります。 カスタム ニューラル音声をトレーニングするには、平均で約 40 コンピューティング時間かかります。 Standard サブスクリプション (S0) ユーザーは、4 つの音声を同時にトレーニングできます。 制限に達した場合は、少なくとも 1 つのデータ ファイルのインポートが終わるまで待機します。 その後、やり直してください。
Note
トレーニング方法ごとに必要な合計時間数は異なりますが、それぞれに同じ単価が適用されます。 詳細については、カスタム ニューラル トレーニングの価格の詳細に関するページを参照してください。
トレーニング方法を選択する
データ ファイルを検証したら、それを使用してカスタム ニューラル音声モデルを作成できます。 カスタム ニューラル音声を作成するときに、次のいずれかの方法でトレーニングすることを選択できます。
ニューラル: トレーニング データと同じ言語で音声を作成します。
ニューラル - 言語間: トレーニング データとは異なる言語を話す音声を作成します。 たとえば、
zh-CNトレーニング データを使用して、en-USを話す音声を作成できます。トレーニング データの言語とターゲット言語の両方が、クロス言語音声トレーニングでサポートされている言語のいずれかである必要があります。 ターゲット言語でトレーニング データを準備する必要はありませんが、テスト スクリプトはターゲット言語である必要があります。
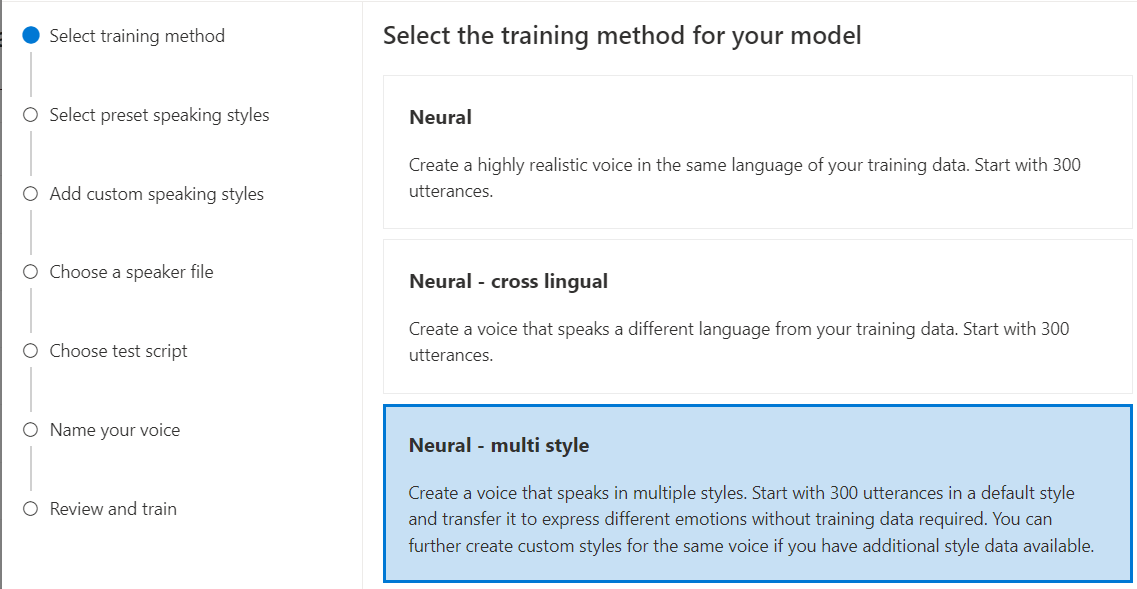
ニューラル - マルチ スタイル: 新しいトレーニング データを追加せずに、複数のスタイルと感情で話すカスタム ニューラル音声を作成します。 複数のスタイルの音声は、ビデオ ゲームのキャラクター、会話チャットボット、オーディオブック、コンテンツ リーダーなどに役立ちます。
複数のスタイルの音声を作成するには、一連の汎用トレーニング データ (少なくとも 300 個の発話) を準備する必要があります。 1 つ以上のプリセット ターゲットの話し方を選択します。 同じ音声の追加トレーニング データとしてスタイル サンプル (スタイルごとに少なくとも 100 個の発話) を提供することで、複数のカスタム スタイルを作成することもできます。 サポートされているプリセット スタイルは言語によって異なります。 「さまざまな言語で利用可能なプリセット スタイル」をご覧ください。
トレーニング データの言語は、カスタム ニューラル音声、クロス言語、または複数のスタイル トレーニング用にサポートされている言語のいずれかである必要があります。
カスタム ニューラル音声モデルをトレーニングする
Speech Studio でカスタム ニューラル音声を作成するには、次のいずれかの方法の次の手順に従います。
Speech Studio にサインインします。
[Custom Voice]><自分のプロジェクトの名前>>[モデルのトレーニング]>[新しいモデルのトレーニング] を選びます。
モデルのトレーニング方法として [ニューラル] を選択し、[次へ] を選択します。 別のトレーニング方法を使用するには、「ニューラル - クロス言語」または「ニューラル - マルチ スタイル」を参照してください。
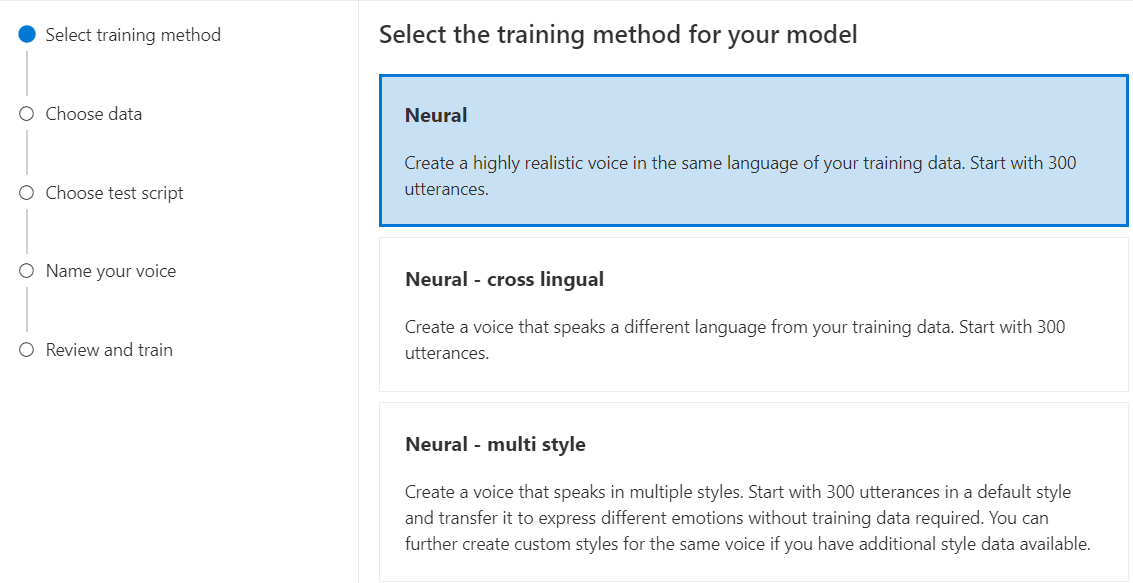
モデルのトレーニング レシピのバージョンを選択します。 既定では最新バージョンが選択されています。 サポートされている機能とトレーニング時間は、バージョンによって異なる場合があります。 通常は、最新のバージョンをお勧めします。 場合によっては、以前のバージョンを選択してトレーニング時間を短縮できます。 バイリンガル トレーニングとロケール間の違いについて詳しくは、「バイリンガル トレーニング」をご覧ください。
Note
モデル バージョン
V2.2021.07、V4.2021.10、V5.2022.05、V6.2022.11、V9.2023.10は、2024 年 10 月 1 日までに廃止されます。 これらの廃止されたバージョンで既に作成されている音声モデルが影響を受けることはありません。トレーニングに使用するデータを選択します。 重複するオーディオ名はトレーニングから削除されます。 選択したデータ内の複数の .zip ファイルに同じオーディオ名が含まれていないことを確認してください。
トレーニングには、正常に処理されたデータセットのみを選択できます。 一覧にトレーニング セットが表示されない場合は、データ処理の状態を確認してください。
トレーニング データのスピーカーに対応するボイス タレント ステートメントを含むスピーカー ファイルを選択します。
[次へ] をクリックします。
トレーニングごとに、既定のスクリプトによるモデルのテストに役立つ 100 個のサンプル オーディオ ファイルが自動的に生成されます。
必要に応じて、[独自のテスト スクリプトを追加] を選択し、最大 100 個の発話を含む独自のテスト スクリプトを提供して、追加コストなしでモデルをテストすることもできます。 生成されたオーディオ ファイルは、自動テスト スクリプトとカスタム テスト スクリプトの組み合わせです。 詳細については、「テスト スクリプトの要件」を参照してください。
モデルを識別しやすい [名前] を入力します。 名前は慎重に選択します。 モデル名は、SDK と SSML 入力を使用した音声合成要求の音声名として使用されます。 文字、数字、およびいくつかの区切り文字だけを使用できます。 ニューラル音声モデルごとに、異なる名前を使用します。
必要に応じて、モデルの識別に役立つ [説明] を入力します。 説明の一般的な用途は、モデルの作成に使用したデータの名前を記録することです。
[次へ] をクリックします。
設定を確認し、チェックボックスをオンにして利用規約に同意します。
[送信] を選択してモデルのトレーニングを開始します。

バイリンガル トレーニング
ニューラル トレーニングの種類を選んだ場合は、複数の言語で話すように音声をトレーニングできます。 zh-CN、zh-HK、および zh-TW ロケールは、中国語と英語の両方を話す音声のためのバイリンガル トレーニングをサポートしています。 ある程度までトレーニング データ次第で、合成された音声は、英語のネイティブ アクセントを持つ英語またはトレーニング データと同じアクセントを持つ英語を話すことができます。
Note
zh-CN ロケールの音声がサンプル データと同じアクセントで英語を話せるようにするには、プロジェクトの作成時に Chinese (Mandarin, Simplified), English bilingual を選ぶか、REST API でトレーニング セット データに対して zh-CN (English bilingual) ロケールを指定する必要があります。
次の表は、ロケール間の違いを示しています。
| Speech Studio のロケール | REST API のロケール | バイリンガルのサポート |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
サンプル データに英語が含まれている場合、合成された音声は、英語データの量に関係なく、サンプル データと同じアクセントではなく、英語のネイティブ アクセントで英語を話します。 |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
合成された音声がサンプル データと同じアクセントで英語を話すようにしたい場合は、トレーニング セットに 10% を超える英語データを含めることをお勧めします。 そうしないと、英語を話すアクセントが理想的ではない可能性があります。 |
Chinese (Cantonese, Simplified) |
zh-HK |
サンプル データと同じアクセントで英語を話せる合成音声をトレーニングしたい場合は、トレーニング セットで 10% より多くの英語データを提供するようにします。 そうしないと、既定で英語のネイティブ アクセントになります。 10% のしきい値は、アップロード前のデータではなく、アップロードが成功した後で受け入れられたデータに基づいて計算されます。 アップロードされた英語データの一部が欠陥のために拒否され、10% のしきい値を満たさなくなった場合、合成される音声は既定で英語のネイティブ アクセントになります。 |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
サンプル データと同じアクセントで英語を話せる合成音声をトレーニングしたい場合は、トレーニング セットで 10% より多くの英語データを提供するようにします。 そうしないと、既定で英語のネイティブ アクセントになります。 10% のしきい値は、アップロード前のデータではなく、アップロードが成功した後で受け入れられたデータに基づいて計算されます。 アップロードされた英語データの一部が欠陥のために拒否され、10% のしきい値を満たさなくなった場合、合成される音声は既定で英語のネイティブ アクセントになります。 |
さまざまな言語で利用可能なプリセット スタイル
次の表は、さまざまな言語に応じたさまざまなプリセット スタイルをまとめたものです。
| 話し方 | 言語 (ロケール) |
|---|---|
| 怒り | 英語 (米国) (en-US)日本語 (日本) ( ja-JP) 1中国語 (標準、簡体字) ( zh-CN) 1 |
| 穏やか | 中国語 (標準、簡体字) (zh-CN) 1 |
| chat | 中国語 (標準、簡体字) (zh-CN) 1 |
| 陽気 | 英語 (米国) (en-US)日本語 (日本) ( ja-JP) 1中国語 (標準、簡体字) ( zh-CN) 1 |
| 不満 | 中国語 (標準、簡体字) (zh-CN) 1 |
| 興奮 | 英語 (米国) (en-US) |
| 怖い | 中国語 (標準、簡体字) (zh-CN) 1 |
| 優しい | 英語 (米国) (en-US) |
| 希望に満ちた | 英語 (米国) (en-US) |
| 悲しい | 英語 (米国) (en-US)日本語 (日本) ( ja-JP) 1中国語 (標準、簡体字) ( zh-CN) 1 |
| 叫ぶ | 英語 (米国) (en-US) |
| 深刻 | 中国語 (標準、簡体字) (zh-CN) 1 |
| 恐怖 | 英語 (米国) (en-US) |
| unfriendly | 英語 (米国) (en-US) |
| ささやく | 英語 (米国) (en-US) |
1 ニューラル音声スタイルはパブリック プレビューで利用できます。 パブリック プレビューでのスタイルは、米国東部、西ヨーロッパ、東南アジアのサービス リージョンでのみ使用できます。
[モデルのトレーニング] の表に、この新しく作成されたモデルに対応する新しいエントリが表示されます。 この状態は、次の表で説明するように、データから音声モデルへの変換プロセスを反映しています。
| State | 意味 |
|---|---|
| 処理中 | 実際の音声モデルを作成中です。 |
| 成功 | 実際の音声モデルは作成が済み、デプロイ可能です。 |
| 失敗 | 音声モデルがトレーニング中に失敗しました。 失敗の原因としては、たとえば、見えないデータの問題やネットワークの問題などが考えられます。 |
| Canceled | 音声モデルのトレーニングが取り消されました。 |
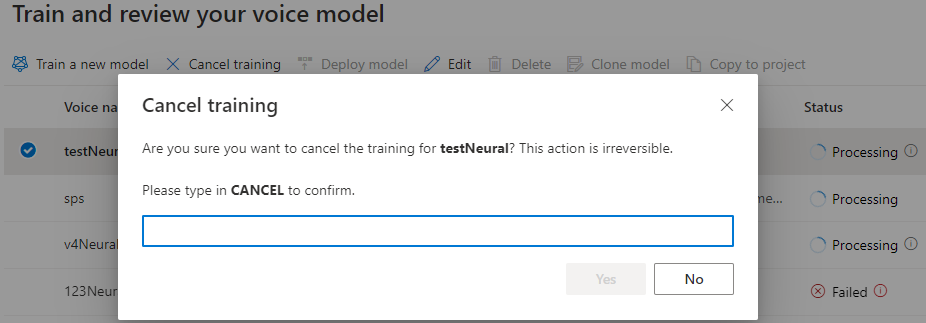
モデルの状態が [処理中] になっているときに、[トレーニングの取り消し] を選択して音声モデルを取り消すことができます。 この取り消されたトレーニングに対しては課金されません。
モデルのトレーニングが正常に完了したら、モデルの詳細を確認し、音声モデルをテストします。
Speech Studio の Audio Content Creation ツールを使用して、オーディオを作成し、デプロイされた音声を微調整できます。 音声に該当する場合は、複数のスタイルのいずれかを選択できます。
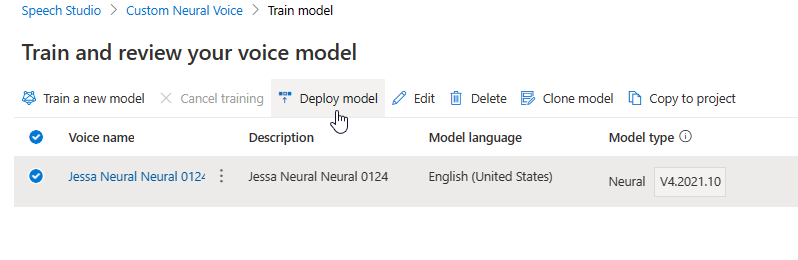
モデルの名前を変更する
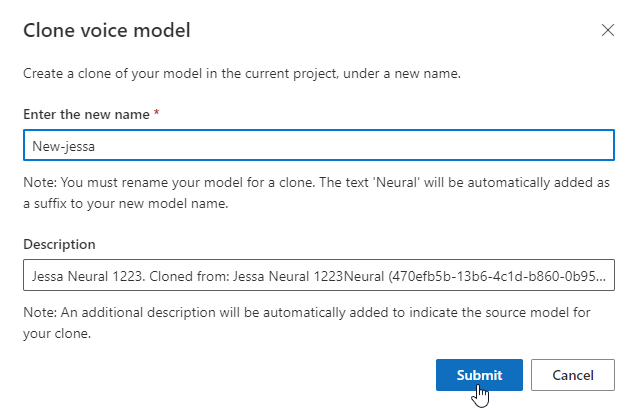
構築したモデルの名前を変更する場合は、[モデルの複製] を選択して、現在のプロジェクトに新しい名前のモデルの複製を作成します。
![[モデルの複製] ボタンを選択しているスクリーン ショット。](media/custom-voice/cnv-clone-model.png)
[音声モデルの複製] ウィンドウに新しい名前を入力し、[送信] を選択します。 テキスト Neural は、新しいモデル名にサフィックスとして自動的に追加されます。
実際の音声モデルをテストする
音声モデルが正常に作成されたら、デプロイする前に、生成されたサンプル オーディオ ファイルを使用してテストすることができます。
音声の品質は、次のような多くの要因によって異なります。
- トレーニング データのサイズ。
- 録音の品質。
- トランスクリプト ファイルの正確性。
- トレーニング データに録音された音声が、意図したユース ケースに対して設計された音声のパーソナリティとどの程度一致しているか。
[テスト] の下にある [DefaultTests] を選択して、サンプル オーディオ ファイルを聴きます。 既定のテスト サンプルには、モデルのテストに役立つトレーニング中に自動的に生成される 100 個のサンプル オーディオ ファイルが含まれています。 既定で提供されるこれらの 100 個のオーディオ ファイルに加え、自分のテスト スクリプトの発話も DefaultTests セットに追加されます。 この追加は、最大 100 個の発話です。 DefaultTests でのテストに対しては課金されません。
![[テスト] の下にある [DefaultTests] を選択しているスクリーン ショット。](media/custom-voice/cnv-model-default-test.png)
自分のテスト スクリプトをアップロードしてモデルをさらにテストする場合は、[テスト スクリプトの追加] を選択して自分のテスト スクリプトをアップロードします。
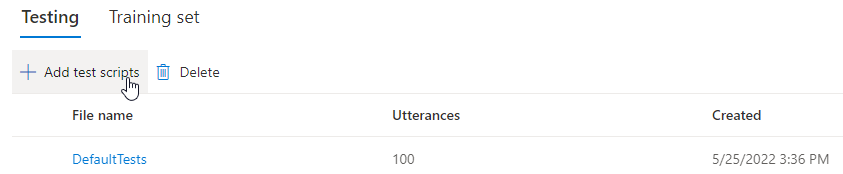
テスト スクリプトをアップロードする前に、テスト スクリプトの要件を確認します。 課金対象の文字数に基づいて、バッチ合成による追加テストに対して課金されます。 「Azure AI Speech の価格」を参照してください。
[テスト スクリプトの追加] の [ファイルの参照] を選択して自分のスクリプトを選び、[追加] を選択してアップロードします。
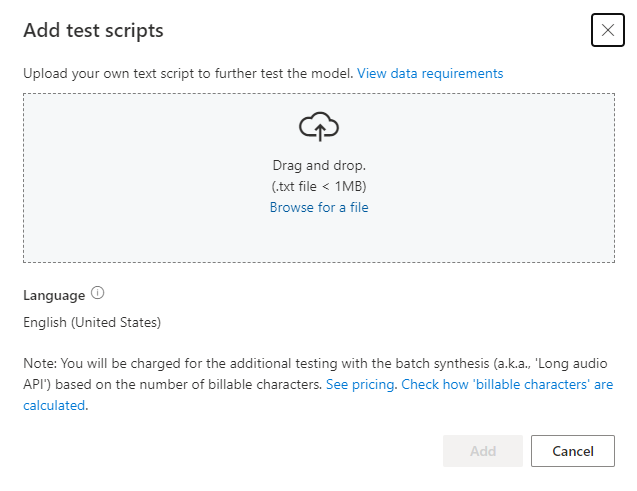
テスト スクリプトの要件
テスト スクリプトは、1 MB 未満の.txt ファイルである必要があります。 サポートされているエンコード形式は、ANSI/ASCII、UTF-8、UTF-8-BOM、UTF-16-LE、UTF-16-BE です。
トレーニング文字起こしファイルとは異なり、テスト スクリプトでは各発話のファイル名である発話 ID を除外する必要があります。 そうしないと、これらの ID が発話されてしまいます。
以下に 1 つの .txt ファイル内の一連の発話の例を示します。
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
発話の段落ごとに、個別の音声になります。 すべての文を 1 つの音声に結合したい場合は、1 つの段落にします。
注意
生成されたオーディオ ファイルは、自動テスト スクリプトとカスタム テスト スクリプトの組み合わせです。
音声モデルのエンジン バージョンを更新する
Azure Text to Speech エンジンは、言語の発音を定義する最新の言語モデルを取り込むために随時更新されます。 音声をトレーニングした後、最新のエンジン バージョンに更新することで、音声を新しい言語モデルに適用できます。
新しいエンジンが使用可能になると、ニューラル音声モデルを更新するように求められます。

モデルの詳細ページに移動し、画面の指示に従って最新のエンジンをインストールします。
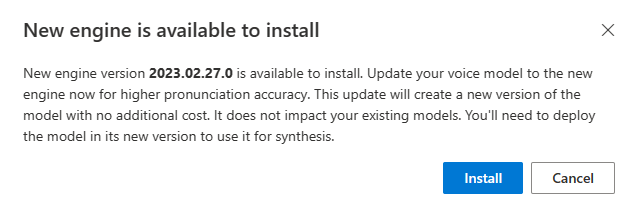
または、後で [最新のエンジンのインストール] を選択して、モデルを最新のエンジン バージョンに更新します。
![[最新のエンジンのインストール] ボタンを選択してエンジンを更新するスクリーンショット。](media/custom-voice/cnv-install-latest-engine.png)
エンジンの更新に対しては課金されません。 以前のバージョンが引き続き保持されます。
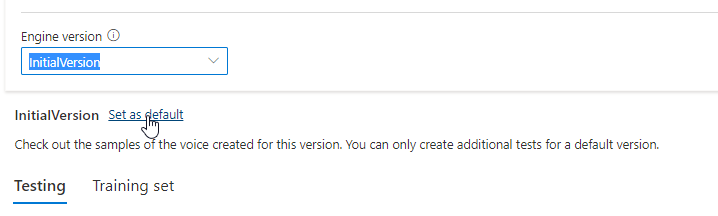
このモデルのすべてのエンジン バージョンを [エンジンのバージョン] リストから確認するか、不要な場合は削除できます。
![[エンジンのバージョン] ドロップダウン リストを表示しているスクリーンショット。](media/custom-voice/cnv-engine-version.png)
更新されたバージョンは自動的に既定に設定されます。 しかし、ドロップダウン リストからバージョンを選択し、[既定に設定] を選択することで、既定のバージョンを変更できます。

音声モデルの各エンジン バージョンをテストする場合は、リストからバージョンを選び、[テスト] の下の [DefaultTests] を選択してサンプル オーディオ ファイルを聴くことができます。 独自のテスト スクリプトをアップロードして現在のエンジン バージョンをさらにテストする場合は、まずそのバージョンが既定に設定されていることを確認してから、[実際の音声モデルをテストする] に従います。
エンジンを更新すると、追加コストなしで新しいバージョンのモデルが作成されます。 音声モデルのエンジン バージョンを更新したら、新しいバージョンをデプロイして新しいエンドポイントを作成する必要があります。 既定のバージョンのみをデプロイできます。
新しいエンドポイントを作成したら、トラフィックをご使用の製品の新しいエンドポイントに転送する必要があります。
この機能の詳細と制限、およびモデルの品質を向上させるためのベスト プラクティスの詳細については、「カスタム ニューラル音声を使用する場合の特性と制限」を参照してください。
音声モデルを別のプロジェクトにコピーする
音声モデルは、同じリージョンまたは別のリージョンの別のプロジェクトにコピーできます。 たとえば、あるリージョンでトレーニングされたニューラル音声モデルを、別のリージョンのプロジェクトにコピーできます。
注意
カスタム ニューラル音声トレーニングは、現在一部のリージョンでのみ使用できます。 ニューラル音声モデルは、それらのリージョンから他のリージョンにコピーできます。 詳細については、「カスタム ニューラル音声のリージョン」を参照してください。
カスタム ニューラル音声モデルを別のプロジェクトにコピーするには、次の手順に従います。
[モデルのトレーニング] タブで、コピーする音声モデルを選択し、[プロジェクトにコピー] を選択します。
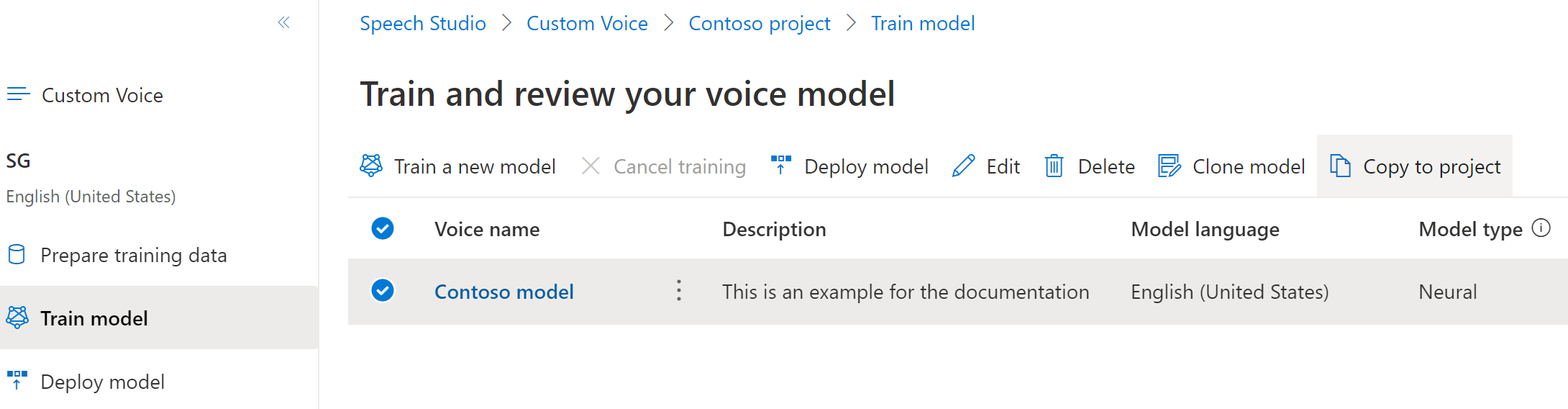
モデルをコピーする[サブスクリプション]、[リージョン]、[Speech リソース]、[プロジェクト] を選択します。 ターゲット リージョンに Speech リソースとプロジェクトが存在する必要があります。存在しない場合は、先に作成する必要があります。
![[copy voice model]\(音声モデルのコピー\) ダイアログのスクリーンショット。](media/custom-voice/cnv-model-copy-dialog.png)
[送信] を選択してモデルをコピーします。
成功したコピーの通知メッセージの下にある [モデルの表示] を選択します。
モデルのコピーをデプロイするためにモデルをコピーしたプロジェクトに移動します。
次のステップ
この記事では、Custom Voice API を使ってカスタム ニューラル音声をトレーニングする方法について説明します。
重要
カスタム ニューラル音声トレーニングは、現在一部のリージョンでのみ使用できます。 サポートされているリージョンでトレーニングが完了した音声モデルは、必要に応じて別のリージョンの Speech リソースにコピーできます。 詳細については、Speech Service テーブルの脚注を参照してください。
トレーニング期間は、使用するデータ量によって異なります。 カスタム ニューラル音声をトレーニングするには、平均で約 40 コンピューティング時間かかります。 Standard サブスクリプション (S0) ユーザーは、4 つの音声を同時にトレーニングできます。 制限に達した場合は、少なくとも 1 つのデータ ファイルのインポートが終わるまで待機します。 その後、やり直してください。
Note
トレーニング方法ごとに必要な合計時間数は異なりますが、それぞれに同じ単価が適用されます。 詳細については、カスタム ニューラル トレーニングの価格の詳細に関するページを参照してください。
トレーニング方法を選択する
データ ファイルを検証したら、それを使用してカスタム ニューラル音声モデルを作成できます。 カスタム ニューラル音声を作成するときに、次のいずれかの方法でトレーニングすることを選択できます。
ニューラル: トレーニング データと同じ言語で音声を作成します。
ニューラル - 言語間: トレーニング データとは異なる言語を話す音声を作成します。 たとえば、
fr-FRトレーニング データを使用して、en-USを話す音声を作成できます。トレーニング データの言語とターゲット言語の両方が、クロス言語音声トレーニングでサポートされている言語のいずれかである必要があります。 ターゲット言語でトレーニング データを準備する必要はありませんが、テスト スクリプトはターゲット言語である必要があります。
ニューラル - マルチ スタイル: 新しいトレーニング データを追加せずに、複数のスタイルと感情で話すカスタム ニューラル音声を作成します。 複数のスタイルの音声は、ビデオ ゲームのキャラクター、会話チャットボット、オーディオブック、コンテンツ リーダーなどに役立ちます。
複数のスタイルの音声を作成するには、一連の汎用トレーニング データ (少なくとも 300 個の発話) を準備する必要があります。 1 つ以上のプリセット ターゲットの話し方を選択します。 同じ音声の追加トレーニング データとしてスタイル サンプル (スタイルごとに少なくとも 100 個の発話) を提供することで、複数のカスタム スタイルを作成することもできます。 サポートされているプリセット スタイルは言語によって異なります。 「さまざまな言語で利用可能なプリセット スタイル」をご覧ください。
トレーニング データの言語は、カスタム ニューラル音声、言語間、または複数スタイルのトレーニング用にサポートされている言語のいずれかである必要があります。
音声モデルを作成する
ニューラル音声を作成するには、Custom Voice API の Models_Create 操作を使用します。 次の手順に従って要求本文を作成します。
- 必須の
projectIdプロパティを設定します。 プロジェクトの作成に関する記事を参照してください。 - 必須の
consentIdプロパティを設定します。 ボイス タレントの同意の追加に関する記事をご覧ください。 - 必須の
trainingSetIdプロパティを設定します。 トレーニング セットの作成に関する記事をご覧ください。 - ニューラル音声トレーニングの場合、必須のレシピ
kindプロパティをDefaultに設定します。 レシピの種類はトレーニング方法を示し、後で変更することはできません。 別のトレーニング方法を使用するには、「ニューラル - クロス言語」または「ニューラル - マルチ スタイル」を参照してください。 バイリンガル トレーニングとロケール間の違いについて詳しくは、「バイリンガル トレーニング」をご覧ください。 - 必須の
voiceNameプロパティを設定します。 音声名は末尾を "Neural" にする必要があり、後で変更することはできません。 名前は慎重に選択します。 音声名は、SDK と SSML 入力による音声合成要求で使われます。 文字、数字、およびいくつかの区切り文字だけを使用できます。 ニューラル音声モデルごとに、異なる名前を使用します。 - 必要に応じて、
descriptionプロパティに音声の説明を設定します。 音声の説明は後で変更できます。
HTTP PUT 要求は、以下の Models_Create の例に示すように URI を使用して行います。
YourResourceKeyをSpeech リソース キーに置き換えます。YourResourceRegionを Azure Cognitive Service for Speech リソースのリージョンに置き換えます。JessicaModelIdを任意のモデル ID に置き換えます。 大文字と小文字が区別される ID はモデルの URI で使われ、後で変更することはできません。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
次の形式で応答本文を受け取る必要があります。
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
バイリンガル トレーニング
ニューラル トレーニングの種類を選んだ場合は、複数の言語で話すように音声をトレーニングできます。 zh-CN、zh-HK、および zh-TW ロケールは、中国語と英語の両方を話す音声のためのバイリンガル トレーニングをサポートしています。 ある程度までトレーニング データ次第で、合成された音声は、英語のネイティブ アクセントを持つ英語またはトレーニング データと同じアクセントを持つ英語を話すことができます。
Note
zh-CN ロケールの音声がサンプル データと同じアクセントで英語を話せるようにするには、プロジェクトの作成時に Chinese (Mandarin, Simplified), English bilingual を選ぶか、REST API でトレーニング セット データに対して zh-CN (English bilingual) ロケールを指定する必要があります。
次の表は、ロケール間の違いを示しています。
| Speech Studio のロケール | REST API のロケール | バイリンガルのサポート |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
サンプル データに英語が含まれている場合、合成された音声は、英語データの量に関係なく、サンプル データと同じアクセントではなく、英語のネイティブ アクセントで英語を話します。 |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
合成された音声がサンプル データと同じアクセントで英語を話すようにしたい場合は、トレーニング セットに 10% を超える英語データを含めることをお勧めします。 そうしないと、英語を話すアクセントが理想的ではない可能性があります。 |
Chinese (Cantonese, Simplified) |
zh-HK |
サンプル データと同じアクセントで英語を話せる合成音声をトレーニングしたい場合は、トレーニング セットで 10% より多くの英語データを提供するようにします。 そうしないと、既定で英語のネイティブ アクセントになります。 10% のしきい値は、アップロード前のデータではなく、アップロードが成功した後で受け入れられたデータに基づいて計算されます。 アップロードされた英語データの一部が欠陥のために拒否され、10% のしきい値を満たさなくなった場合、合成される音声は既定で英語のネイティブ アクセントになります。 |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
サンプル データと同じアクセントで英語を話せる合成音声をトレーニングしたい場合は、トレーニング セットで 10% より多くの英語データを提供するようにします。 そうしないと、既定で英語のネイティブ アクセントになります。 10% のしきい値は、アップロード前のデータではなく、アップロードが成功した後で受け入れられたデータに基づいて計算されます。 アップロードされた英語データの一部が欠陥のために拒否され、10% のしきい値を満たさなくなった場合、合成される音声は既定で英語のネイティブ アクセントになります。 |
さまざまな言語で利用可能なプリセット スタイル
次の表は、さまざまな言語に応じたさまざまなプリセット スタイルをまとめたものです。
| 話し方 | 言語 (ロケール) |
|---|---|
| 怒り | 英語 (米国) (en-US)日本語 (日本) ( ja-JP) 1中国語 (標準、簡体字) ( zh-CN) 1 |
| 穏やか | 中国語 (標準、簡体字) (zh-CN) 1 |
| chat | 中国語 (標準、簡体字) (zh-CN) 1 |
| 陽気 | 英語 (米国) (en-US)日本語 (日本) ( ja-JP) 1中国語 (標準、簡体字) ( zh-CN) 1 |
| 不満 | 中国語 (標準、簡体字) (zh-CN) 1 |
| 興奮 | 英語 (米国) (en-US) |
| 怖い | 中国語 (標準、簡体字) (zh-CN) 1 |
| 優しい | 英語 (米国) (en-US) |
| 希望に満ちた | 英語 (米国) (en-US) |
| 悲しい | 英語 (米国) (en-US)日本語 (日本) ( ja-JP) 1中国語 (標準、簡体字) ( zh-CN) 1 |
| 叫ぶ | 英語 (米国) (en-US) |
| 深刻 | 中国語 (標準、簡体字) (zh-CN) 1 |
| 恐怖 | 英語 (米国) (en-US) |
| unfriendly | 英語 (米国) (en-US) |
| ささやく | 英語 (米国) (en-US) |
1 ニューラル音声スタイルはパブリック プレビューで利用できます。 パブリック プレビューでのスタイルは、米国東部、西ヨーロッパ、東南アジアのサービス リージョンでのみ使用できます。
トレーニング状態の取得
音声モデルのトレーニング状態を取得するには、Custom Voice API の Models_Get 操作を使用します。 次の手順のようにして、要求 URI を作成します。
次の Models_Get の例に示すように、URI を使用して HTTP GET 要求を行います。
YourResourceKeyをSpeech リソース キーに置き換えます。YourResourceRegionを Azure Cognitive Service for Speech リソースのリージョンに置き換えます。- 前のステップで異なるモデル ID を指定した場合は、
JessicaModelIdを置き換えます。
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
次の形式で応答本文を受け取るはずです。
Note
レシピの kind と他のプロパティは、音声をトレーニングした方法によって異なります。 この例のレシピの種類は、ニューラル音声トレーニング用の Default です。
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
トレーニングが完了するまで数分待つ必要がある場合があります。 最終的に、状態は Succeeded または Failed に変わります。