Azure Data Factory の統合ランタイム
適用対象:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
ヒント
企業向けのオールインワン分析ソリューション、Microsoft Fabric の Data Factory をお試しください。 Microsoft Fabric は、データ移動からデータ サイエンス、リアルタイム分析、ビジネス インテリジェンス、レポートまで、あらゆるものをカバーしています。 無料で新しい試用版を開始する方法について説明します。
Integration Runtime (IR) は、異なるネットワーク環境間でデータ統合機能を提供するために Azure Data Factory と Azure Synapse のパイプラインによって使用されるコンピューティング インフラストラクチャです。
- データ フロー: マネージド Azure コンピューティング環境でデータ フローを実行します。
- データの移動: パブリックネットワークまたはプライベートネットワーク内のデータストア間でデータをコピーします (オンプレミスネットワークと仮想プライベートネットワークの両方)。 このサービスは、組み込みコネクタ、形式の変換、列のマッピング、パフォーマンスとスケーラビリティに優れたデータ転送に関するサポートを提供します。
- アクティビティのディスパッチ: Azure Databricks、Azure HDInsight、ML スタジオ (クラシック)、Azure SQL Database、SQL Server などのさまざまなコンピューティング サービスで実行される変換アクティビティをディスパッチして監視します。
- SSIS パッケージの実行:マネージド Azure コンピューティング環境で SQL Server Integration Services (SSIS) パッケージをネイティブに実行します。
Data Factory と Synapse のパイプラインでは、実行されるアクションをアクティビティで定義します。 リンクされたサービスは、ターゲットのデータ ストアやコンピューティング サービスを定義します。 統合ランタイムは、アクティビティとリンクされたサービスとを橋渡しします。 リンクされたサービスまたはアクティビティによって参照され、アクティビティが直接実行されたり、ディスパッチされたりするコンピューティング環境を提供します。 これにより、対象のデータストアまたはコンピューティングサービスに対して最も近いリージョンでアクティビティを実行し、パフォーマンスを最大化しながら、セキュリティとコンプライアンスの要件を柔軟に満たすことができます。
統合ランタイムは、Azure Data Factory と Azure Synapse の UI で、管理ハブから直接、およびそれらを参照するすべてのアクティビティ、データセット、データ フローから使用して作成できます。
統合ランタイムの種類
Data Factory には 3 種類の統合ランタイム (IR) が用意されているので、ご使用のデータ統合機能やネットワーク環境に最もかなっている種類を選択する必要があります。 IR の 3 種類は次のとおりです。
- Azure
- セルフホステッド
- Azure-SSIS
注意
Synapse パイプラインは、現在 Azure またはセルフホステッド統合ランタイムのみに対応しています。
次の表で、各種の統合ランタイムの機能とネットワークのサポートについて説明します。
| IR の種類 | パブリック ネットワークのサポート | Private Link のサポート |
|---|---|---|
| Azure | Data Flow データの移動 アクティビティのディスパッチ |
Data Flow データの移動 アクティビティのディスパッチ |
| セルフホステッド | データの移動 アクティビティのディスパッチ |
データの移動 アクティビティのディスパッチ |
| Azure-SSIS | SSIS パッケージ実行 | SSIS パッケージ実行 |
注意
Azure IR の送信制御は、サービスによって異なります。 Synapse では、Azure IR を利用するときにマネージド仮想ネットワークからの送信トラフィックを制限するオプションがワークスペースに用意されています。 Data Factory では、Azure IR を利用するときにすべてのポートが送信方向の通信用に開かれています。 Azure-SSIS IR を vNET と統合して、送信方向の通信制御を提供できます。
Azure 統合ランタイム
Azure Integration Runtime では以下が可能です。
- Azure でデータ フローを実行する
- クラウドのデータ ストア間でコピー アクティビティを実行する
- パブリック ネットワークで次の変換アクティビティをディスパッチする:
- .NET カスタム アクティビティ
- Azure Functions アクティビティ
- Databricks Notebook/Jar/Python アクティビティ
- Data Lake Analytics U-SQL アクティビティ
- GetMetadata アクティビティ
- HDInsight Hive アクティビティ
- HDInsight Pig アクティビティ
- HDInsight MapReduce アクティビティ
- HDInsight Spark アクティビティ
- HDInsight Streaming アクティビティ
- Lookup アクティビティ
- Machine Learning Studio (クラシック) の Batch Execution アクティビティ
- Machine Learning Studio (クラシック) のリソースの更新アクティビティ
- Stored Procedure アクティビティ
- Validation アクティビティ
- Web アクティビティ
Azure IR のネットワーク環境
Azure Integration Runtime では、だれでもアクセス可能なエンドポイントを使用して、データ ストアやコンピューティング サービスへの接続がサポートされます。 マネージド仮想ネットワークを有効にすると、Azure Integration Runtime では、プライベート ネットワーク環境でプライベート リンク サービスを使用したデータ ストアへの接続がサポートされます。 Synapse では、ワークスペースには、IR マネージド仮想ネットワークからの送信トラフィックを制限するオプションがあります。 Data Factory では、すべてのポートが送信方向の通信用に開かれています。 Azure-SSIS IR は vNET と統合して送信方向の通信制御を提供できます。
Azure IR のコンピューティング リソースとスケーリング
Azure 統合ランタイムは、Azure 内のフル マネージドのサーバーレス コンピューティングを提供します。 インフラストラクチャのプロビジョニング、ソフトウェアのインストール、修正プログラムの適用、容量のスケーリングについて心配する必要はありません。 さらに、実際の使用時間分だけのお支払いになります。
Azure 統合ランタイムは、ネイティブのコンピューティングを備えており、セキュリティで保護された、信頼性とパフォーマンスの高い方法で、クラウドのデータ ストア間でデータを移動します。 コピー アクティビティで使用するデータの統合単位の数を設定できます。Azure IR のコンピューティング サイズはそれに応じて柔軟にスケール アップし、Azure 統合ランタイムのサイズを明示的に調整する必要はありません。
アクティビティのディスパッチは、アクティビティをターゲット コンピューティング サービスにルーティングする負荷の低い操作であるため、このシナリオのためにコンピューティング サイズをスケールアップする必要はありません。
Azure IR の作成と構成に関する詳細については、「Azure 統合ランタイムを作成して構成する方法」を参照してください。
注意
Azure Integration Runtime には、データ フローを実行するための基盤となるコンピューティング インフラストラクチャを定義する、Data Flow ランタイムに関連するプロパティがあります。
セルフホステッド統合ランタイム
セルフホステッド IR により、次のことが可能になります。
- クラウドのデータ ストアとプライベート ネットワーク内のデータ ストアの間でコピー アクティビティを実行する。
- オンプレミスまたは Azure Virtual Network 内のコンピューティング リソースに対して次の変換アクティビティをディスパッチする:
- Azure Functions アクティビティ
- カスタム アクティビティ (Azure Batch で実行)
- Data Lake Analytics U-SQL アクティビティ
- GetMetadata アクティビティ
- HDInsight Hive アクティビティ (BYOC - 自分のクラスターを利用)
- HDInsight Pig アクティビティ (BYOC)
- HDInsight MapReduce アクティビティ (BYOC)
- HDInsight Spark アクティビティ (BYOC)
- HDInsight Streaming アクティビティ (BYOC)
- Lookup アクティビティ
- Machine Learning Studio (クラシック) の Batch Execution アクティビティ
- Machine Learning Studio (クラシック) のリソースの更新アクティビティ
- Machine Learning の Execute Pipeline アクティビティ
- Stored Procedure アクティビティ
- Validation アクティビティ
- Web アクティビティ
Note
SAP Hana や MySQL などの独自ドライバーを必要とするデータ ストアをサポートするには、セルフホステッド統合ランタイムを使用します。詳細については、「サポートされるデータ ストア」を参照してください。
注意
Java Runtime Environment (JRE) は、セルフホステッド IR の依存関係です。 JRE が同じホストにインストールされていることを確認してください。
セルフホステッド IR のネットワーク環境
パブリック クラウド環境からの直接の通信経路がないプライベート ネットワーク環境で、安全にデータ統合を実行しようとしている場合は、ファイアウォール内のオンプレミス環境か仮想プライベート ネットワーク内にセルフホステッド IR をインストールできます。 セルフホステッド統合ランタイムは、インターネットへの送信 HTTP ベースの接続のみを行います。
セルフホステッド IR のコンピューティング リソースとスケーリング
セルフホステッド IR は、オンプレミスのマシンか、プライベート ネットワーク内の仮想マシンにインストールします。 現在、セルフホステッド IR は、Windows オペレーティングシステムでのみサポートされています。
高可用性とスケーラビリティを実現するには、アクティブ/アクティブ モードで論理インスタンスをオンプレミスの複数のマシンに関連付けて、セルフホステッド IR をスケールアウトできます。 詳細については、セルフホステッド IR を作成および構成する方法に関する記事をご覧ください。
Azure-SSIS 統合ランタイム
既存の SSIS ワークロードをリフトアンドシフトするには、Azure-SSIS IR を作成して SSIS パッケージをネイティブに実行できます。
Azure-SSIS IR のネットワーク環境
Azure-SSIS IR は、パブリック ネットワークかプライベート ネットワーク内でプロビジョニングできます。 オンプレミスのデータ アクセスは、オンプレミスのネットワークに接続している仮想ネットワークと Azure-SSIS IR を結合することでサポートされます。
Azure-SSIS IR のコンピューティング リソースとスケーリング
Azure-SSIS IR は、SSIS パッケージ実行専用の、Azure VM のフル マネージドのクラスターです。 SSIS プロジェクトまたはパッケージのカタログ (SSISDB) 用に独自の Azure SQL Database または SQL Managed Instance を持ち込むことができます。 ノードのサイズを指定してコンピューティング能力をスケールアップしたり、クラスター内のノードの数を指定してスケール アウトしたりできます。 必要に応じてAzure-SSIS Integration Runtime を停止したり開始したりして、その実行のコストを管理できます。
詳細については、「Azure-SSIS IR を作成して構成する方法」を参照してください。 作成終は、オンプレミスで SSIS を使用する場合と同様に、SQL Server Data Tools (SSDT) や SQL Server Management Studio (SSMS) などの使い慣れたツールを使用して、既存の SSIS パッケージをほとんど変更せずにデプロイして管理することができます。
Azure-SSIS ランタイムの詳細については、次の記事をご覧ください。
- チュートリアル: SSIS パッケージを Azure にデプロイする: この記事は、Azure-SSIS IR を作成し、Azure SQL Database を使用して SSIS カタログをホストするための詳細な手順を示しています。
- 方法: Azure-SSIS 統合ランタイムを作成する。 この記事では、チュートリアルを基に、SQL Managed Instance の使い方と、IR を仮想ネットワークに参加させる方法が説明されています。
- Azure-SSIS IR を監視する: この記事では、Azure-SSIS IR に関する情報を取得する方法と、返された情報での状態が説明されています。
- Azure-SSIS IR を管理する: この記事では、Azure-SSIS IR を停止、開始、削除する方法が説明されています。 また、IR にノードを追加することで Azure-SSIS IR をスケールアウトする方法も説明されています。
- 仮想ネットワークへの Azure-SSIS IR の参加: この記事では、Azure 仮想ネットワークへの Azure-SSIS IR の参加に関する概念情報が説明されています。 また、Azure Portal を使用して、Azure-SSIS IR が仮想ネットワークに参加できるように構成する手順についても説明されています。
統合ランタイムの場所
ファクトリの場所と IR の場所の関係
Data Factory または Synapse ワークスペースのインスタンスを作成する場合は、その場所を指定する必要があります。 このインスタンスのメタデータはここに格納されており、パイプラインのトリガーはここから開始されます。 メタデータは選択したリージョンにのみ格納され、他のリージョンには格納されません。
ただし、パイプラインは、他の Azure リージョン内のデータ ストアやコンピューティング サービスにアクセスし、データ ストア間でデータを移動したり、コンピューティング サービスを使用してデータを処理したりできます。 この動作はグローバルに使用できる IR によって実現し、データのコンプライアンス、効率性、ネットワークのエグレスのコストの削減が保証されます。
IR の場所は、そのバックエンドのコンピューティングの場所を定義するほか、データの移動、アクティビティのディスパッチ、SSIS パッケージの実行が行われる場所を定義します。 IR の場所は、それが属している Data Factory の場所とは別にすることができます。
Azure IR の場所
Azure IR の場所を設定することができます。その場合は、その選択したリージョンでアクティビティの実行やディスパッチが行われます。
デフォルトでは、パブリック ネットワーク内の Azure IR が自動解決されます。 このオプションでは、
コピー アクティビティの場合、可能な限りシンク データ ストアの場所が自動的に検出され、同じリージョン (使用可能な場合) または同じ地理的な場所の最も近いリージョンのどちらかにある IR が使用されるようにします。そうしないと、シンク データ ストアのリージョンを検出できない場合、インスタンスのリージョン内の IR が代わりに使用されます。
たとえば、Data Factory または Synapse ワークスペースが米国東部で作成されたとします。
- 米国西部にある Azure BLOB にデータをコピーするときに、その BLOB が米国西部で検出された場合、そのコピー アクティビティは米国西部にある IR で実行されます。リージョンの検出に失敗した場合、コピー アクティビティは米国東部にある IR で実行されます。
- リージョンを検出できない Salesforce にデータをコピーする場合、コピー アクティビティは米国東部にある IR で実行されます。
ヒント
データ コンプライアンスの要件が厳しく、データが地理的な特定の場所を離れないようにする必要がある場合は、Azure IR を明示的に特定のリージョンに作成し、リンクされたサービスが ConnectVia プロパティを使用してこの IR を指すようにすることができます。 たとえば、データを英国内に留めたまま、英国南部の BLOB から英国南部の Azure Synapse ワークスペースにデータをコピーしたい場合は、英国南部に Azure IR を作成して、両方のリンクされたサービスをこの IR にリンクします。
Lookup/GetMetadata/Delete アクティビティの実行 (パイプライン アクティビティ)、変換アクティビティのディスパッチ (外部アクティビティ)、およびオーサリング操作 (接続のテスト、フォルダー一覧とテーブル一覧の参照、データのプレビュー) の場合、Data Factory または Synapse ワークスペースと同じリージョンにある IR が使用されます。
Data Flow の場合、Data Factory または Synapse ワークスペースのリージョンの IR が使用されます。
ヒント
ベスト プラクティスは、可能であれば、対応するデータ ストアと同じリージョンでデータ フローを実行することです。 これを実現するには、Azure IR の自動解決か (データ ストアの場所が Data Factory または Synapse ワークスペースの場所と同じ場合)、またはデータ ストアと同じリージョンに新しい Azure IR インスタンスを作成し、そこでデータ フローを実行します。
Azure IR の自動解決を使用してマネージド仮想ネットワークを有効にする場合は、Data Factory または Synapse ワークスペースのリージョンにある IR が使用されます。
アクティビティの実行中に有効な IR の場所は、Data Factory Studio または Synapse Studio のパイプライン アクティビティ監視ビュー、またはアクティビティ監視ペイロードで監視できます。
セルフホステッド IR の場所
セルフホステッド IR は Data Factory または Synapse ワークスペースに論理的に登録され、その機能のサポートのために使用するコンピューティングは自分で指定します。 したがって、セルフホステッド IR の明示的な場所のプロパティはありません。
セルフホステッド IR を使用してデータの移動を実行する場合、この IR はデータをソースから抽出して移動先に書き込みます。
Azure-SSIS IR の場所
注意
Azure-SSIS 統合ランタイムは、現在 Synapse パイプラインではサポートされていません。
抽出、変換、読み込み (ETL) ワークフローで高いパフォーマンスを実現するには、Azure-SSIS IR の正しい場所を選択することが重要です。
- Azure-SSIS IR の場所を Data Factory の場所と同じにする必要はありませんが、SSISDB のホストとなる独自の Azure SQL Database または SQL Managed Instance の場所と同じにする必要があります。 こうすると、Azure-SSIS 統合ランタイムから SSISDB に簡単にアクセスでき、複数の場所の間で過剰なトラフィックが生じません。
- 既存の SQL Database または SQL Managed Instance がなく、オンプレミスのデータ ソースまたは移動先がある場合、オンプレミスのネットワークに接続している仮想ネットワークの同じ場所に新しい Azure SQL Database または SQL Managed Instance を作成する必要があります。 これにより、新しい Azure SQL Database または SQL Managed Instance を使用して Azure-SSIS IR を作成し、その仮想ネットワークに参加できます。 すべてが同じ場所に位置すると、データ移動および関連コストを最小限に抑えつつ、パフォーマンスを最大化できます。
- 既存の Azure SQL Database または SQL Managed Instance の場所と、オンプレミスのネットワークに接続している仮想ネットワークの場所が違う場合は、まず、既存の Azure SQL Database または SQL Managed Instance を使用して Azure-SSIS IR を作成し、同じ場所の別の仮想ネットワークを参加させます。 次に、異なる場所に存在する仮想ネットワーク同士の接続を構成します。
次の図は、Data Factory とその統合ランタイムの場所の設定を示しています。
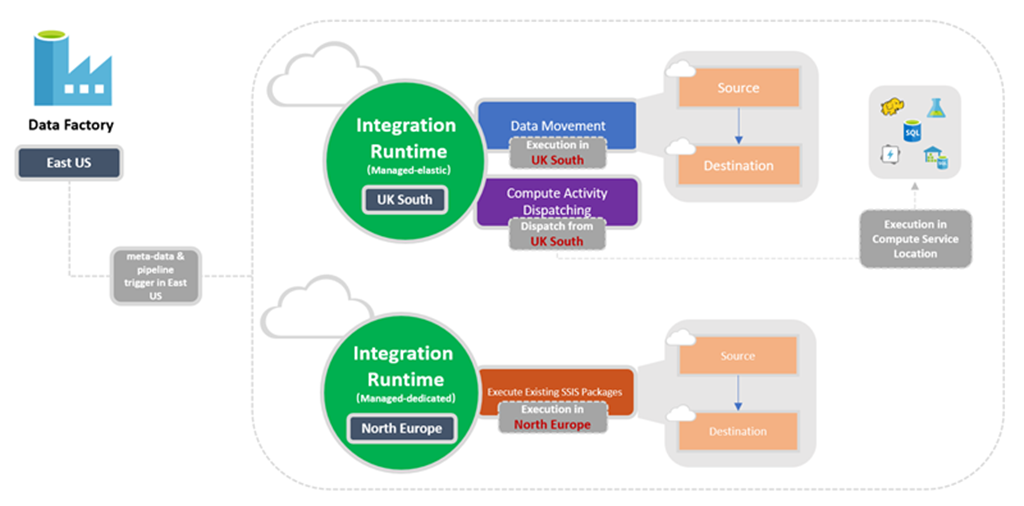
使用する IR の判別
1 つのアクティビティが複数の種類の統合ランタイムに関連付けられる場合は、そのどちらかに解決されます。 セルフホステッド統合ランタイムは、マネージド仮想ネットワークが使用されている Azure Data Factory や Synapse ワークスペースのインスタンス内の Azure 統合ランタイムよりも優先されます。 そして、後者はグローバル Azure 統合ランタイムよりも優先されます。
たとえば、ソースからシンクへのデータのコピーには、1 つのコピー アクティビティが使用されます。 グローバル Azure 統合ランタイムは、ソースにリンクされたサービスに関連付けられています。また、Azure Data Factory マネージド仮想ネットワーク内の Azure 統合ランタイムは、シンクのリンクされたサービスに関連付けられています。このため、ソースとシンクの両方のリンクされたサービスによって、Azure Data Factory マネージド仮想ネットワーク内の Azure 統合ランタイムが使用されます。 ただし、セルフホステッド統合ランタイムが、ソースのリンクされたサービスに関連付けられている場合は、ソースとシンクの両方のリンクされたサービスによって、セルフホステッド統合ランタイムが使用されます。
コピー アクティビティ
コピー アクティビティは、データ フローの方向を定義するのに、ソースとシンクの両方がリンクされたサービスが必要です。 どの統合ランタイム インスタンスを使用してコピーを実行するかを決めるために、次のロジックが使用されます。
- 2 つのクラウド データ ソース間でのコピー: ソースとシンクの両方のリンクされたサービスで Azure IR が使用されているとき、指定されている場合はそのリージョンの Azure IR が使用され、自動解決 IR (既定) オプションが選択されている場合は、「統合ランタイムの場所」セクションで説明したとおり、Azure IR の場所が自動的に決定されます。
- クラウド データ ソースとプライベート ネットワーク内のデータ ソースの間でのコピー: ソースかシンクのいずれかのリンクされたサービスがセルフホステッド IR を指している場合、そのセルフホステッド IR 上でコピー アクティビティが実行されます。
- プライベート ネットワーク内の 2 つのデータ ソース間でのコピー: ソースとシンクの両方のリンクされたサービスが同じ統合ランタイム インスタンスを指す必要があり、その IR を使用してコピー アクティビティが実行されます。
Lookup および GetMetadata アクティビティ
Lookup および GetMetadata アクティビティは、データ ストアのリンクされたサービスに関連付けられている統合ランタイム上で実行されます。
外部変換アクティビティ
外部のコンピューティング エンジンを活用する外部変換アクティビティにはそれぞれ、ターゲット コンピューティングのリンクされたサービスがあり、これは統合ランタイムに向けられています。 この IR インスタンスによって、手動コーディングされたその外部変換アクティビティのディスパッチ元が判断されます。
Data Flow アクティビティ
Data Flow アクティビティは、それに関連付けられている Azure 統合ランタイムで実行されます。 Data Flow で活用される Spark コンピューティングは Azure IR のデータ フロー プロパティによって決定され、サービスによって完全管理されます。
CI/CD での統合ランタイム
統合ランタイムは頻繁には変更されず、CI/CD のすべてのステージで類似しています。 Data Factory、CI/CD のすべてのステージで同じ名前と種類の統合ランタイムを使用する必要があります。 すべてのステージで統合ランタイムを共有する場合は、共有の統合ランタイムを含めるためだけに専用ファクトリを使用することを検討してください。 それにより、この共有ファクトリは、すべての環境で、リンクされた統合ランタイムの種類として使用できます。
関連するコンテンツ
次の記事をご覧ください。
- Azure Integration Runtime の作成
- Create self-hosted integration runtime (セルフホステッド統合ランタイムの作成)
- Azure-SSIS 統合ランタイムを作成します。 この記事では、チュートリアルを基に、SQL Managed Instance の使い方と、IR を仮想ネットワークに参加させる方法が説明されています。