プロの音声トレーニング データセットを追加する
お使いのアプリケーション用にカスタムのテキスト読み上げ音声を作成する準備ができたら、まず、オーディオ録音と関連するスクリプトを収集して、音声モデルのトレーニングを開始します。 音声サンプルの録音の詳細については、チュートリアルを参照してください。 音声サービスでは、このデータを使用して一意の音声を作成し、録音の音声に一致するように調整します。 音声のトレーニングが完了すると、お使いのアプリケーションで音声の合成を開始できます。
アップロードするすべてのデータは、選択したデータの種類の要件を満たしている必要があります。 データをアップロードする前に適切にフォーマットすることが重要です。これにより、音声サービスによってデータが正確に処理されるようになります。 データが正しく書式設定されていることを確認するには、「トレーニング データ型」を参照してください。
Note
- Standard サブスクリプション (S0) ユーザーは、5 個のデータ ファイルを同時にアップロードできます。 制限に達した場合は、少なくとも 1 つのデータ ファイルのインポートが終わるまで待機します。 その後、やり直してください。
- サブスクリプションあたりのインポートできるデータ ファイルの最大数は、Standard サブスクリプション (S0) ユーザーの場合は .zip ファイル 500 個です。 詳細については、「音声サービスのクォータと制限」を参照してください。
データをアップロードする
データをアップロードする準備ができたら、 [トレーニング データの準備] タブに移動し、最初のトレーニング セットを追加してデータをアップロードします。 "トレーニング セット" とは、音声モデルのトレーニングに使用される一連の音声発話とそのマッピング スクリプトです。 トレーニング セットを使用すると、トレーニング データを整理することができます。 サービスにより、トレーニング セットごとにデータの準備状況がチェックされます。 複数のデータを 1 つのトレーニング セットにインポートできます。
トレーニング データをアップロードするには、次の手順に従います。
- Speech Studio にサインインします。
- [Custom Voice]> [プロジェクト名] >[トレーニング データの準備]>[データのアップロード] の順に選択します。
- [データのアップロード] ウィザードで、[データ型] を選択し、[次へ] を選択します。
- コンピューターからローカル ファイルを選択するか、Azure BLOB ストレージの URL を入力してデータをアップロードします。
- [ターゲット トレーニング セットの指定] で、既存のトレーニング セットを選択するか、新しいトレーニング セットを作成します。 新しいトレーニング セットを作成した場合は、続行する前に、ドロップダウン リストで選択されていることを確認してください。
- [次へ] を選択します。
- データの名前と説明を入力し、[次へ] を選択します。
- アップロードの詳細を確認し、[送信] を選択します。
Note
重複する ID は使用できません。 同じ ID の発話は削除されます。
重複するオーディオ名はトレーニングから削除されます。 選択したデータ内の 1 つの .zip ファイルまたは複数の .zip ファイルに同じオーディオ名が含まれていないことを確認してください。 (オーディオ ファイルまたはスクリプト ファイル内の) 発話 ID が重複している場合、それらは拒否されます。
[送信] を選択すると、データ ファイルが自動的に検証されます。 データ検証には、ファイル形式、サイズ、サンプリング レートを確認する、オーディオ ファイルの一連のチェックが含まれます。 エラーが見つかった場合は、修正して再度送信します。
データがアップロードされたら、トレーニング セットの詳細ビューで詳細を確認できます。 概要ページでは、発音の問題と各データのノイズ レベルをさらにチェックできます。 文レベルでの発音スコアは 0 から 100 の範囲です。 スコアが 70 未満の場合は、通常、音声のエラーまたはスクリプトの不一致を示しています。 全体的なスコアが 70 未満の発話は拒否されます。 アクセントが強いと発音スコアが下がることがあり、生成されるデジタル音声に影響します。
オンラインでデータの問題を解決する
アップロード後、トレーニング セットのデータの詳細を確認できます。 音声モデルのトレーニングを続行する前に、データの問題を解決する必要があります。
Speech Studio では、発話ごとのデータの問題を特定して解決できます。
詳細ページで、[承諾データ] または [拒否されたデータ] ページに移動します。 変更する必要がある個々の発話を選んでから、[編集] を選びます。
![[承諾データ] または [拒否されたデータ] の詳細ページで [編集] ボタンを選択しているスクリーンショット。](media/custom-voice/cnv-edit-trainingset.png)
条件に基づいて、表示するデータの問題を選べます。
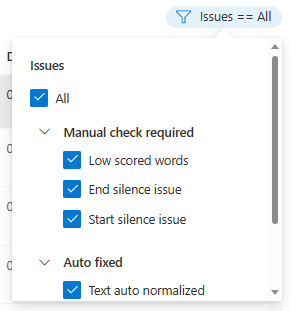
編集ウィンドウが表示されます。
![[トランスクリプトとレコーディング ファイルの編集] ウィンドウを表示しているスクリーンショット。](media/custom-voice/cnv-edit-trainingset-editscript.png)
編集ウィンドウの問題の説明に従って、トランスクリプトまたは記録ファイルを更新します。
テキスト ボックスでトランスクリプトを編集し、[完了] を選択できます
![[トランスクリプトとレコーディング ファイルの編集] ウィンドウで [完了] ボタンを選択しているスクリーンショット。](media/custom-voice/cnv-edit-trainingset-scriptedit-done.png)
レコーディング ファイルを更新する必要がある場合は、[記録ファイルの更新] を選択し、修正済みのレコーディング ファイル (.wav) をアップロードします。
![[トランスクリプトとレコーディング ファイルの編集] ウィンドウでのレコーディング ファイルのアップロードの方法を示しているスクリーンショット。](media/custom-voice/cnv-edit-trainingset-upload-recording.png)
データに変更を加えた後、このデータセットをトレーニングで使用する前に [Analyze data] (データの分析) をクリックして、データ品質をチェックする必要があります。
分析が完了する前に、このトレーニング セットをトレーニング モデルに対して選択することはできません。
![[データの詳細] ページで [データの分析] を選択しているスクリーンショット。](media/custom-voice/cnv-edit-trainingset-analyze.png)
また、問題のある発話を選択し、[削除] をクリックすることで削除することもできます。
一般的なデータの問題
これらの問題は 3 つの種類に分類されます。 次の表を参照して、それぞれのエラーの種類について確認してください。
自動拒否
これらのエラーを含むデータはトレーニングには使用されません。 エラーのあるインポート データは無視されるため、削除する必要はありません。 オンラインでこれらのデータ エラーを修正することも、トレーニングのために修正済みデータをもう一度アップロードすることもできます。
| カテゴリ | 名前 | 説明 |
|---|---|---|
| スクリプト | 無効な区切り記号 | 発話 ID とスクリプト コンテンツはタブ文字で分離する必要があります。 |
| スクリプト | 無効なスクリプト ID | スクリプトの行 ID は数値である必要があります。 |
| スクリプト | 重複したスクリプト | スクリプト コンテンツの各行は一意である必要があります。 この行は {} と重複しています。 |
| スクリプト | スクリプトが長すぎる | スクリプトは、1,000 文字未満にする必要があります。 |
| スクリプト | 一致するオーディオがない | 各発話 (スクリプト ファイルの各行) の ID は、オーディオ ID と一致する必要があります。 |
| スクリプト | 有効なスクリプトがない | このデータセットで有効なスクリプトが見つかりませんでした。 詳細な問題リストに表示されるスクリプト行を修正します。 |
| オーディオ | 一致するスクリプトがない | このスクリプト ID と一致するオーディオ ファイルはありません。 .wav ファイルの名前は、スクリプト ファイル内の ID と一致する必要があります。 |
| オーディオ | 無効なオーディオ形式 | .wav ファイルのオーディオ形式が無効です。 SoX のようなオーディオ ツールを使用して .wav ファイルの形式を確認してください。 |
| オーディオ | サンプリング レートが低い | .wav ファイルのサンプリング レートを 16 KHz 未満にすることはできません。 |
| オーディオ | 音声が長すぎる | 音声の長さが 30 秒を超えています。 長い音声を複数のファイルに分割してください。 発話を 15 秒より短くすることをお勧めします。 |
| オーディオ | 有効な音声がない | このデータセットには有効な音声が見つかりません。 音声データを確認して、もう一度アップロードしてください。 |
| 不一致 | 低スコアの発話 | 文レベルの発音スコアが 70 未満です。 スクリプトと音声コンテンツを調べて、それらが一致していることを確認します。 |
自動修正
次のエラーは自動的に修正されますが、正しく修正が行われたことを確認する必要があります。
| カテゴリ | 名前 | 説明 |
|---|---|---|
| 不一致 | 無音の自動修正 | 冒頭の無音が 100 ミリ秒より短いことが検出され、自動的に 100 ミリ秒に延長されました。 正規化されたデータセットをダウンロードして確認してください。 |
| 不一致 | 無音の自動修正 | 末尾の無音が 100 ミリ秒より短いことが検出され、自動的に 100 ミリ秒に延長されました。 正規化されたデータセットをダウンロードして確認してください。 |
| スクリプト | テキストの自動正規化 | テキストは、数字、記号、略語について自動的に正規化されます。 スクリプトとオーディオを調べて、それらが一致していることを確認します。 |
手動チェックが必要
次の表に示す未解決のエラーは、トレーニングの品質に影響しますが、これらのエラーを含むデータはトレーニング中に除外されません。 高品質のトレーニングを行うために、これらのエラーを手動で修正することをお勧めします。
| カテゴリ | 名前 | 説明 |
|---|---|---|
| スクリプト | 正規化されていないテキスト | このスクリプトには、記号が含まれています。 音声に一致するように記号を正規化します。 たとえば、/ を "スラッシュ" に正規化します。 |
| スクリプト | 質問の発話が十分ではない | 全体の発話のうち、少なくとも 10% は質問文である必要があります。 これにより、音声モデルが質問のトーンを適切に表現できるようになります。 |
| スクリプト | 感嘆の発話が十分ではない | 全体の発話のうち、少なくとも 10% は感嘆文である必要があります。 これにより、音声モデルが感嘆のトーンを適切に表現できるようになります。 |
| スクリプト | 有効な文末の句点がない | 行の末尾に次のいずれかを追加します。ピリオド (半角の '.' または全角の '。')、感嘆符 (半角の '!' または全角の '!' )、または疑問符 (半角の '?' または全角の '?')。 |
| オーディオ | ニューラル音声のサンプリング レートが低い | ニューラル音声を作成する際には、.wav ファイルのサンプリング レートを 24 KHz 以上に設定することをお勧めします。 低い場合は、自動的に 24 KHz に引き上げられます。 |
| ボリューム | 全体的にボリュームが低すぎる | ボリュームは -18 dB (最大ボリュームの 10%) より低くすることはできません。 サンプル録音中またはデータの準備時に、ボリュームの平均レベルが適切な範囲内になるように制御してください。 |
| ボリューム | ボリュームのオーバーフロー | オーバーフローしているボリュームが {} で検出されています。 ピーク値でのボリュームのオーバーフローを回避するように録音装置を調整してください。 |
| ボリューム | 冒頭の無音の問題 | 最初の 100 ミリ秒の無音がクリーンではありません。 録音のノイズ フロア レベルを下げ、最初の 100 ミリ秒を冒頭無音のままにします。 |
| ボリューム | 末尾の無音の問題 | 最後の 100 ミリ秒の無音がクリーンではありません。 録音のノイズ フロア レベルを下げ、最後の 100 ミリ秒を末尾無音のままにします。 |
| 不一致 | スコアが低い単語 | スクリプトと音声コンテンツを調べて、それらが一致していることを確認し、ノイズ フロア レベルを制御します。 長い無音の長さを短縮するか、長すぎる場合は音声を複数の発話に分割します。 |
| 不一致 | 冒頭の無音の問題 | 最初の単語の前に余分な音声が聞こえました。 スクリプトと音声コンテンツを調べて、それらが一致していることを確認し、ノイズ フロア レベルを制御し、最初の 100 ミリ秒が無音になるようにします。 |
| 不一致 | 末尾の無音の問題 | 最後の単語の後に余分な音声が聞こえました。 スクリプトと音声コンテンツを調べて、それらが一致していることを確認し、ノイズ フロア レベルを制御し、最後の 100 ミリ秒が無音になるようにします。 |
| 不一致 | 信号対雑音比が低い | 音声の SNR レベルが 20 dB より低くなっています。 少なくとも 35 dB にすることをお勧めします。 |
| 不一致 | 使用可能なスコアがない | この音声の音声コンテンツを認識できませんでした。 音声とスクリプト コンテンツを調べて、音声が有効であり、スクリプトと一致していることを確認します。 |
次のステップ
プロの音声を作成するためのトレーニング データセットが必要です。 トレーニング データセットには、オーディオ ファイルとスクリプト ファイルが含まれます。 オーディオ ファイルは、スクリプト ファイルを読み取るボイス タレントの録音です。 スクリプト ファイルは、オーディオ ファイルのテキストです。
この記事では、トレーニング セットを作成し、そのリソース ID を取得します。 次に、リソース ID を使用して、一連のオーディオ ファイルとスクリプト ファイルをアップロードできます。
トレーニング セットを作成する
トレーニング セットを作成するには、Custom Voice API の TrainingSets_Create 操作を使用します。 次の手順に従って要求本文を作成します。
- 必須の
projectIdプロパティを設定します。 プロジェクトを作成するに関するページを参照してください。 - 必須の
voiceKindプロパティをMaleまたはFemaleに設定します。 種類を後から変更することはできません。 - 必須の
localeプロパティを設定します。 これは、トレーニング セット データのロケールにする必要があります。 トレーニング セットのロケールは、同意ステートメントのロケールと同じである必要があります。 ロケールを後から変更することはできません。 テキスト読み上げロケールの一覧はここにあります。 - 必要に応じて、トレーニング セットの説明に
descriptionプロパティを設定します。 トレーニング セットの説明は後で変更できます。
HTTP PUT 要求は、以下の TrainingSets_Create の例に示したように URI を使用して行います。
YourResourceKeyをSpeech リソース キーに置き換えます。YourResourceRegionを、Speech リソース リージョンに置き換えます。JessicaTrainingSetIdを、選択したトレーニング セット ID に置き換えます。 大文字と小文字を区別する ID がトレーニング セットの URI で使用され、後で変更することはできません。
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
次の形式で応答本文を受け取る必要があります。
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
トレーニング セット データをアップロードする
オーディオとスクリプトのトレーニング セットをアップロードするには、Custom Voice API の TrainingSets_UploadData 操作を使用します。
この API を呼び出す前に、レコーディング ファイルとスクリプト ファイルを Azure BLOB に保存してください。 以下の例では、レコーディング ファイルは https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav、スクリプト ファイルは https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt です。
次の手順に従って要求本文を作成します。
- 必須の
kindプロパティをAudioAndScriptに設定します。 種類によってトレーニング セットのタイプが決まります。 - 必須の
audiosプロパティを設定します。audiosプロパティ内で、次のプロパティを設定します。- 必須の
containerUrlプロパティを、オーディオ ファイルを含む Azure Blob Storage コンテナーの URL に設定します。 読み取りアクセス許可とリスト アクセス許可の両方を持つコンテナーには、Shared Access Signature (SAS) を使用します。 - 必須の
extensionsプロパティを、オーディオ ファイルの拡張子に設定します。 - 必要に応じて、
prefixプロパティを設定して、BLOB 名のプレフィックスを設定します。
- 必須の
- 必須の
scriptsプロパティを設定します。scriptsプロパティ内で、次のプロパティを設定します。- 必須の
containerUrlプロパティを、スクリプト ファイルを含む Azure Blob Storage コンテナーの URL に設定します。 読み取りアクセス許可とリスト アクセス許可の両方を持つコンテナーには、Shared Access Signature (SAS) を使用します。 - 必須の
extensionsプロパティを、スクリプト ファイルの拡張子に設定します。 - 必要に応じて、
prefixプロパティを設定して、BLOB 名のプレフィックスを設定します。
- 必須の
HTTP POST 要求は、以下の TrainingSets_UploadData の例に示したように URI を使用して行います。
YourResourceKeyをSpeech リソース キーに置き換えます。YourResourceRegionを、Speech リソース リージョンに置き換えます。- 前の手順で別のトレーニング セット ID を指定した場合は、
JessicaTrainingSetIdを置き換えます。
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
応答ヘッダーに Operation-Location プロパティが含まれています。 この URI を使用して、TrainingSets_UploadData 操作の詳細を取得します。 応答ヘッダーの例を次に示します。
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345