Criteri di distribuzione modello
Questo articolo descrive due modelli comuni per lo spostamento degli artefatti di Machine Learning tramite la gestione temporanea e l'ambiente di produzione. La natura asincrona delle modifiche apportate ai modelli e al codice significa che esistono più modelli possibili che un processo di sviluppo di Machine Learning potrebbe seguire.
I modelli vengono creati dal codice, ma gli artefatti del modello risultanti e il codice che li ha creati possono funzionare in modo asincrono. Ovvero, le nuove versioni del modello e le modifiche al codice potrebbero non verificarsi contemporaneamente. Si consideri ad esempio gli scenari seguenti:
- Per rilevare transazioni fraudolente, si sviluppa una pipeline di Machine Learning che ripete il training di un modello ogni settimana. Il codice potrebbe non cambiare molto spesso, ma il modello potrebbe essere sottoposto nuovamente a training ogni settimana per incorporare nuovi dati.
- È possibile creare una rete neurale profonda di grandi dimensioni per classificare i documenti. In questo caso, il training del modello è dispendioso in termini di calcolo e richiede molto tempo e è probabile che il training del modello venga eseguito raramente. Tuttavia, il codice che distribuisce, gestisce e monitora questo modello può essere aggiornato senza ripetere il training del modello.
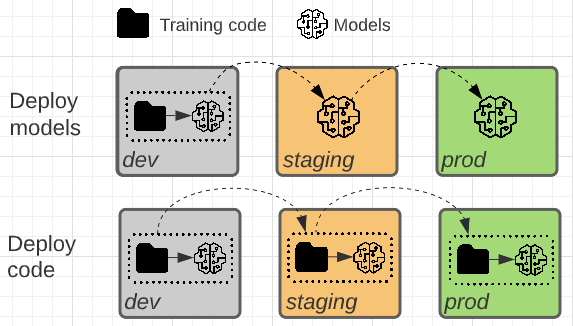
I due modelli differiscono se l'artefatto del modello o il codice di training che produce l'artefatto del modello viene alzato di livello verso la produzione.
Distribuire il codice (scelta consigliata)
Nella maggior parte dei casi, Databricks consiglia l'approccio "distribuire il codice". Questo approccio viene incorporato nel flusso di lavoro MLOps consigliato.
In questo modello, il codice per il training dei modelli viene sviluppato nell'ambiente di sviluppo. Lo stesso codice passa alla gestione temporanea e quindi alla produzione. Il training del modello viene eseguito in ogni ambiente: inizialmente nell'ambiente di sviluppo come parte dello sviluppo di modelli, nella gestione temporanea (in un subset limitato di dati) come parte dei test di integrazione e nell'ambiente di produzione (sui dati di produzione completi) per produrre il modello finale.
Vantaggi:
- Nelle organizzazioni in cui l'accesso ai dati di produzione è limitato, questo modello consente di eseguire il training del modello sui dati di produzione nell'ambiente di produzione.
- La ripetizione automatica del training dei modelli è più sicura, poiché il codice di training viene esaminato, testato e approvato per la produzione.
- Il codice di supporto segue lo stesso modello del codice di training del modello. Entrambi i test di integrazione vengono sottoposti a test di gestione temporanea.
Svantaggi:
- La curva di apprendimento per i data scientist può essere ripida. I modelli di progetto e i flussi di lavoro predefiniti sono utili.
Anche in questo modello, i data scientist devono essere in grado di esaminare i risultati del training dall'ambiente di produzione, in quanto hanno le conoscenze necessarie per identificare e risolvere i problemi specifici di ML.
Se la situazione richiede che il training del modello venga eseguito nello staging sul set di dati di produzione completo, è possibile usare un approccio ibrido distribuendo il codice nella gestione temporanea, eseguendo il training del modello e quindi distribuendo il modello nell'ambiente di produzione. Questo approccio consente di risparmiare sui costi di training nell'ambiente di produzione, ma aggiunge un costo aggiuntivo per le operazioni di gestione temporanea.
Distribuire i modelli
In questo modello l'artefatto del modello viene generato dal codice di training nell'ambiente di sviluppo. L'artefatto viene quindi testato nell'ambiente di staging prima di essere distribuito nell'ambiente di produzione.
Si consideri questa opzione quando si applica una o più delle opzioni seguenti:
- Il training del modello è molto costoso o difficile da riprodurre.
- Tutte le operazioni vengono eseguite in una singola area di lavoro di Azure Databricks.
- Non si lavora con repository esterni o con un processo CI/CD.
Vantaggi:
- Un handoff più semplice per i data scientist
- Nei casi in cui il training del modello è costoso, è necessario eseguire l'addestramento del modello solo una volta.
Svantaggi:
- Se i dati di produzione non sono accessibili dall'ambiente di sviluppo (che può essere vero per motivi di sicurezza), questa architettura potrebbe non essere valida.
- La ripetizione automatica del training dei modelli è complessa in questo modello. È possibile automatizzare la ripetizione del training nell'ambiente di sviluppo, ma il team responsabile della distribuzione del modello in produzione potrebbe non accettare il modello risultante come pronto per la produzione.
- Il codice di supporto, ad esempio le pipeline usate per la progettazione delle funzionalità, l'inferenza e il monitoraggio, deve essere distribuito in produzione separatamente.
In genere un ambiente (sviluppo, gestione temporanea o produzione) corrisponde a un catalogo in Unity Catalog. Per informazioni dettagliate su come implementare questo modello, vedere la guida all'aggiornamento.
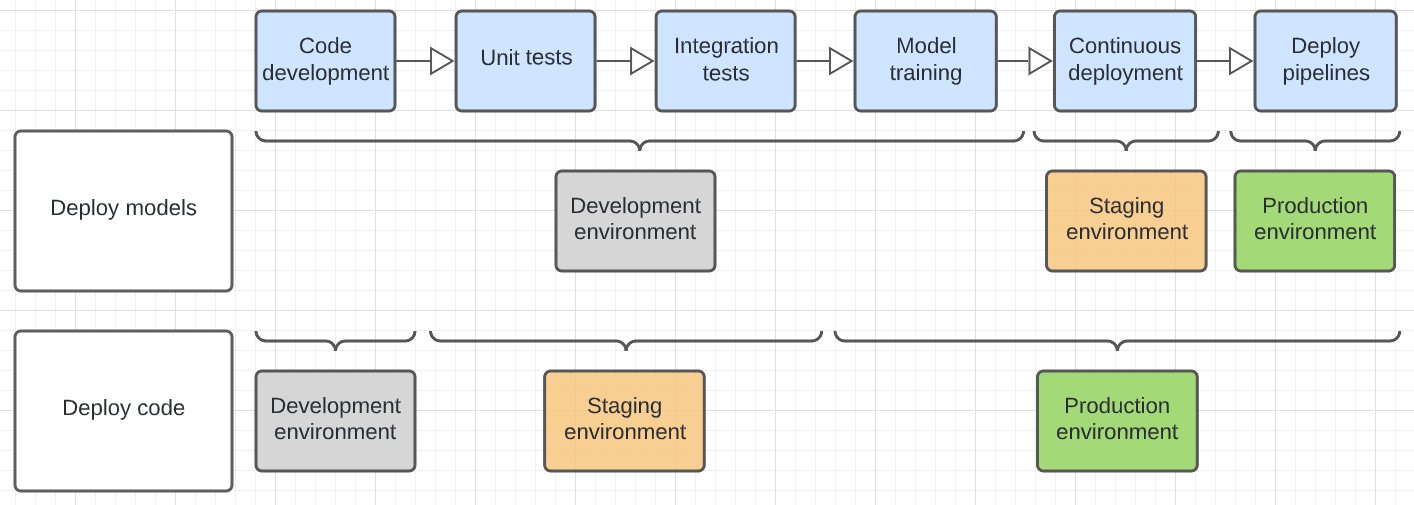
Il diagramma seguente contrasta il ciclo di vita del codice per i modelli di distribuzione precedenti nei diversi ambienti di esecuzione.
L'ambiente illustrato nel diagramma è l'ambiente finale in cui viene eseguito un passaggio. Ad esempio, nel modello di distribuzione dei modelli, l'unità finale e il test di integrazione vengono eseguiti nell'ambiente di sviluppo. Nel modello di codice di distribuzione, gli unit test e i test di integrazione vengono eseguiti negli ambienti di sviluppo e gli unit test finali e di integrazione vengono eseguiti nell'ambiente di gestione temporanea.