Pianificazione della migrazione da Azure Data Factory
Microsoft Fabric è il prodotto SaaS di analisi dei dati di Microsoft che riunisce tutti i prodotti di analisi leader di mercato di Microsoft in un'unica esperienza utente. Fabric Data Factory offre orchestrazione del flusso di lavoro, spostamento dei dati, replica dei dati e trasformazione dei dati su larga scala con funzionalità simili disponibili in Azure Data Factory (ADF). Se si hanno investimenti ADF esistenti da modernizzare in Data Factory di Fabric, questo documento è utile per comprendere considerazioni, strategie e approcci alla migrazione.
La migrazione dai servizi Azure PaaS ETL/DI ADF &, le pipeline e i flussi di dati Synapse può offrire diversi vantaggi importanti.
- Le nuove funzionalità della pipeline integrata, tra cui la posta elettronica e le attività di Teams, consentono un semplice routing dei messaggi durante l'esecuzione della pipeline.
- Le funzionalità predefinite di integrazione e recapito continuo (CI/CD) (pipeline di distribuzione) non richiedono l'integrazione esterna con i repository Git.
- L'integrazione dell'area di lavoro con il data lake OneLake consente una gestione semplice dell'analisi a riquadro singolo.
- L'aggiornamento dei modelli di dati semantici è semplice in Fabric con un'attività della pipeline completamente integrata.
Microsoft Fabric è una piattaforma integrata sia per i dati aziendali self-service che per i dati aziendali gestiti dall'IT. Con una crescita esponenziale dei volumi di dati e della complessità, i clienti di Fabric richiedono soluzioni aziendali scalabili, sicure, facili da gestire e accessibili a tutti gli utenti nelle più grandi organizzazioni.
Negli ultimi anni Microsoft ha investito notevoli sforzi per offrire funzionalità cloud scalabili a Premium. A tal fine, Data Factory in Fabric abilita istantaneamente un vasto ecosistema di sviluppatori e soluzioni di integrazione dei dati sviluppati nel corso di decenni per applicare il set completo di funzionalità e capacità che superano di gran lunga le funzionalità disponibili nelle generazioni precedenti.
Naturalmente, i clienti chiedono se è possibile consolidare ospitando le soluzioni di integrazione dei dati all'interno di Fabric. Le domande comuni includono:
- Tutta la funzionalità su cui facciamo affidamento funziona nelle pipeline di Fabric?
- Quali funzionalità sono disponibili solo nelle pipeline di Fabric?
- Come si esegue la migrazione delle pipeline esistenti alle pipeline di Fabric?
- Qual è la roadmap di Microsoft per l'inserimento di dati aziendali?
Differenze tra le piattaforme
Quando si esegue la migrazione di un'intera istanza di Azure Data Factory, esistono molte differenze importanti da considerare tra ADF e Data Factory in Fabric, che diventa importante durante la migrazione a Fabric. In questa sezione vengono esaminate diverse di queste importanti differenze.
Per comprendere più nel dettaglio le differenze di mappatura funzionale tra le funzionalità di Azure Data Factory e Fabric Data Factory, consultare Confrontare Data Factory in Fabric e Azure Data Factory.
Runtime di integrazione
In Azure Data Factory i runtime di integrazione sono oggetti di configurazione che rappresentano il calcolo usato da Azure Data Factory per completare l'elaborazione dei dati. Queste proprietà di configurazione includono l'area di Azure per il calcolo cloud e le dimensioni di calcolo spark del flusso di dati. Altri tipi di runtime di integrazione includono i runtime di integrazione self-hosted (SHIR) per la connettività dei dati locale, i runtime di integrazione SSIS per l'esecuzione di pacchetti di SQL Server Integration Services e i runtime di integrazione cloud abilitati per le reti virtuali.
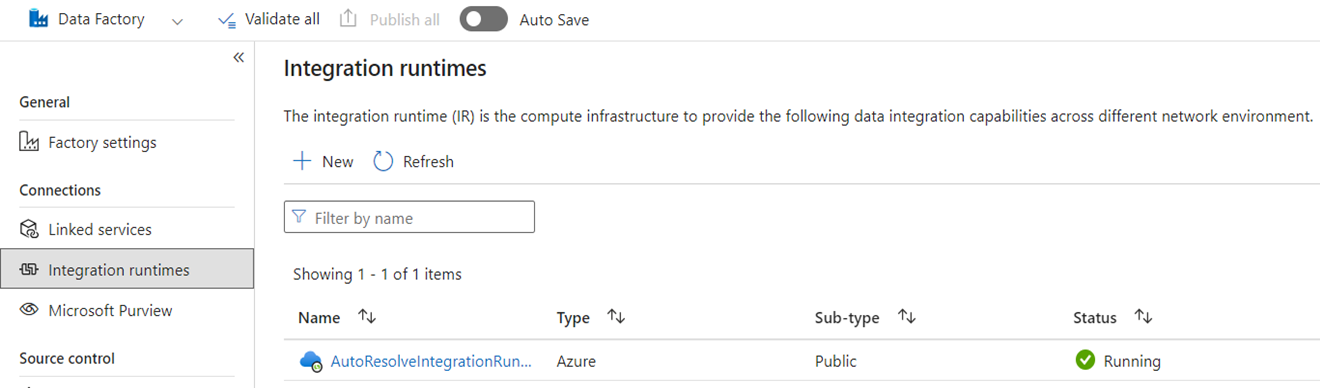
Microsoft Fabric è un prodotto SaaS (Software-as-a-Service), mentre ADF è un prodotto PaaS (Platform-as-a-Service). Ciò che questa distinzione significa in termini di runtime di integrazione è che non è necessario configurare nulla per usare pipeline o flussi di dati in Fabric perché l'impostazione predefinita consiste nell'usare il calcolo basato sul cloud nell'area in cui si trovano le capacità di Fabric. Le istanze di runtime di integrazione SSIS non esistono in Fabric e per la connettività dati locale si utilizza un componente specifico di Fabric noto come gateway dati locale (OPDG). Per la connettività basata su rete virtuale alle reti protette, si usa il gateway dati di rete virtuale in Fabric.
Quando si esegue la migrazione da ADF a Fabric, non è necessario eseguire la migrazione di IR di Rete pubblica di Azure (cloud). È necessario ricreare i tuoi SHIR come OPDG e gli Azure Integration Runtime abilitati alla rete virtuale come Gateway dati di rete virtuale.
Condutture
Le pipeline sono il componente fondamentale di Azure Data Factory, che viene usato per il flusso di lavoro primario e l'orchestrazione dei processi di Azure Data Factory per lo spostamento dei dati, la trasformazione dei dati e l'orchestrazione dei processi. Le pipeline in Fabric Data Factory sono quasi identiche a ADF, ma con componenti aggiuntivi che soddisfano il modello SaaS in base a Power BI. Questa somiglianza include attività native per gli aggiornamenti di messaggi di posta elettronica, Teams e Semantic Model.
La definizione JSON delle pipeline in Fabric Data Factory è leggermente diversa da ADF a causa delle differenze nel modello applicativo tra i due prodotti. A causa di questa differenza, non è possibile copiare/incollare pipeline JSON, pipeline di importazione/esportazione o puntare a un repository Git di Azure Data Factory.
Quando si ricompilano le pipeline di Azure Data Factory (ADF) come pipeline di Fabric, si usano essenzialmente gli stessi modelli di flusso di lavoro e competenze usati in ADF. La considerazione principale riguarda i servizi collegati e i set di dati che sono concetti in Azure Data Factory che non esistono in Fabric.
Servizi collegati
In Azure Data Factory i servizi collegati definiscono le proprietà di connettività necessarie per connettersi agli archivi dati per lo spostamento dei dati, la trasformazione dei dati e le attività di elaborazione dei dati. In Fabric, è necessario ricreare queste definizioni come Connessioni che sono proprietà delle tue attività, come Copy e Dataflows.
Dataset
I set di dati definiscono la forma, la posizione e il contenuto dei dati in Azure Data Factory, ma non esistono come entità in Fabric. Per definire proprietà dei dati come tipi di dati, colonne, cartelle, tabelle e così via nelle pipeline di Data Factory di Fabric, è necessario definire queste caratteristiche inline all'interno delle attività della pipeline e all'interno dell'oggetto Connection a cui si fa riferimento in precedenza nella sezione Servizio collegato.
Flussi di dati
In Fabric Data Factory, il termine flussi di dati si riferisce alle attività di trasformazione dei dati senza codice, mentre in ADF la stessa funzionalità viene definita flussi di dati. I flussi di dati di Data Factory di Fabric hanno un'interfaccia utente basata su Power Query, che viene usata nell'attività di Power Query di Azure Data Factory. Il motore di calcolo utilizzato per eseguire flussi di dati in Fabric è un motore di esecuzione nativo che può espandere per la trasformazione di dati su larga scala utilizzando il nuovo motore di calcolo di Fabric Data Warehouse.
In Azure Data Factory i flussi di dati sono basati sull'infrastruttura Synapse Spark e definiti usando un'interfaccia utente di costruzione che usa un linguaggio specifico del dominio sottostante noto come script del flusso di dati . Questo linguaggio di definizione differisce notevolmente dai flussi di dati basati su Power Query in Fabric che usano un linguaggio di definizione noto come M per definirne il comportamento. A causa di queste differenze nelle interfacce utente, nei linguaggi e nei motori di esecuzione, Fabric flussi di dati e ADF flussi di dati non sono compatibili ed è necessario ricreare i flussi di dati di Azure Data Factory come infrastruttura flussi di dati durante l'aggiornamento delle soluzioni a Fabric.
Trigger
I trigger segnalano ad ADF di eseguire una pipeline basata su una programmazione basata sull'orario di sistema, fette di tempo a finestra mobile, eventi basati su file o eventi personalizzati. Queste funzionalità sono simili in Fabric anche se l'implementazione sottostante è diversa.
In Fabric trigger esistono solo come concetto di pipeline. Il più ampio framework usato dai trigger della pipeline in Fabric è noto come Data Activator, che è un sottosistema per eventi e avvisi delle funzionalità di intelligenza in tempo reale di Fabric.
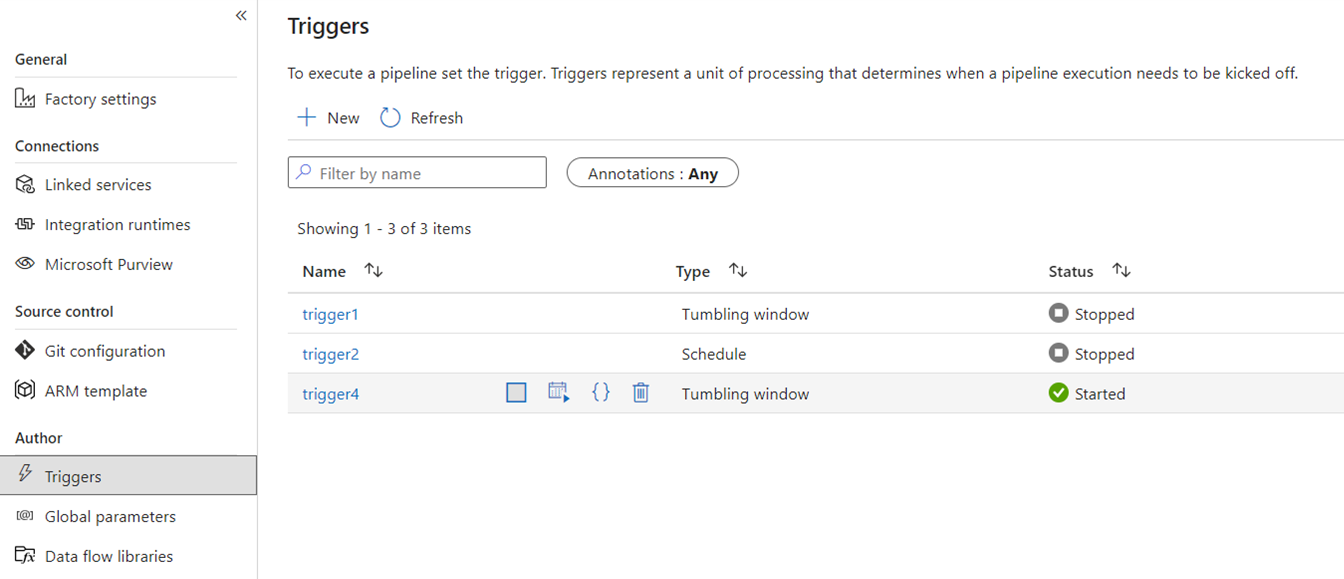
Fabric Data Activator comprende avvisi che possono essere utilizzati per creare eventi di file specifici e trigger di eventi personalizzati. Sebbene i trigger di pianificazione siano un'entità separata in Fabric nota come pianificazioni . Queste pianificazioni sono a livello di piattaforma in Fabric e non specifiche delle pipeline. Non sono inoltre definiti come trigger in Fabric.
Per eseguire la migrazione dei trigger da ADF a Fabric, pensa a ricostruire i trigger della pianificazione semplicemente come proprietà delle pipeline di Fabric. Per tutti gli altri tipi di trigger, usare il pulsante Triggers all'interno della pipeline di Fabric o usare il Data Activator in modo nativo in Fabric.
Debug
Il debug delle pipeline è più semplice in Fabric rispetto a ADF. Questa semplicità è dovuta al fatto che le pipeline di Data Factory di Fabric non hanno un concetto separato di modalità di debug che trovi nelle pipeline di ADF e nei flussi di dati. Al contrario, quando si compila la pipeline, si è sempre in modalità interattiva. Per testare ed eseguire il debug delle pipeline, è sufficiente selezionare il pulsante play sulla barra degli strumenti dell'editor della pipeline quando si è pronti nel ciclo di sviluppo. Le pipeline in Fabric non includono il debug fino a quando non si segue uno schema sequenziale di debug interattivo. In Fabric, invece, si usa lo stato dell'attività e si impostano solo le attività da testare come attive impostando tutte le altre attività su inattive per ottenere gli stessi modelli di test e debug. Fare riferimento al video seguente che illustra come ottenere questa esperienza di debug in Fabric.
Cattura delle Modifiche dei Dati
Change Data Capture (CDC) in ADF è una funzionalità di anteprima che semplifica lo spostamento dei dati in modo incrementale applicando le funzionalità CDC sul lato origine degli archivi dati. Per eseguire la migrazione degli artefatti CDC a Fabric Data Factory, ricrea questi artefatti come elementi attività di copia nell'area di lavoro Fabric. Questa funzionalità offre funzionalità simili di spostamento incrementale dei dati con un'interfaccia utente facile da usare senza richiedere una pipeline, proprio come in ADF CDC. Per ulteriori informazioni, vedere l'attività di copia per Data Factory in Fabric.
Collegamento ad Azure Synapse
Sebbene non sia disponibile in Azure Data Factory, gli utenti della pipeline di Synapse usano spesso collegamento ad Azure Synapse per replicare i dati dai database SQL al data lake in un approccio chiavi in mano. In Fabric, ricrei gli artefatti di Azure Synapse Link come elementi di Mirroring nell'area di lavoro. Per ulteriori informazioni, vedere su Infrastruttura il mirroring del database.
SQL Server Integration Services (SSIS)
SSIS è l'integrazione dei dati locale e lo strumento ETL fornito da Microsoft con SQL Server. In Azure Data Factory, puoi trasferire i pacchetti SSIS nel cloud attraverso la modalità lift-and-shift utilizzando l'SSIS IR di Azure Data Factory. In Fabric non è disponibile il concetto di IR, quindi questa funzionalità non è possibile oggi. Tuttavia, stiamo lavorando per abilitare l'esecuzione del pacchetto SSIS in modo nativo da Fabric, che speriamo di portare presto al prodotto. Nel frattempo, il modo migliore per eseguire pacchetti SSIS nel cloud con Fabric Data Factory consiste nell'avviare un runtime di integrazione SSIS nella factory di Azure Data Factory e quindi richiamare una pipeline di Azure Data Factory per chiamare i pacchetti SSIS. È possibile eseguire in remoto una chiamata a una pipeline di Azure Data Factory dalle pipeline di Fabric utilizzando l'attività di pipeline invocata descritta nella sezione seguente.
Richiamare l'attività della pipeline
Un'attività comune usata nelle pipeline di Azure Data Factory è l'attività Esegui pipeline che consente di chiamare un'altra pipeline nella tua factory. In Fabric, abbiamo migliorato questa attività come attività della pipeline Invoke. Fare riferimento alla documentazione dell'attività della pipeline "Invoke".
Questa attività è utile per gli scenari di migrazione in cui sono disponibili molte pipeline di Azure Data Factory che usano funzionalità specifiche di Azure Data Factory, ad esempio flussi di dati di mapping o SSIS. È possibile mantenere tali pipeline as-is in Azure Data Factory o anche nelle pipeline di Synapse, e quindi richiamare quella pipeline in linea dalla nuova pipeline di Fabric Data Factory utilizzando l'attività di Invoke pipeline e puntando alla pipeline della factory remota.
Scenari di migrazione di esempio
Gli scenari seguenti sono scenari di migrazione comuni che possono verificarsi durante la migrazione da ADF a Data Factory di Fabric.
Scenario 1: Pipeline e flussi di dati di Azure Data Factory
I casi d'uso principali per le migrazioni della factory si basano sulla modernizzazione dell'ambiente ETL dal modello di factory ADF PaaS al nuovo modello SaaS di Fabric. Gli elementi principali della factory di cui eseguire la migrazione sono pipeline e flussi di dati. Esistono diversi elementi fondamentali della factory che è necessario pianificare per la migrazione all'esterno di questi due elementi di primo livello: servizi collegati, runtime di integrazione, set di dati e trigger.
- I servizi collegati devono essere ricreati in Fabric come connessioni nelle attività del tuo pipeline.
- I set di dati non esistono in Factory. Le proprietà dei set di dati sono rappresentate come proprietà all'interno di attività della pipeline, ad esempio Copia o Ricerca, mentre Le connessioni contengono altre proprietà del set di dati.
- I runtime di integrazione non esistono in Fabric. È tuttavia possibile ricreare i runtime di integrazione self-hosted usando i gateway dati locali (OPDG) in Fabric e i runtime di integrazione della rete virtuale di Azure come gateway di rete virtuale gestiti nell'ambito di Fabric.
- Queste attività della pipeline di Azure Data Factory non sono incluse in Fabric Data Factory:
- Data Lake Analytics (U-SQL): questa funzionalità è un servizio di Azure deprecato.
- Attività di convalida: l'attività di convalida in Azure Data Factory è un'attività helper che è possibile ricompilare facilmente nelle pipeline di Fabric usando un'attività Recupera metadati, un ciclo della pipeline e un'attività If.
- Power Query: in Fabric, tutti i flussi di dati vengono compilati usando l'interfaccia utente di Power Query, per poter semplicemente copiare e incollare il codice M dalle attività di Power Query di Azure Data Factory e trasformarli in flussi di dati in Fabric.
- Se si usa una delle funzionalità della pipeline di Azure Data Factory non trovate in Fabric Data Factory, usare l'attività Invoke pipeline in Fabric per chiamare le pipeline esistenti in Azure Data Factory.
- Le attività della pipeline di Azure Data Factory seguenti vengono combinate in un'attività a scopo singolo:
- Attività di Azure Databricks (Notebook, Jar, Python)
- Azure HDInsight (Hive, Pig, MapReduce, Spark, Streaming)
L'immagine seguente mostra la pagina di configurazione del set di dati di Azure Data Factory con le relative impostazioni di compressione e percorso file:
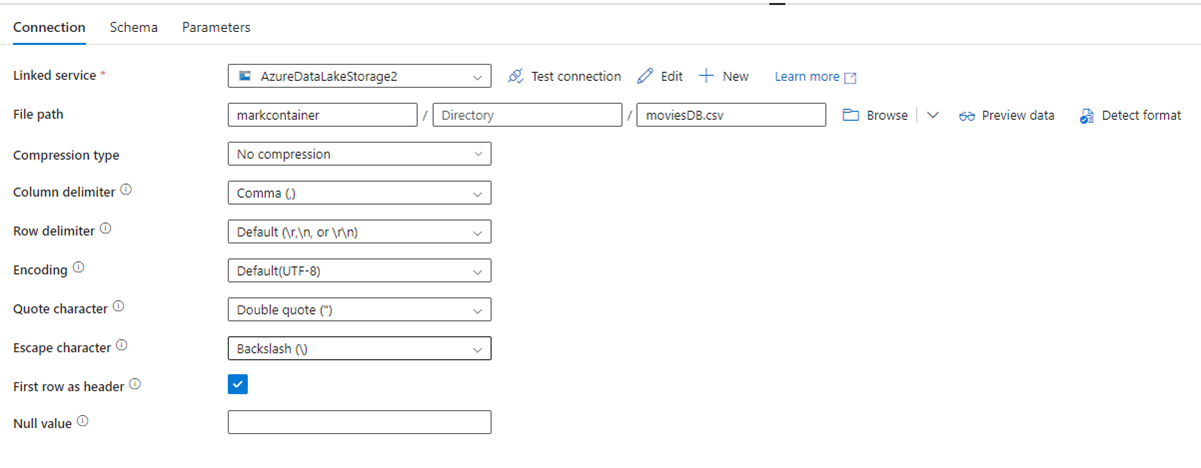
L'immagine seguente mostra la configurazione dell'attività di copia per Data Factory in Fabric, in cui la compressione e il percorso del file sono inline nell'attività:
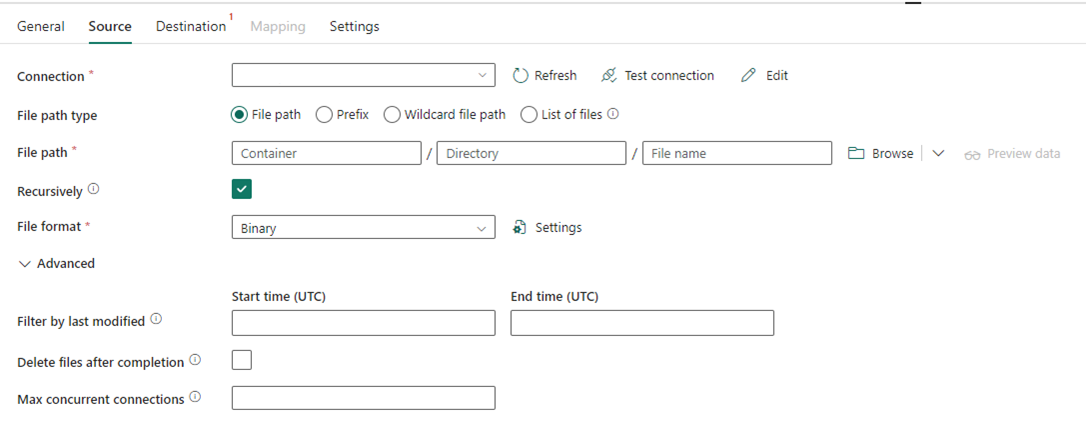
Scenario 2: ADF con CDC, SSIS e Airflow
CDC & Airflow in ADF sono funzionalità di anteprima, mentre SSIS in ADF è una funzionalità disponibile a livello generale per molti anni. Ognuna di queste funzionalità serve diverse esigenze di integrazione dei dati, ma richiede particolare attenzione durante la migrazione da ADF a Fabric. Change Data Capture (CDC) è un concetto di ADF di primo livello, ma in Fabric questa funzionalità viene visualizzata come processo di copia .
Airflow è la funzionalità Apache Airflow gestita dal cloud di Azure Data Factory ed è disponibile anche in Fabric Data Factory. Dovresti essere in grado di usare lo stesso repository di origine Airflow o prendere i tuoi DAG e copiare/incollare il codice nell'offerta Fabric Airflow con poche o nessuna modifica richiesta.
Scenario 3: Migrazione di Data Factory abilitata per Git a Fabric
È comune, anche se non necessario, che le factory e le aree di lavoro di Azure Data Factory o Synapse siano collegate a un provider Git esterno come ADO o GitHub. In questo scenario è necessario eseguire la migrazione degli elementi della factory e dell'area di lavoro a un'area di lavoro Fabric e quindi configurare l'integrazione Git nell'area di lavoro Fabric.
Fabric offre due modi principali per abilitare CI/CD, entrambi a livello di area di lavoro: integrazione Git, in cui si usa il proprio repository Git in ADO e ci si connette da Fabric e pipeline di distribuzione predefinite, in cui è possibile alzare di livello il codice a ambienti più elevati senza dover portare il proprio Git.
In entrambi i casi, il repository Git esistente da Azure Data Factory non funziona con Fabric. È invece necessario puntare a un nuovo repository o avviare un nuovo flusso di distribuzione in Fabric e ricompilare gli artefatti del flusso in Fabric.
Collega direttamente le tue istanze esistenti di Azure Data Factory a un'area di lavoro Fabric.
In precedenza abbiamo parlato dell'uso dell'attività Invoke Pipeline di Fabric Data Factory come meccanismo per mantenere gli investimenti esistenti nelle pipeline di Azure Data Factory e chiamarli direttamente da Fabric. All'interno di Fabric, è possibile portare questo concetto analogo un passo avanti e montare l'intera fabbrica all'interno dello spazio di lavoro di Fabric come elemento nativo di Fabric.
Per ulteriori informazioni sugli scenari d'uso crescenti, vedere scenari di collaborazione e distribuzione dei contenuti.
Integrare Azure Data Factory nel proprio spazio di lavoro Fabric offre molti vantaggi da considerare. Se non si ha familiarità con Fabric e si vuole mantenere le fabbriche affiancate all'interno dello stesso riquadro di vetro, è possibile montarle in Fabric in modo che sia possibile gestirle all'interno di Fabric. L'interfaccia utente completa di Azure Data Factory è ora disponibile dalla tua factory configurata, dove puoi monitorare, gestire e modificare completamente gli elementi della factory di Azure Data Factory direttamente dall'area di lavoro Fabric. Questa funzionalità semplifica notevolmente l'avvio della migrazione di questi elementi in Fabric come artefatti nativi di Fabric. Questa funzionalità è principalmente progettata per facilitare l'uso e semplifica la visualizzazione delle factory di Azure Data Factory nel tuo spazio di lavoro Fabric. Tuttavia, l'esecuzione effettiva delle pipeline, delle attività, dei runtime di integrazione e così via, si verifica comunque all'interno delle risorse di Azure.
Contenuto correlato
considerazioni sulla migrazione da Azure Data Factory a Data Factory in Fabric