Flussi di lavoro LLMOps in Azure Databricks
Questo articolo integra i flussi di lavoro MLOps in Databricks aggiungendo informazioni specifiche ai flussi di lavoro LLMOps. Per altri dettagli, vedere Il Big Book di MLOps.
In che modo il flusso di lavoro MLOps cambia per i moduli LLM?
LLM è una classe di modelli di elaborazione del linguaggio naturale (NLP) che hanno superato significativamente le dimensioni e le prestazioni dei predecessori in un'ampia gamma di attività, ad esempio risposte a domande aperte, riepilogo ed esecuzione di istruzioni.
Lo sviluppo e la valutazione dei moduli LLM differiscono in alcuni modi importanti rispetto ai modelli di Machine Learning tradizionali. In questa sezione vengono riepilogate brevemente alcune delle proprietà principali dei moduli LLM e le implicazioni per MLOps.
| Proprietà chiave di LLM | Implicazioni per MLOps |
|---|---|
| LLM sono disponibili in molti moduli. - Modelli di sistema operativo e proprietari generali a cui si accede usando le API a pagamento. - Modelli open source che variano da applicazioni generali a specifiche. - Modelli personalizzati ottimizzati per applicazioni specifiche. - Applicazioni con training preliminare personalizzato. |
Processo di sviluppo: i progetti spesso sviluppano in modo incrementale, a partire da modelli esistenti, di terze parti o open source e terminano con modelli personalizzati ottimizzati. |
| Molti LLM accettano query e istruzioni in linguaggio naturale generali come input. Queste query possono contenere richieste accuratamente elaborate per ottenere le risposte desiderate. |
Processo di sviluppo: la progettazione di modelli di testo per l'esecuzione di query sulle LLM è spesso una parte importante dello sviluppo di nuove pipeline LLM. Creazione di pacchetti di artefatti ML: molte pipeline LLM usano gli endpoint di gestione LLM o LLM esistenti. La logica di Machine Learning sviluppata per tali pipeline potrebbe concentrarsi su modelli di richiesta, agenti o catene anziché sul modello stesso. Gli artefatti ML inseriti in un pacchetto e alzati di livello alla produzione potrebbero essere queste pipeline, anziché modelli. |
| È possibile assegnare a molti LLM prompt con esempi, contesto o altre informazioni per rispondere alla query. | Infrastruttura di gestione: quando si aumentano le query LLM con contesto, è possibile usare strumenti aggiuntivi, ad esempio i database vettoriali, per cercare il contesto pertinente. |
| Le API di terze parti forniscono modelli proprietari e open source. | Governance API: L'uso della governance centralizzata delle API offre la possibilità di passare facilmente tra provider di API. |
| I LLM sono modelli di Deep Learning di grandi dimensioni, spesso compresi tra gigabyte e centinaia di gigabyte. |
Infrastruttura di gestione: i LLM potrebbero richiedere GPU per la gestione dei modelli in tempo reale e l'archiviazione rapida per i modelli che devono essere caricati in modo dinamico. Compromessi di costo/prestazioni: poiché i modelli di dimensioni maggiori richiedono più calcoli e sono più costosi da gestire, potrebbero essere necessarie tecniche per ridurre le dimensioni e il calcolo del modello. |
| I LLM sono difficili da valutare usando le metriche di Machine Learning tradizionali, poiché spesso non esiste una singola risposta "corretta". | Feedback umano: il feedback umano è essenziale per la valutazione e il test di LLM. È consigliabile incorporare il feedback degli utenti direttamente nel processo MLOps, inclusi i test, il monitoraggio e l'ottimizzazione futura. |
Punti in comune tra MLOps e LLMOps
Molti aspetti dei processi MLOps non cambiano per i LLM. Ad esempio, le linee guida seguenti si applicano anche ai LLM:
- Usare ambienti separati per lo sviluppo, la gestione temporanea e la produzione.
- Usare Git per il controllo della versione.
- Gestire lo sviluppo di modelli con MLflow e usare Modelli in Unity Catalog per gestire il ciclo di vita del modello.
- Archivia i dati in un'architettura lakehouse usando tabelle Delta.
- L'infrastruttura CI/CD esistente non deve richiedere alcuna modifica.
- La struttura modulare di MLOps rimane invariata, con pipeline per la definizione delle caratteristiche, il training del modello, l'inferenza del modello e così via.
Diagrammi dell'architettura di riferimento
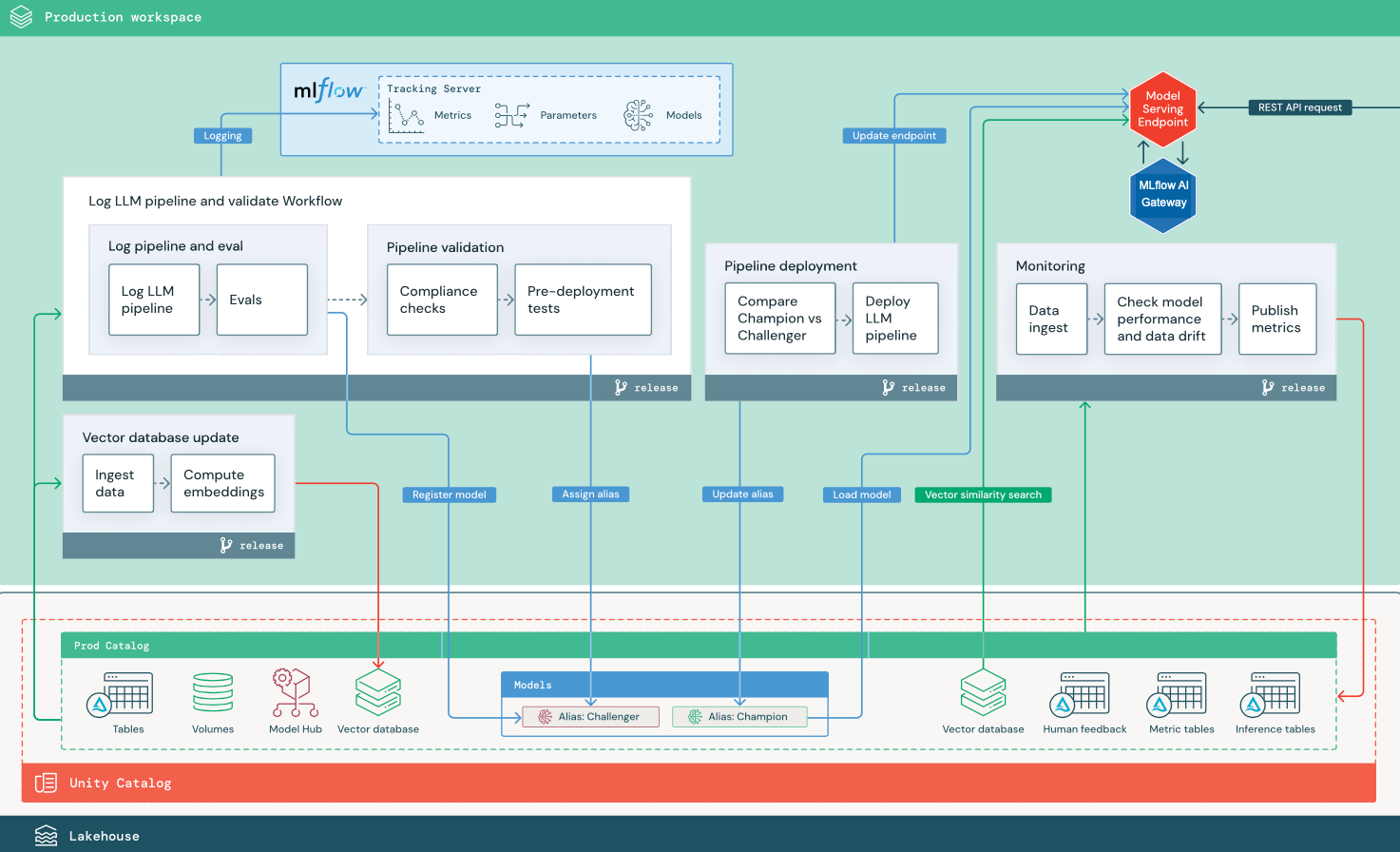
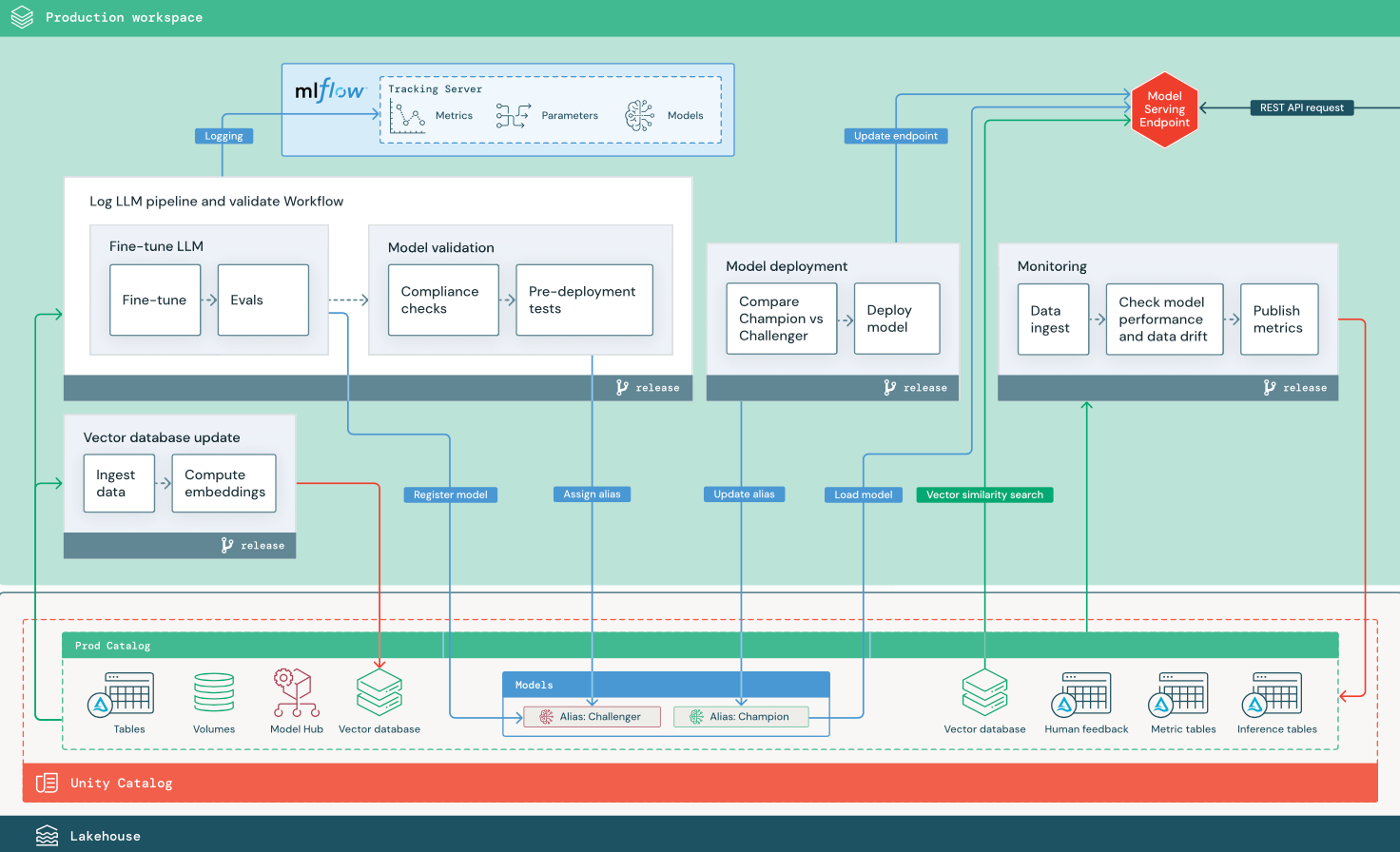
Questa sezione usa due applicazioni basate su LLM per illustrare alcune delle modifiche apportate all'architettura di riferimento di MLOps tradizionale. I diagrammi illustrano l'architettura di produzione per 1) un'applicazione di generazione aumentata di recupero (RAG) usando un'API di terze parti e 2) un'applicazione RAG usando un modello ottimizzato in modalità self-hosted. Entrambi i diagrammi mostrano un database vettoriale facoltativo. Questo elemento può essere sostituito eseguendo direttamente una query sull'LLM tramite l'endpoint Model Serving.
RAG con un'API LLM di terze parti
Il diagramma mostra un'architettura di produzione per un'applicazione RAG che si connette a un'API LLM di terze parti usando modelli esterni di Databricks.
RAG con un modello open source ottimizzato
Il diagramma mostra un'architettura di produzione per un'applicazione RAG che ottimizza un modello open source.
Modifiche LLMOps all'architettura di produzione MLOps
In questa sezione vengono evidenziate le principali modifiche apportate all'architettura di riferimento MLOps per le applicazioni LLMOps.
Hub del modello
Le applicazioni LLM usano spesso modelli esistenti con training preliminare selezionati da un hub modello interno o esterno. Il modello può essere usato così com'è o ottimizzato.
Databricks include una selezione di modelli di base di alta qualità con training preliminare in Unity Catalog e in Databricks Marketplace. È possibile usare questi modelli con training preliminare per accedere alle funzionalità di intelligenza artificiale all'avanguardia, risparmiando tempo e spese per la creazione di modelli personalizzati. Per informazioni dettagliate, consultare Modelli pre-addestrati in Unity Catalog e Marketplace.
Database vettoriale
Alcune applicazioni LLM usano database vettoriali per ricerche veloci di somiglianza, ad esempio per fornire informazioni sul contesto o sul dominio nelle query LLM. Databricks offre una funzionalità di ricerca vettoriale integrata che consente di usare qualsiasi tabella Delta in Unity Catalog come database vettoriale. L'indice di ricerca vettoriale viene sincronizzato automaticamente con la tabella Delta. Per informazioni dettagliate, vedere Vector Search.
È possibile creare un artefatto del modello che incapsula la logica per recuperare informazioni da un database vettoriale e fornisce i dati restituiti come contesto all'LLM. È quindi possibile registrare il modello usando il modello MLflow LangChain o PyFunc.
Ottimizzare LLM
Poiché i modelli LLM sono costosi e dispendiosi in termini di tempo per la creazione da zero, le applicazioni LLM spesso ottimizzano un modello esistente per migliorare le prestazioni in uno scenario specifico. Nell'architettura di riferimento, l'ottimizzazione e la distribuzione del modello sono rappresentate come processi di Databricks distinti. La convalida di un modello ottimizzato prima della distribuzione è spesso un processo manuale.
Databricks offre l'ottimizzazione del modello di base, che consente di usare i propri dati per personalizzare un LLM esistente per ottimizzare le prestazioni per l'applicazione specifica. Per informazioni dettagliate, vedere Ottimizzazione del modello di base.
Gestione dei modelli
Nel RAG che usa uno scenario API di terze parti, una modifica importante dell'architettura consiste nel fatto che la pipeline LLM effettua chiamate API esterne, dall'endpoint Model Serving alle API LLM interne o di terze parti. Ciò aggiunge complessità, potenziale latenza e gestione aggiuntiva delle credenziali.
Databricks offre Mosaic AI Model Serving che fornisce un'interfaccia unificata per implementare, gestire ed eseguire query sui modelli di intelligenza artificiale. Per informazioni dettagliate, vedere Mosaic AI Model Serving.
Feedback umano nel monitoraggio e nella valutazione
I cicli di feedback umano sono essenziali nella maggior parte delle applicazioni LLM. Il feedback umano deve essere gestito come altri dati, idealmente incorporato nel monitoraggio basato sullo streaming quasi in tempo reale.
L'app di revisione di Mosaic AI Agent Framework consente di raccogliere feedback dai revisori umani. Per informazioni dettagliate, vedi Ottieni feedback sulla qualità di un'applicazione agentica.