Collegamenti a OneLake
I collegamenti in Microsoft OneLake consentono di unificare i dati tra domini, cloud e account creando un singolo data lake virtuale per l'intera azienda. Tutte le esperienze di Fabric e i motori analitici possono connettersi direttamente alle origini dati esistenti, ad esempio Azure, Amazon Web Services (AWS) e OneLake tramite uno spazio dei nomi unificato. OneLake gestisce tutte le autorizzazioni e le credenziali, quindi non è necessario configurare separatamente ogni carico di lavoro Fabric per connettersi a ogni origine dati. Inoltre, è possibile usare i collegamenti per eliminare le copie perimetrali dei dati e ridurre la latenza dei processi associati alle copie dei dati e alla gestione temporanea.
Che cosa sono i collegamenti?
I collegamenti sono oggetti in OneLake che puntano ad altre posizioni di archiviazione. La posizione può essere interna o esterna a OneLake. La posizione a cui punta un collegamento è nota come percorso di destinazione del collegamento. Il percorso in cui viene visualizzato il collegamento è noto come percorso di collegamento. I collegamenti vengono visualizzati come cartelle in OneLake e qualsiasi carico di lavoro o servizio che ha accesso a OneLake può usarli. I collegamenti si comportano come collegamenti simbolici. Sono un oggetto indipendente dalla destinazione. Se si elimina un collegamento, la destinazione rimane invariata. Se si sposta, si rinomina o si elimina un percorso di destinazione, il collegamento può interrompersi.

Dove è possibile creare collegamenti?
È possibile creare collegamenti in lakehouse e database Linguaggio di query Kusto (KQL). Inoltre, i collegamenti creati all'interno di questi elementi possono puntare ad altre posizioni di OneLake, Azure Data Lake Storage (ADLS) Gen2, account di archiviazione Amazon S3 o Dataverse. È anche possibile creare collegamenti a percorsi locali o con restrizioni di rete con l'uso del gateway dati locale di Fabric (OPDG).
È possibile usare l'interfaccia utente di Fabric per creare collegamenti in modo interattivo ed è possibile usare l'API REST per creare collegamenti a livello di codice.
Lakehouse
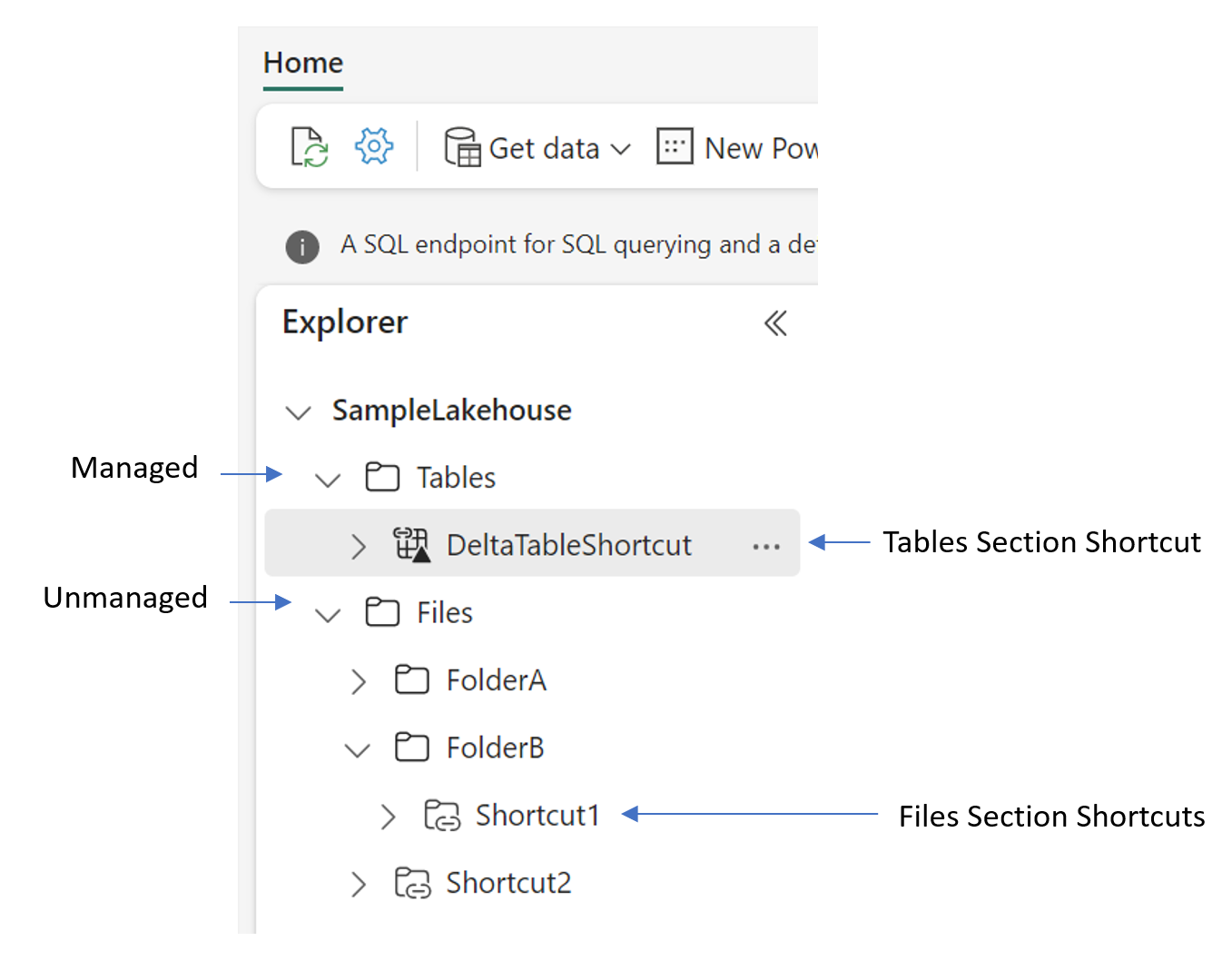
Quando si creano collegamenti in una lakehouse, è necessario comprendere la struttura di cartelle dell'elemento. Le lakehouse sono costituite da due cartelle di primo livello: la cartella Tabelle e la cartella File. La cartella tabelle rappresenta la parte gestita della lakehouse, cioè per i set di dati strutturati. La cartella File è la parte non gestita della lakehouse, destinata ai dati non strutturati o semi-strutturati.
Nella cartella Tabelle è possibile creare collegamenti solo al livello superiore. I collegamenti non sono supportati in altre sottodirectory della cartella Tabelle. Le scorciatoie nella sezione Tabelle in genere puntano a origini interne di OneLake o sono associate ad altri asset di dati conformi al formato di tabella Delta. Se la destinazione del collegamento contiene dati nel formato Delta\Parquet, la lakehouse sincronizza automaticamente i metadati e riconosce la cartella come tabella.
Nella cartella File non sono previste restrizioni sulla posizione in cui è possibile creare collegamenti. È possibile crearli a qualsiasi livello della gerarchia di cartelle. L'individuazione tabelle non viene eseguita nella cartella File. I collegamenti qui possono puntare sia ai sistemi di archiviazione interni (OneLake) che a sistemi di archiviazione esterni con dati in qualsiasi formato.
Database KQL
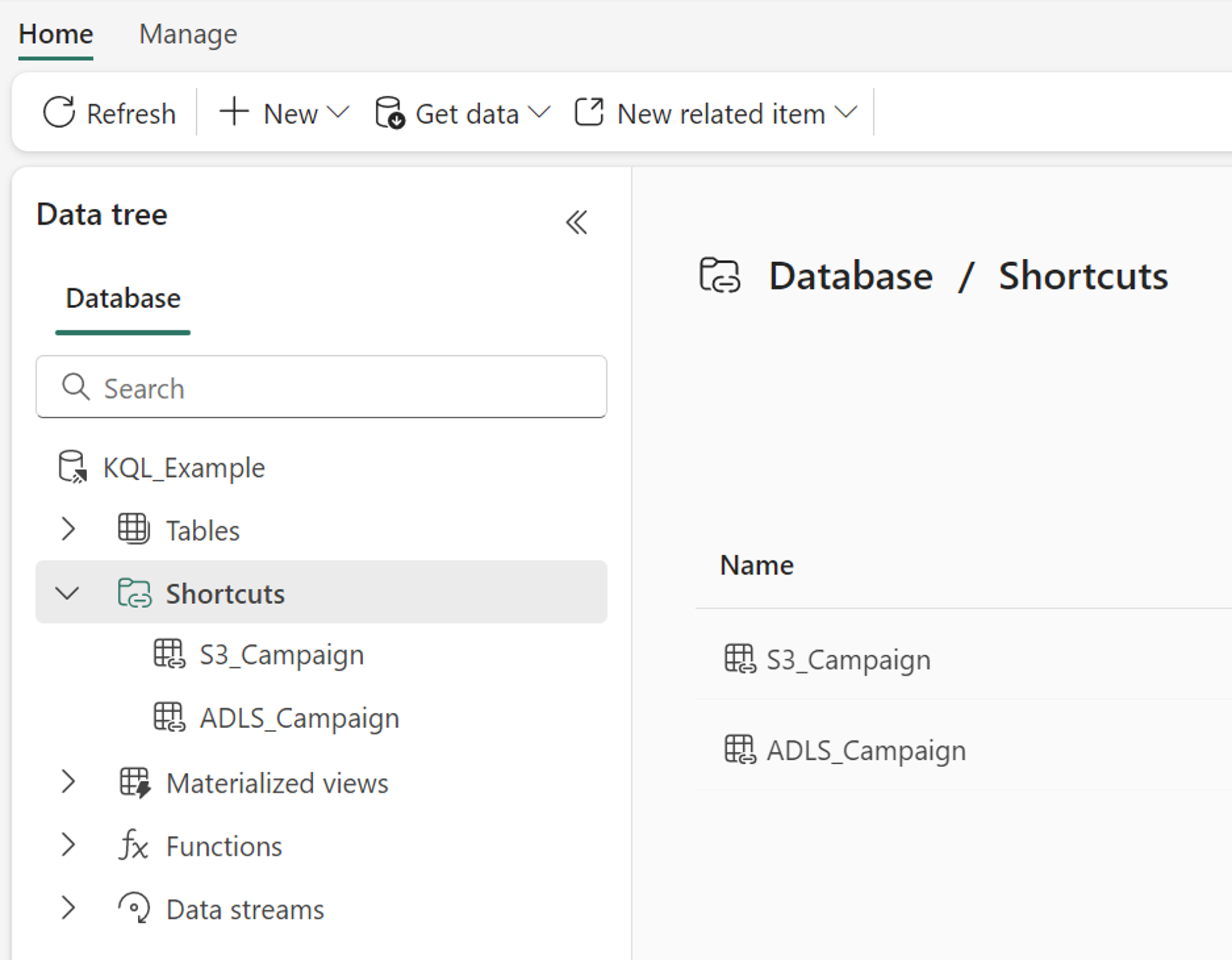
Quando si crea un collegamento in un database KQL, viene visualizzato nella cartella Collegamenti del database. Il database KQL gestisce collegamenti come tabelle esterne. Per eseguire una query sul collegamento, usare la funzione external_table del Linguaggio di query Kusto.
Dove è possibile accedere ai collegamenti?
Qualsiasi servizio Fabric o non Fabric in grado di accedere ai dati in OneLake può usare i collegamenti. I collegamenti sono trasparenti per qualsiasi servizio che accede ai dati tramite l'API OneLake. I collegamenti vengono visualizzati come un'altra cartella nel lake. Apache Spark, SQL, Intelligenza in tempo reale e Analysis Services possono usare tutti i collegamenti per l'esecuzione di query sui dati.
Apache Spark
I notebook Apache Spark e i processi Apache Spark possono usare i collegamenti creati in OneLake. I percorsi di file relativi possono essere usati per leggere direttamente i dati dai collegamenti. Inoltre, se si crea un collegamento nella sezione Tabelle della lakehouse e si trova nel formato Delta, è possibile leggerlo come tabella gestita usando la sintassi SQL di Apache Spark.
df = spark.read.format("delta").load("Tables/MyShortcut")
display(df)
df = spark.sql("SELECT * FROM MyLakehouse.MyShortcut LIMIT 1000")
display(df)
Nota
Il formato Delta non supporta tabelle con spazi nel nome. Qualsiasi collegamento contenente uno spazio nel nome non verrà individuato come tabella Delta nella lakehouse.
SQL
È anche possibile leggere i collegamenti nella sezione Tabelle di una lakehouse tramite l'endpoint di analisi SQL per la lakehouse. È possibile accedere all'endpoint di analisi SQL tramite il selettore di modalità della lakehouse o tramite SQL Server Management Studio (SSMS).
SELECT TOP (100) *
FROM [MyLakehouse].[dbo].[MyShortcut]
Intelligence in tempo reale
I collegamenti nei database KQL vengono riconosciuti come tabelle esterne. Per eseguire una query sul collegamento, usare la funzione external_table del Linguaggio di query Kusto.
external_table('MyShortcut')
| take 100
Analysis Services
È possibile creare modelli semantici per le lakehouse contenenti collegamenti nella sezione Tabelle della lakehouse. Quando il modello semantico viene eseguito in modalità Direct Lake, Analysis Services può leggere i dati direttamente dal collegamento.
Non Fabric
Le applicazioni e i servizi all'esterno di Fabric possono anche accedere ai collegamenti tramite l'API OneLake. OneLake supporta un sottoinsieme delle API di archiviazione BLOB e ADLS Gen2. Per altre informazioni sull'API OneLake, consultare Accesso a OneLake con le API.
https://onelake.dfs.fabric.microsoft.com/MyWorkspace/MyLakhouse/Tables/MyShortcut/MyFile.csv
Tipi di collegamenti
I collegamenti OneLake supportano più origini dati del file system. Sono incluse le posizioni interne di OneLake, Azure Data Lake Storage (ADLS) Gen2, Amazon S3, S3 Compatible, Google Cloud Storage (GCS) e Dataverse.
Collegamenti interni a OneLake
I collegamenti interni a OneLake consentono di fare riferimento ai dati all'interno di elementi Fabric esistenti. Questi elementi includono lakehouse, database KQL e data warehouse. Il collegamento può puntare a una posizione della cartella all'interno dello stesso elemento, tra gli elementi all'interno della stessa area di lavoro o anche tra elementi in aree di lavoro diverse. Quando si crea un collegamento tra gli elementi, i tipi di elemento non devono corrispondere per forza. Ad esempio, è possibile creare un collegamento in una lakehouse che punta ai dati in un data warehouse.
Quando si accede ai dati tramite un collegamento a un'altra sede OneLake, l'identità dell'utente chiamante verrà utilizzata per autorizzare l'accesso ai dati nel percorso di destinazione del collegamento*. L'utente deve disporre delle autorizzazioni nella posizione di destinazione per leggere i dati.
Importante
Quando si accede ai collegamenti tramite modelli semantici di Power BI o T-SQL, l'identità dell'utente chiamante non viene passata alla destinazione del collegamento. Viene invece passata l'identità del proprietario dell'elemento chiamante, delegando l'accesso all'utente chiamante.
Collegamenti ADLS
È possibile anche creare collegamenti agli account di archiviazione di ADLS Gen2. Quando si creano collegamenti ad ADLS, il percorso di destinazione può puntare a qualsiasi cartella all'interno dello spazio dei nomi gerarchico. Come minimo, il percorso di destinazione deve includere un nome contenitore.
Accesso
I collegamenti ADLS devono puntare all'endpoint DFS per l'account di archiviazione.
Esempio: https://accountname.dfs.core.windows.net/
Se l'account di archiviazione è protetto da un firewall di archiviazione, è possibile configurare un accesso attendibile al servizio. Vedere Accesso all'area di lavoro attendibile
Autorizzazione
I collegamenti ADLS usano un modello di autorizzazione delegata. In questo modello, l'autore dei collegamenti specifica una credenziale per il collegamento ADLS e l'intero accesso a tale collegamento è autorizzato usando tale credenziale. I tipi delegati supportati sono account aziendale, chiave dell'account, firma di accesso condiviso (SAS) ed entità servizio.
- Account aziendale - deve disporre del ruolo Lettore dati BLOB di archiviazione, Collaboratore ai dati BLOB di archiviazione o Proprietario dei dati BLOB di archiviazione nell'account di archiviazione
- Firma di accesso condiviso (SAS) - deve includere almeno le autorizzazioni seguenti: Lettura, Elenco ed Esecuzione
- Entità servizio - deve disporre del ruolo Lettore dati BLOB di archiviazione, Collaboratore ai dati BLOB di archiviazione o Proprietario dei dati BLOB di archiviazione nell'account di archiviazione
- Identità dell'area di lavoro: deve avere lettore dati BLOB di archiviazione, collaboratore ai dati dei BLOB di archiviazione o ruolo proprietario dei dati blob di archiviazione nell'account di archiviazione
Nota
È necessario che gli spazi dei nomi gerarchici siano abilitati nell'account di archiviazione di ADLS Gen 2.
Collegamenti a S3
È possibile anche creare collegamenti agli account Amazon S3. Quando si creano collegamenti ad Amazon S3, il percorso di destinazione deve contenere almeno un nome di bucket. S3 non supporta in modo nativo gli spazi dei nomi gerarchici, ma è possibile usare i prefissi per simulare una struttura di directory. È possibile includere prefissi nel percorso di collegamento per restringere ulteriormente l'ambito dei dati accessibili tramite il collegamento. Quando si accede ai dati tramite un collegamento S3, i prefissi vengono rappresentati come cartelle.
Accesso
I collegamenti S3 devono puntare all'endpoint https per il bucket S3.
Esempio: https://bucketname.s3.region.amazonaws.com/
Nota
Non è necessario disabilitare l'impostazione Blocca accesso pubblico S3 per l'account S3 affinché il collegamento S3 funzioni.
L'accesso all'endpoint S3 non deve essere bloccato da un firewall di archiviazione o da un cloud privato virtuale.
Autorizzazione
I collegamenti S3 usano un modello di autorizzazione delegata. In questo modello, l'autore dei collegamenti specifica una credenziale per il collegamento S3 e l'intero accesso a tale collegamento è autorizzato usando tale credenziale. Le credenziali delegate supportate sono chiave e segreto per un utente IAM.
L'utente IAM deve disporre delle autorizzazioni seguenti per il bucket a cui punta il collegamento.
S3:GetObjectS3:GetBucketLocationS3:ListBucket
Nota
I collegamenti S3 sono di sola lettura. Non supportano operazioni di scrittura indipendentemente dalle autorizzazioni per l'utente IAM.
Collegamenti a Google Cloud Storage
È possibile creare collegamenti a Google Cloud Storage (GCS) usando l'API XML per GCS. Quando si creano collegamenti a Google Cloud Storage, il percorso di destinazione deve contenere almeno un nome di bucket. È possibile anche limitare l'ambito del collegamento specificando ulteriormente il prefisso o la cartella da puntare all'interno della gerarchia di archiviazione.
Accesso
Quando si configura la connessione per una scorciatoia GCS, è possibile specificare l'endpoint globale del servizio di archiviazione o usare un endpoint specifico del bucket.
- Esempio di endpoint globale:
https://storage.googleapis.com - Esempio di endpoint specifico del bucket:
https://<BucketName>.storage.googleapis.com
Autorizzazione
I collegamenti GCS usano un modello di autorizzazione delegata. In questo modello, l'autore dei collegamenti specifica una credenziale per il collegamento GCS e l'intero accesso a tale collegamento è autorizzato usando tale credenziale. Le credenziali delegate supportate sono una chiave HMAC e un segreto per un account del servizio o un account utente.
L'account deve disporre dell'autorizzazione per accedere ai dati all'interno del bucket GCS. Se nella connessione per il collegamento è stato usato l'endpoint specifico del bucket, l'account deve disporre delle autorizzazioni seguenti:
storage.objects.getstoage.objects.list
Se nella connessione per il collegamento è stato usato l'endpoint globale, l'account deve disporre anche dell'autorizzazione seguente:
storage.buckets.list
Nota
I collegamenti GCS sono di sola lettura. Non supportano operazioni di scrittura indipendentemente dalle autorizzazioni per l'account usato.
Collegamenti a Dataverse
L'integrazione diretta di Microsoft Dataverse con Microsoft Fabric consente alle organizzazioni di estendere applicazioni aziendali e processi di business di Dynamics 365 in Fabric. Questa integrazione viene eseguita tramite collegamenti, che possono essere creati in due modi: tramite il portale di PowerApps maker o direttamente tramite Fabric.
Creazione di collegamenti tramite il portale di PowerApps Maker
Gli utenti autorizzati di PowerApps possono accedere al portale di PowerApps maker e usare la funzionalità Collega a Microsoft Fabric. Da questa singola azione viene creata una lakehouse in Fabric e i collegamenti vengono generati automaticamente per ogni tabella nell'ambiente Dataverse. Per ulteriori informazioni, consultare Integrazione diretta di Dataverse con Microsoft Fabric.
Creazione di collegamenti tramite Fabric
Gli utenti di Fabric possono anche creare collegamenti a Dataverse. Dall'esperienza utente Crea collegamenti, gli utenti possono selezionare Dataverse, specificare l'URL dell'ambiente ed esplorare le tabelle disponibili. Questa esperienza consente agli utenti di scegliere in modo selettivo quali tabelle inserire in Fabric anziché inserirle tutte.
Nota
Le tabelle di Dataverse devono essere disponibili prima di tutto in Dataverse Managed Lake prima che siano visibili nell'esperienza utente Crea collegamenti Fabric. Se le tabelle non sono visibili da Fabric, usare la funzionalità Collega a Microsoft Fabric dal portale di PowerApps maker.
Autorizzazione
I collegamenti Dataverse usano un modello di autorizzazione delegata. In questo modello, l'autore dei collegamenti specifica una credenziale per il collegamento a Dataverse e l'intero accesso a tale collegamento è autorizzato usando tale credenziale. La credenziale delegata supportata è Account aziendale (OAuth2). L'account aziendale deve disporre dell'autorizzazione di amministratore del sistema per accedere ai dati in Dataverse Managed Lake.
Nota
Le entità servizio aggiunte all'area di lavoro Fabric devono disporre del ruolo di amministratore per autorizzare il collegamento Dataverse.
Memorizzazione nella cache
La memorizzazione dei collegamenti nella cache può essere usata per ridurre i costi di uscita associati all'accesso ai dati tra cloud. Man mano che i file vengono letti tramite un collegamento esterno, vengono archiviati in una cache per l'area di lavoro Fabric. Le richieste di lettura successive vengono gestite dalla cache anziché dal provider di archiviazione remota. I file memorizzati nella cache hanno un periodo di conservazione di 24 ore. Ogni volta che si accede al file, il periodo di conservazione viene ripristinato. Se il file nel provider di archiviazione remota è più recente del file nella cache, la richiesta viene servita dal provider di archiviazione remota e il file aggiornato verrà archiviato nella cache. Se non è stato eseguito l'accesso a un file per più di 24 ore, viene eliminato dalla cache. I singoli file di dimensioni superiori a 1 GB non vengono memorizzati nella cache.
Nota
La memorizzazione dei collegamenti nella cache è attualmente supportata solo per i collegamenti compatibili con GCS, S3 e S3.
Per abilitare la memorizzazione dei collegamenti nella cache, aprire il pannello Impostazioni area di lavoro. Scegliere la scheda OneLake. Attivare o disattivare l'impostazione della cache e selezionare Salva.

Utilizzo delle connessioni cloud da parte dei collegamenti
L'autorizzazione dei collegamenti ADLS e S3 viene delegata tramite connessioni cloud. Quando si crea un nuovo collegamento ADLS o S3, è possibile creare una nuova connessione o selezionare una connessione esistente per l'origine dati. L'impostazione di una connessione per un collegamento è un'operazione di associazione. Solo gli utenti con autorizzazione per la connessione possono eseguire l'operazione di associazione. Se non si dispone delle autorizzazioni per la connessione, non è possibile creare nuovi collegamenti usando tale connessione.
Sicurezza dei collegamenti
Sono necessarie determinate autorizzazioni per gestire e usare i collegamenti. La Sicurezza dei collegamenti OneLake esamina le autorizzazioni necessarie per creare collegamenti e accedere ai dati usandoli.
In che modo i collegamenti gestiscono le eliminazioni?
I collegamenti non eseguono eliminazioni a catena. Quando si esegue un'operazione di eliminazione su un collegamento, si elimina solo l'oggetto collegamento. I dati nella destinazione di collegamento rimangono invariati. Tuttavia, se si esegue un'operazione di eliminazione di un file o una cartella all'interno di un collegamento e si dispone delle autorizzazioni nella destinazione di collegamento per eseguire tale operazione, i file e/o le cartelle vengono eliminati nella destinazione. Nell'esempio seguente viene illustrato questo argomento.
Esempi di eliminazione
L'utente A ha una lakehouse con il percorso seguente:
MyLakehouse\Files\MyShortcut\Foo\Bar
MyShortcut è un collegamento che punta a un account ADLS Gen2 che contiene le directory Foo\Bar.
Eliminazione di un oggetto collegamento
L'utente A esegue un'operazione di eliminazione nel percorso seguente:
MyLakehouse\Files\MyShortcut
In questo caso, MyShortcut viene eliminato dalla lakehouse. I collegamenti non eseguono eliminazioni a catena, pertanto i file e le directory nell'account ADLS Gen2 Foo\Bar rimangono invariati.
Eliminazione del contenuto a cui fa riferimento un collegamento
L'utente A esegue un'operazione di eliminazione nel percorso seguente:
MyLakehouse\Files\MyShortcut\Foo\Bar
In questo caso, se l'utente A dispone delle autorizzazioni di scrittura nell'account ADLS Gen2, la directory Bar viene eliminata dall'account ADLS Gen2.
Visualizzazione di derivazione dell'area di lavoro
Quando si creano collegamenti tra più elementi di Fabric all'interno di un'area di lavoro, è possibile visualizzare le relazioni di collegamento tramite la visualizzazione di derivazione dell'area di lavoro. Selezionare il pulsante Visualizzazione di derivazione ( ) nell'angolo superiore destro di Esplora aree di lavoro.
) nell'angolo superiore destro di Esplora aree di lavoro.

Nota
La visualizzazione di derivazione ha come ambito una singola area di lavoro. I collegamenti alle posizioni esterne all'area di lavoro selezionata non verranno visualizzati.
Limitazioni e considerazioni
- Il numero massimo di collegamenti per ogni elemento di Fabric è 100.000. In questo contesto, il termine articolo si riferisce a: app, lakehouse, warehouse, report e altro ancora.
- Il numero massimo di collegamenti in un singolo percorso di OneLake è 10.
- Il numero massimo di collegamenti diretti ai collegamenti è 5.
- I percorsi di destinazione dei collegamenti ADLS e S3 non possono contenere caratteri riservati dalla RFC 3986, sezione 2.2. Per i caratteri consentiti, consultare la RFC 3968, sezione 2.3.
- I nomi dei collegamenti OneLake, i percorsi padre e i percorsi di destinazione non possono contenere i caratteri "%" o "+".
- I collegamenti non supportano caratteri non latini.
- La copia dell’API BLOB non è supportata per i collegamenti ADLS o S3.
- La funzione Copia non funziona per i collegamenti che puntano direttamente ai contenitori ADLS. È consigliabile creare collegamenti ADLS a una directory di almeno un livello inferiore a un contenitore.
- Non è possibile creare ulteriori collegamenti all'interno di collegamenti ADLS o S3.
- La derivazione per i collegamenti ai data warehouse e ai modelli semantici non è attualmente disponibile.
- Un collegamento Fabric si sincronizza con l'origine quasi istantaneamente, ma il tempo di propagazione può variare a causa delle prestazioni dell'origine dati, delle visualizzazioni memorizzate nella cache o dei problemi di connettività di rete.
- L'API Tabella può richiedere fino a un minuto per riconoscere i nuovi collegamenti.
- I collegamenti a OneLake non supportano ancora le connessioni agli account di archiviazione ADLS Gen2 utilizzando endpoint privati gestiti. Per ulteriori informazioni, vedere endpoint privati gestiti per Fabric.