Azure AI Foundry を使用してコンテンツ フィルターを構成する方法
Azure AI Foundry に統合されたコンテンツ フィルタリング システムは、DALL-E イメージ生成モデルを含むコア モデルと共に実行されます。 マルチクラス分類モデルのアンサンブルを使用して、有害なコンテンツ (暴力、憎悪、性的、自傷行為) の 4 つのカテゴリをそれぞれ 4 つの重大度レベル (安全、低、中、高) で検出し、オプションで二項分類器を使用して、脱獄リスク、既存のテキスト、パブリック リポジトリ内のコードを検出します。
既定のコンテンツ フィルタリング構成では、プロンプトと入力候補の両方で、4 つの有害なコンテンツ カテゴリすべてに対して "中" の重大度しきい値でフィルター処理するように設定されています。 つまり、重大度レベル "中" または "高" で検出されたコンテンツはコンテンツ フィルターによってフィルタリングされますが、重大度レベル "低" で検出されたコンテンツはフィルタリングされません。 コンテンツ カテゴリ、重大度レベル、およびコンテンツ フィルタリング システムの動作の詳細については、こちらを参照してください。
脱獄リスク検出、保護されたテキスト、およびコード モデルは省略可能で、既定ではオンになっています。 脱獄、保護された素材のテキスト、およびコード モデルについては、構成可能性機能により、すべてのお客様がモデルのオン/オフを切り替えることができます。 モデルは既定ではオンになっており、シナリオに応じてオフにできます。 モデルによっては、Customer Copyright Commitment の適用範囲を維持するために、特定のシナリオでオンになっている必要がある場合があります。
Note
すべての顧客は、コンテンツ フィルターを変更し、重大度のしきい値 (低、中、高) を構成できます。 コンテンツ フィルターを部分的または完全にオフにする場合は、承認が必要です。 管理対象のお客様は、Azure OpenAI 制限付きアクセス レビュー: 変更されたコンテンツ フィルターというフォームを介してのみ、完全なコンテンツ フィルター制御を適用できます。 現時点では、管理対象のお客様になることはできません。
コンテンツ フィルターは、リソース レベルで構成できます。 新しい構成を作成したら、1 つ以上のデプロイに関連付けることができます。 モデル デプロイの詳細については、リソース デプロイ ガイドを参照してください。
前提条件
- コンテンツ フィルターを構成するには、Azure OpenAI リソースと大規模言語モデル (LLM) のデプロイが必要です。 クイックスタートに従って始めてください。
コンテンツ フィルターの構成可否について
Azure OpenAI Service には、(Azure OpenAI Whisper を除く) すべてのモデルに適用される既定の安全性の設定が含まれています。 これらの構成により、コンテンツ フィルタリング モデル、ブロックリスト、プロンプト変換、コンテンツ資格情報など、責任あるエクスペリエンスが既定で提供されます。 詳細については、こちらを参照してください。
また、すべてのお客様は、コンテンツ フィルターを構成し、ユース ケースの要件に合わせたカスタム安全性ポリシーを作成することもできます。 この構成機能を使用すると、利用者はプロンプトと補完の設定を個別に調整し、以下の表に示す異なる重大度レベルで各コンテンツ カテゴリのコンテンツをフィルター処理できます。 重大度レベル "安全" で検出されたコンテンツは注釈でラベル付けされますが、フィルタリングの対象ではなく、構成もできません。
| フィルタリングされた重大度 | プロンプト用に構成可能 | 入力候補用に構成可能 | 説明 |
|---|---|---|---|
| [低]、[中]、[高] | はい | はい | 最も厳密なフィルタリング構成。 重大度レベルが低、中、高で検出されたコンテンツはフィルタリングされます。 |
| 中、高 | はい | はい | 低い重大度レベルの検出されたコンテンツはフィルター処理されず、中および高のコンテンツはフィルター処理されます。 |
| 高 | はい | はい | 重大度レベルが低および中で検出されたコンテンツはフィルター処理されません。 重大度レベルが高のコンテンツのみがフィルタリングされます。 |
| フィルターなし | 承認された場合 1 | 承認された場合 1 | 重大度レベルの検出に関係なく、コンテンツはフィルタリングされません。 承認が必要1. |
| 注釈のみ | 承認された場合 1 | 承認された場合 1 | フィルター機能を無効にするため、コンテンツはブロックされませんが、注釈は API 応答を介して返されます。 承認が必要1. |
1 Azure OpenAI モデルの場合、変更されたコンテンツ フィルタリングを承認されたお客様のみコンテンツのフィルター処理を完全に制御でき、コンテンツ フィルターをオフにできます。 次のフォームから修正コンテンツ フィルターを申請してください: Azure OpenAI 制限付きアクセス レビュー: 修正コンテンツ フィルター。 Azure Government のお客様の場合は、次のフォームから修正コンテンツ フィルターを申請してください: Azure Government - Azure OpenAI Service の修正コンテンツ フィルタリングのリクエスト。
入力 (プロンプト) と出力 (入力候補) の構成可能なコンテンツ フィルターは、すべての Azure OpenAI モデルで利用できます。
コンテンツ フィルタリング構成は、Azure AI Foundry ポータルのリソース内に作成され、デプロイに関連付けることができます。 構成可能性の詳細については、こちらを参照してください。
Azure OpenAI を統合するアプリケーションが倫理規定に準拠していることを確認する責任は、お客様にあります。
その他のフィルターについて
既定の危害カテゴリ フィルターに加えて、次のフィルター カテゴリを構成できます。
| フィルター カテゴリー | 状態 | 既定の設定 | プロンプトと入力候補のどちらに適用されますか? | 説明 |
|---|---|---|---|---|
| 直接攻撃に関するプロンプト シールド (ジェイルブレイク) | GA | オン | ユーザー プロンプト | ジェイルブレイク リスクがあるかもしれないユーザー プロンプトをフィルター処理/注釈付けします。 注釈の詳細については、「Azure AI Foundry のコンテンツ フィルタリング」を参照してください。 |
| 間接攻撃に関するプロンプト シールド | GA | "オフ" | ユーザー プロンプト | 生成 AI システムがアクセスして処理できるドキュメント内に、第三者が悪意のある命令を配置する潜在的な脆弱性である間接攻撃 (別名、間接プロンプト攻撃またはクロスドメイン プロンプト インジェクション攻撃) をフィルター処理/注釈付けします。 必須: ドキュメントの埋め込みと書式設定。 |
| 保護された素材 - コード | GA | オン | 完了 | 保護されたコードをフィルター処理するか、GitHub Copilot を利用して何らかのパブリック コード ソースと一致するコード スニペット用の注釈内の引用とライセンスの情報の例を取得します。 注釈の使用に関する詳細については、「コンテンツのフィルター処理の概念のガイド」を参照してください |
| 保護された素材 - テキスト | GA | オン | 完了 | 既知のテキスト コンテンツを識別し、モデル出力内でそれが表示されることをブロックします (たとえば、曲の歌詞、レシピ、選択した Web コンテンツなど)。 |
| グラウンデッドネス* | プレビュー | "オフ" | 完了 | 大規模言語モデル (LLM) のテキスト応答が、ユーザーが提供するソース資料に基づいているかどうかを検出します。 根拠なしとは、ソース資料に存在していた事実に基づかない、または不正確な情報が LLM から生成されることを指します。 必須: ドキュメントの埋め込みと書式設定。 |
Azure AI Foundry でコンテンツ フィルターを作成する
Azure AI Foundry 内のモデル デプロイに対しては、既定のコンテンツ フィルターを直接使用できますが、より詳細な制御が必要な場合があります。 たとえば、フィルターをより厳密にしたり、より緩やかにしたり、プロンプト シールドや保護されたマテリアルの検出などのより高度な機能を有効にしたりできます。
ヒント
Azure AI Foundry プロジェクトでのコンテンツ フィルターに関するガイダンスについては、Azure AI Foundry コンテンツ フィルタリングに関するページを参照してください。
コンテンツ フィルターを作成するには、以下の手順に従います。
Azure AI Foundry にアクセスし、プロジェクトに移動します。 次に、左側のメニューから [安全性とセキュリティ] ページを選択し、[コンテンツ フィルター] タブを選択します。

[+ コンテンツ フィルターの作成] を選択します。
[基本情報] ページで、コンテンツ フィルタリングの構成の名前を入力します。 コンテンツ フィルターに関連付ける接続を選択します。 [次へ] を選択します。
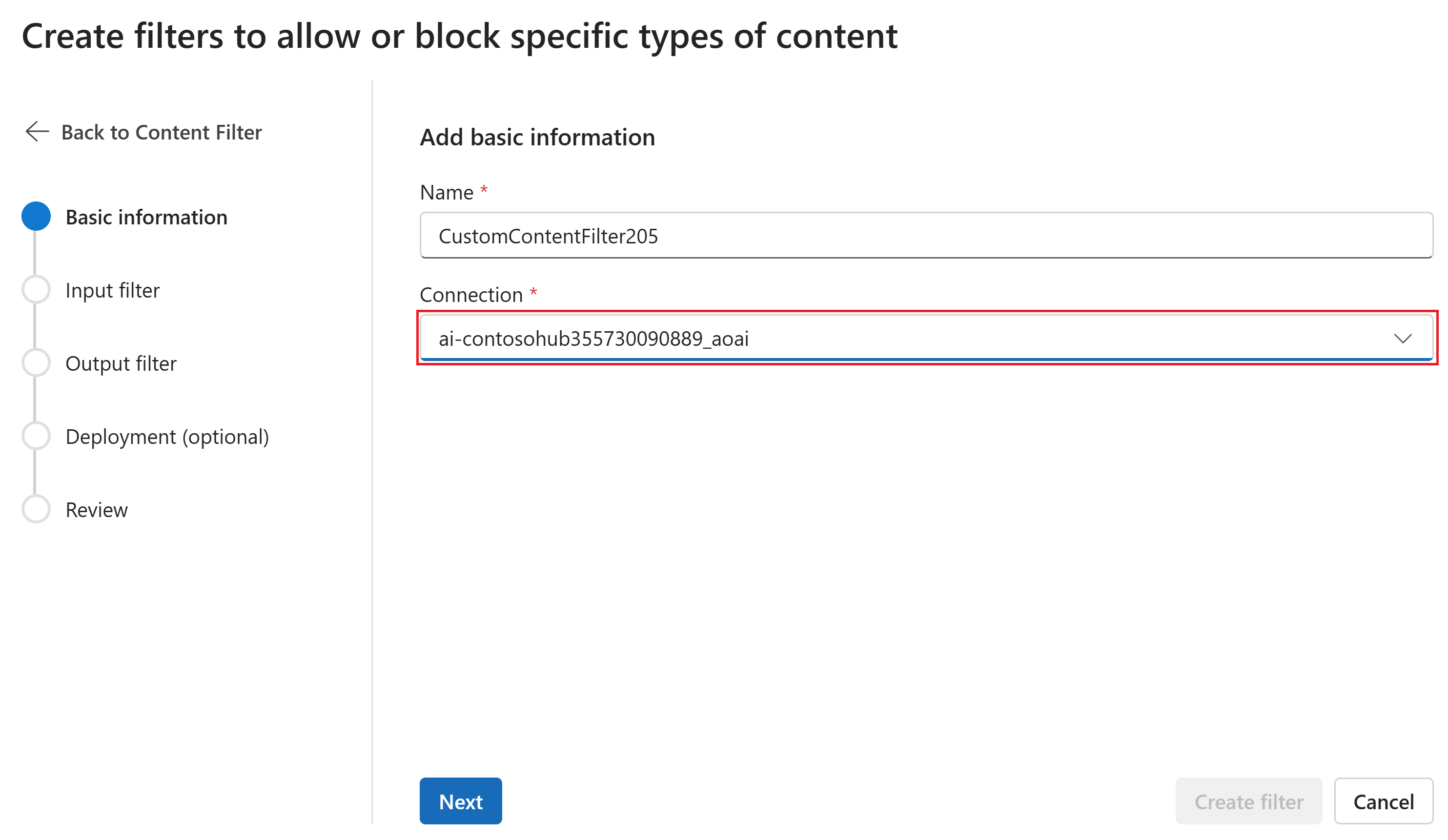
次に、入力フィルター (ユーザー プロンプト用) と出力フィルター (モデル補完用) を構成できます。
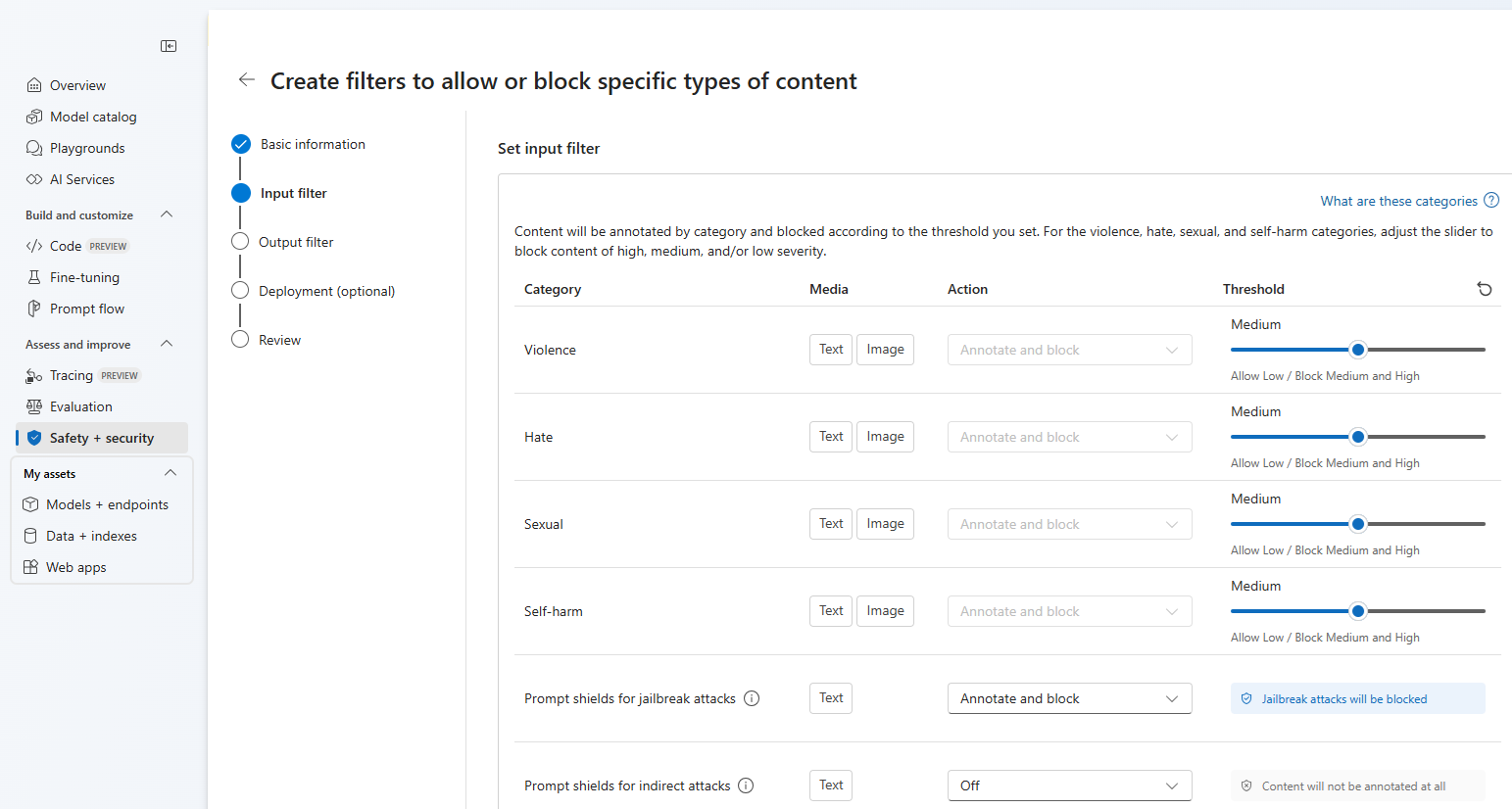
[入力フィルター] ページでは、入力プロンプトのフィルターを設定できます。 最初の 4 つのコンテンツ カテゴリには、低、中、高の 3 つの重大度レベルを構成できます。 アプリケーションまたは使用シナリオで既定値とは異なるフィルター処理が必要であると判断した場合は、スライダーを使用して重大度のしきい値を設定できます。 フィルターの中には、たとえば "プロンプト シールド" や "保護されたマテリアルの検出" のように、モデルがコンテンツに注釈を付けたりブロックしたりする必要があるかどうかの判断に利用できるものがあります。 [注釈のみ] を選択すると、それぞれのモデルが実行されて注釈が API 応答を介して返されますが、コンテンツのフィルタリングは行われません。 注釈を付けるだけでなく、コンテンツをブロックすることもできます。
お客様のユース ケースで修正済みコンテンツ フィルターの使用が承認された場合は、お客様はコンテンツ フィルタリング構成のあらゆる面の制御が可能であり、フィルタリングを部分的または完全にオフにするかどうか、または有害なコンテンツ カテゴリ (暴力、憎悪、性的、自傷行為) に対してのみ注釈を付けるかどうかを選択できます。
コンテンツはカテゴリによって注釈付けされ、ユーザーが設定したしきい値に従ってブロックされます。 暴力、ヘイト、性的、自傷行為のカテゴリに関して、スライダーを調整して、重大度が高、中、または低のコンテンツをブロックします。
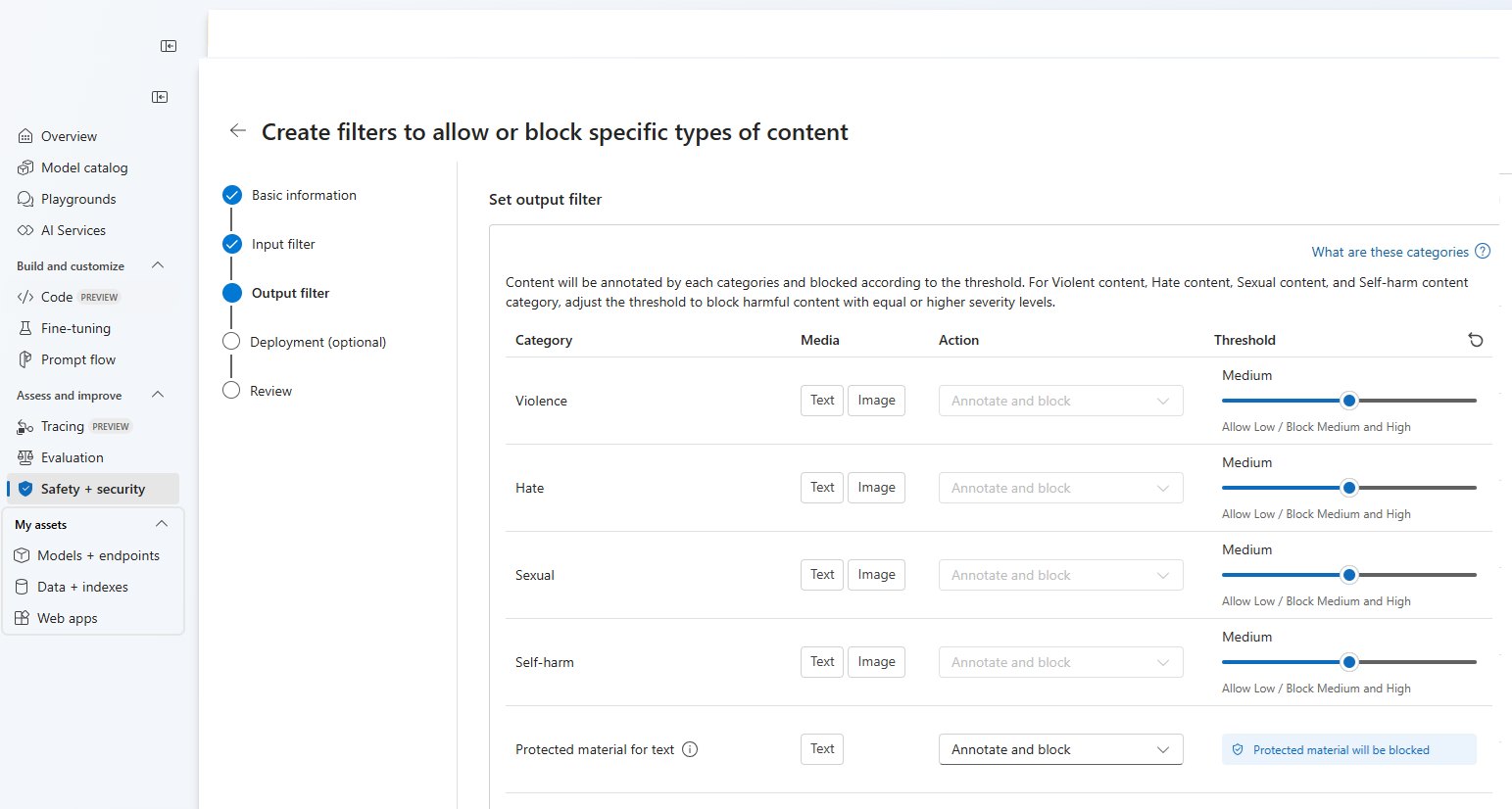
[出力フィルター] ページでは、出力フィルターを構成できます。このフィルターは、お使いのモデルによって生成されるあらゆる出力コンテンツに適用されます。 以前と同じように個々のフィルターを構成します。 このページには、ストリーミング モード オプションもあります。このオプションでは、モデルによって生成されるほぼリアルタイムのタイミングでコンテンツにフィルターを適用できます。待ち時間が短縮されます。 完了したら、[次へ] を選択します。
コンテンツは各カテゴリによって注釈付けされ、しきい値に従ってブロックされます。 暴力コンテンツ、ヘイト コンテンツ、性的コンテンツ、自傷行為コンテンツ カテゴリに関して、しきい値を調整して、重大度レベルがそれ以上の有害なコンテンツをブロックします。
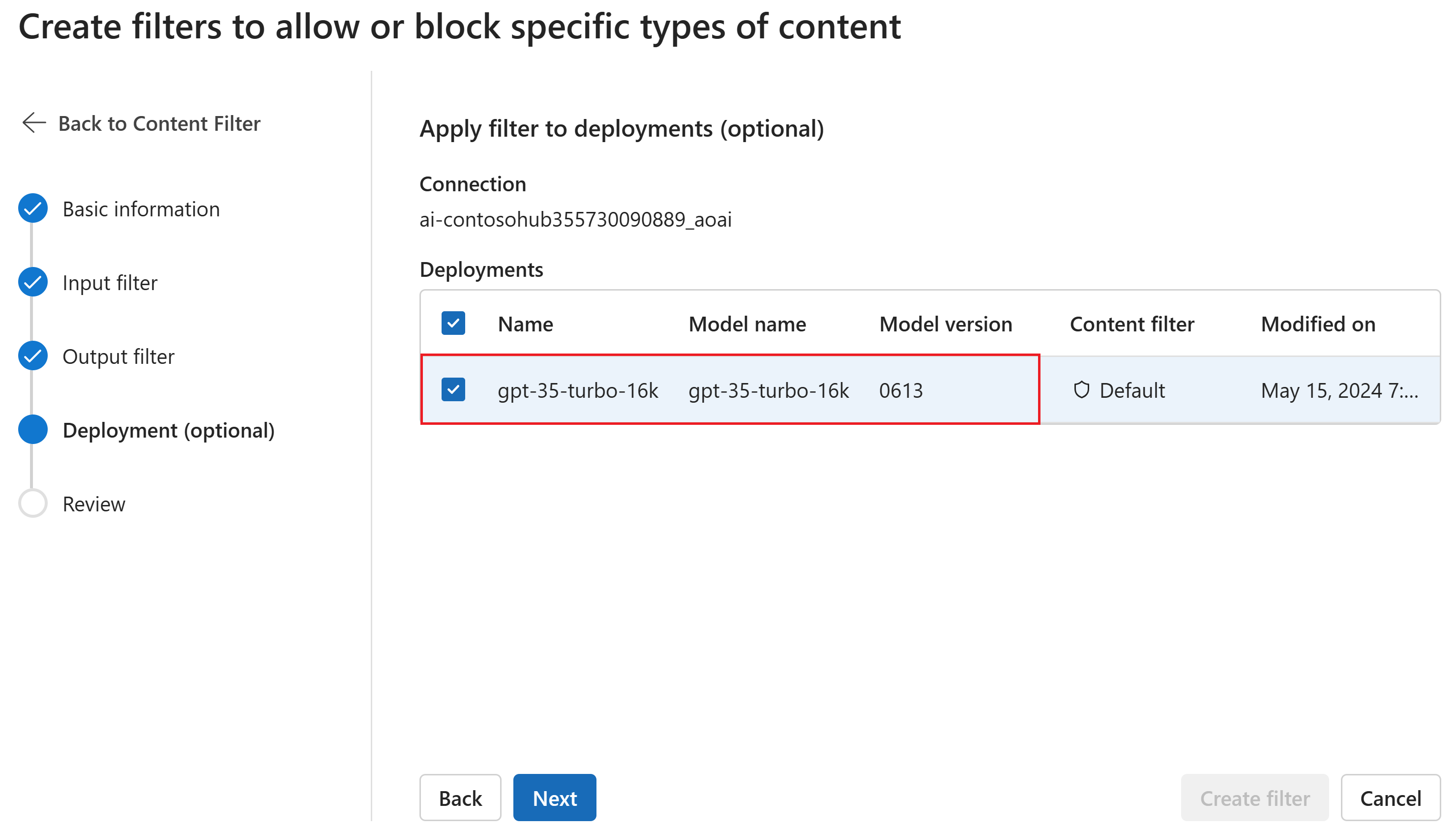
必要に応じて、[デプロイ] ページで、コンテンツ フィルターをデプロイに関連付けることができます。 選択されたデプロイにフィルターが既にアタッチされている場合、その置換を望むことを確定する必要があります。 コンテンツ フィルターを後でデプロイに関連付けることもできます。 [作成] を選択します
コンテンツ フィルタリングの構成は、Azure AI Foundry ポータルのハブ レベルで作成されます。 Azure OpenAI Service のドキュメントで構成可能性の詳細を確認してください。
[確認] ページで、設定を確認した後、[フィルターの作成] を選択します。



ブロックリストをフィルターとして使用する
ブロックリストは、入力フィルター、出力フィルター、またはその両方として適用できます。 [入力フィルター] または [出力フィルター] ページ、あるいはその両方で [ブロックリスト] オプションを有効にします。 ドロップダウンから 1 つ以上のブロックリストを選択するか、組み込みの不適切表現のブロックリストを使用します。 複数のブロックリストを同じフィルターに結合することができます。
コンテンツ フィルターを適用する
フィルター作成プロセスには、必要なデプロイにフィルターを適用するオプションがあります。 デプロイのコンテンツ フィルターはいつでも変更または削除することもできます。
コンテンツ フィルターをデプロイに適用するには、以下の手順に従います。
Azure AI Foundry に移動し、プロジェクトを選択します。
左側のペインで [モデルとエンドポイント] を選択し、いずれかのデプロイを選択してから、[編集] を選択します。

[デプロイの更新] ウィンドウで、デプロイに対して適用したいコンテンツ フィルターを選択します。 次に、保存して終了 を選択します。

必要に応じて、コンテンツ フィルター構成を編集および削除することもできます。 コンテンツ フィルタリング構成を削除する前に、[デプロイ] タブでデプロイへの割り当てを解除して置き換える必要があります。


これで、プレイグラウンドに移動して、コンテンツ フィルターが想定どおりに動作するかどうかをテストできます。
コンテンツ フィルタリングのフィードバックを報告する
コンテンツ フィルタリングの問題が発生した場合は、プレイグラウンドの上部にある [フィードバックをフィルター処理] ボタンを選択してください。 これは、プロンプトを送信すると、画像、チャット、補完のプレイグラウンドで有効になります。
ダイアログが表示されたら、該当するコンテンツ フィルタリングの問題を選択します。 コンテンツ フィルタリングの問題に関連する情報をできるだけ詳しく記述してください。たとえば、具体的なプロンプトと発生したコンテンツ フィルタリング エラーです。 個人情報や機密情報が含まれないようにしてください。
サポートが必要な場合は、サポート チケットを提出してください。
ベスト プラクティスに従う
反復的な特定 (レッド チーム テスト、ストレス テスト、分析など) と測定のプロセスを通じてコンテンツ フィルタリング構成の決定を通知し、特定のモデル、アプリケーション、デプロイ シナリオに関連する潜在的な損害に対処することをお勧めします。 コンテンツ フィルタリングなどの軽減策を実装した後、測定を繰り返して有効性をテストします。 Microsoft Responsible AI Standard に基づいた Azure OpenAI の Responsible AI に関する推奨事項とベスト プラクティスについては、「Azure OpenAI の Responsible AI の概要」を参照してください。
関連するコンテンツ
- Azure OpenAI の Responsible AI プラクティスの詳細については、「Azure OpenAI モデルの Responsible AI プラクティスの概要」に関するページを参照してください。
- Azure AI Foundry を使用したコンテンツ フィルタリング カテゴリと重大度レベルに関するページで詳細を参照してください。
- レッド チーミングの詳細については、「大規模言語モデル (LLM) のレッド チーミングの概要」の記事を参照してください。