Flussi di lavoro MLOps in Azure Databricks
Questo articolo descrive come usare MLOps nella piattaforma Databricks per ottimizzare le prestazioni e l'efficienza a lungo termine dei sistemi di Machine Learning (ML). Include raccomandazioni generali per un'architettura MLOps e descrive un flusso di lavoro generalizzato che utilizza la piattaforma Databricks e che è possibile usare come modello per il processo di sviluppo-produzione di ML. Per le modifiche di questo flusso di lavoro per le applicazioni LLMOps, vedere Flussi di lavoro LLMOps.
Per altri dettagli, vedere Il Big Book di MLOps.
Che cos'è MLOps?
MLOps è un set di processi e passaggi automatizzati per la gestione di codice, dati e modelli per migliorare le prestazioni, la stabilità e l'efficienza a lungo termine dei sistemi di Machine Learning. Combina DevOps, DataOps e ModelOps.
Le risorse di ML, come codice, dati e modelli, sono sviluppate in fasi che vanno dalle prime fasi di sviluppo, che non hanno limitazioni di accesso e non sono rigorosamente testate, passando per una fase intermedia di test, fino alla fase finale di produzione, che è strettamente controllata. La piattaforma Databricks consente di gestire queste risorse su un'unica piattaforma con un controllo unificato degli accessi. È possibile sviluppare applicazioni di dati e applicazioni di ML sulla stessa piattaforma, riducendo i rischi e i ritardi associati allo spostamento dei dati.
Consigli generali per MLOps
Questa sezione contiene alcuni consigli generali per MLOps in Databricks, con collegamenti ad altre informazioni.
Creare un ambiente separato per ogni fase
Un ambiente di esecuzione è il luogo in cui i modelli e i dati vengono creati o utilizzati dal codice. Ogni ambiente di esecuzione è costituito da istanze di calcolo, runtime e librerie e processi automatizzati.
Databricks consiglia di creare ambienti separati per le diverse fasi del codice e dello sviluppo di modelli di Machine Learning con transizioni chiaramente definite tra le fasi. Il flusso di lavoro descritto in questo articolo segue questo processo, usando i nomi comuni per le fasi:
È anche possibile usare altre configurazioni per soddisfare le esigenze specifiche dell'organizzazione.
Controllo di accesso e controllo delle versioni
Il controllo di accesso e il controllo delle versioni sono componenti chiave di qualsiasi processo operativo software. Databricks consiglia quanto segue:
- Utilizzare Git per il controllo della versione. Le pipeline e il codice devono essere archiviati in Git per il controllo della versione. Lo spostamento della logica ML tra le fasi può essere interpretato come lo spostamento di codice dal ramo di sviluppo al ramo di staging fino al ramo di rilascio. Usare cartelle Git di Databricks per l'integrazione con il provider Git e sincronizzare notebook e codice sorgente con le aree di lavoro di Databricks. Databricks offre anche strumenti aggiuntivi per l'integrazione git e il controllo della versione; vedere Strumenti di sviluppo locale.
- Archivia i dati in un'architettura di tipo lakehouse utilizzando le tabelle Delta. I dati devono essere archiviati in un'architettura lakehouse nell'account cloud. Sia i dati non elaborati che le tabelle delle funzionalità devono essere archiviati come tabelle Delta con controlli di accesso per determinare chi può leggerli e modificarli.
- Gestire lo sviluppo dei modelli con MLflow. È possibile usare MLflow per tenere traccia del processo di sviluppo del modello e salvare snapshot del codice, parametri del modello, metriche e altri metadati.
- Usare i modelli nel catalogo Unity per gestire il ciclo di vita del modello. Usare Modelli in Unity Catalog per gestire il controllo delle versioni dei modelli, la governance e lo stato della distribuzione.
Distribuire codice, non modelli
Nella maggior parte delle situazioni, Databricks consiglia di promuovere il codice, piuttosto che i modelli, da un ambiente all'altro durante il processo di sviluppo ML. Lo spostamento delle risorse del progetto in questo modo garantisce che tutto il codice del processo di sviluppo ML sia sottoposto agli stessi processi di revisione del codice e di test di integrazione. Inoltre, garantisce che la versione di produzione del modello sia addestrata sul codice di produzione. Per una descrizione più dettagliata delle opzioni e dei compromessi, vedere Criteri di distribuzione dei modelli.
Flusso di lavoro MLOps consigliato
Le sezioni seguenti descrivono un tipico flusso di lavoro MLOps, che copre ognuna delle tre fasi: sviluppo, gestione temporanea e produzione.
Questa sezione utilizza i termini “scienziato dei dati” e “tecnico di ML” come archetipi; i ruoli e le responsabilità specifiche nel flusso di lavoro MLOps variano a seconda dei team e delle organizzazioni.
Fase di sviluppo
L'obiettivo della fase di sviluppo è la sperimentazione. I data scientist sviluppano funzionalità e modelli ed eseguono esperimenti per ottimizzare le prestazioni del modello. L'output del processo di sviluppo è il codice della pipeline di Machine Learning che può includere il calcolo delle funzionalità, il training del modello, l'inferenza e il monitoraggio.
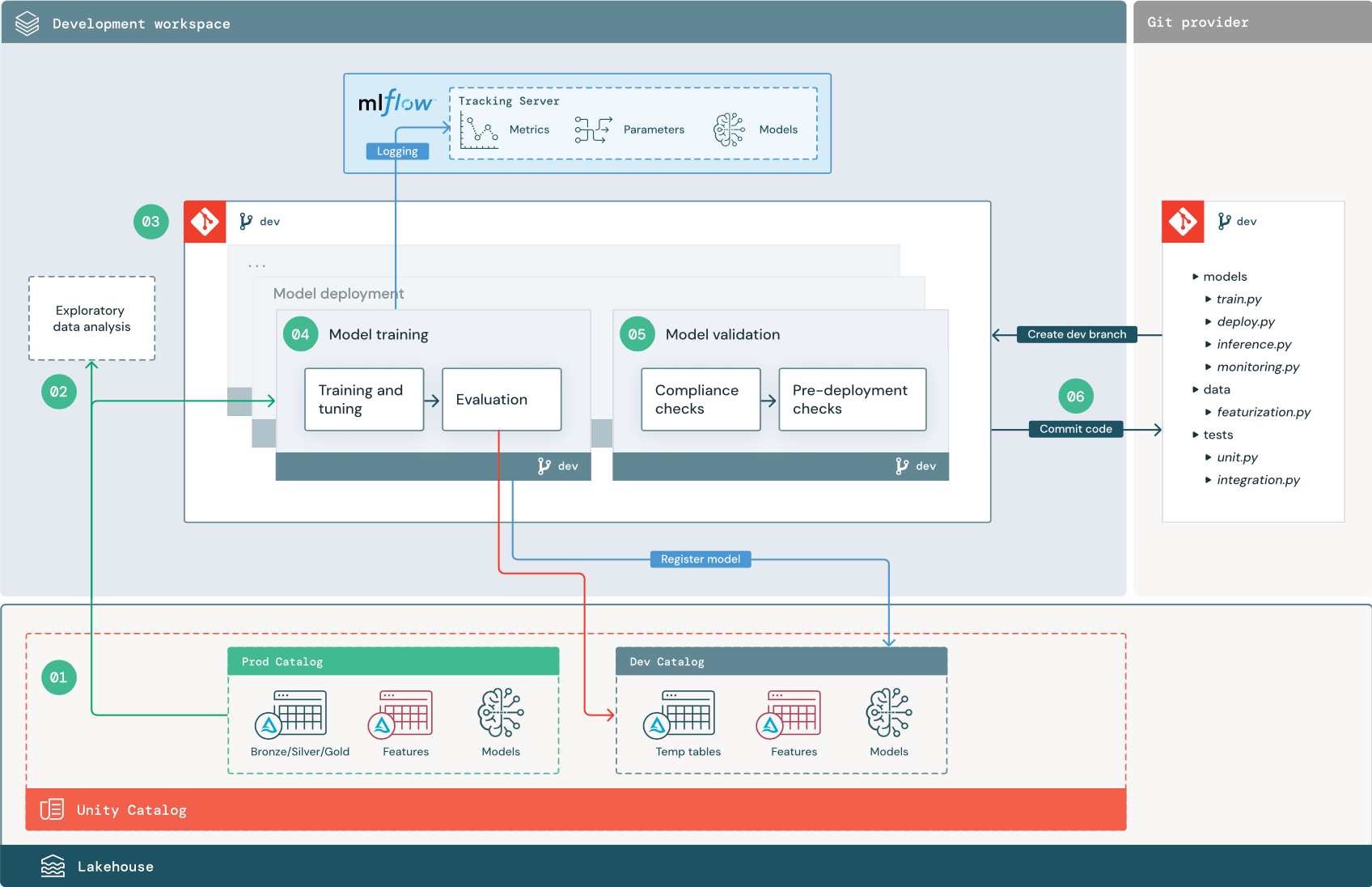
I passaggi numerati corrispondono ai numeri indicati nel diagramma.
1. Origini dati
L'ambiente di sviluppo è rappresentato dal catalogo di sviluppo in Unity Catalog. I data scientist hanno accesso in lettura/scrittura al catalogo di sviluppo durante la creazione di tabelle temporanee di dati e funzionalità nell'area di lavoro di sviluppo. I modelli creati nella fase di sviluppo vengono registrati nel catalogo di sviluppo.
Idealmente, gli scienziati dei dati che lavorano nell'area di lavoro di sviluppo hanno anche accesso in sola lettura ai dati di produzione nel catalogo di produzione. Consentire ai data scientist l'accesso in lettura ai dati di produzione, alle tabelle di inferenza e alle tabelle delle metriche nel catalogo prod consente loro di analizzare le stime e le prestazioni correnti del modello di produzione. Gli scienziati dei dati devono anche essere in grado di caricare modelli di produzione per la sperimentazione e l'analisi.
Se non è possibile concedere l'accesso in sola lettura al catalogo prod, è possibile scrivere uno snapshot dei dati di produzione nel catalogo di sviluppo per consentire ai data scientist di sviluppare e valutare il codice del progetto.
2. Analisi esplorativa dei dati
Gli scienziati dei dati esplorano e analizzano i dati in un processo interattivo iterativo usando i notebook. L'obiettivo è valutare se i dati disponibili hanno il potenziale per risolvere il problema aziendale. In questo passaggio, lo scienziato dei dati inizia a identificare le sottoattività di preparazione dei dati e di definizione delle funzionalità per il training del modello. Questo processo ad hoc in genere non fa parte di una pipeline che verrà implementata in altri ambienti di esecuzione.
AutoML accelera questo processo generando modelli di base per un set di dati. AutoML esegue e registra un set di versioni di valutazione e fornisce un notebook Python con il codice sorgente per ogni esecuzione di valutazione, in modo da poter esaminare, riprodurre e modificare il codice. AutoML calcola anche le statistiche di riepilogo sul set di dati e salva queste informazioni in un notebook che è possibile esaminare.
3. Codice
Il repository di codice contiene tutte le pipeline, i moduli e altri file di progetto per un progetto ML. Gli scienziati dei dati creano pipeline nuove o aggiornate in un ramo di sviluppo ("dev") del repository di progetti. A partire da EDA e dalle fasi iniziali di un progetto, gli scienziati dei dati devono lavorare in un repository per condividere il codice e tenere traccia delle modifiche.
4. Eseguire il training del modello (sviluppo)
I data scientists sviluppano la pipeline di addestramento del modello nell'ambiente di sviluppo, utilizzando tabelle dai cataloghi di sviluppo o produzione.
Questa pipeline include 2 attività:
training e ottimizzazione. Il processo di training registra i parametri, le metriche e gli artefatti del modello nel server MLflow Tracking. Dopo il training e l'ottimizzazione degli iperparametri, l'artefatto finale del modello viene registrato nel server di rilevamento per registrare un collegamento tra il modello, i dati di input su cui è stato eseguito il training e il codice usato per generarlo.
Valutazione. Valutare la qualità del modello testando i dati conservati. I risultati di questi test vengono registrati nel server di rilevamento MLflow. Lo scopo della valutazione è determinare se il modello appena sviluppato offre prestazioni migliori rispetto al modello di produzione corrente. Date autorizzazioni sufficienti, qualsiasi modello di produzione registrato nel catalogo prod può essere caricato nell'area di lavoro di sviluppo e confrontato con un modello appena sottoposto a training.
Se i requisiti di governance dell'organizzazione includono informazioni aggiuntive sul modello, è possibile salvarlo usando il rilevamento MLflow. Gli artefatti tipici sono descrizioni in testo normale e interpretazioni del modello, come i grafici prodotti da SHAP. Requisiti di governance specifici possono provenire da un responsabile della governance dei dati o da stakeholder aziendali.
L'output della pipeline di training del modello è un artefatto del modello di ML archiviato nel server di rilevamento MLflow per l'ambiente di sviluppo. Se la pipeline viene eseguita nell'area di lavoro di staging o di produzione, l'artefatto del modello viene archiviato nel server di rilevamento MLflow per tale area di lavoro.
Al termine del training del modello, registrare il modello nel Catalogo Unity. Configurare il codice della pipeline per registrare il modello nel catalogo corrispondente all'ambiente in cui è stata eseguita la pipeline del modello; in questo esempio, il catalogo di sviluppo.
Con l'architettura consigliata, si implementa un flusso di lavoro multitask Databricks in cui il primo task è la pipeline di training del modello, seguito dai task di convalida modello e di distribuzione modello. Il task di training del modello produce un URI del modello che può essere utilizzato dal task di convalida del modello. È possibile usare i valori dell'attività
5. Convalidare e implementare il modello (sviluppo)
Oltre alla pipeline di training dei modelli, nell'ambiente di sviluppo vengono sviluppate altre pipeline, come quelle per la convalida e per la distribuzione dei modelli.
Convalida del modello. La pipeline di convalida del modello accetta l'URI del modello dalla pipeline di training del modello, carica il modello dal catalogo unity ed esegue i controlli di convalida.
I controlli di convalida dipendono dal contesto. Possono includere controlli fondamentali, come la conferma del formato e dei metadati richiesti, e controlli più complessi che potrebbero essere richiesti per settori altamente regolamentati, come i controlli di conformità predefiniti e la conferma delle prestazioni del modello su sezioni dati selezionate.
La funzione primaria della pipeline di convalida del modello consiste nel determinare se un modello deve procedere al passaggio di distribuzione. Se il modello supera i controlli di pre-distribuzione, può essere assegnato l'alias "Challenger" nel Catalogo Unity. Se i controlli hanno esito negativo, il processo termina. È possibile configurare il flusso di lavoro per notificare agli utenti un errore di convalida. Vedere Aggiungere notifiche in un processo.
Distribuzione di modelli. La pipeline di distribuzione del modello in genere promuove direttamente il nuovo modello "Challenger" allo stato di "Campione" usando un aggiornamento tramite alias, oppure facilita un confronto tra il modello "Campione" esistente e il nuovo modello "Challenger". Questa pipeline può anche configurare qualsiasi infrastruttura di inferenza necessaria, ad esempio endpoint di gestione dei modelli. Per una descrizione dettagliata dei passaggi coinvolti nella pipeline di distribuzione dei modelli, vedere Produzione.
6. Eseguire il commit del codice
Dopo aver sviluppato codice per il training, la convalida, la distribuzione e altre pipeline, lo scienziato dei dati o il tecnico di ML esegue il commit delle modifiche del ramo di sviluppo nel controllo del codice sorgente.
Fase di gestione temporanea
L'obiettivo di questa fase è testare il codice della pipeline ML per assicurarsi che sia pronto per la produzione. Tutto il codice della pipeline ML viene testato in questa fase, incluso il codice per il training del modello, nonché le pipeline di ingegneria delle funzionalità, il codice di inferenza e così via.
I tecnici di ML creano una pipeline CI per implementare i test di unità e di integrazione eseguiti in questa fase. L'output del processo di gestione temporanea è un ramo di rilascio che attiva il sistema CI/CD per avviare la fase di produzione.
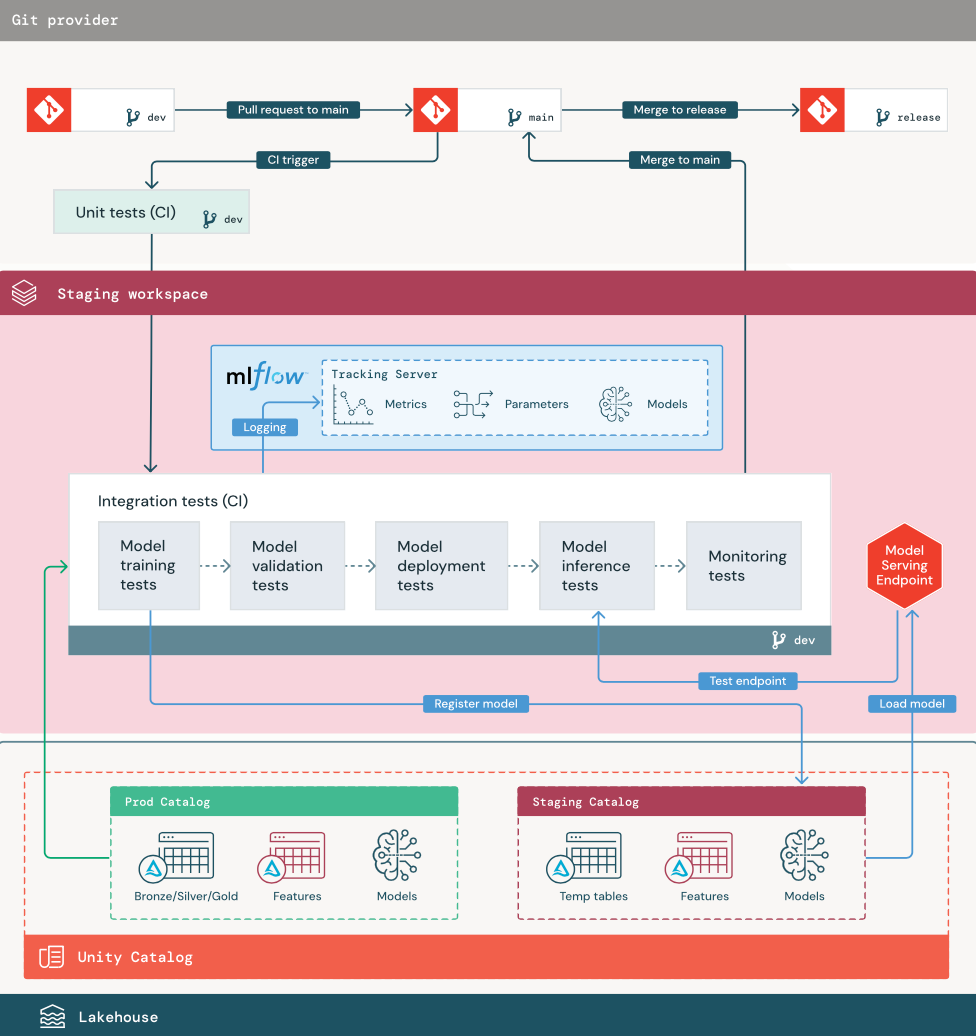
1. Dati
L'ambiente di gestione temporanea deve avere un proprio catalogo in Unity Catalog per testare le pipeline di Ml e registrare i modelli nel catalogo Unity. Questo catalogo viene visualizzato come catalogo "staging" nel diagramma. Gli asset scritti in questo catalogo sono in genere temporanei e conservati solo fino al completamento dei test. L'ambiente di sviluppo può anche richiedere l'accesso al catalogo di staging a scopo di debug.
2. Unire il codice
Gli scienziati dei dati sviluppano la pipeline di addestramento del modello nell'ambiente di sviluppo usando tabelle dai cataloghi di sviluppo o produzione.
Richiesta pull. Il processo di distribuzione inizia quando viene creata una richiesta pull nel ramo principale del progetto nel controllo del codice sorgente.
Unit test (CI). La richiesta pull compila automaticamente il codice sorgente e attiva gli unit test. Se gli unit test hanno esito negativo, la richiesta pull viene rifiutata.
Gli unit test fanno parte del processo di sviluppo software e vengono continuamente eseguiti e aggiunti alla codebase durante lo sviluppo di qualsiasi codice. L'esecuzione di unit test come parte di una pipeline CI garantisce che le modifiche apportate in un ramo di sviluppo non interrompano le funzionalità esistenti.
3. Test di integrazione (CI)
Il processo CI esegue quindi i test di integrazione. I test di integrazione eseguono tutte le pipeline (tra cui ingegneria delle funzionalità, training del modello, inferenza e monitoraggio) per garantire che funzionino correttamente insieme. L'ambiente di gestione temporanea deve corrispondere il più possibile all'ambiente di produzione.
Se si sta distribuendo un'applicazione ML con inferenza in tempo reale, è necessario creare e testare l'infrastruttura di gestione nell'ambiente di gestione temporanea. Ciò comporta l'attivazione della pipeline di distribuzione del modello, che crea un endpoint di gestione nell'ambiente di gestione temporanea e carica un modello.
Per ridurre il tempo necessario all'esecuzione dei test di integrazione, alcune fasi possono implementare un compromesso tra la fedeltà dei test e la velocità o il costo. Ad esempio, se i modelli sono costosi o dispendiosi in termini di tempo per il training, è possibile usare piccoli sottoinsiemi di dati o eseguire un minor numero di iterazioni di training. Per la gestione del modello, a seconda dei requisiti di produzione è possibile eseguire test di carico su larga scala nei test di integrazione, oppure testare semplicemente processi batch di piccole dimensioni o richieste a un endpoint temporaneo.
4. Eseguire il merge nel ramo di gestione temporanea
Se tutti i test vengono superati, il nuovo codice viene unito nel ramo principale del progetto. Se i test hanno esito negativo, il sistema CI/CD deve inviare notifiche agli utenti e pubblicare i risultati nella richiesta pull.
È possibile pianificare test di integrazione periodici nel ramo principale. Questa è una buona idea se il ramo viene aggiornato di frequente con richieste pull simultanee da più utenti.
5. Creare un ramo di rilascio
Dopo che i test CI sono stati superati e il ramo di sviluppo viene unito nel ramo principale, il tecnico ml crea un ramo di rilascio, che attiva il sistema CI/CD per aggiornare i processi di produzione.
Fase di produzione
I tecnici ml possiedono l'ambiente di produzione in cui vengono distribuite ed eseguite le pipeline di Machine Learning. Queste pipeline attivano il training del modello, convalidano e distribuiscono nuove versioni del modello, pubblicano stime in tabelle o applicazioni downstream e monitorano l'intero processo per evitare riduzione delle prestazioni e instabilità.
Gli scienziati dei dati in genere non hanno accesso in scrittura o in calcolo nell'ambiente di produzione. È tuttavia importante avere visibilità per testare i risultati, i log, gli artefatti del modello, lo stato della pipeline di produzione e le tabelle di monitoraggio. Questa visibilità consente loro di identificare e diagnosticare i problemi nell'ambiente di produzione e di confrontare le prestazioni dei nuovi modelli con i modelli attualmente in produzione. È possibile concedere ai data scientist l'accesso in sola lettura agli asset nel catalogo di produzione per questi scopi.
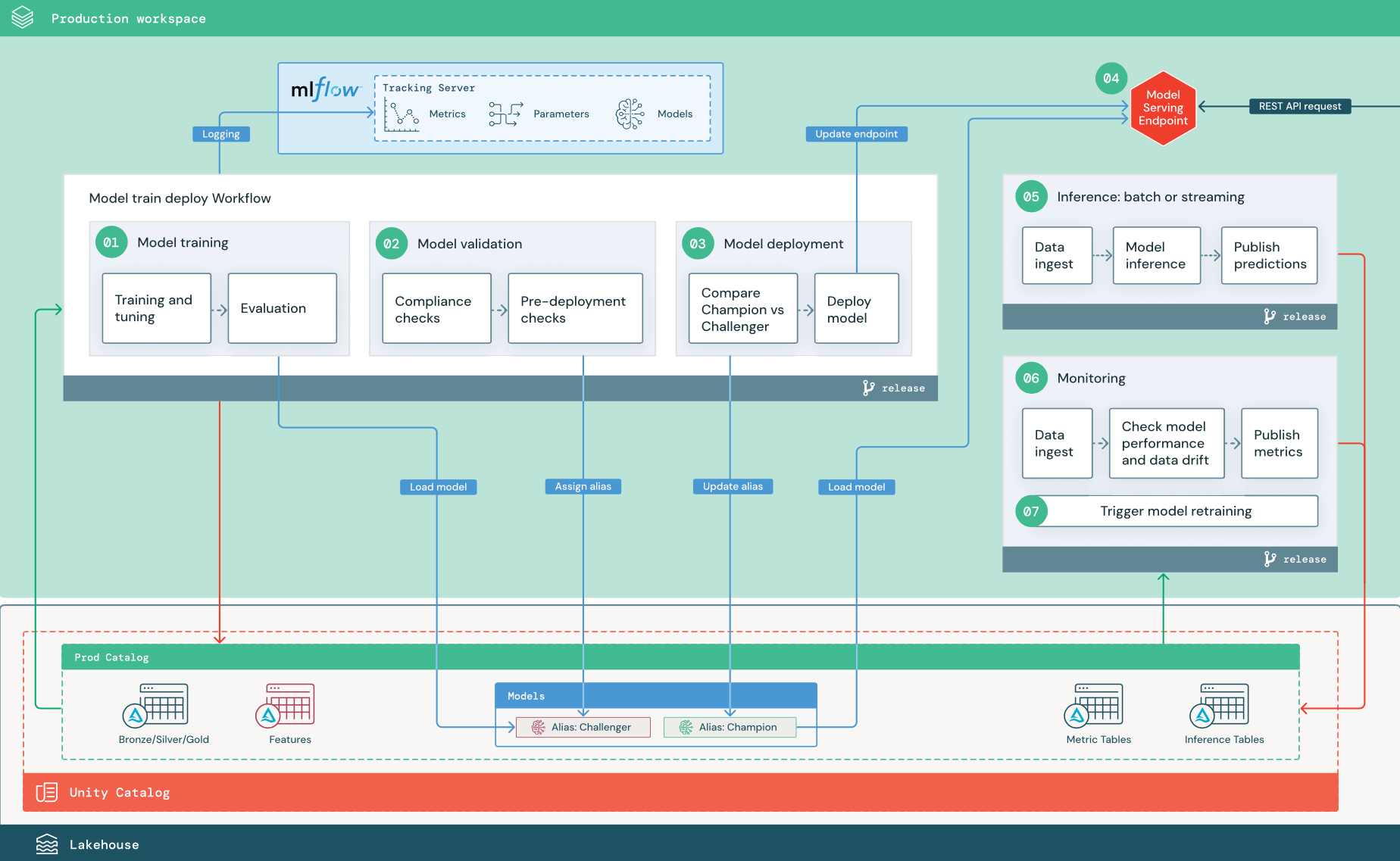
I passaggi numerati corrispondono ai numeri indicati nel diagramma.
1 - Eseguire il training del modello
Questa pipeline può essere attivata da modifiche al codice o da processi automatici di ripetizione del training. In questo passaggio, le tabelle del catalogo di produzione vengono usate per i passaggi seguenti.
training e ottimizzazione. Durante il processo di training, i log vengono registrati nel server di rilevamento MLflow dell'ambiente di produzione. Questi log includono metriche del modello, parametri, tag e il modello stesso. Se si usano tabelle delle funzionalità, il modello viene registrato in MLflow usando il client databricks Feature Store, che crea un pacchetto del modello con informazioni di ricerca delle funzionalità usate in fase di inferenza.
Durante lo sviluppo, gli scienziati dei dati possono testare molti algoritmi e iperparametri. Nel codice del training di produzione è comune considerare solo le opzioni che offrono le prestazioni migliori. Limitare l'ottimizzazione in questo modo permette di risparmiare tempo e può ridurre la varianza dell'ottimizzazione nella ripetizione automatica del training.
Se i data scientist hanno accesso in sola lettura al catalogo di produzione, possono determinare il set ottimale di iperparametri per un modello. In questo caso, la pipeline di training del modello distribuita nell'ambiente di produzione può essere eseguita usando il set selezionato di iperparametri, in genere incluso nella pipeline come file di configurazione.
Valutazione. La qualità del modello viene valutata mediante test su dati di produzione non utilizzati. I risultati di questi test vengono registrati nel server di rilevamento MLflow. Questo passaggio usa le metriche di valutazione specificate degli scienziati dei dati nella fase di sviluppo. Queste metriche possono includere codice personalizzato.
Registrare un modello. Al termine dell'addestramento del modello, il file di modello viene salvato come versione registrata nel percorso specificato per il modello nel catalogo di produzione in Unity Catalog. Il task di training del modello produce un URI del modello che può essere utilizzato dal task di convalida del modello. È possibile usare i valori dell'attività
per passare questo URI al modello.
2. Convalidare il modello
Questa pipeline usa l'URI del modello del passaggio 1 e carica il modello dal catalogo Unity. Esegue quindi una serie di controlli di convalida. Questi controlli dipendono dall'organizzazione e dallo use case, e possono includere elementi come la convalida del formato di base e dei metadati, le valutazioni delle prestazioni sulle sezioni di dati selezionate e la conformità ai requisiti dell'organizzazione, ad esempio i controlli di conformità per i tag o la documentazione.
Se il modello supera correttamente tutti i controlli di convalida, è possibile assegnare l'alias "Challenger" alla versione del modello nel catalogo Unity. Se il modello non supera tutti i controlli di convalida, il processo viene chiuso e gli utenti possono ricevere automaticamente una notifica. È possibile usare i tag per aggiungere attributi chiave-valore a seconda del risultato di questi controlli di convalida. Ad esempio, è possibile creare un tag "model_validation_status" e impostare il valore su "PENDING" durante l'esecuzione dei test e quindi aggiornarlo a "PASS" o "FAILED" al termine della pipeline.
Poiché il modello è registrato in Unity Catalog, i data scientist che lavorano nell'ambiente di sviluppo possono caricare questa versione del modello dal catalogo di produzione per verificare se la convalida del modello non riesce. Indipendentemente dal risultato, i risultati vengono registrati nel modello registrato nel catalogo di produzione usando annotazioni per la versione del modello.
3. Distribuire il modello
Analogamente alla pipeline di convalida, la pipeline di distribuzione del modello dipende dall'organizzazione e dallo use case. Questa sezione presuppone che sia stato assegnato al modello appena convalidato l'alias "Challenger" e che al modello di produzione esistente sia stato assegnato l'alias "Champion". Il primo passaggio prima di il nuovo modello consiste nel verificare che esegua almeno il modello di produzione corrente.
Confrontare il modello "CHALLENGER" con il modello "CHAMPION". È possibile eseguire questo confronto offline o online. Un confronto offline valuta entrambi i modelli rispetto a un set di dati in uscita e tiene traccia dei risultati usando il server MLflow Tracking. Per la gestione dei modelli in tempo reale, è possibile eseguire confronti online più lunghi, ad esempio test A/B o un'implementazione graduale del nuovo modello. Se la versione del modello "Challenger" offre prestazioni migliori nel confronto, sostituisce l'alias "Champion" corrente.
Mosaic AI Model Serving e Databricks Lakehouse Monitoring consentono di raccogliere e monitorare automaticamente le tabelle di inferenza che contengono dati di richiesta e risposta per un endpoint.
Se non esiste un modello "Champion", è possibile confrontare il modello "Challenger" con un'euristica aziendale o un'altra soglia come baseline.
Il processo descritto di seguito è completamente automatizzato. Se sono necessari passaggi di approvazione manuali, è possibile configurarli usando le notifiche del flusso di lavoro o i callback CI/CD dalla pipeline di distribuzione del modello.
Distribuire il modello. Le pipeline di inferenza batch o di streaming possono essere configurate per l'uso del modello con l'alias "Campione". Per i casi d'uso in tempo reale, è necessario configurare l'infrastruttura per distribuire il modello come endpoint API REST. È possibile creare e gestire questo endpoint usando Mosaic AI Model Serving. Se un endpoint è già in uso per il modello corrente, è possibile aggiornare l'endpoint con il nuovo modello. Mosaic AI Model Serving esegue un aggiornamento senza tempi di inattività mantenendo la configurazione esistente in esecuzione fino a quando il nuovo non è pronto.
4. Gestione dei modelli
Quando si configura un endpoint Model Serving, specificare il nome del modello nel catalogo unity e la versione da gestire. Se è stato eseguito il training della versione del modello usando le funzionalità delle tabelle nel catalogo di Unity, il modello archivia le dipendenze per le funzionalità e le funzioni. La Gestione dei modelli usa automaticamente questo grafo delle dipendenze per cercare le caratteristiche da archivi online appropriati in fase di inferenza. Questo approccio può essere usato anche per applicare funzioni per la pre-elaborazione dei dati o per calcolare le caratteristiche su richiesta durante l'assegnazione dei punteggi del modello.
È possibile creare un singolo endpoint con più modelli e specificare la suddivisione del traffico dell'endpoint tra questi modelli, consentendo di effettuare confronti online tra “Champion” e “Challenger”.
5. Inferenza: batch o streaming
La pipeline di inferenza legge i dati più recenti dal catalogo di produzione, esegue funzioni per calcolare le funzionalità su richiesta, carica il modello "Campione", assegna un punteggio ai dati e restituisce stime. L'inferenza di batch o di streaming è in genere l'opzione più conveniente per una produttività più elevata e use case di latenza più elevati. Per gli scenari in cui sono necessarie stime a bassa latenza, ma le stime possono essere calcolate offline, queste stime batch possono essere pubblicate in un archivio chiave-valore online, ad esempio DynamoDB o Cosmos DB.
Il modello registrato in Unity Catalog fa riferimento al relativo alias. La pipeline di inferenza è configurata per caricare e applicare la versione del modello "Champion". Se la versione "Champion" viene aggiornata a una nuova versione del modello, la pipeline di inferenza usa automaticamente la nuova versione per l'esecuzione successiva. In questo modo il passaggio di distribuzione modello è separato dalle pipeline di inferenza.
I processi Batch in genere pubblicano stime in tabelle nel catalogo di produzione, in file flat o tramite una connessione JDBC. I processi di streaming in genere pubblicano previsioni sulle tabelle di Unity Catalog o nelle code di messaggistica come Apache Kafka.
6. Monitoraggio Lakehouse
Il Monitoraggio Lakehouse monitora le proprietà statistiche, ad esempio la deriva dei dati e le prestazioni del modello, dei dati di input e delle previsioni del modello. È possibile creare avvisi in base a queste metriche o pubblicarli nei dashboard.
- Inserimento dati. Questa pipeline legge i log da batch, streaming o inferenza online.
- Controllare l'accuratezza e la deriva dei dati. La pipeline calcola le metriche relative ai dati di input, alle previsioni del modello e alle prestazioni dell'infrastruttura. Gli scienziati dei dati specificano le metriche dei dati e del modello durante lo sviluppo e i tecnici di ML specificano le metriche dell'infrastruttura. È anche possibile definire metriche personalizzate con il Monitoraggio Lakehouse.
- Pubblicare le metriche e configurare gli avvisi. La pipeline scrive in tabelle nel catalogo di produzione per l'analisi e la creazione di report. È necessario configurare queste tabelle in modo che siano leggibili dall'ambiente di sviluppo in modo che i data scientist abbiano accesso per l'analisi. È possibile usare Databricks SQL per creare dashboard di monitoraggio per tenere traccia delle prestazioni del modello e configurare il processo di monitoraggio o lo strumento dashboard per inviare una notifica quando una metrica supera una soglia specificata.
- Attivare la ripetizione del training del modello. Quando le metriche di monitoraggio indicano problemi di prestazioni o modifiche nei dati di input, lo scienziato dei dati potrebbe dover sviluppare una nuova versione del modello. È possibile configurare gli avvisi SQL per inviare notifiche ai data scientist in questo caso.
7. Ripetizione del training
Questa architettura supporta la ripetizione automatica del training usando la stessa pipeline di training del modello precedente. Databricks consiglia di iniziare con il training pianificato periodico e di passare alla ripetizione del training mediante attivazione quando necessario.
- Pianificati. Se sono disponibili regolarmente nuovi dati, è possibile creare un lavoro pianificato per eseguire il codice di training del modello sugli ultimi dati disponibili. Vedere Automazione dei processi con pianificazioni e trigger
- Attivato. Se la pipeline di monitoraggio può identificare i problemi di prestazioni del modello e inviare avvisi, può anche attivare la ripetizione del training. Ad esempio, se la distribuzione dei dati in ingresso cambia in modo significativo o se le prestazioni del modello peggiorano, il training automatico e la ridistribuzione possono migliorare le prestazioni del modello con un intervento umano minimo. Questa operazione può essere ottenuta tramite un avviso SQL per verificare se una metrica è anomala( ad esempio, controllare la deriva o la qualità del modello rispetto a una soglia). L'avviso può essere configurato per l'uso di una destinazione webhook, che può successivamente attivare il workflow di training.
Se la pipeline di ripetizione del training o altre pipeline presentano problemi di prestazioni, lo scienziato dei dati potrebbe dover tornare all'ambiente di sviluppo per effettuare ulteriori sperimentazioni per risolvere i problemi.