Installare e abilitare Deduplicazione dati
In questo argomento viene descritto come installare Deduplicazione dati, valutare i carichi di lavoro per la deduplicazione e abilitare la deduplicazione dei dati su volumi specifici.
Nota
Se si sta pianificando di eseguire Deduplicazione dati in un cluster di failover, ogni nodo nel cluster deve avere il ruolo del server Deduplicazione dati installato.
Installare la deduplicazione dei dati
Importante
KB4025334 contiene un rollup di correzioni di Deduplicazione dati, incluse correzioni importanti di affidabilità e consigliamo fermamente di installarlo quando si usa Deduplicazione dati con Windows Server 2016.
Installare Deduplicazione dati tramite Server Manager
- In Aggiunta guidata ruoli e funzionalità selezionare Ruoli server e quindi Deduplicazione dati.
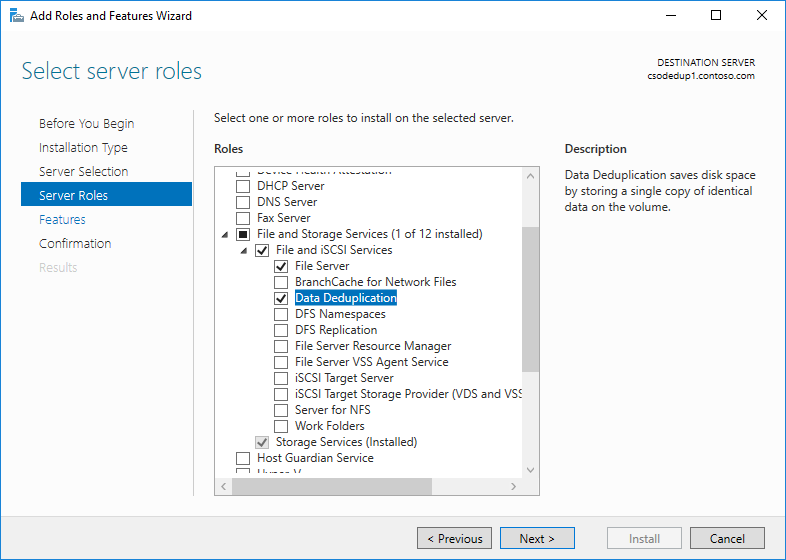
- Fare clic su Avanti fino a quando il pulsante Installa non è attivo e quindi fare clic su Installa.
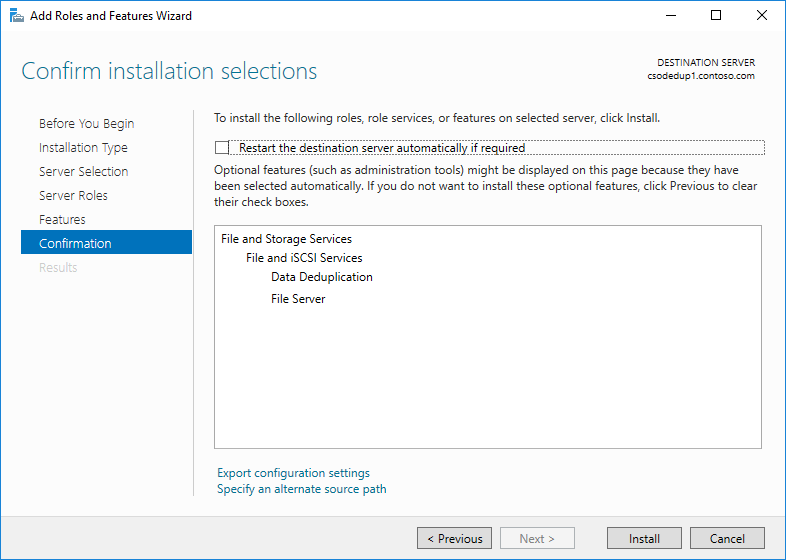
Installare Deduplicazione dati tramite PowerShell
Per installare Deduplicazione dati, eseguire il comando di PowerShell seguente come amministratore: Install-WindowsFeature -Name FS-Data-Deduplication
Per installare Deduplicazione dati:
Da un server che esegue Windows Server 2016 o versioni successive o da un PC Windows con installato Strumenti di amministrazione remota del server (RSAT), installare Deduplicazione dati con un riferimento esplicito al nome del server (sostituire "MyServer" con il nome effettivo dell'istanza del server):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-DeduplicationOr
Connettersi in remoto all'istanza del server con la comunicazione remota di PowerShell e usare Gestione e manutenzione immagini distribuzione per installare Deduplicazione dati:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Abilitare la deduplicazione dei dati
Determinare quali carichi di lavoro sono indicati per la deduplicazione dei dati
Deduplicazione dati può sensibilmente ridurre i costi di utilizzo dei dati delle applicazioni server, riducendo la quantità di spazio su disco occupato dai dati ridondanti. Prima di abilitare la deduplicazione, è importante comprendere le caratteristiche del proprio carico di lavoro per assicurarsi di ottenere le massime prestazioni di archiviazione. Le classi di carichi di lavoro da considerare sono due:
- I carichi di lavoro consigliati che hanno dimostrato di avere sia set di dati per cui la deduplicazione si è rivelata molto vantaggiosa sia modelli di uso delle risorse compatibili con il modello di post-elaborazione di Deduplicazione dati. È consigliabile abilitare sempre Deduplicazione dati su questi carichi di lavoro:
- Condivisioni di file server generali come condivisioni di team, home directory utente, cartelle di lavoro e condivisioni per lo sviluppo del software.
- Server VDI (Virtual Desktop Infrastructure).
- Applicazioni di backup virtualizzate, ad esempio Microsoft Data Protection Manager (DPM).
- I carichi di lavoro che potrebbero trarre vantaggio dalla deduplicazione, ma non sempre sono indicati per la deduplicazione. Ad esempio, i carichi di lavoro seguenti possono andare bene per la deduplicazione, ma è necessario valutare prima i vantaggi che possono trarne:
- Host Hyper-V per uso generico
- Server SQL
- Server line-of-business
Valutare i carichi di lavoro per Deduplicazione dati
Importante
Se si esegue un carico di lavoro consigliato, è possibile ignorare questa sezione e passare a Abilitare Deduplicazione dati per il carico di lavoro.
Per determinare se un carico di lavoro è idoneo alla deduplicazione, rispondere alle domande seguenti. Se non si è certi dell'idoneità di un carico di lavoro, eseguire una distribuzione pilota di Deduplicazione dati in un set di dati di test per il carico di lavoro e osservarne le prestazioni.
Il set di dati del carico di lavoro ha una duplicazione sufficiente per trarre vantaggio dall'abilitazione della deduplicazione? Prima di abilitare Deduplicazione dati per un carico di lavoro, verificare quanta duplicazione ha il set di dati del carico di lavoro tramite lo Strumento di valutazione risparmio deduplicazione dati Microsoft, o DDPEval. Dopo aver installato la deduplicazione dei dati, è possibile trovare questo strumento nel percorso
C:\Windows\System32\DDPEval.exe. DDPEval valuta il potenziale per l'ottimizzazione su volumi direttamente connessi (incluse unità locali o volumi condivisi cluster) e condivisioni di rete mappate o non mappate.L’esecuzione di DDPEval.exe restituirà un output simile al seguente:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Come sono i modelli IO del carico di lavoro rispetto al set di dati relativo? Quali prestazioni ha il carico di lavoro? Deduplicazione dati consente di ottimizzare i file come un processo periodico, anziché quando il file viene scritto su disco. È quindi importante esaminare i modelli di lettura prevista del carico di lavoro per il volume deduplicato. Poiché Deduplicazione dati sposta il contenuto di file nell'archivio blocchi e tenta il più possibile di organizzare l'archivio blocchi per file, le operazioni di lettura offrono prestazioni ottimali quando vengono applicate a intervalli sequenziali di un file.
I carichi di lavoro simili ai database hanno in genere modelli di lettura più casuali rispetto ai modelli di lettura sequenziali poiché in genere i database non garantiscono che il layout del database sarà ottimale per tutte le query che possono essere eseguite. Dal momento che le sezioni dell'archivio blocchi potrebbero esistere in tutto il volume, l'accesso agli intervalli di dati nell'archivio blocchi per le query di database può introdurre una latenza maggiore. I carichi di lavoro a prestazioni elevate sono particolarmente sensibili a questa latenza maggiore mentre altri carichi di lavoro di tipo database possono non esserlo altrettanto.
Nota
Questi problemi riguardano principalmente i carichi di lavoro di archiviazione in volumi costituiti da supporti di archiviazione rotazionali tradizionali (noti anche come unità disco rigido o HDD). Tutte le infrastrutture di archiviazione flash (note anche come unità disco stato solido, o unità SSD), sono meno influenzate dai modelli IO casuali perché una delle proprietà dei supporti flash è il tempo di accesso uguale a tutti i percorsi sul supporto. Di conseguenza, la deduplicazione non introduce la stessa quantità di latenza per le letture nei set di dati del carico di lavoro archiviati in tutti i supporti flash, come avviene nei supporti di archiviazione tradizionale rotazionali.
Quali sono i requisiti di risorse del carico di lavoro sul server? Dal momento che Deduplicazione dati usa un modello di post-elaborazione, deve avere periodicamente risorse di sistema sufficienti per completare l'ottimizzazione e altri processi. Ciò significa che i carichi di lavoro con tempo di inattività, ad esempio la sera o nei fine settimana, sono ottimi candidati per la deduplicazione e i carichi di lavoro che vengono eseguiti ogni giorno per tutto il giorno. Anche i carichi di lavoro che non hanno alcun tempo di inattività possono essere validi candidati per la deduplicazione se non hanno requisiti di risorse elevati nel server.
Abilitare la deduplicazione dei dati
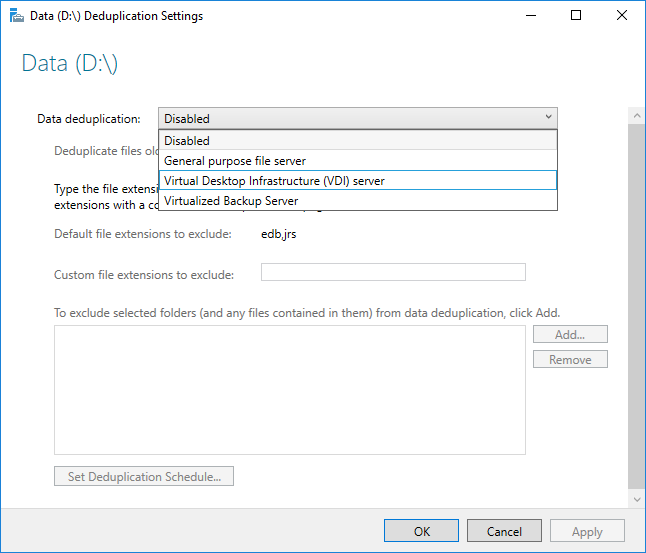
Prima di abilitare Deduplicazione dati, è necessario scegliere il tipo di utilizzo che rispecchia maggiormente il carico di lavoro. I tipi di utilizzo inclusi in Deduplicazione dati sono tre.
- Predefinito: ottimizzato in modo specifico per file server generali
- Hyper-V: ottimizzato in modo specifico per i server VDI
- Backup: ottimizzato in modo specifico per applicazioni di backup virtualizzate, ad esempio Microsoft DPM (Data Protection Manager)
Abilitare Deduplicazione dati tramite Server Manager
- Selezionare Servizi file e archiviazione in Server Manager.
- Selezionare Volumi da Servizi file e archiviazione.
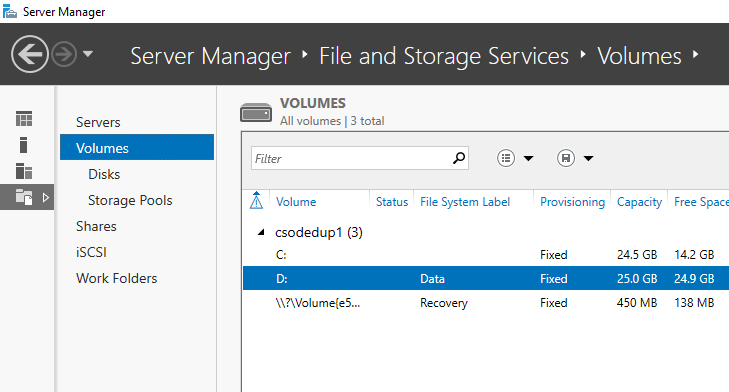
- Fare clic con il pulsante destro del mouse sul volume desiderato e selezionare Configura deduplicazione dati.
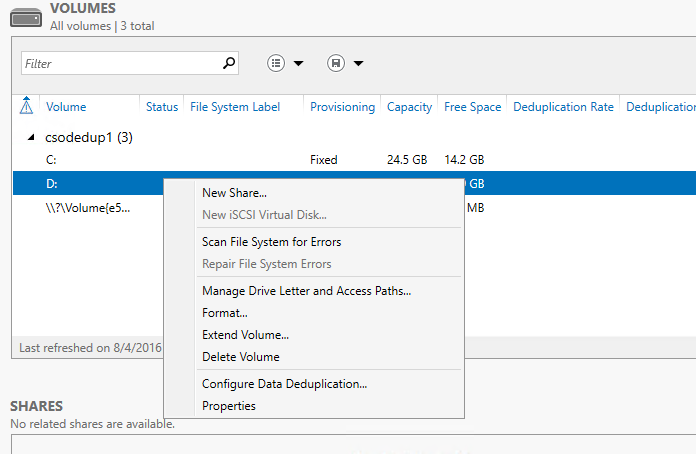
- Selezionare un tipo di uso dalla casella di riepilogo a discesa e selezionare OK.
- Se si sta eseguendo un carico di lavoro consigliato, la procedura termina qui. Per altri carichi di lavoro, vedere Altre considerazioni.
Nota
Per altre informazioni sull'esclusione di estensioni di file o cartelle e sulla selezione della pianificazione della deduplicazione, nonché sui motivi per cui si vuole eseguire questa operazione, vedere Configuring Data Deduplication (Configurazione di Deduplicazione dati).
Abilitare Deduplicazione dati tramite PowerShell
In un contesto con autorizzazioni di amministratore eseguire il comando di PowerShell seguente:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Se si sta eseguendo un carico di lavoro consigliato, la procedura termina qui. Per altri carichi di lavoro, vedere Altre considerazioni.
Nota
I cmdlet di PowerShell di Deduplicazione dati, inclusi Enable-DedupVolume, possono essere eseguiti in remoto mediante l'aggiunta del parametro -CimSession con una sessione CIM. Ciò è particolarmente utile per l'esecuzione in modalità remota dei cmdlet di PowerShell di deduplicazione dati per un'istanza del server. Per creare una nuova sessione CIM eseguire New-CimSession.
Altre considerazioni
Importante
Se si esegue un carico di lavoro consigliato, è possibile ignorare questa sezione.
- I tipi di utilizzo di Deduplicazione dati specificano i valori predefiniti appropriati per i carichi di lavoro consigliati, ma sono anche un buon punto di partenza per tutti i carichi di lavoro. Per i carichi di lavoro diversi da quelli consigliati, è possibile modificare le impostazioni avanzate di Deduplicazione dati per migliorare le prestazioni di deduplicazione.
- Se il carico di lavoro è caratterizzato da requisiti di risorse elevati sul server, i processi di Deduplicazione dati devono essere pianificati in modo che la loro esecuzione avvenga durante i periodi di inattività previsti per il carico di lavoro. Ciò è particolarmente importante quando si esegue la deduplicazione su un host iperconvergente, in quanto l'esecuzione di Deduplicazione dati durante l'orario di lavoro previsto può sottrarre risorse alle macchine virtuali.
- Se il carico di lavoro non è caratterizzato da requisiti di risorse elevati o se il completamento dei processi di ottimizzazione è più importante delle richieste del carico di lavoro, è possibile rettificare memoria, CPU e priorità dei processi di Deduplicazione dati.
Domande frequenti
L'esecuzione di Deduplicazione dati nel set di dati per il carico di lavoro X è supportata? A parte i carichi di lavoro che notoriamente non sono interoperabili con Deduplicazione dati, l'integrità dei dati completa di Deduplicazione dati è supportata con tutti i carichi di lavoro. I carichi di lavoro consigliati sono supportati da Microsoft anche per le prestazioni. Le prestazioni di altri carichi di lavoro dipendono notevolmente dalle attività che eseguono sul server. È necessario determinare quale impatto ha Deduplicazione dati sul carico di lavoro in termini di prestazioni e se questo è accettabile per questo carico di lavoro.
Quali sono i requisiti di ridimensionamento del volume per i volumi deduplicati? In Windows Server 2012 e Windows Server 2012 R2, i volumi dovevano essere ridimensionati con attenzione per assicurarsi che la deduplicazione dei dati potesse far fronte alla varianza nel volume. Questo significava in genere che la dimensione massima media di un volume deduplicato per un carico di lavoro di varianza elevato era 1-2 TB e la dimensione assoluta massima consigliata era 10 TB. In Windows Server 2016 queste limitazioni sono state rimosse. Per altre informazioni, vedere What's new in Data Deduplication (Novità di Deduplicazione dati).
È necessario modificare la pianificazione o altre impostazioni di Deduplicazione dati per i carichi di lavoro consigliati? No, i tipi di utilizzo specificati sono stati creati per offrire valori predefiniti ragionevoli per i carichi di lavoro consigliati.
Quali sono i requisiti di memoria per la deduplicazione dei dati?
I requisiti minimi di memoria per Deduplicazione dati sono 300 MB + 50 MB per ogni TB di dati logici. Ad esempio, se si sta ottimizzando un volume di 10 TB, è necessario un minimo di 800 MB di memoria allocata per la deduplicazione (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Mentre Deduplicazione dati può ottimizzare un volume con una quantità di memoria così ridotta, risorse così vincolate rallenteranno i processi di Deduplicazione dati.
In una situazione ottimale Deduplicazione dati deve avere almeno 1 GB di memoria per ogni TB di dati logici. Ad esempio, se si sta ottimizzando un volume di 10 TB, la quantità di memoria allocata ottimale per Deduplicazione dati sarebbe di 10 GB (1 GB * 10). Questo rapporto garantisce prestazioni massime per i processi di Deduplicazione dati.
Quali sono i requisiti di archiviazione per la deduplicazione dei dati? In Windows Server 2016 Deduplicazione dati supporta dimensioni di volume fino a 64 TB. Per altre informazioni, vedere What's new in Data Deduplication (Novità della deduplicazione dei dati).