Usare Arricchimento delle note cliniche non strutturate (anteprima) nelle soluzioni per dati sanitari
[Questo articolo fa parte della documentazione non definitiva, pertanto è soggetto a modifiche.]
Nota
Questo contenuto è in fase di aggiornamento.
Arricchimento delle note cliniche non strutturate (anteprima) utilizza il servizio Text Analytics for Health di Lingua di Azure AI per estrarre entità FHIR (Fast Healthcare Interoperability Resources) da note cliniche non strutturate. Crea dati strutturati a partire da queste note cliniche. Puoi quindi analizzare questi dati strutturati per ottenere informazioni dettagliate, previsioni e misure di qualità intese a migliorare i risultati sulla salute dei pazienti.
Per altre informazioni sulla funzionalità e su come distribuirla e configurarla, vedi:
- Panoramica di Arricchimento delle note cliniche non strutturate (anteprima)
- Distribuire e configurare Arricchimento delle note cliniche non strutturate (anteprima)
Arricchimento delle note cliniche non strutturate (anteprima) ha una dipendenza diretta dalla funzionalità Data foundation per il settore sanitario. Assicurati innanzitutto di configurare ed eseguire correttamente le pipeline di Data foundation per il settore sanitario.
Prerequisiti
- Distribuire soluzioni per dati sanitari in Microsoft Fabric
- Installa i notebook e le pipeline di base in Distribuire Data foundation per il settore sanitario.
- Configura il servizio Lingua di Azure come descritto in Configurare il servizio Lingua di Azure .
- Distribuire e configurare Arricchimento delle note cliniche non strutturate (anteprima)
- Distribuire e configurare Trasformazioni OMOP. Questo passaggio è facoltativo.
Servizio di inserimento NLP
Il notebook healthcare#_msft_ta4h_silver_ingestion esegue il modulo NLPIngestionService nella libreria delle soluzioni per dati sanitari per richiamare il servizio Azure Text Analytics for Health. Questo servizio estrae le note cliniche non strutturate dalla risorsa FHIR DocumentReference.Content per creare un output flat. Per altre informazioni, vedi Esaminare la configurazione dei notebook.
Archiviazione dei dati nel livello Silver
Dopo l'analisi dell'API NLP (elaborazione del linguaggio naturale), l'output strutturato e flat viene archiviato nelle seguenti tabelle native nel lakehouse healthcare#_msft_silver:
- nlpentity: contiene le entità flat estratte dalle note cliniche non strutturate. Ogni riga è un singolo termine estratto dal testo non strutturato dopo aver eseguito l'analisi del testo.
- nlprelationship: fornisce la relazione tra le entità estratte.
- nlpfhir: contiene il bundle di output FHIR come stringa JSON.
Per tenere traccia dell'ultimo timestamp aggiornato, NLPIngestionService utilizza il campo parent_meta_lastUpdated in tutte e tre le tabelle del lakehouse Silver. Questo rilevamento garantisce che il documento di origine DocumentReference, ovvero la risorsa padre, venga prima archiviato per mantenere l'integrità referenziale. Questo processo consente di evitare incoerenze nei dati e nelle risorse orfane.
Importante
Attualmente, Text Analytics for Health restituisce vocabolari elencati nella documentazione del vocabolario Metathesaurus UMLS. Per informazioni su questi vocabolari, vedi Importare dati da UMLS.
Per la versione di anteprima, usiamo le terminologie SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) e RxNorm incluse nel set di dati OMOP di esempio in base alle linee guida Observational Health Data Sciences and Informatics (OHDSI).
Trasformazione OMOP
Le soluzioni per dati sanitari in Microsoft Fabric offrono anche un'altra funzionalità per le trasformazioni OMOP (Observational Medical Outcomes Partnership). Quando si esegue questa funzionalità, la trasformazione sottostante dal lakehouse Silver al lakehouse Gold OMOP trasforma anche l'output strutturato e flat dell'analisi delle note cliniche non strutturate. La trasformazione legge dalla tabella nlpentity nel lakehouse Silver ed esegue il mapping dell'output alla tabella NOTE_NLP nel lakehouse Gold OMOP.
Per altre informazioni, vedi Panoramica di Trasformazioni OMOP.
Di seguito è riportato lo schema per gli output NLP strutturati, con il mapping della colonna NOTE_NLP al modello di dati comune OMOP:
| Riferimento a documenti flat | Descrzione | Mapping Note_NLP | Dati di esempio |
|---|---|---|---|
| ID. | Identificatore univoco per l'entità. Chiave composta di parent_id, offset e length. |
note_nlp_id |
1380 |
| parent_id | Una chiave esterna del testo documentreferencecontent flat da cui è stato estratto il termine. | note_id |
625 |
| Testo | Testo dell'entità come appare nel documento. | lexical_variant |
Nessuna allergia nota |
| Offset | Offset di caratteri del termine estratto nel testo documentreferencecontent di input. | offset |
294 |
| data_source_entity_id | ID dell'entità nel catalogo di origini specificato. | note_nlp_concept_id e note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | Data dell'elaborazione dell'analisi del testo documentreferencecontent. | nlp_date_time e nlp_date |
2023-05-17T00:00:00.0000000 |
| modello | Nome e versione del sistema NLP (nome e versione del sistema NLP di Text Analytics for Health). | nlp_system |
MSFT TA4H |

Limiti del servizio per Text Analytics for Health
- Il numero massimo di caratteri per documento è limitato a 125.000.
- La dimensione massima dei documenti contenuti nell'intera richiesta è limitata a 1 MB.
- Il numero massimo di documenti per richiesta è limitato a:
- 25 per l'API basata sul Web.
- 1000 per il contenitore.
Abilitare i log
Segui questa procedura per abilitare la registrazione di richieste e risposte per l'API Text Analytics for Health:
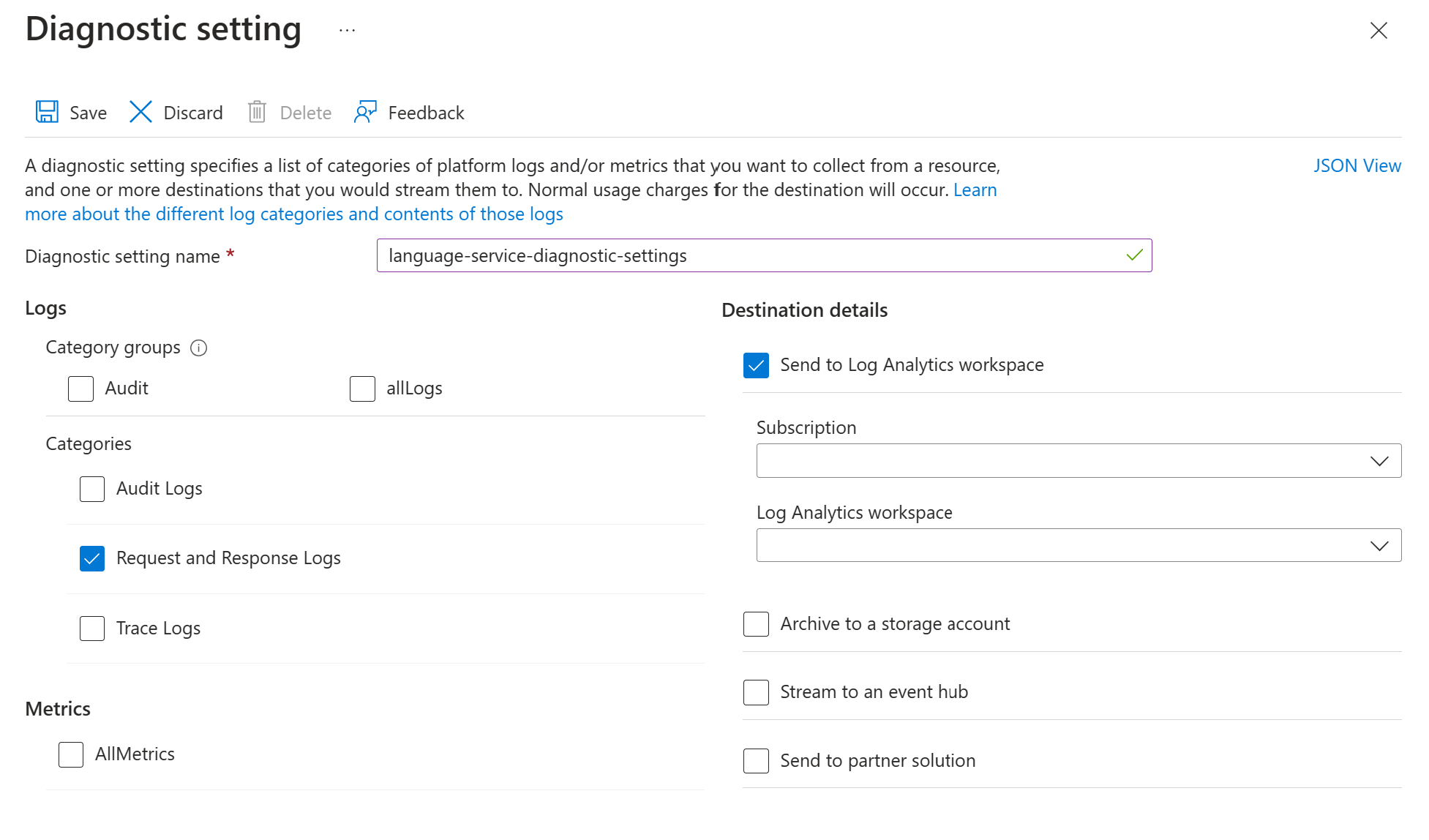
Abilita le impostazioni di diagnostica per la risorsa del servizio Lingua di Azure seguendo le istruzioni riportate in Abilitare la registrazione diagnostica per Servizi di Azure AI. Questa risorsa è lo stesso servizio di lingua che hai creato durante il passaggio di distribuzione Configurare il servizio Lingua di Azure.
- Immetti un nome per l'impostazione di diagnostica.
- Imposta la categoria su Log di richieste e risposte.
- Per i dettagli sulla destinazione, seleziona Invia all'area di lavoro Log Analytics e seleziona l'area di lavoro Log Analytics necessaria. Se non disponi di un'area di lavoro, segui le istruzioni per crearne una.
- Salva le impostazioni.
Passa alla vConfigurazione NLP nel notebook del servizio di inserimento NLP. Aggiorna il valore del parametro di configurazione da
enable_text_analytics_logsaTrue. Per altre informazioni su questo notebook, vedi Esaminare la configurazione del notebook.

Visualizzare i log in Azure Log Analytics
Per esplorare i dati di Log Analytics:
- Accedi all'area di lavoro di Log Analytics.
- Individua e seleziona Log. Da questa pagina puoi eseguire query sui log.
Query di esempio
Di seguito è riportata una query Kusto di base che puoi usare per esplorare i dati di log. Questa query di esempio recupera tutte le richieste non riuscite dal provider di risorse Servizi cognitivi di Azure nell'ultimo giorno, raggruppate per tipo di errore:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature