Azure Data Factory または Synapse Analytics を使用して、Azure Database for PostgreSQL のデータをコピーして変換する
適用対象: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
この記事では、Azure Data Factory および Synapse Analytics パイプラインの Copy アクティビティを使用して、Azure Database for PostgreSQL との間でデータをコピーする方法、および Data Flow を使用して Azure Database for PostgreSQL のデータを変換する方法について説明します。 詳細については、Azure Data Factory および Azure Synapse Analytics の概要記事を参照してください。
このコネクタは、Azure Database for PostgreSQL サービス用に特化しています。 オンプレミスまたはクラウドにある汎用 PostgreSQL データベースからデータをコピーするには、PostgreSQL コネクタを使用します。
サポートされる機能
この Azure Database for PostgreSQL コネクタは、以下の機能でサポートされています。
| サポートされる機能 | IR | マネージド プライベート エンドポイント |
|---|---|---|
| Copy アクティビティ (ソース/シンク) | ① ② | ✓ |
| マッピング データ フロー (ソース/シンク) | ① | ✓ |
| Lookup アクティビティ | ① ② | ✓ |
① Azure 統合ランタイム ② セルフホステッド統合ランタイム
3 つのアクティビティは、すべての Azure Database for PostgreSQL デプロイ オプションで機能します。
作業の開始
パイプラインでコピー アクティビティを実行するには、次のいずれかのツールまたは SDK を使用します。
UI を使用して Azure Database for PostgreSQL へのリンク サービスを作成する
次の手順を使用して、Azure portal UI で Azure database for PostgreSQL のリンク サービスを作成します。
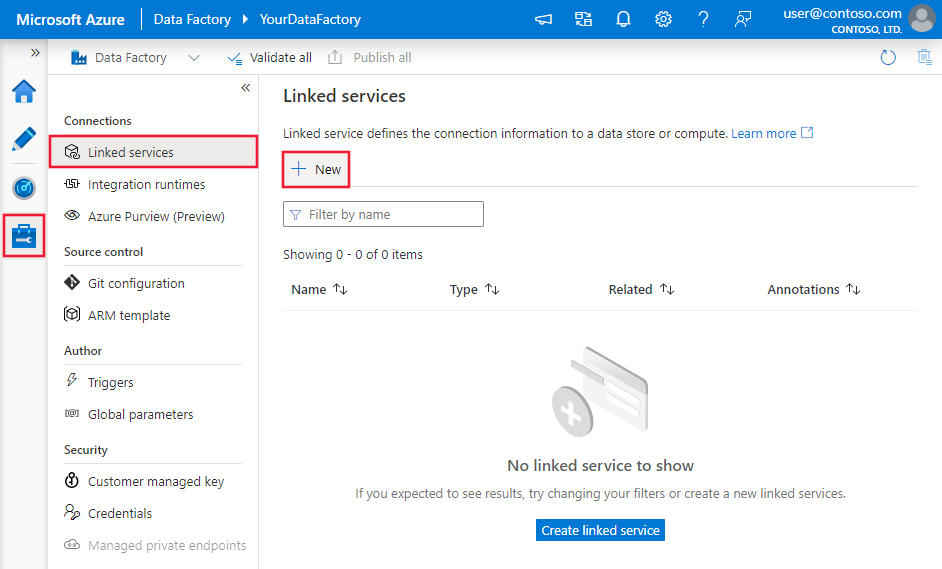
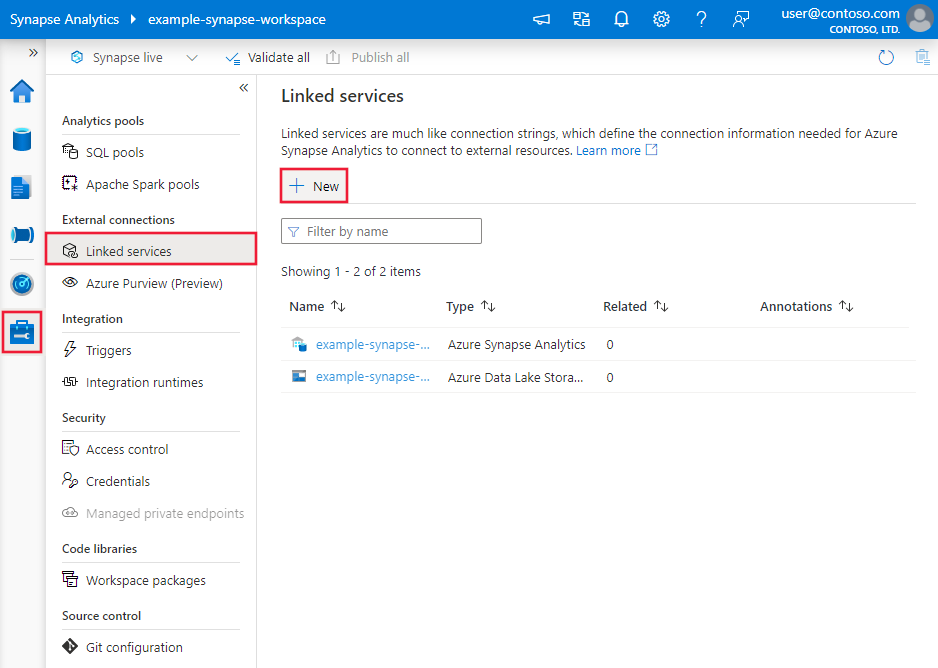
Azure Data Factory または Synapse ワークスペースの [管理] タブに移動し、[リンク サービス] を選択して、[新規] をクリックします。
PostgreSQL を検索し、Azure database for PostgreSQL コネクタを選択します。
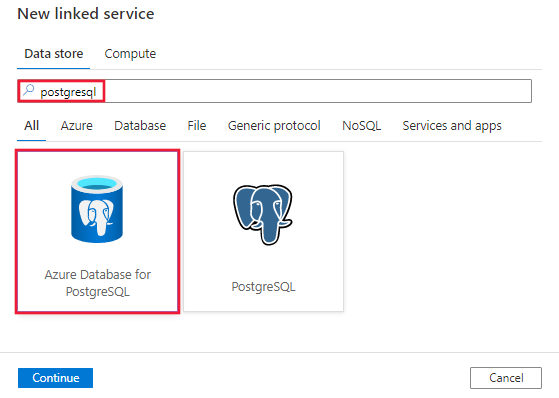
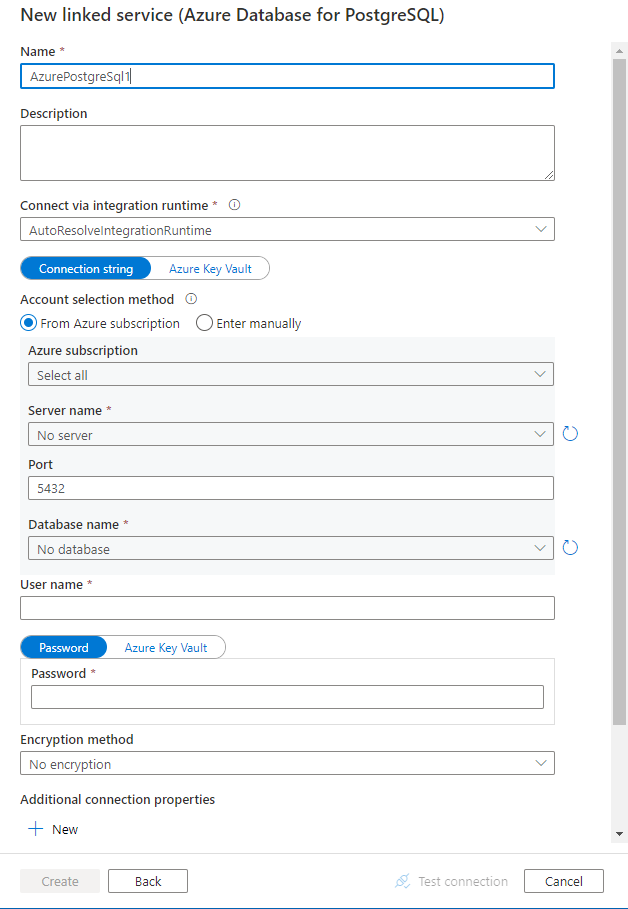
サービスの詳細を構成し、接続をテストして、新しいリンク サービスを作成します。
コネクタの構成の詳細
以下のセクションでは、Azure Database for PostgreSQL コネクタに固有の Data Factory エンティティの定義に使用されるプロパティについて詳しく説明します。
リンクされたサービスのプロパティ
Azure Database for PostgreSQL のリンクされたサービスでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | type プロパティは、次のように設定する必要があります:AzurePostgreSql | はい |
| connectionString | Azure Database for PostgreSQL に接続するための ODBC 接続文字列。 パスワードを Azure Key Vault に格納して、接続文字列から password 構成をプルすることもできます。 詳細については、下記の例と、「Azure Key Vault への資格情報の格納」を参照してください。 |
はい |
| connectVia | このプロパティは、データ ストアに接続するために使用される統合ランタイムを表します。 Azure 統合ランタイムまたは自己ホスト型統合ランタイム (データ ストアがプライベート ネットワークにある場合) を使用できます。 指定されていない場合は、既定の Azure 統合ランタイムが使用されます。 | いいえ |
一般的な接続文字列は Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password> です。 ケースごとにさらに多くのプロパティを設定できます。それらのプロパティを次に示します。
| プロパティ | 説明 | Options | 必須 |
|---|---|---|---|
| EncryptionMethod (EM) | ドライバーとデータベース サーバー間で送信されるデータを暗号化するためにドライバーが使用するメソッド。 たとえば、EncryptionMethod=<0/1/6>; |
0 (暗号化なし) (既定) /1 (SSL)/6 (RequestSSL) | いいえ |
| ValidateServerCertificate (VSC) | SSL 暗号化が有効 (Encryption Method=1) になっているときに、データベース サーバーによって送信される証明書をドライバーが検証するかどうかを決定します。 たとえば、ValidateServerCertificate=<0/1>; |
0 (無効) (既定) / 1 (有効) | いいえ |
例:
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;Password=<Password>"
}
}
}
例:
Azure Key Vault にパスワードを格納する
{
"name": "AzurePostgreSqlLinkedService",
"properties": {
"type": "AzurePostgreSql",
"typeProperties": {
"connectionString": "Server=<server>.postgres.database.azure.com;Database=<database>;Port=<port>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
}
}
}
データセットのプロパティ
データセットの定義に使用できるセクションとプロパティの一覧については、データセットに関する記事をご覧ください。 このセクションでは、Azure Database for PostgreSQL がデータセットでサポートするプロパティの一覧を示します。
Azure Database for PostgreSQL からデータをコピーするには、データセットの type プロパティを AzurePostgreSqlTable に設定します。 次のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | データセットの type プロパティは、AzurePostgreSqlTable に設定する必要があります | はい |
| tableName | テーブルの名前 | いいえ (アクティビティ ソースの "query" が指定されている場合) |
例:
{
"name": "AzurePostgreSqlDataset",
"properties": {
"type": "AzurePostgreSqlTable",
"linkedServiceName": {
"referenceName": "<AzurePostgreSql linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {}
}
}
コピー アクティビティのプロパティ
アクティビティの定義に利用できるセクションとプロパティの完全な一覧については、パイプラインおよびアクティビティに関するページを参照してください。 このセクションでは、Azure Database for PostgreSQL ソースでサポートされるプロパティの一覧を示します。
ソースとしての Azure Database for PostgreSql
Azure Database for PostgreSQL からデータをコピーするには、コピー アクティビティのソースの種類を AzurePostgreSqlSource に設定します。 コピー アクティビティの source セクションでは、次のプロパティがサポートされます。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのソースの type プロパティは AzurePostgreSqlSource に設定する必要があります | はい |
| query | カスタム SQL クエリを使用してデータを読み取ります。 たとえば、SELECT * FROM mytable や SELECT * FROM "MyTable" などです。 PostgreSQL では、エンティティ名が引用符で囲まれていない場合、大文字と小文字が区別されません。 |
いいえ (データセットの tableName プロパティが指定されている場合) |
| queryTimeout | コマンド実行の試行を終了してエラーを生成するまでの待機時間。既定値は 120 分です。 このプロパティにパラメーターを設定する場合、使用できる値は "02:00:00" (120 分) などの期間です。 詳細については、「CommandTimeout」を参照してください。 | いいえ |
| partitionOptions | Azure SQL Database からのデータの読み込みに使用されるデータ パーティション分割オプションを指定します。 使用できる値は、以下のとおりです。None (既定値)、PhysicalPartitionsOfTable、および DynamicRange。 パーティション オプションが有効になっている場合 (つまり、 None ではない場合)、Azure SQL Database から同時にデータを読み込む並列処理の次数は、コピー アクティビティの parallelCopies の設定によって制御されます。 |
いいえ |
| partitionSettings | データ パーティション分割の設定のグループを指定します。 パーティション オプションが None でない場合に適用されます。 |
いいえ |
partitionSettings の下: |
||
| partitionNames | コピーする必要がある物理パーティションのリスト。 パーティション オプションが PhysicalPartitionsOfTable である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfTabularPartitionName をフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionColumnName | 並列コピーの範囲パーティション分割で使用される整数型または日付/日時型 (int、smallint、bigint、date、timestamp without time zone、timestamp with time zone または time without time zone) のソース列の名前を指定します。 指定されていない場合は、テーブルの主キーが自動検出され、パーティション列として使用されます。パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionColumnName をフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionUpperBound | データをコピーするパーティション列の最大値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionUpbound をフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 |
いいえ |
| partitionLowerBound | データをコピーするパーティション列の最小値。 パーティション オプションが DynamicRange である場合に適用されます。 クエリを使用してソース データを取得する場合は、WHERE 句で ?AdfRangePartitionLowbound をフックします。 例については、「Azure Database for PostgreSQL からの並列コピー」セクションを参照してください。 |
いいえ |
例:
"activities":[
{
"name": "CopyFromAzurePostgreSql",
"type": "Copy",
"inputs": [
{
"referenceName": "<AzurePostgreSql input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzurePostgreSqlSource",
"query": "<custom query e.g. SELECT * FROM mytable>",
"queryTimeout": "00:10:00"
},
"sink": {
"type": "<sink type>"
}
}
}
]
シンクとしての Azure Database for PostgreSQL
データを Azure Database for PostgreSQL にコピーするために、コピー アクティビティの sink セクションでは以下のプロパティがサポートされています。
| プロパティ | 内容 | 必須 |
|---|---|---|
| type | コピー アクティビティのシンクの type プロパティは AzurePostgreSQLSink に設定する必要があります | はい |
| preCopyScript | コピー アクティビティの毎回の実行で、データを Azure Database for PostgreSQL に書き込む前に実行する SQL クエリを指定します。 このプロパティを使用して、事前に読み込まれたデータをクリーンアップできます。 | いいえ |
| writeMethod | Azure Database for PostgreSQL にデータを書き込むために使用するメソッド。 使用できる値は、CopyCommand (規定値で、パフォーマンスがより高い)、BulkInsert です。 |
いいえ |
| writeBatchSize | バッチごとに Azure Database for PostgreSQL に読み込まれる行の数。 許可される値は行数を表す整数です。 |
いいえ (既定値は 1,000,000) |
| writeBatchTimeout | タイムアウトする前に一括挿入操作の完了を待つ時間です。 Timespan 文字列を値として使用できます。 たとえば "00:30:00" (30 分) を指定できます。 |
いいえ (既定値は 00:30:00) |
例:
"activities":[
{
"name": "CopyToAzureDatabaseForPostgreSQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure PostgreSQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzurePostgreSQLSink",
"preCopyScript": "<custom SQL script>",
"writeMethod": "CopyCommand",
"writeBatchSize": 1000000
}
}
}
]
Azure Database for PostgreSQL からの並列コピー
Azure Database for PostgreSQL コネクタでは、Copy アクティビティの際に、データを並列でコピーするための組み込みのデータ パーティション分割が提供されます。 データ パーティション分割オプションは、コピー アクティビティの [ソース] タブにあります。
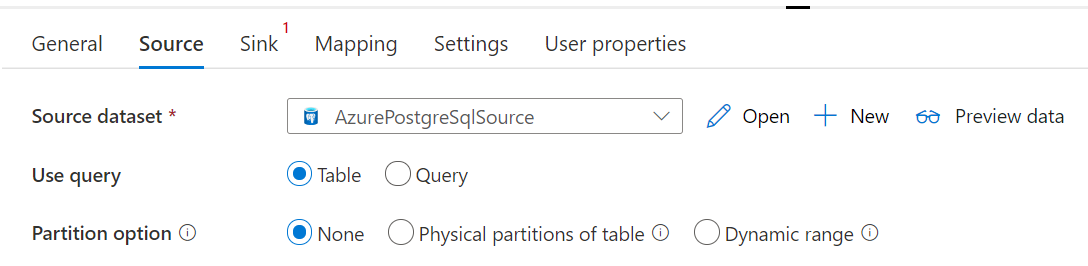
パーティション分割されるコピーを有効にすると、Copy アクティビティによって Azure Database for PostgreSQL ソースに対する並列クエリが実行され、パーティションごとにデータが読み込まれます。 並列度は、コピー アクティビティの parallelCopies 設定によって制御されます。 たとえば、parallelCopies を 4 に設定した場合、指定したパーティション オプションと設定に基づいて 4 つのクエリが同時に生成され、実行されます。各クエリでは、Azure Database for PostgreSQL からデータの一部を取得します。
Azure Database for PostgreSQL から大量のデータを読み込む場合は特に、データ パーティション分割を行う並列コピーを有効にすることが推奨されます。 さまざまなシナリオの推奨構成を以下に示します。 ファイルベースのデータ ストアにデータをコピーする場合は、複数のファイルとしてフォルダーに書き込む (フォルダー名のみを指定する) ことをお勧めします。この場合、1 つのファイルに書き込むよりもパフォーマンスが優れています。
| シナリオ | 推奨設定 |
|---|---|
| 物理パーティションに分割された大きなテーブル全体から読み込む。 |
パーティション オプション: テーブルの物理パーティション。 実行中に、サービスによって物理パーティションが自動的に検出され、パーティションごとにデータがコピーされます。 |
| 物理パーティションがなく、データ パーティション分割用の整数列がある大きなテーブル全体から読み込む。 |
パーティション オプション: 動的範囲パーティション。 パーティション列: データのパーティション分割に使用される列を指定します。 指定されていない場合は、主キー列が使用されます。 |
| カスタム クエリを使用して大量のデータを読み込む (物理パーティションがある場合)。 |
パーティション オプション: テーブルの物理パーティション。 クエリ: SELECT * FROM ?AdfTabularPartitionName WHERE <your_additional_where_clause>パーティション名: データのコピー元のパーティション名を指定します。 指定されていない場合は、PostgreSQL データセットで指定したテーブルの物理パーティションがサービスによって自動検出されます。 実行中に、サービスによって ?AdfTabularPartitionName が実際のパーティション名に置き換えられ、Azure Database for PostgreSQL に送信されます。 |
| カスタム クエリを使用して大量のデータを読み込む (物理パーティションがなく、データ パーティション分割用の整数列がある場合)。 |
パーティション オプション: 動的範囲パーティション。 クエリ: SELECT * FROM ?AdfTabularPartitionName WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>パーティション列: データのパーティション分割に使用される列を指定します。 整数データ型または date/datetime データ型の列に対してパーティション分割を実行できます。 パーティションの上限とパーティションの下限: パーティション列に対してフィルター処理を実行して、下限から上限までの範囲内のデータのみを取得する場合に指定します。 実行中に、 ?AdfRangePartitionColumnName、?AdfRangePartitionUpbound、?AdfRangePartitionLowbound が各パーティションの実際の列名と値の範囲に置き換えられ、Azure Database for PostgreSQL に送信されます。 たとえば、パーティション列 "ID" で下限が 1、上限が 80 に設定され、並列コピーが 4 に設定されている場合、サービスは 4 つのパーティションでデータを取得します。 これらの ID の範囲はそれぞれ [1, 20]、[21, 40]、[41, 60]、[61, 80] です。 |
パーティション オプションを使用してデータを読み込む場合のベスト プラクティス:
- データ スキューを回避するため、パーティション列 (主キーや一意キーなど) には特徴のある列を選択します。
- テーブルに組み込みパーティションがある場合は、パフォーマンスを向上させるためにパーティション オプションとして "テーブルの物理パーティション" を使用します。
- Azure Integration Runtime を使用してデータをコピーする場合は、より大きな (4 より大きい) "データ統合単位 (DIU)" (>4) を設定すると、より多くのコンピューティング リソースを利用できます。 そこで、該当するシナリオを確認してください。
- パーティション数は、"コピーの並列処理の次数" によって制御されます。この数値を大きくしすぎるとパフォーマンスが低下するため、この数値は、(DIU またはセルフホステッド IR ノードの数) x (2 から 4) に設定することをお勧めします。
例: 複数の物理パーティションがある大きなテーブル全体から読み込む
"source": {
"type": "AzurePostgreSqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
例: 動的範囲パーティションを使用してクエリを実行する
"source": {
"type": "AzurePostgreSqlSource",
"query": "SELECT * FROM <TableName> WHERE ?AdfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Mapping Data Flow のプロパティ
マッピング データ フローでデータを変換する場合、Azure Database for PostgreSQL からテーブルの読み取りと書き込みを実行できます。 詳細については、マッピング データ フローのソース変換とシンク変換に関する記事をご覧ください。 ソースとシンクの種類として、Azure Database for PostgreSQL データセットまたはインライン データセットを使用することができます。
ソース変換
次の表に、Azure Database for PostgreSQL ソースでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [ソース オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| テーブル | [テーブル] を入力として選択した場合、データセットで指定されたテーブルからすべてのデータがデータ フローによってフェッチされます。 | いいえ | - |
(インライン データセットのみ) tableName |
| クエリ | [クエリ] を入力として選択した場合は、ソースからデータをフェッチする SQL クエリを指定します。これにより、データセットで指定したテーブルがオーバーライドされます。 テストまたはルックアップ対象の行を減らすうえで、クエリの使用は有効な手段です。 Order By 句はサポートされていませんが、完全な SELECT FROM ステートメントを設定することができます。 ユーザー定義のテーブル関数を使用することもできます。 select * from udfGetData() は、データ フローで使用できるテーブルを返す SQL の UDF です。 クエリ例: select * from mytable where customerId > 1000 and customerId < 2000 または select * from "MyTable"。 PostgreSQL では、エンティティ名が引用符で囲まれていない場合、大文字と小文字が区別されません。 |
いいえ | String | query |
| スキーマ名 | 入力としてストアド プロシージャを選択する場合、ストアド プロシージャのスキーマを指定するか、[更新] を選択し、スキーマ名を検出するようにサービスに要求します。 | いいえ | String | schemaName |
| ストアド プロシージャ | 入力として [ストアド プロシージャ] を選択する場合、ソース テーブルからデータを読み込むストアド プロシージャの名前を指定するか、[更新] を選択し、プロシージャ名を検出するようにサービスに要求します。 | はい ([ストアド プロシージャ] を入力として選択した場合) | String | procedureName |
| プロシージャのパラメーター | 入力として [ストアド プロシージャ] を選択した場合、プロシージャで設定された順序でストアド プロシージャの入力パラメーターを指定するか、[インポート] を選択し、フォーム @paraName を使用してすべてのプロシージャ パラメーターをインポートします。 |
いいえ | Array | inputs |
| バッチ サイズ | 大量データをバッチにまとめるバッチ サイズを指定します。 | いいえ | Integer | batchSize |
| Isolation Level | 次のいずれかの分離レベルを選択します。 - コミットされたものを読み取り - コミットされていないものを読み取り (既定値) - 反復可能読み取り - シリアル化可能 - なし (分離レベルを無視) |
いいえ | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE NONE |
isolationLevel |
Azure Database for PostgreSQL ソース スクリプトの例
ソースの種類として Azure Database for PostgreSQL を使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzurePostgreSQLSource
シンク変換
次の表に、Azure Database for PostgreSQL シンクでサポートされるプロパティの一覧を示します。 これらのプロパティは、 [シンク オプション] タブで編集できます。
| 名前 | 説明 | 必須 | 使用できる値 | データ フロー スクリプトのプロパティ |
|---|---|---|---|---|
| 更新方法 | 対象となるデータベースに対して許可される操作を指定します。 既定では、挿入のみが許可されます。 行を更新、アップサート、または削除するには、それらのアクションに対して行をタグ付けするために行の変更変換が必要になります。 |
はい |
true または false |
deletable insertable updateable upsertable |
| [キー列] | 更新、upsert、削除の場合、キー列 (複数可) を設定して、変更する行を決定する必要があります。 キーとして選択する列の名前は、後続の更新、upsert、削除の一部として使用されます。 そのため、シンク マッピングに存在する列を選択する必要があります。 |
いいえ | Array | キー |
| Skip writing key columns\(キー列の書き込みをスキップする) | キー列に値を書き込まない場合は、[Skip writing key columns](キー列の書き込みをスキップする) を選択します。 | いいえ |
true または false |
skipKeyWrites |
| テーブル アクション | 書き込み前に変換先テーブルのすべての行を再作成するか削除するかを指定します。 - なし: テーブルに対してアクションは実行されません。 - Recreate:テーブルが削除され、再作成されます。 新しいテーブルを動的に作成する場合に必要です。 - Truncate:ターゲット テーブルのすべての行が削除されます。 |
いいえ |
true または false |
recreate truncate |
| バッチ サイズ | 各バッチで書き込まれる行の数を指定します。 バッチ サイズを大きくすると、圧縮とメモリの最適化が向上しますが、データをキャッシュする際にメモリ不足の例外が発生するリスクがあります。 | いいえ | Integer | batchSize |
| ユーザー DB スキーマの選択 | 既定では、シンク スキーマの下にステージングとして一時テーブルが作成されます。 または、[シンク スキーマを使用する] オプションをオフにして、Data Factory でステージング テーブルを作成してアップストリーム データを読み込み、完了時に自動的にクリーンアップするスキーマ名を指定することもできます。 データベースにテーブルの作成権限があり、スキーマに対する変更権限があることを確認します。 | いいえ | String | stagingSchemaName |
| 事前および事後の SQL スクリプト | データがシンク データベースに書き込まれる前 (前処理) と書き込まれた後 (後処理) に実行される複数行の SQL スクリプトを指定します。 | いいえ | String | preSQLs postSQLs |
ヒント
- 複数のコマンドを含む単一のバッチ スクリプトを複数のバッチに分割することをお勧めします。
- バッチの一部として実行できるのは、単純に更新数を返すデータ操作言語 (DML) ステートメントおよびデータ定義言語 (DDL) ステートメントだけです。 詳細については、「バッチ操作の実行」を参照してください。
増分抽出を有効にする: このオプションを使用して、パイプラインが最後に実行されてから変更された行のみを処理するように ADF に指示します。
増分日付列: 増分抽出機能を使う場合は、ソース テーブルのウォーターマークとして使う日時列を選ぶ必要があります。
最初から読み取りを開始する: 増分抽出でこのオプションを設定すると、増分抽出が有効になっているパイプラインの最初の実行時にすべての行を読み取るよう ADF に指示します。
Azure Database for PostgreSQL シンク スクリプトの例
シンクの種類として Azure Database for PostgreSQL を使用する場合、関連付けられているデータ フロー スクリプトは次のようになります。
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzurePostgreSQLSink
Lookup アクティビティのプロパティ
プロパティの詳細については、ルックアップ アクティビティに関する記事を参照してください。
関連するコンテンツ
コピー アクティビティによってソース、シンクとしてサポートされるデータ ストアの一覧については、サポートされるデータ ストアに関するセクションを参照してください。