Che cosa sono gli schemi lakehouse (anteprima)?
Lakehouse supporta la creazione di schemi personalizzati. Gli schemi consentono di raggruppare le tabelle per migliorare l'individuazione dei dati, il controllo di accesso e altro.
Creare uno schema lakehouse
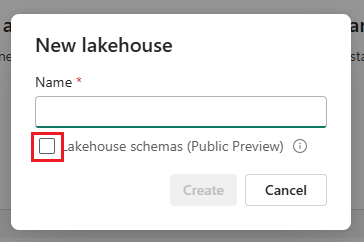
Per abilitare il supporto schema per un lakehouse, selezionare la casella accanto a Schemi lakehouse (anteprima pubblica) al momento della creazione.
Importante
I nomi delle aree di lavoro devono contenere solo caratteri alfanumerici a causa delle limitazioni dell’anteprima. Se nei nomi delle aree di lavoro vengono usati caratteri speciali, alcune funzionalità di Lakehouse non funzioneranno.
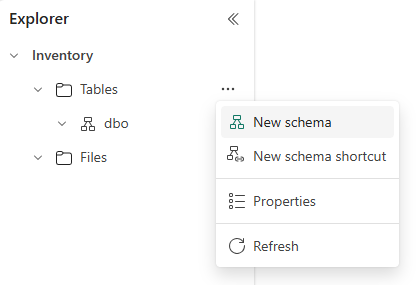
Dopo aver creato il lakehouse, è possibile trovare uno schema predefinito denominato dbo in Tabelle. Questo schema è sempre presente e non può essere modificato o rimosso. Per creare un nuovo schema, passare il puntatore del mouse su Tabelle, selezionare ... e scegliere Nuovo schema. Immettere un nome schema e selezionare Crea. Lo schema verrà elencato in Tabelle in ordine alfabetico.
Archiviare tabelle in schemi lakehouse
È necessario un nome schema per archiviare una tabella in uno schema. In caso contrario, si passa allo schema dbo predefinito.
df.write.mode("Overwrite").saveAsTable("contoso.sales")
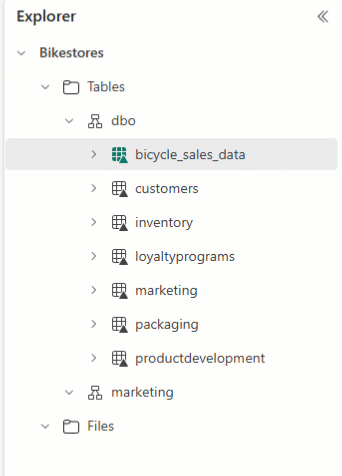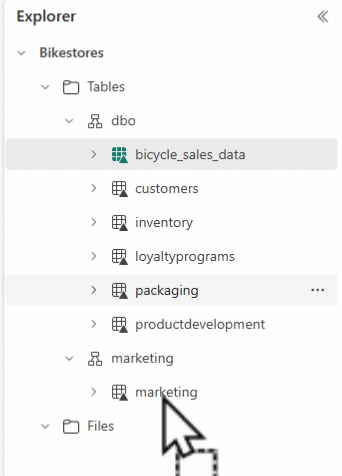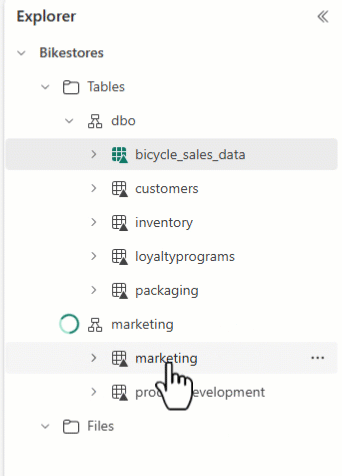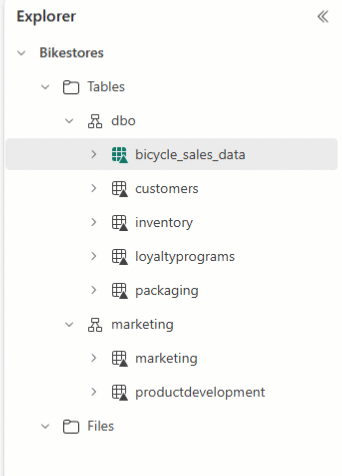
È possibile usare Esplora lakehouse per disporre le tabelle e trascinare e rilasciare nomi tabella in schemi diversi.
Attenzione
Se si modifica la tabella, è necessario anche aggiornare gli elementi correlati, ad esempio il codice del notebook o i flussi di dati, per assicurarsi che siano allineati allo schema corretto.
Portare più tabelle con collegamento schema
Per fare riferimento a più tabelle Delta da un altro lakehouse Fabric o da un’archiviazione esterna, usare il collegamento schema che visualizza tutte le tabelle nello schema o nella cartella scelta. Tutte le modifiche apportate alle tabelle nella posizione di origine appaiono anche nello schema. Per creare un collegamento schema, passare il puntatore del mouse su Tabelle, selezionare ... e scegliere Nuovo collegamento schema. Selezionare quindi uno schema in un altro lakehouse o una cartella con tabelle Delta nell'archiviazione esterna, ad esempio Azure Data Lake Storage (ADLS) Gen2. In questo modo viene creato un nuovo schema con le tabelle a cui si fa riferimento.
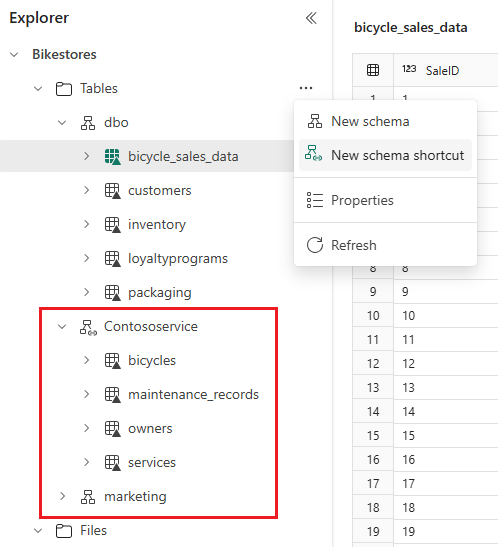
Accedere agli schemi lakehouse per la creazione di report di Power BI
Per rendere il modello semantico, è sufficiente scegliere le tabelle da usare. Le tabelle possono trovarsi in schemi diversi. Se le tabelle di schemi diversi condividono lo stesso nome, vengono visualizzati numeri accanto ai nomi delle tabelle nella visualizzazione del modello.
Schemi lakehouse nel notebook
Quando si esamina uno lakehouse abilitato per lo schema in Esplora oggetti del notebook, si vede che le tabelle si trovano in schemi. È possibile trascinare e rilasciare una tabella in una cella di codice e ottenere un frammento di codice che fa riferimento allo schema in cui si trova la tabella. Usare questo spazio dei nomi per fare riferimento alle tabelle nel codice: "workspace.lakehouse.schema.table". Se si esclude uno degli elementi, l'executor usa l'impostazione predefinita. Ad esempio, se si assegna solo un nome tabella, viene usato lo schema predefinito (dbo) dal lakehouse predefinito per il notebook.
Importante
Se si vogliono usare schemi nel codice, assicurarsi che il lakehouse predefinito per il notebook sia abilitato per lo schema.
Query SQL Spark tra aree di lavoro
Usare lo spazio dei nomi "workspace.lakehouse.schema.table" per fare riferimento alle tabelle nel codice. In questo modo, è possibile unire tabelle da aree di lavoro diverse se l'utente che esegue il codice dispone dell'autorizzazione per accedere alle tabelle.
SELECT *
FROM operations.hr.hrm.employees as employees
INNER JOIN global.corporate.company.departments as departments
ON employees.deptno = departments.deptno;
Importante
Assicurarsi di unire tabelle solo da lakehouse con schemi abilitati. L’unione di tabelle da lakehouse senza schemi abilitati non funzionerà.
Limiti dell'anteprima pubblica
Di seguito sono elencate le funzionalità non supportate per la release corrente dell'anteprima pubblica. Verranno risolte nelle prossime release prima della disponibilità generale.
| Funzionalità non supportata | Note |
|---|---|
| Lakehouse condiviso | L'uso dell'area di lavoro nello spazio dei nomi per i lakehouse condivisi non funzionerà, ad esempio wokrkspace.sharedlakehouse.schema.table. L'utente deve avere il ruolo dell'area di lavoro per usare l'area di lavoro in namaspace. |
| Schema di tabella gestita, non Delta | Il recupero dello schema per le tabelle gestite in formato non Delta (ad esempio CSV) non è supportato. L'espansione di queste tabelle in Esplora lakehouse non mostra informazioni sullo schema nell'UX. |
| Tabelle Spark esterne | Le operazioni delle tabelle Spark esterne (ad esempio individuazione, recupero dello schema e così via) non sono supportate. Queste tabelle non sono identificate nell'UX. |
| API pubblica | Le API pubbliche (Elenca tabelle, Carica tabella, esposizione della proprietà estesa defaultSchema e così via) non sono supportate per Lakehouse con abilitazione schema. Le API pubbliche esistenti chiamate su un lakehouse con abailitazione schema generano un errore. |
| Aggiornare le proprietà delle tabelle | Non supportato. |
| Nome dell'area di lavoro contenente caratteri speciali | L'area di lavoro con caratteri speciali (ad esempio spazio, barre) non è supportata. Viene visualizzato un errore utente. |
| Viste di Spark | Non supportato. |
| Funzionalità specifiche di hive | Non supportato. |
| Spark.catalog API | Non supportato. Usare invece Spark SQL. |
USE <schemaName> |
Non funziona tra aree di lavoro, ma il supporto è disponibile all'interno della stessa area di lavoro. |
| Migrazione | La migrazione di lakehouse non schema esistenti a lakehouse basati su schema non è supportata. |