Content filtering in Azure AI Foundry portal
Azure AI Foundry includes a content filtering system that works alongside core models and DALL-E image generation models.
Important
The content filtering system isn't applied to prompts and completions processed by the Whisper model in Azure OpenAI Service. Learn more about the Whisper model in Azure OpenAI.
How it works
This content filtering system is powered by Azure AI Content Safety, and it works by running both the prompt input and completion output through an ensemble of classification models aimed at detecting and preventing the output of harmful content. Variations in API configurations and application design might affect completions and thus filtering behavior.
With Azure OpenAI model deployments, you can use the default content filter or create your own content filter (described later on). Models available through serverless APIs have content filtering enabled by default. To learn more about the default content filter enabled for serverless APIs, see Content safety for models curated by Azure AI in the model catalog.
Language support
The content filtering models have been trained and tested on the following languages: English, German, Japanese, Spanish, French, Italian, Portuguese, and Chinese. However, the service can work in many other languages, but the quality can vary. In all cases, you should do your own testing to ensure that it works for your application.
Content risk filters (input and output filters)
The following special filters work for both input and output of generative AI models:
Categories
| Category | Description |
|---|---|
| Hate | The hate category describes language attacks or uses that include pejorative or discriminatory language with reference to a person or identity group based on certain differentiating attributes of these groups including but not limited to race, ethnicity, nationality, gender identity and expression, sexual orientation, religion, immigration status, ability status, personal appearance, and body size. |
| Sexual | The sexual category describes language related to anatomical organs and genitals, romantic relationships, acts portrayed in erotic or affectionate terms, physical sexual acts, including those portrayed as an assault or a forced sexual violent act against one's will, prostitution, pornography, and abuse. |
| Violence | The violence category describes language related to physical actions intended to hurt, injure, damage, or kill someone or something; describes weapons, etc. |
| Self-Harm | The self-harm category describes language related to physical actions intended to purposely hurt, injure, or damage one's body, or kill oneself. |
Severity levels
| Category | Description |
|---|---|
| Safe | Content might be related to violence, self-harm, sexual, or hate categories but the terms are used in general, journalistic, scientific, medical, and similar professional contexts, which are appropriate for most audiences. |
| Low | Content that expresses prejudiced, judgmental, or opinionated views, includes offensive use of language, stereotyping, use cases exploring a fictional world (for example, gaming, literature) and depictions at low intensity. |
| Medium | Content that uses offensive, insulting, mocking, intimidating, or demeaning language towards specific identity groups, includes depictions of seeking and executing harmful instructions, fantasies, glorification, promotion of harm at medium intensity. |
| High | Content that displays explicit and severe harmful instructions, actions, damage, or abuse; includes endorsement, glorification, or promotion of severe harmful acts, extreme or illegal forms of harm, radicalization, or nonconsensual power exchange or abuse. |
Other input filters
You can also enable special filters for generative AI scenarios:
- Jailbreak attacks: Jailbreak Attacks are User Prompts designed to provoke the Generative AI model into exhibiting behaviors it was trained to avoid or to break the rules set in the System Message.
- Indirect attacks: Indirect Attacks, also referred to as Indirect Prompt Attacks or Cross-Domain Prompt Injection Attacks, are a potential vulnerability where third parties place malicious instructions inside of documents that the Generative AI system can access and process.
Other output filters
You can also enable the following special output filters:
- Protected material for text: Protected material text describes known text content (for example, song lyrics, articles, recipes, and selected web content) that can be outputted by large language models.
- Protected material for code: Protected material code describes source code that matches a set of source code from public repositories, which can be outputted by large language models without proper citation of source repositories.
- Groundedness: The groundedness detection filter detects whether the text responses of large language models (LLMs) are grounded in the source materials provided by the users.
Create a content filter in Azure AI Foundry
For any model deployment in Azure AI Foundry, you can directly use the default content filter, but you might want to have more control. For example, you could make a filter stricter or more lenient, or enable more advanced capabilities like prompt shields and protected material detection.
Tip
For guidance with content filters in your Azure AI Foundry project, you can read more at Azure AI Foundry content filtering.
Follow these steps to create a content filter:
Go to Azure AI Foundry and navigate to your project. Then select the Safety + security page from the left menu and select the Content filters tab.

Select + Create content filter.
On the Basic information page, enter a name for your content filtering configuration. Select a connection to associate with the content filter. Then select Next.
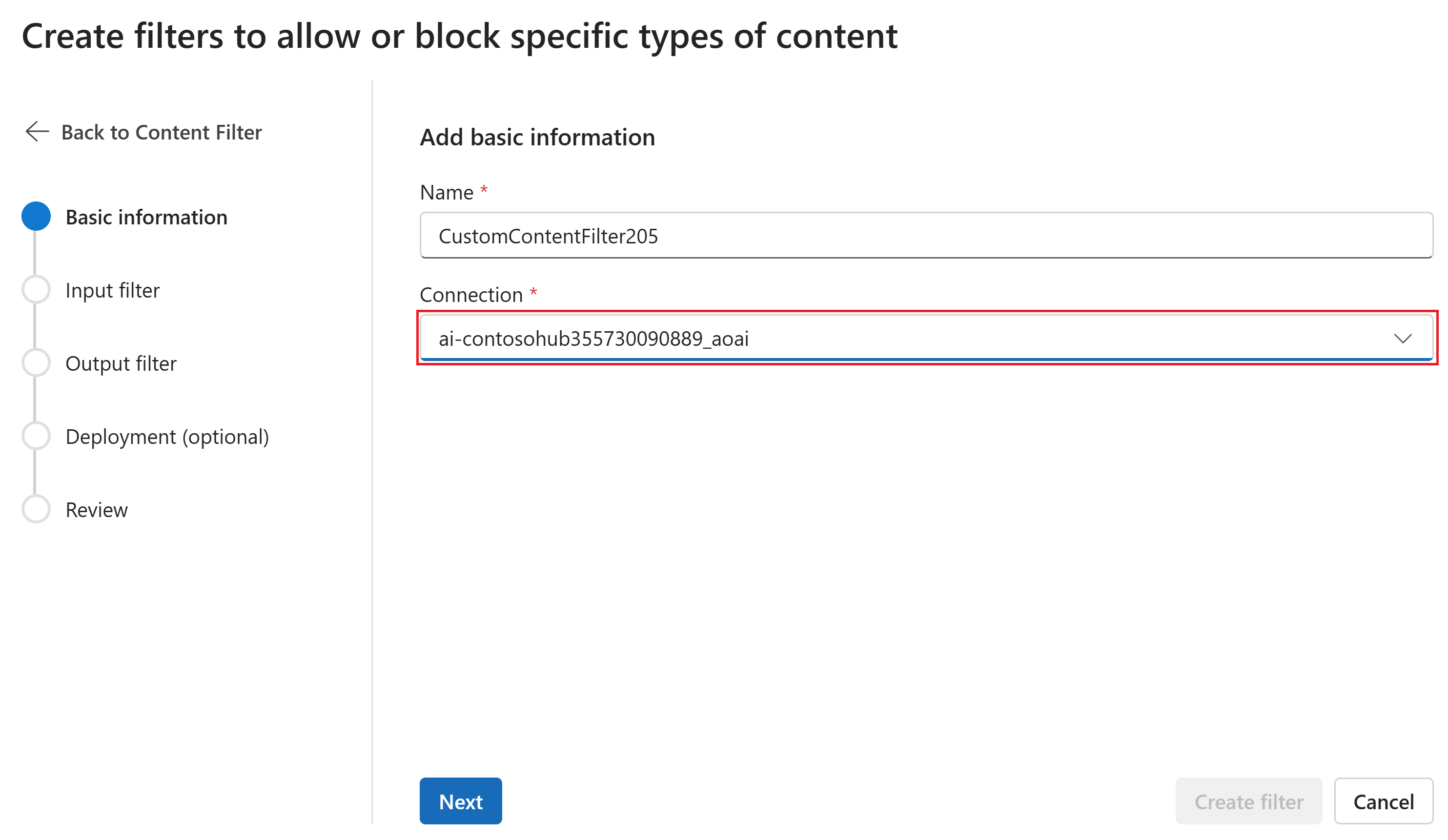
Now you can configure the input filters (for user prompts) and output filters (for model completion).
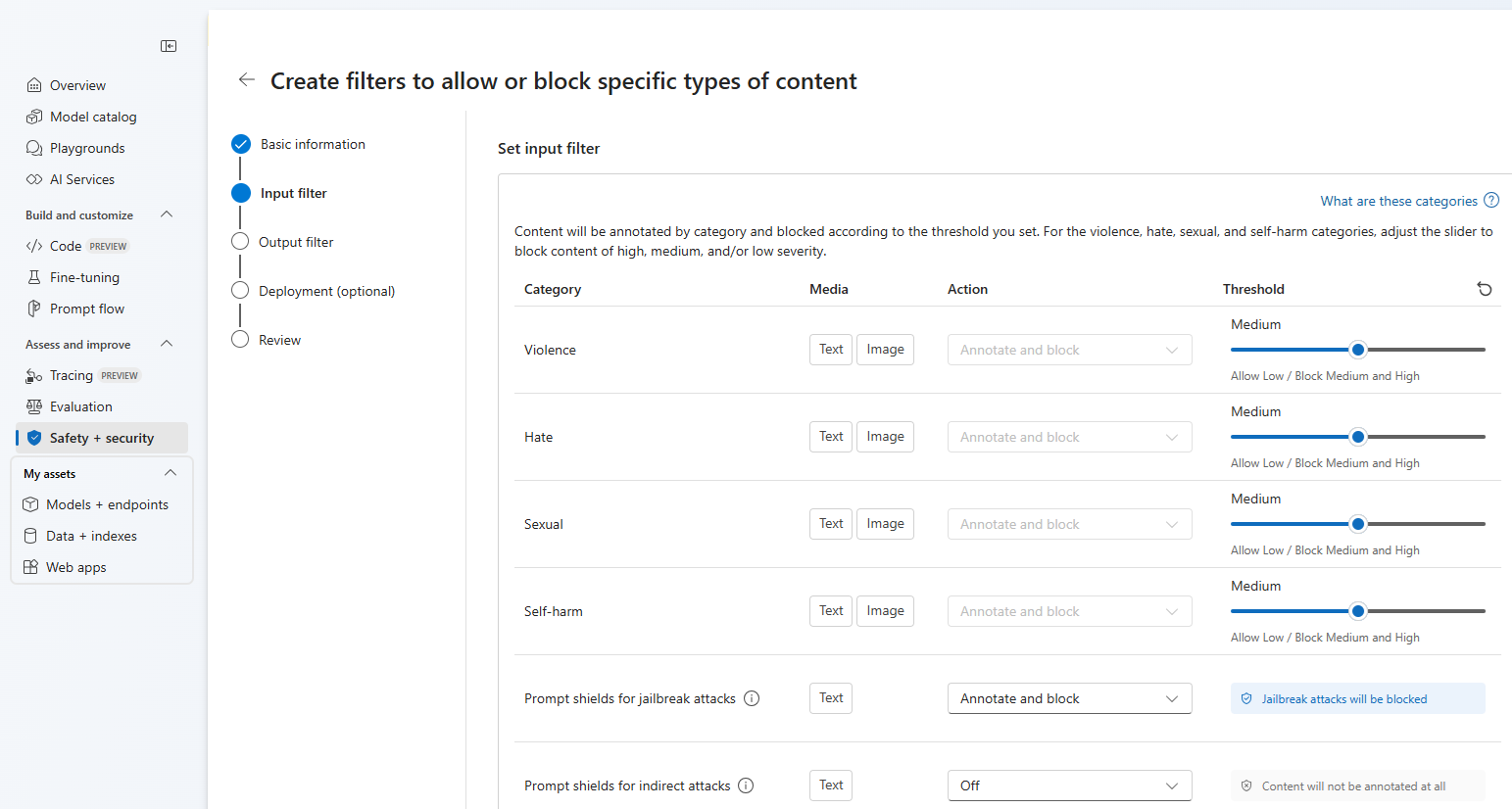
On the Input filters page, you can set the filter for the input prompt. For the first four content categories there are three severity levels that are configurable: Low, medium, and high. You can use the sliders to set the severity threshold if you determine that your application or usage scenario requires different filtering than the default values. Some filters, such as Prompt Shields and Protected material detection, enable you to determine if the model should annotate and/or block content. Selecting Annotate only runs the respective model and return annotations via API response, but it will not filter content. In addition to annotate, you can also choose to block content.
If your use case was approved for modified content filters, you receive full control over content filtering configurations and can choose to turn filtering partially or fully off, or enable annotate only for the content harms categories (violence, hate, sexual and self-harm).
Content will be annotated by category and blocked according to the threshold you set. For the violence, hate, sexual, and self-harm categories, adjust the slider to block content of high, medium, or low severity.
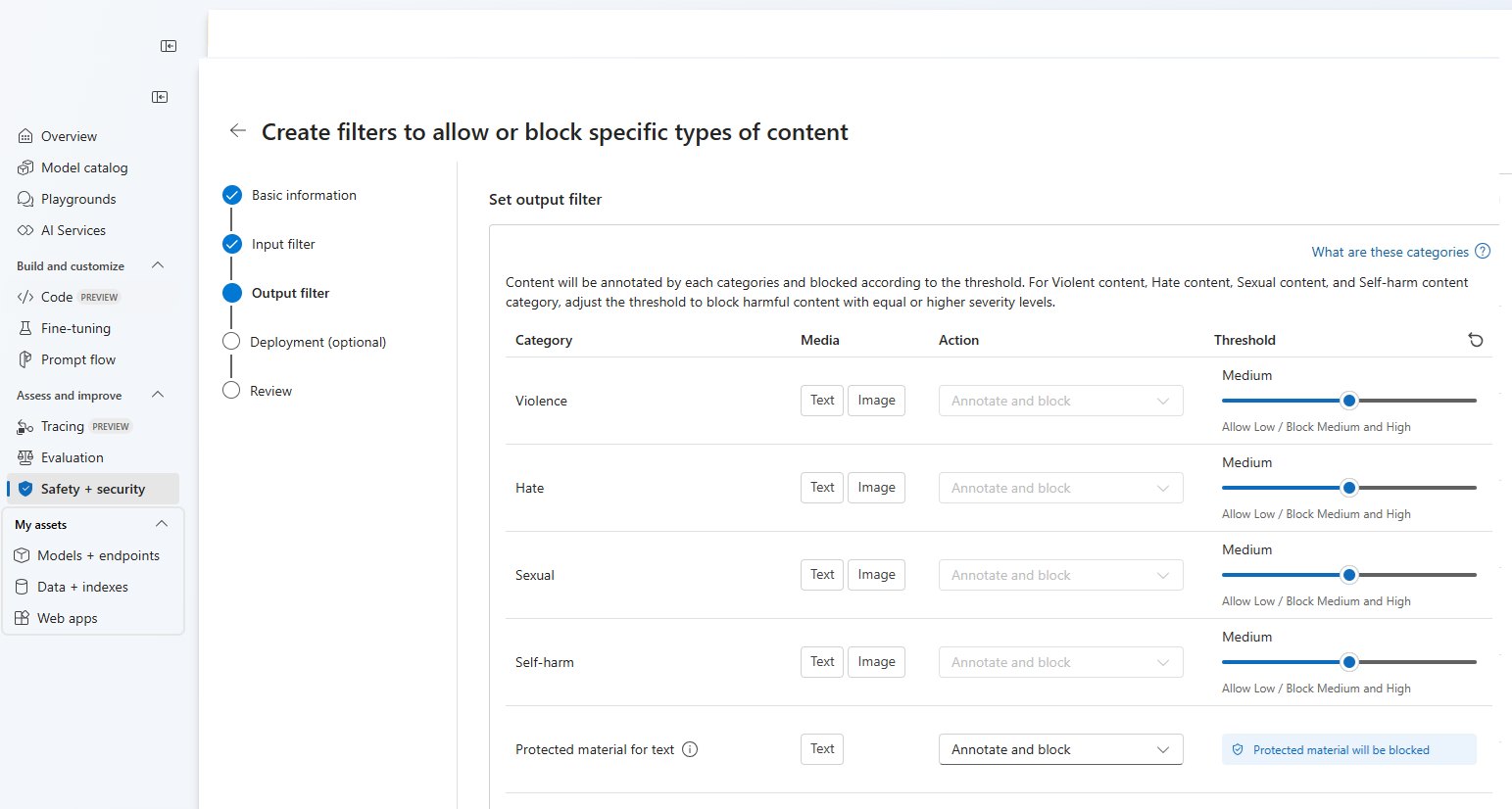
On the Output filters page, you can configure the output filter, which will be applied to all output content generated by your model. Configure the individual filters as before. This page also provides the Streaming mode option, which lets you filter content in near-real-time as it's generated by the model, reducing latency. When you're finished select Next.
Content will be annotated by each category and blocked according to the threshold. For violent content, hate content, sexual content, and self-harm content category, adjust the threshold to block harmful content with equal or higher severity levels.
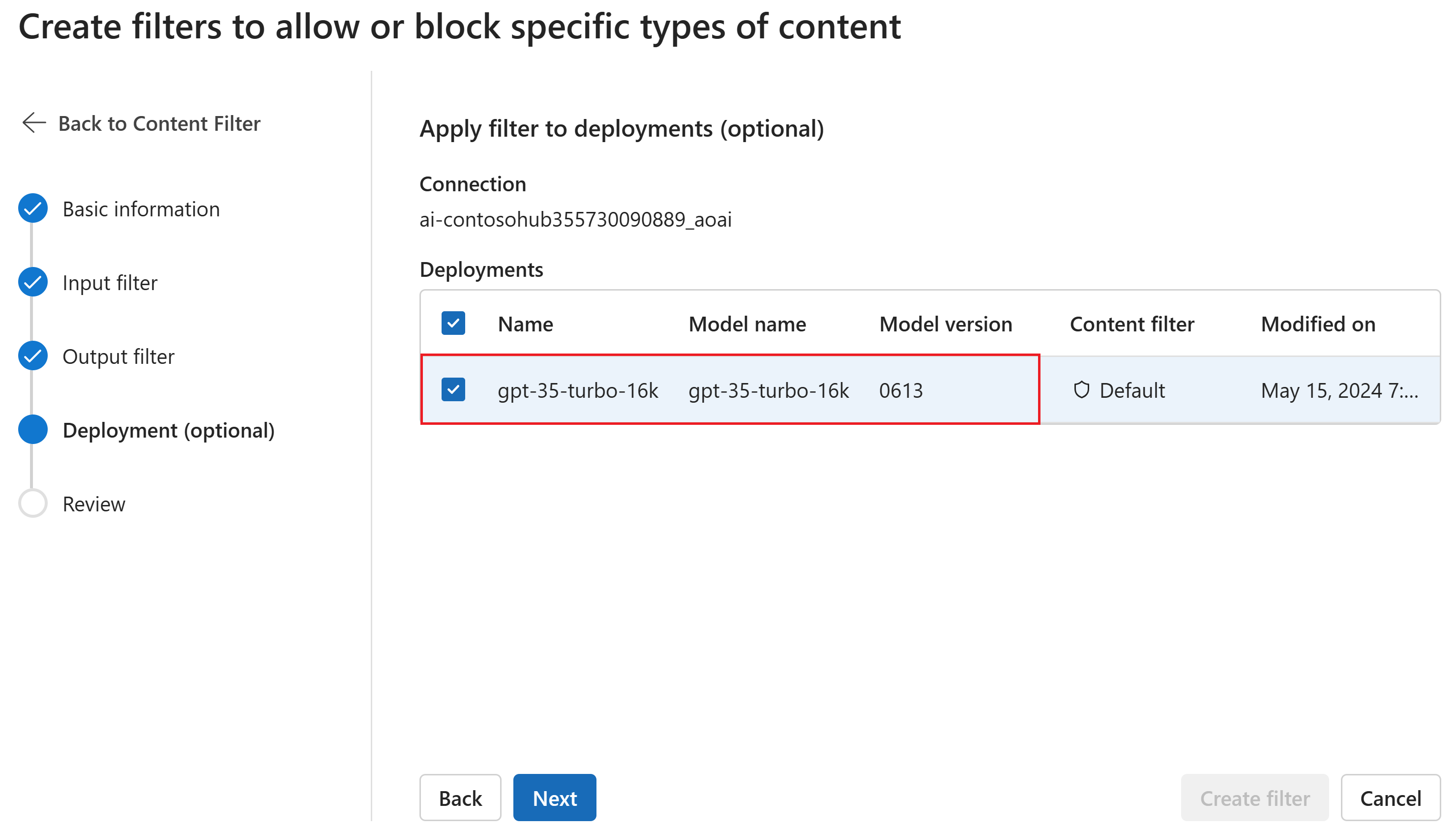
Optionally, on the Deployment page, you can associate the content filter with a deployment. If a selected deployment already has a filter attached, you must confirm that you want to replace it. You can also associate the content filter with a deployment later. Select Create.
Content filtering configurations are created at the hub level in the Azure AI Foundry portal. Learn more about configurability in the Azure OpenAI Service documentation.
On the Review page, review the settings and then select Create filter.



Use a blocklist as a filter
You can apply a blocklist as either an input or output filter, or both. Enable the Blocklist option on the Input filter and/or Output filter page. Select one or more blocklists from the dropdown, or use the built-in profanity blocklist. You can combine multiple blocklists into the same filter.
Apply a content filter
The filter creation process gives you the option to apply the filter to the deployments you want. You can also change or remove content filters from your deployments at any time.
Follow these steps to apply a content filter to a deployment:
Go to Azure AI Foundry and select a project.
Select Models + endpoints on the left pane and choose one of your deployments, then select Edit.

In the Update deployment window, select the content filter you want to apply to the deployment. Then select Save and close.

You can also edit and delete a content filter configuration if required. Before you delete a content filtering configuration, you will need to unassign and replace it from any deployment in the Deployments tab.


Now, you can go to the playground to test whether the content filter works as expected.
Tip
You can also create and update content filters using the REST APIs. For more information, see the API reference. Content filters can be configured at the resource level. Once a new configuration is created, it can be associated with one or more deployments. For more information about model deployment, see the resource deployment guide.
Configurability (preview)
The default content filtering configuration for the GPT model series is set to filter at the medium severity threshold for all four content harm categories (hate, violence, sexual, and self-harm) and applies to both prompts (text, multi-modal text/image) and completions (text). This means that content that is detected at severity level medium or high is filtered, while content detected at severity level low isn't filtered by the content filters. For DALL-E, the default severity threshold is set to low for both prompts (text) and completions (images), so content detected at severity levels low, medium, or high is filtered.
The configurability feature allows customers to adjust the settings, separately for prompts and completions, to filter content for each content category at different severity levels as described in the table below:
| Severity filtered | Configurable for prompts | Configurable for completions | Descriptions |
|---|---|---|---|
| Low, medium, high | Yes | Yes | Strictest filtering configuration. Content detected at severity levels low, medium and high is filtered. |
| Medium, high | Yes | Yes | Content detected at severity level low isn't filtered, content at medium and high is filtered. |
| High | Yes | Yes | Content detected at severity levels low and medium isn't filtered. Only content at severity level high is filtered. Requires approval1. |
| No filters | If approved1 | If approved1 | No content is filtered regardless of severity level detected. Requires approval1. |
1 For Azure OpenAI models, only customers who have been approved for modified content filtering have full content filtering control, including configuring content filters at severity level high only or turning off content filters. Apply for modified content filters via these forms: Azure OpenAI Limited Access Review: Modified Content Filters, and Modified Abuse Monitoring.
Customers are responsible for ensuring that applications integrating Azure OpenAI comply with the Code of Conduct.
Next steps
- Learn more about the underlying models that power Azure OpenAI.
- Azure AI Foundry content filtering is powered by Azure AI Content Safety.
- Learn more about understanding and mitigating risks associated with your application: Overview of Responsible AI practices for Azure OpenAI models.
- Learn more about evaluating your generative AI models and AI systems via Azure AI Evaluation.